统计学习方法与Python实现(三)——朴素贝叶斯法
统计学习方法与Python实现(三)——朴素贝叶斯法
iwehdio的博客园:https://www.cnblogs.com/iwehdio/
1、定义
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。
对于给定的训练数据集,首先基于特征条件独立假设学习输入输出的联合概率分布。然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出y,从而进行决策分类。
朴素贝叶斯法学习到的是生成数据的机制,属于生成模型。
设Ω为试验E的样本空间,A为E的事件,B1~Bn为Ω的一个划分,则有全概率公式:
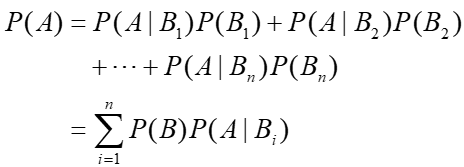
2、学习与分类
对于训练数据集: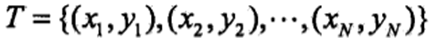 。
。
我们的目的是从训练集中学习到联合概率分布P(X, Y),为此先学习后验概率分布和条件概率分布。
后验概率分布,即类标签Y的概率分布,条件概率分布即在类标签Y确定的情况下输入特征向量x的分布。
从中学习后验概率分布:

从中学习条件概率分布:

条件概率分布的参数是指数级数量的,对其进行参数估计是不可能的。因此,对条件概率分布做独立性假设,认为输入特征向量x的各个分量是独立的,这也是“朴素”的含义。这样做简化了模型,但是也牺牲了分类的准确率。
条件独立性假设:

朴素贝叶斯法进行分类时,对于输入特征向量x,通过学习到的模型计算后验概率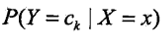 。主要是之前学习的后验概率
。主要是之前学习的后验概率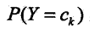 和条件概率
和条件概率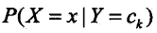 ,带入全概率公式,可得输入x的条件下,输出y取各个值的概率,并且将概率最大的y作为分类结果。
,带入全概率公式,可得输入x的条件下,输出y取各个值的概率,并且将概率最大的y作为分类结果。
朴素贝叶斯法分类的基本公式为:

朴素贝叶斯分类器为: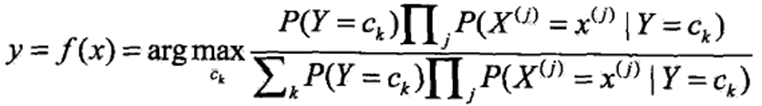
分母为定值,则进一步简化可得:
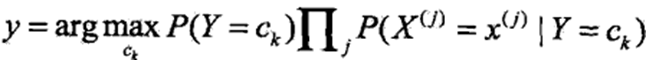
3、分类方法的含义
一般的分类方法都有损失函数的概念,优化的目标也是最小化损失函数。朴素贝叶斯法直接要求将实例分到后验概率最大的类中有何含义?实际上,这也等价于期望风险即损失函数最小化。
如果对模型f(X)取0-1损失函数L(Y,f(X)),即分类正确损失L取0,分类错误L取1。则期望风险函数为:
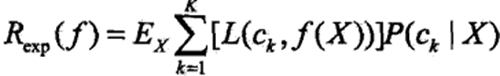
因为每个输入特征向量x是独立的,因此只需对每个X=x的实例进行极小化。
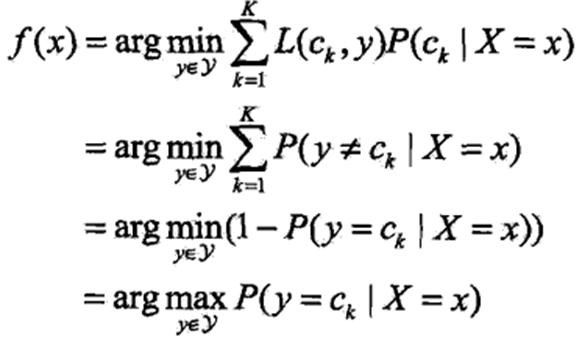
即推导得到了后验概率最大化准则。
4、参数学习
参数学习即确定每个先验概率和条件概率,一般用极大似然估计法。
先验概率P(Y = ck)的极大似然估计是:
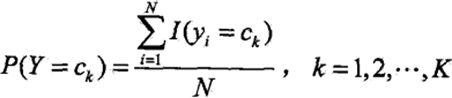 条件概率
条件概率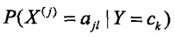 (即Y取ck时X的第j个特征取第l个值的概率)的极大似然估计是:
(即Y取ck时X的第j个特征取第l个值的概率)的极大似然估计是:

其中,函数I(.)表示当括号内的条件满足取1,不满足取0。
朴素贝叶斯算法为:
a、对于给定的训练数据集,计算先验概率和条件概率。
,
b、对于给定的实例x,计算

c、确定实例x的类
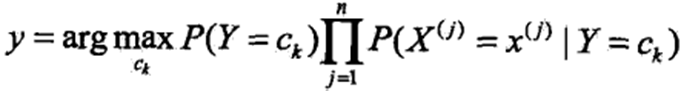
5、贝叶斯估计
极大似然估计可能会使所要估计的概率为0的情况,这时会导致计算条件概率时分母为0,使分类出现偏差。可以用贝叶斯估计来解决此问题,即在随机变量各个取值的聘书上加一个正数λ。λ取0时为极大似然估计,λ取1时为拉普拉斯平滑。贝叶斯估计下的条件概率为:
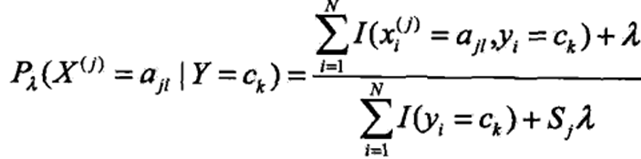
贝叶斯估计下的先验概率为: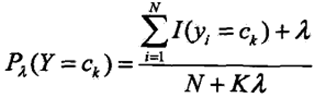
6、Python实现
