Disruptor原理探讨
之前谈到了在我的项目里用到了Disruptor,因为对它了解不足的原因,才会引发之前的问题,因此,今天特意来探讨其原理。
为什么采用Disruptor
先介绍一下我的这个服务。这个服务主要是作为游戏服务器的游戏逻辑部分,包括帧同步逻辑及其他在游戏过程中玩家产生的一些业务逻辑。
从用户量来说,现在最高峰大概有300人同时在线,游戏服务器设置1秒有30帧的数据量,因此,1秒内服务器接收到的请求量为30 * 300 = 9000。
虽然QPS并不是很高,但对于多人对抗竞技类游戏而言,低延迟十分重要,每一次客户端向服务器端的响应时间需要低于1/30秒(因为1秒需要发送30次)。针对这种情况,我需要的存储消息的容器应该具备快速生产、快速消费的特性。
那为什么当初要选择使用Disruptor作为存储客户端发来消息的容器,为什么不直接使用Java本身自带的那些队列结构呢?
让我们看看Java里常用的线程安全的内置队列:
| 类 | 是否有界 | 是否加锁 | 底层数据结构 |
|---|---|---|---|
| ArrayBlockingQueue | 有界 | 加锁 | 数组 |
| LinkedBlockingQueue | 有界(2^31-1) | 加锁 | 链表 |
| ConcurrentLinkedQueue | 无界 | 无锁 | 链表 |
| LinkedTransferQueue | 无界 | 无锁 | 链表 |
| PriorityBlockingQueue | 无界 | 加锁 | 堆 |
| DelayQueue | 无界 | 加锁 | 堆 |
一般来说我们并不会考虑堆,因为堆在实现带有优先级的队列更好。
从性能上来说,无锁时的QPS一般来说优于加锁,而ConcurrentLinkedQueue的无锁其实是通过原子变量进行compare and swap(以下简称为CAS,由CPU保证原子性)这种不加锁的方式来实现的。
但无锁的结构都是无界的,为了系统的稳定,我们需要防止生产者速度过快导致内存溢出,我们需要使队列有界;同时,为了减少Java的垃圾回收对系统性能的影响,会尽量选择array/heap(因为使用这两种结构,数据在内存中存储的地址连续)。
这样筛选下来,ArrayBlockingQueue可能相对而言更加合适,但它依旧存在性能问题——加锁、伪共享。
加锁上面也提到了,更好的方式是使用CAS,那伪共享又是什么呢?
伪共享
什么是共享
下图是计算的基本结构。L1、L2、L3分别表示一级缓存、二级缓存、三级缓存,越靠近CPU的缓存,速度越快,容量也越小。所以L1缓存很小但很快,并且紧靠着在使用它的CPU内核;L2大一些,也慢一些,并且仍然只能被一个单独的CPU核使用;L3更大、更慢,并且被单个插槽上的所有CPU核共享;最后是主存,由全部插槽上的所有CPU核共享。如图:
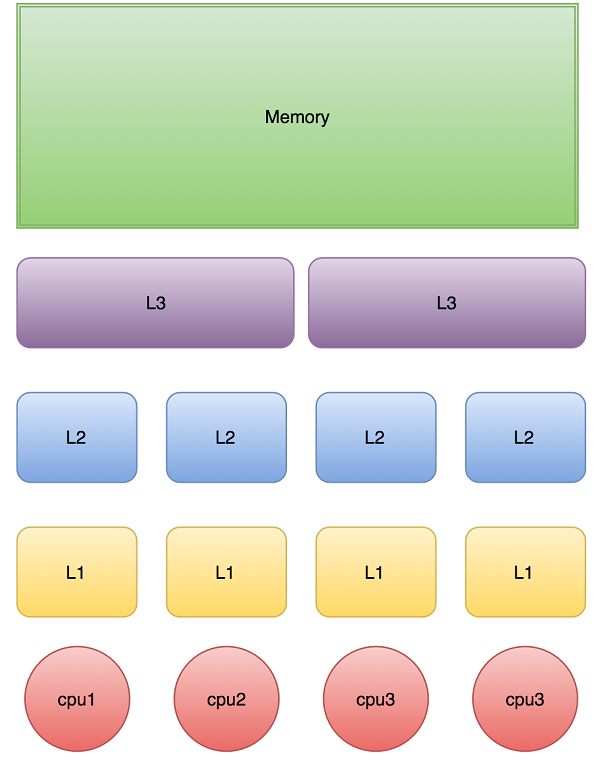
当CPU执行运算的时候,它先去L1查找所需的数据、再去L2、然后是L3,如果最后这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要尽量确保数据在L1缓存中。
另外,线程之间共享一份数据的时候,需要一个线程把数据写回主存,而另一个线程访问主存中相应的数据。
缓存行
Cache是由很多个cache line组成的。每个cache line通常是64字节,并且它有效地引用主内存中的一块儿地址。一个Java的long类型变量是8字节,因此在一个缓存行中可以存8个long类型的变量。
CPU每次从主存中拉取数据时,会把相邻的数据也存入同一个cache line。
在访问一个long数组的时候,如果数组中的一个值被加载到缓存中,它会自动加载另外7个。因此你能非常快的遍历这个数组。事实上,你可以非常快速的遍历在连续内存块中分配的任意数据结构。
下面的例子是测试利用cache line的特性和不利用cache line的特性的效果对比。
/**
* 缓存行
* Cache是由很多个cache line组成的。每个cache line通常是64字节,并且它有效地引用主内存中的一块儿地址。一个Java的long类型变量是8字节,因此在一个缓存行中可以存8个long类型的变量。
*
* CPU每次从主存中拉取数据时,会把相邻的数据也存入同一个cache line。
*
