python大作业二
一、存入csv
上次爬取到了所需要的内容,但是没有存入到csv中,这次存入了csv文件中,代码如下:
import requests
from bs4 import BeautifulSoup
import csv
import io
import sys
sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') def get_url():#得到A-Z所有网站
urls=[]
for i in range(1,27):
i = chr(i+96)
urls.append('http://www.thinkbabynames.com/start/0/%s'%i)
return urls
pass def get_text(url):#得到所有名字以及连接,爬取所需内容
headers = {'Cookie':"User-Agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36"}
docx=requests.get(url)
soup=BeautifulSoup(docx.content,'html.parser')
c_txt1=soup.find('section',{'id':'index'}).findAll('b')
for x in c_txt1:
s=[]
if x.find('a'):
name=x.find('a')['href'].split("/")[-1]#使用正则表达式获得所有名字
#url.append('http://www.thinkbabynames.com/meaning/0/%s'%i)#获得所有名字详情页链接
if name:
r=requests.get('http://www.thinkbabynames.com/meaning/0/%s'%name)
result=r.text
bs=BeautifulSoup(result,'html.parser')
li=bs.find('div',class_='content').find('h1')
Enname=li.text[8::1]#使用切片语法获得详情页名字(s[x:y:z]x为起始,y为终止,z为步长)
Gender=li.text[1:8:1]#使用切片语法获得详情页名字性别
li1=bs.find('section',id='meaning').find('p')
Description=li1.text