数据集选择mnist手写数字集,数据集中为0~255的整数,先读入数据并对其进行0-1二值化。并初始化数组记录条件概率和先验概率。
from tensorflow.keras.datasets import mnist
import numpy as np (train_data, train_label), (test_data, test_label) = \
mnist.load_data(r'E:\code\statistical_learning_method\Data_set\mnist.npz') # 训练集和测试集大小
train_length = 60000
test_length = 10000
size = 28 * 28 # 输入特征向量长度
data_kind = 10 # 分为几类
choice = 2 # 每个向量有几种取值
lam = 1 # 贝叶斯估计中的lamda # 预处理数据
train_data = train_data[:train_length].reshape(train_length, size)
# 数据二值化
np.place(train_data, train_data > 0, 1)
train_label = np.array(train_label, dtype='int8')
train_label = train_label[:train_length].reshape(train_length, ) test_data = test_data[:test_length].reshape(test_length, size)
np.place(test_data, test_data > 0, 1) # 数据二值化
test_label = np.array(test_label, dtype='int8')
test_label = test_label[:test_length].reshape(test_length, ) # 初始化数组记录条件概率和先验概率
P_con = np.zeros([data_kind, size, choice])
P_pre = np.zeros(data_kind)
然后在训练集上进行学习,计算先验概率和条件概率。
# 计算先验概率
def compute_P_pre(label, P_init, lamda=1): pre = P_init
for la in label:
pre[int(la)] += 1 pre += lamda return pre / (label.shape[0] + pre.shape[0] * lamda) # 计算条件概率
def compute_P_con(data, label, P_init, lamda=1): con = P_init
summ = np.zeros(P_init.shape[0])
for index, value in enumerate(data):
for jndex, dalue in enumerate(value):
con[int(label[index]), jndex, int(dalue)] += 1
summ[int(label[index])] += 1 con += lamda
summ += lamda * 2 for index, value in enumerate(con):
con[index] /= summ[index] return con
最后,在测试集上进行测试。
# 进行测试
def Bayes_divide(pre, con, test, label): acc = 0
ans = np.full(test.shape[0], -1)
P_div = np.ones([test.shape[0], pre.shape[0]])
for index, value in enumerate(test):
for times in range(pre.shape[0]):
for jndex, dalue in enumerate(value):
P_div[index, times] *= con[times, jndex, int(dalue)]
P_div[index, times] *= pre[times] for index, temp in enumerate(P_div):
ans[index] = temp.argmax()
if ans[index] == label[index]:
acc += 1 return acc / label.shape[0], ans P_pre = compute_P_pre(train_label, P_pre, lamda=lam)
P_con = compute_P_con(train_data, train_label, P_con, lamda=lam)
acc, ans = Bayes_divide(P_pre, P_con, test_data, test_label)
print('acc', acc)
lam=1时的测试结果为acc=0.8413。
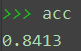
更改lam的值,lam=0时,acc=0.8410;lam=2时,acc=0.8411;lam=5时,acc=0.8407;lam=10时,acc=0.8399。总的而言影响不大。
7、生成模型
因为朴素贝叶斯方法是生成模型,所以可以通过训练好的模型生成出模型学习到的特征,也就是生成模型认为最像某个数字的图像。最简单的思想就是,因为我们假设输入特征向量x的各个维度的值是独立的,所以可以输入一个初始向量,然后比较每个维度上取0或1时,模型输出的概率大小,然后将各个维度的值置为更大的概率所对应的值。代码实现如下:
from skimage import io
import matplotlib.pyplot as plt # 测试输入数据被识别为goal的概率
def test(data0, goal, pre, con): P_gene = 1
for index, value in enumerate(data0):
P_gene *= con[goal, index, int(value)]
P_gene *= pre[goal] return P_gene # 初始化输入为全0向量
gene = np.zeros([data_kind, size])
for goals, sim in enumerate(gene):
temp = sim
# 遍历向量
for index in range(sim.shape[0]):
ans1 = test(temp, goals, P_pre, P_con)
temp[index] = 1
ans2 = test(temp, goals, P_pre, P_con)
if ans1 > ans2:
temp[index] = 0 # 画出生成的图像
for i in range(gene[:10].shape[0]):
draw = gene[i][:, np.newaxis]
draw = draw.reshape([28, 28])
plt.subplot(1, 10, i+1)
plt.axis('off')
io.imshow(draw)
plt.tight_layout()
最后的输出结果为:
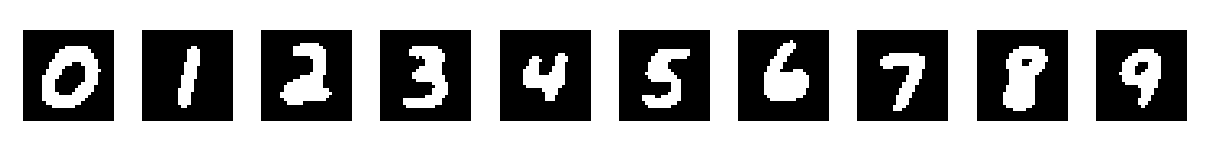
参考:李航 《统计学习方法(第二版)》
iwehdio的博客园:https://www.cnblogs.com/iwehdio/
统计学习方法与Python实现(三)——朴素贝叶斯法的更多相关文章
- 【机器学习实战笔记(3-2)】朴素贝叶斯法及应用的python实现
文章目录 1.朴素贝叶斯法的Python实现 1.1 准备数据:从文本中构建词向量 1.2 训练算法:从词向量计算概率 1.3 测试算法:根据现实情况修改分类器 1.4 准备数据:文档词袋模型 2.示 ...
- Python机器学习算法 — 朴素贝叶斯算法(Naive Bayes)
朴素贝叶斯算法 -- 简介 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法.最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Baye ...
- Python实现nb(朴素贝叶斯)
Python实现nb(朴素贝叶斯) 运行环境 Pyhton3 numpy科学计算模块 计算过程 st=>start: 开始 op1=>operation: 读入数据 op2=>ope ...
- 朴素贝叶斯法(naive Bayes algorithm)
对于给定的训练数据集,朴素贝叶斯法首先基于iid假设学习输入/输出的联合分布:然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出y. 一.目标 设输入空间是n维向量的集合,输出空间为 ...