* 在访问一个long数组的时候,如果数组中的一个值被加载到缓存中,它会自动加载另外7个。因此你能非常快的遍历这个数组。事实上,你可以非常快速的遍历在连续内存块中分配的任意数据结构。
*/
public class CacheLineEffect {
//考虑一般缓存行大小是64字节,一个 long 类型占8字节
static long[][] arr;
public static void main(String[] args) {
arr = new long[1024 * 1024][];
for (int i = 0; i < 1024 * 1024; i++) {
arr[i] = new long[8];
for (int j = 0; j < 8; j++) {
arr[i][j] = 0L;
}
}
long sum = 0L;
long marked = System.currentTimeMillis();
for (int i = 0; i < 1024 * 1024; i+=1) {
// 此时的8个数据其实已经直接在拿第1次的时候就全部拿下来了
for(int j =0; j< 8;j++){
sum = arr[i][j];
}
}
System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms");
marked = System.currentTimeMillis();
for (int i = 0; i < 8; i+=1) {
// 此时拿的数据其实同一列上的数据,从内存地址上来说并不连续
for(int j =0; j< 1024 * 1024;j++){
sum = arr[j][i];
}
}
System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms");
}
}
结果为:
Loop times:16ms
Loop times:72ms
速度差异还是比较明显的。
什么是伪共享
ArrayBlockingQueue有三个成员变量: - takeIndex:需要被取走的元素下标 - putIndex:可被元素插入的位置的下标 - count:队列中元素的数量
这三个变量很容易放到一个缓存行中,但是之间修改没有太多的关联。所以每次修改,都会使之前缓存的数据失效,从而不能完全达到共享的效果。

如上图所示,当生产者线程put一个元素到ArrayBlockingQueue时,putIndex会修改,从而导致消费者线程的缓存中的缓存行无效,需要从主存中重新读取。
这种无法充分使用缓存行特性的现象,称为伪共享。
对于伪共享,一般的解决方案是,增大数组元素的间隔使得由不同线程存取的元素位于不同的缓存行上,以空间换时间。
/**
* 伪共享
*
* 针对处在同一个缓存行内的数据,假设线程1修改了其中的一个数据a后,线程2想要读取数据a,
* 因为a已经被修改了,因此缓存行失效,需要从主内存中重新读取。
* 这种无法充分使用缓存行特性的现象,称为伪共享。
* 当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
*/
public class FalseSharing implements Runnable{
public final static long ITERATIONS = 500L * 1000L * 100L;
private int arrayIndex = 0;
private static ValueNoPadding[] longsNoPadding;
private static ValuePadding[] longsPadding;
private boolean padding;
public FalseSharing(final int arrayIndex, boolean padding) {
this.arrayIndex = arrayIndex;
this.padding = padding;
}
public static void main(final String[] args) throws Exception {
for(int i=1;i<10;i++){
System.gc();
final long start = System.currentTimeMillis();