#保存名字,性别,简介到s中
s.append(Enname)
s.append(Gender)
s.append(Description)
save_text(s)
return s
pass def save_text(s):#保存到csv中
with open('text.csv','a',encoding='utf_8_sig',newline='')as f:
writer = csv.writer(f)
writer.writerow(s) if __name__ == '__main__':
urls=get_url();
for url in urls:
get_text(url)
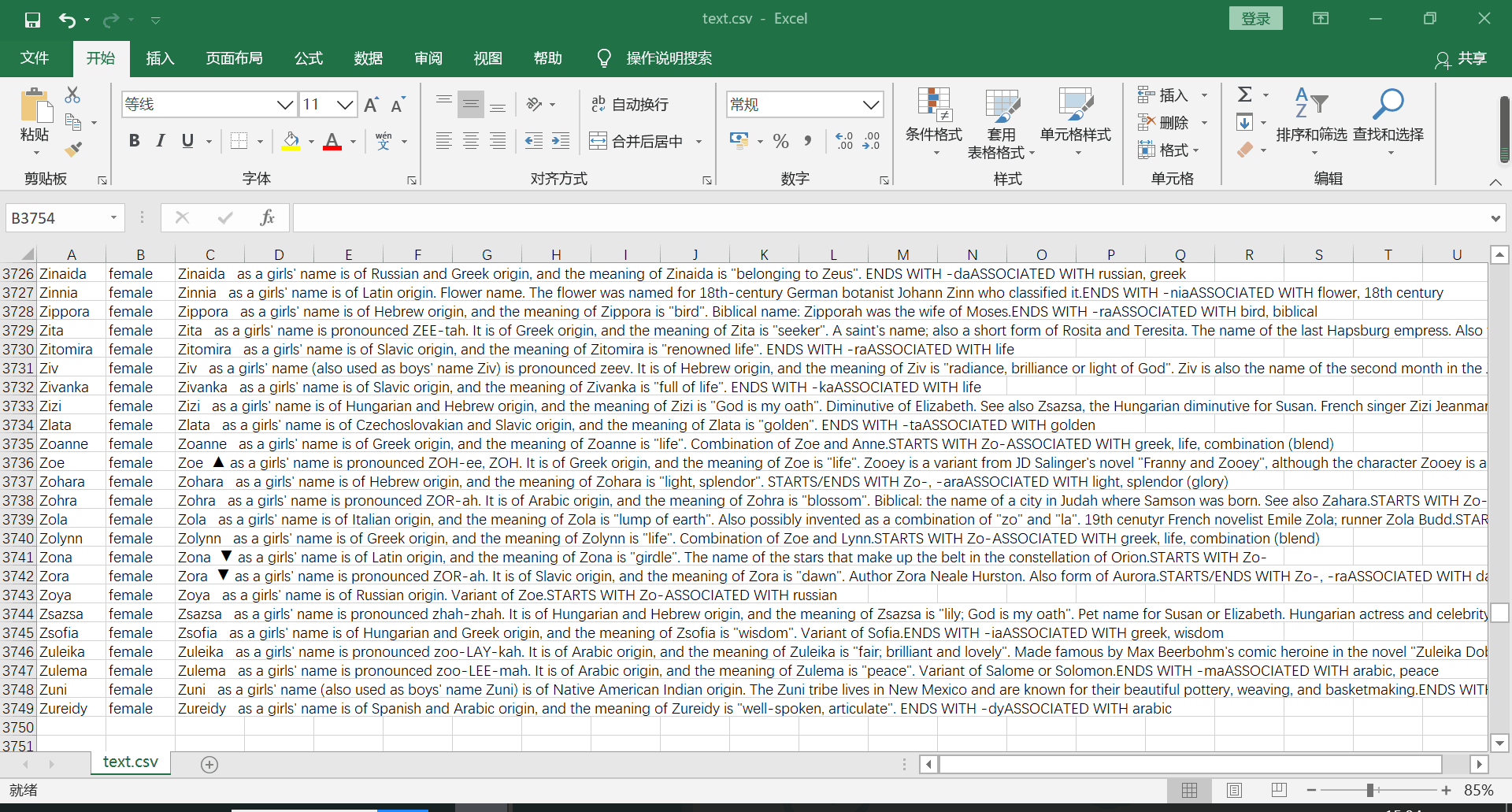
如上把得到的名字,性别,以及简介存入s中,再把s存到csv中。
二、csv文件截图

三、遇到的问题及解决方案
(1)爬取到所有名字时不能获得文本内容
解决方案:选择合适的正则表达式
docx=requests.get(url)
soup=BeautifulSoup(docx.content,'html.parser')
c_txt1=soup.find('section',{'id':'index'}).findAll('b')
for x in c_txt1:
s=[]
if x.find('a'):
name=x.find('a')['href'].split("/")[-1]#使用正则表达式获得所有名字
(2)获取名字详情页内容时,名字和性别在一起。
解决方案:使用切片语法分别获得名字和姓名分开存取
li=bs.find('div',class_='content').find('h1')
Enname=li.text[8::1]#使用切片语法获得详情页名字(s[x:y:z]x为起始,y为终止,z为步长)
Gender=li.text[1:8:1]#使用切片语法获得详情页名字性别
(3)在笔记本上运行时,访问量大
解决方案:分开来爬
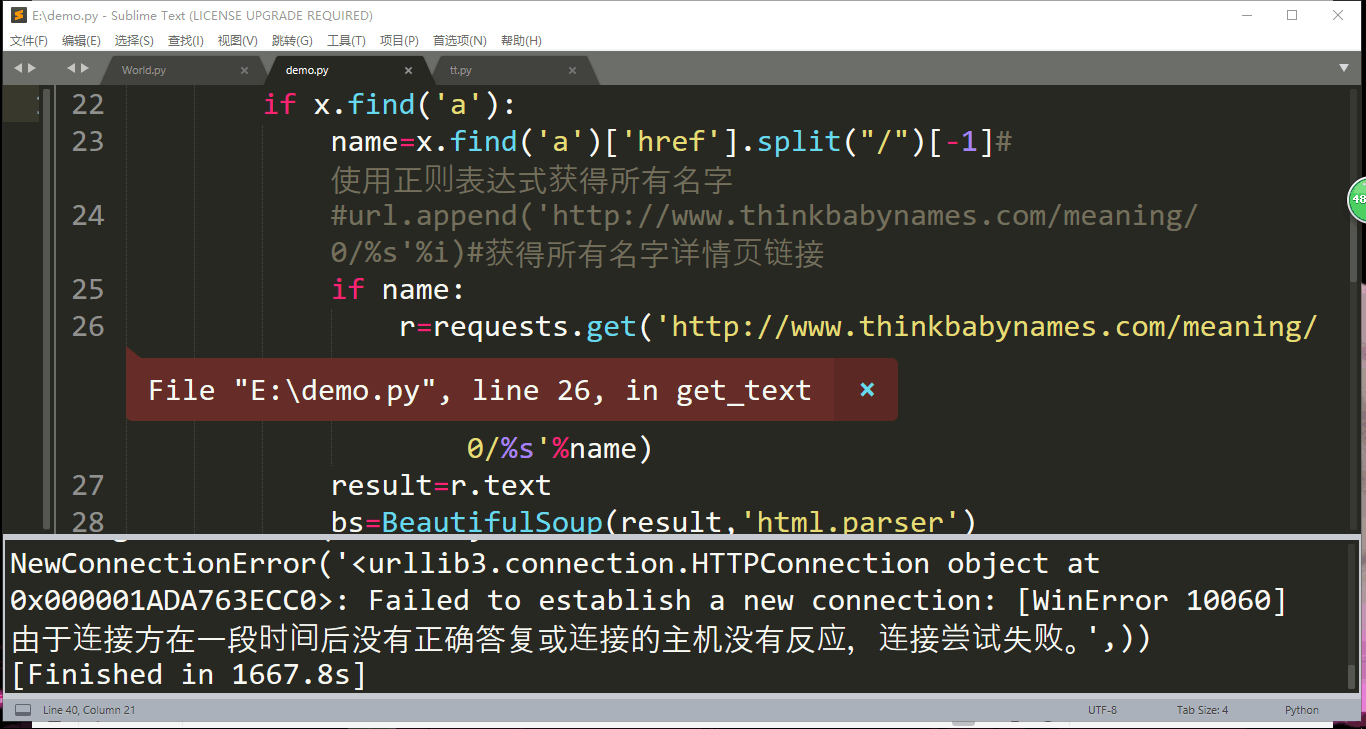

如上图,改变range()函数中的数字来选择爬取部分网站以减少访问量。
这样既能够满足爬取要求,也不会被网站禁止爬取。
python大作业二的更多相关文章
- python大作业
爬取西刺代理 生成请求头 #encoding = utf-8; __all__ = ("Header"); import random; class Header(object): ...