- 朴素贝叶斯法(naive Bayes)
<统计学习方法>(第二版)第4章 4 朴素贝叶斯法 生成模型 4.1 学习与分类 基于特征条件独立假设学习输入输出的联合概率分布 基于联合概率分布,利用贝叶斯定理求出后验概率最大的输出 条 ...
- 第四章 朴素贝叶斯法(naive_Bayes)
总结 朴素贝叶斯法实质上是概率估计. 由于加上了输入变量的各个参量条件独立性的强假设,使得条件分布中的参数大大减少.同时准确率也降低. 概率论上比较反直觉的一个问题:三门问题:由于主持人已经限定了他打 ...
- 吴裕雄--天生自然python机器学习:朴素贝叶斯算法
分类器有时会产生错误结果,这时可以要求分类器给出一个最优的类别猜测结果,同 时给出这个猜测的概率估计值. 概率论是许多机器学习算法的基础 在计算 特征值取某个值的概率时涉及了一些概率知识,在那里我们先 ...
- spark(1.1) mllib 源码分析(三)-朴素贝叶斯
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/4042467.html 本文主要以mllib 1.1版本为基础,分析朴素贝叶斯的基本原理与源码 一.基本原 ...
- Python之机器学习-朴素贝叶斯(垃圾邮件分类)
目录 朴素贝叶斯(垃圾邮件分类) 邮箱训练集下载地址 模块导入 文本预处理 遍历邮件 训练模型 测试模型 朴素贝叶斯(垃圾邮件分类) 邮箱训练集下载地址 邮箱训练集可以加我微信:nickchen121 ...
随机推荐
- A.Two Rival Students
题目:两个竞争的学生 链接:(两个竞争的对手)[https://codeforces.com/contest/1257/problem/A] 题意:有n个学生排成一行.其中有两个竞争的学生.第一个学生 ...
- ASP.NET Core 选项模式源码学习Options IOptionsMonitor(三)
前言 IOptionsMonitor 是一种单一示例服务,可随时检索当前选项值,这在单一实例依赖项中尤其有用.IOptionsMonitor用于检索选项并管理TOption实例的选项通知, IOpti ...
- redis(6)--redis集群之分片机制(redis-cluster)
Redis-Cluster 即使是使用哨兵,此时的Redis集群的每个数据库依然存有集群中的所有数据,从而导致集群的总数据存储量受限于可用存储内存最小的节点,形成了木桶效应.而因为Redis是基于内存 ...
- 2019年JVM面试都问了什么?快看看这22道面试题!(附答案解析)
一. Java 类加载过程? Java 类加载需要经历一下 7 个过程: 1. 加载 加载是类加载的第一个过程,在这个阶段,将完成一下三件事情: • 通过一个类的全限定名获取该类的二进制流. • 将该 ...
- ajax结合sweetalert实现删除按钮动态效果
目录 一.ajax结合sweetalert实现删除按钮动态效果 二.bulk_create批量插入数据 1. 一条一条插入 2. 批量插入 三.自定义分页器 一.ajax结合sweetalert实现删 ...
- keras实现mnist手写数字数据集的训练
网络:两层卷积,两层全连接,一层softmax 代码: import numpy as np from keras.utils import to_categorical from keras imp ...
- Java生鲜电商平台-生鲜系统中商品订单系统售后系统设计
Java生鲜电商平台-生鲜系统中商品订单系统售后系统设计(服务订单履约系统) 说明: 电商之下,我们几乎能从电商平台上买到任何我们日常需要的商品,但是对于很多商品来说,用户购买发货后,只是整个交易流程 ...
- ArcGIS Runtime SDK for WPF学习笔记(一)
本节主要讲解如何安装ArcGIS Runtime SDK,以及移除注释与水印. 附上ArcGIS Runtime SDK for .NET的官方操作手册网址:https://developers.ar ...
- VNC连接CentOS7远程桌面
1.在centos7安装图形化 先安装图形用户接口X Window System,再安装GNOME桌面. [root@centos7 ~]# yum groupinstall -y "X W ...
- mac-安装sshpass
在配置了ssh免密认证id_rsa.pub之后,在cmd终端可以实现免密登陆对应配置了密钥的服务器,但是在python程序中,想要调用cmd执行免密操作,还需要安装sshpass,sshpass用于非 ...