runTestNoPadding(i);
System.out.println("NoPadding Thread num "+i+" duration = " + (System.currentTimeMillis() - start));
}
for(int i=1;i<10;i++){
System.gc();
final long start = System.currentTimeMillis();
runTestPadding(i);
System.out.println("Padding Thread num "+i+" duration = " + (System.currentTimeMillis() - start));
}
}
private static void runTestPadding(int NUM_THREADS) throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
longsPadding = new ValuePadding[NUM_THREADS];
for (int i = 0; i < longsPadding.length; i++) {
longsPadding[i] = new ValuePadding();
}
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseSharing(i, true));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
private static void runTestNoPadding(int NUM_THREADS) throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
longsNoPadding = new ValueNoPadding[NUM_THREADS];
for (int i = 0; i < longsNoPadding.length; i++) {
longsNoPadding[i] = new ValueNoPadding();
}
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseSharing(i, false));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
if (padding) {
longsPadding[arrayIndex].value = 0L;
} else {
longsNoPadding[arrayIndex].value = 0L;
}
}
}
public final static class ValuePadding {
protected long p1, p2, p3, p4, p5, p6, p7;
protected volatile long value = 0L;
protected long p9, p10, p11, p12, p13, p14;
protected long p15;
}
public final static class ValueNoPadding {
// protected long p1, p2, p3, p4, p5, p6, p7;
protected volatile long value = 0L;
// protected long p9, p10, p11, p12, p13, p14, p15;
}
}
结果:
NoPadding Thread num 1 duration = 394
NoPadding Thread num 2 duration = 1594
NoPadding Thread num 3 duration = 1702
NoPadding Thread num 4 duration = 1580
NoPadding Thread num 5 duration = 3217
NoPadding Thread num 6 duration = 3539
NoPadding Thread num 7 duration = 3269
NoPadding Thread num 8 duration = 3317