- python大作业-图书管理系统
#缺少循环执行和错误处理 #add()函数 添加了循环执行 #错误处理:regist()函数 登录和退出选择的时候添加了错误处理 import sys import importlib importl ...
- 数据库大作业--由python+flask
这个是项目一来是数据库大作业,另一方面也算是再对falsk和python熟悉下,好久不用会忘很快. 界面相比上一个项目好看很多,不过因为时间紧加上只有我一个人写,所以有很多地方逻辑写的比较繁琐,如果是 ...
- Python学习之编写三级菜单(Day1,作业二)
作业二:多级菜单 三级菜单 可依次进入各子菜单 在各级菜单中输入B返回上一级Q退出程序 知识点:字典的操作,while循环,for循环,if判断 思路: 1.开始,打印一级菜单让用户进行选择(可以输入 ...
- c++小学期大作业攻略(二)整体思路+主界面
写在前面:如果我曾经说过要在第一周之内写完大作业,那……肯定是你听错了.不过如果我在写的时候有攻略看的话应该可以轻松地在4~5天内做完,然后觉得写攻略的人是个小天使吧(疯狂暗示).出于给大家自由发挥的 ...
- 【大数据应用技术】作业十二|Hadoop综合大作业
本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 前言 本次作业是在<爬虫大作业>的基础上进行的 ...
- 爬虫综合大作业——网易云音乐爬虫 & 数据可视化分析
作业要求来自于https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075 爬虫综合大作业 选择一个热点或者你感兴趣的主题. 选择爬取的对象 ...
- 程设大作业xjb写——魔方复原
鸽了那么久总算期中过[爆]去[炸]了...该是时候写写大作业了 [总不能丢给他们不会写的来做吧 一.三阶魔方的几个基本定义 ↑就像这样,可以定义面的称呼:上U下D左L右R前F后B UD之间的叫E,LR ...
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
Python 数据分析(二) 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识 第1节 groupby 技术 第2节 数据聚合 第3节 分组级运算和转换 第4 ...
随机推荐
- 踩坑了!使用 @Autowired 注入成功,GetBean 方法却获取不到?!
本文首发于个人微信公众号:Coder小黑 踩坑了?! 之前推文已经讲过 当@Transactional遇到@CacheEvict,你的代码是不是有bug! 现在要在事务提交之后清除缓存.在Spring ...
- art-template循环无法显示出数据
art-template循环遍历无法显示数据原因 1.语法问题:循环语句导致的问题 2.插件问题: 用标准语法时循环数据如果引入第一个插件,会导致数据显示不出来只有引入第二个插件才可循环出数据 用原生 ...
- Qt5教程: (9) Qt多线程
目录 0. 创建工程 1. QThread 源码一览 2. QThread相关方法介绍 2.1 启动线程 2.2 关闭线程 2.3 阻塞线程 2.4线程状态判断 2.5 设置优先级 2.6 信号 3. ...
- 【Seleniuem】selenium.common.exceptions.InvalidSelectorException
selenium.common.exceptions.InvalidSelectorException: Message: invalid selector: An invalid or illega ...
- 基于JavaScript google map集成流程
google地图集成流程 一.获取Google Map API密钥 1.进入Google官网 => https://www.google.com.hk/ ,申请一个谷歌账号(如果没有)然后访问下 ...
- php使用phpqrcode生成二维码
前期准备: 1.phpqrcode类文件下载,下载地址:https://sourceforge.net/projects/phpqrcode/2.PHP环境必须开启支持GD2扩展库支持(一般情况下都是 ...
- 在Docker中跑Hadoop与镜像制作
重复造轮子,这里使用重新打包生成一个基于Docker的Hadoop镜像: Hadoop集群依赖的软件分别为:jdk.ssh等,所以只要这两项还有Hadoop相关打包进镜像中去即可: 配置文件准 ...
- spring源码学习(四)-spring生命周期用到的后置处理器
生命周期的九大后置处理器 第一次调用后置处理器org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory# ...
- 【CV现状-2】三维感知
#磨染的初心--计算机视觉的现状 [这一系列文章是关于计算机视觉的反思,希望能引起一些人的共鸣.可以随意传播,随意喷.所涉及的内容过多,将按如下内容划分章节.已经完成的会逐渐加上链接.] 缘起 三维感 ...
- 微信公众号:Mysticbinary
愿你有绝对自由.每周会写一篇哲学类文章.