NoPadding Thread num 9 duration = 2800
Padding Thread num 1 duration = 373
Padding Thread num 2 duration = 432
Padding Thread num 3 duration = 453
Padding Thread num 4 duration = 490
Padding Thread num 5 duration = 533
Padding Thread num 6 duration = 565
Padding Thread num 7 duration = 622
Padding Thread num 8 duration = 685
Padding Thread num 9 duration = 810
从这儿可以看出,使用了共享机制比没有使用共享机制,速度快了4倍左右。(在jdk1.8中,有专门的注解@Contended来避免伪共享,更优雅地解决问题,有兴趣地朋友可以取了解一下。)
因此,虽然ArrayBlockingQueue相对于其他队列结构而言更适合我的服务,但依旧有着性能上的缺陷,因此我选择了Disruptor。
生产者和消费者
Disruptor通过环形数组结构来解决队列速度慢的问题,那具体针对生产者和消费者,它是如何保证数据读写一致性的呢?
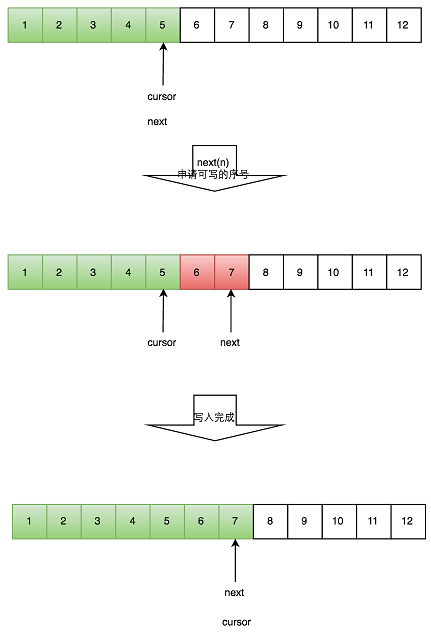
一个生产者写数据
生产者单线程写数据的流程比较简单: 1. 申请写入m个元素; 2. 若是有m个元素可以写入,则返回最大的序列号。这儿主要判断是否会覆盖未读的元素; 3. 若是返回的正确,则生产者开始写入元素。
多个生产者
多个生产者的情况下,会遇到“如何防止多个线程重复写同一个元素”的问题。Disruptor的解决方法是,每个线程获取不同的一段数组空间进行操作。这个通过CAS很容易达到。只需要在分配元素的时候,通过CAS判断一下这段空间是否已经分配出去即可。
但是会遇到一个新问题:如何防止读取的时候,读到还未写的元素。Disruptor在多个生产者的情况下,引入了一个与Ring Buffer大小相同的buffer:available Buffer。当某个位置写入成功的时候,便把availble Buffer相应的位置置位,标记为写入成功。读取的时候,会遍历available Buffer,来判断元素是否已经就绪。
下面分读数据和写数据两种情况介绍。
读数据
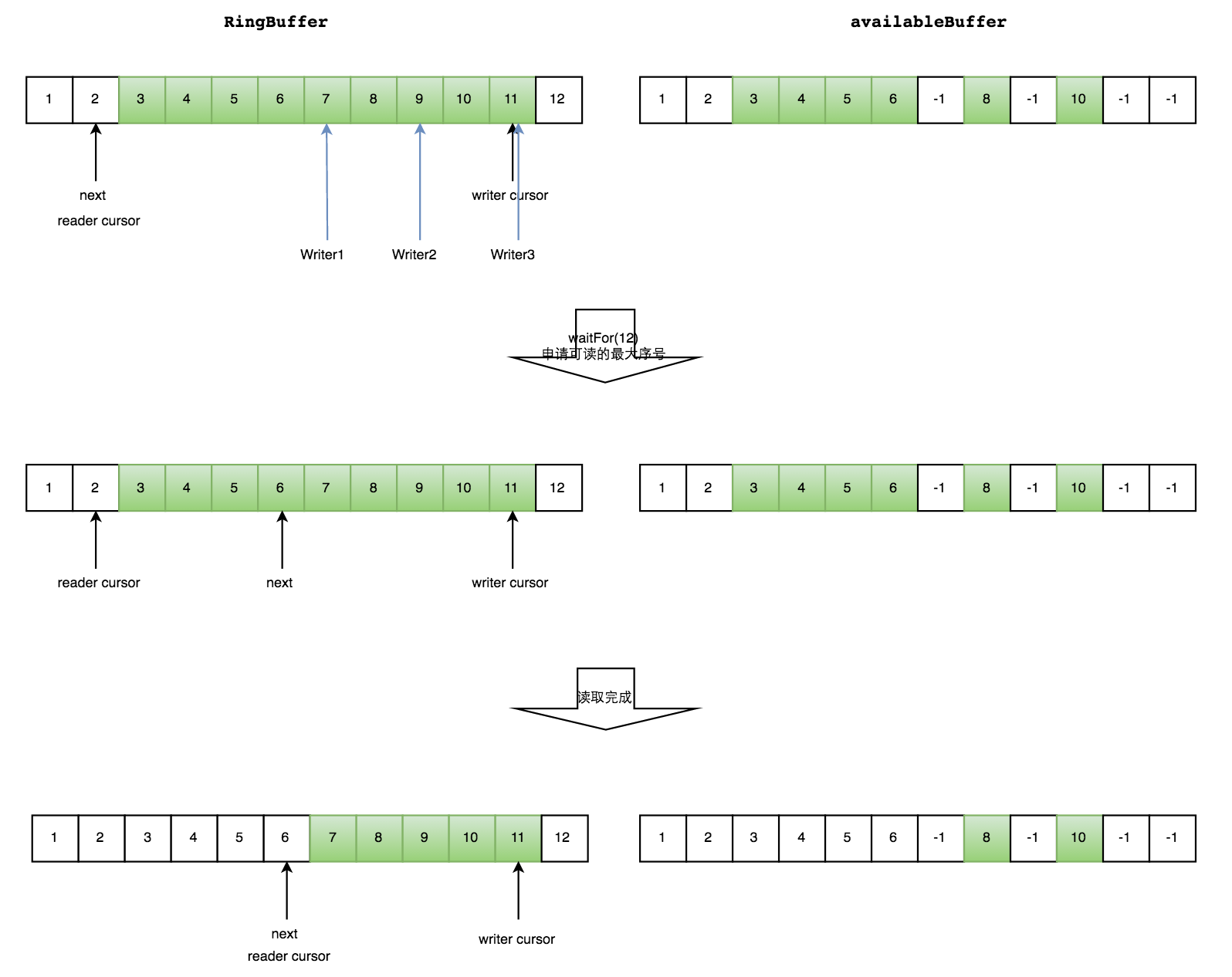
生产者多线程写入的情况会复杂很多: 1. 申请读取到序号n; 2. 若writer cursor >= n,这时仍然无法确定连续可读的最大下标。从reader cursor开始读取available Buffer,一直查到第一个不可用的元素,然后返回最大连续可读元素的位置; 3. 消费者读取元素。
如下图所示,读线程读到下标为2的元素,三个线程Writer1/Writer2/Writer3正在向RingBuffer相应位置写数据,写线程被分配到的最大元素下标是11。
读线程申请读取到下标从3到11的元素,判断writer cursor>=11。然后开始读取availableBuffer,从3开始,往后读取,发现下标为7的元素没有生产成功,于是WaitFor(11)返回6。
然后,消费者读取下标从3到6共计4个元素。
写数据
多个生产者写入的时候: 1. 申请写入m个元素; 2. 若是有m个元素可以写入,则返回最大的序列号。每个生产者会被分配一段独享的空间; 3. 生产者写入元素,写入元素的同时设置available Buffer里面相应的位置,以标记自己哪些位置是已经写入成功的。
如下图所示,Writer1和Writer2两个线程写入数组,都申请可写的数组空间。Writer1被分配了下标3到下表5的空间,Writer2被分配了下标6到下标9的空间。
Writer1写入下标3位置的元素,同时把available Buffer相应位置置位,标记已经写入成功,往后移一位,开始写下标4位置的元素。Writer2同样的方式。最终都写入完成。

消费者的等待策略
| 名称 | 措施 | 适用场景 |
|---|---|---|
| BlockingWaitStrategy | 加锁 | CPU资源紧缺,吞吐量和延迟并不重要的场景 |
| BusySpinWaitStrategy | 自旋 | 通过不断重试,减少切换线程导致的系统调用,而降低延迟。推荐在线程绑定到固定的CPU的场景下使用 |
| PhasedBackoffWaitStrategy | 自旋 + yield + 自定义策略 | CPU资源紧缺,吞吐量和延迟并不重要的场景 |
| SleepingWaitStrategy | 自旋 + yield + sleep | 性能和CPU资源之间有很好的折中。延迟不均匀 |
| TimeoutBlockingWaitStrategy | 加锁,有超时限制 | CPU资源紧缺,吞吐量和延迟并不重要的场景 |
| YieldingWaitStrategy | 自旋 + yield + 自旋 | 性能和CPU资源之间有很好的折中。延迟比较均匀 |
从这儿可以看出,我需要的就是低延迟,因此就采用了BusySpinWaitStrategy,它虽然占用的资源多,但延迟低,非常符合我这个服务的要求。后来测试了一下其他的策略,发现都会有一些卡顿,毕竟不是一直在运行,接受到的客户端的消息就会有延迟产生。
总结
Disruptor的高性能一方面是在于它没有用很重的锁,仅仅通过CPU的CAS就保证了操作的原子性;另一方面是在于它的数据结构RingBuffer(也包括Available)和Cursor的设计巧妙;当然还有它的等待策略、线程池等等。
如果你有什么意见或者建议,欢迎在下方评论。
有兴趣的话可以关注我的公众号或者头条号,说不定会有意外的惊喜。


Disruptor原理探讨的更多相关文章
- MySQL 复制夯住一例排查以及原理探讨
目录 目录 一 引子 二 故障分析 三 故障解决 四 原理探讨 五 小结 文/温国兵 一 引子 研发反应,有台从库和主库不同步.由于业务读操作是针对从库的,数据不同步必定会带来数据的不一致,业务获取的 ...
- LMAX Disruptor 原理
http://mechanitis.blogspot.com/search/label/disruptor http://ifeve.com/disruptor/, 并发框架Disruptor译文 h ...
- 高效取余运算(n-1)&hash原理探讨
Java的HashMap源码中用到的(n-1)&hash这样的运算,查找发现这是一种高效的求余数的办法,但其中的原理是什么呢为什么可以这么做呢? 先上结论:假设被除数是x,对于除数是2n的取余 ...
- 并发编程-CPU执行volatile原理探讨-可见性与原子性的深入理解
volatile的定义 Java语言规范第3版中对volatile的定义如下:Java编程语言允许线程访问共享变量,为了确保共享变量能被准确和一致地更新,线程应该确保通过排他锁单独获得这个变量.Jav ...
- Socket通信原理探讨(C++为例)
一.网络中进程之间如何通信? 本地的进程间通信(IPC)有很多种方式,但可以总结为下面4类: 1.消息传递(管道.FIFO.消息队列) 2.同步(互斥量.条件变量.读写锁.文件和写记录锁.信号量) 3 ...
- Socket通信原理探讨(C++为例) good
http://www.cnblogs.com/xufeiyang/articles/4878096.html http://www.cnblogs.com/xufeiyang/articles/453 ...
- MySQL复制(一)复制原理探讨
1 复制概述 1.1.复制解决的问题 数据复制技术有以下一些特点: (1) 数据分布 (2) 负载平衡(load balancing) (3) 备份 (4) 高可用性(high availabilit ...
- 从零开始实现lmax-Disruptor队列(五)Disruptor DSL风格API原理解析
MyDisruptor V5版本介绍 在v4版本的MyDisruptor实现多线程生产者后.按照计划,v5版本的MyDisruptor需要支持更便于用户使用的DSL风格的API. 由于该文属于系列博客 ...
- Disruptor深入解读
将系统性能优化到极致,永远是程序爱好者所努力的一个方向.在java并发领域,也有很多的实践与创新,小到乐观锁.CAS,大到netty线程模型.纤程Quasar.kilim等.Disruptor是一个轻 ...
随机推荐
- net core Webapi基础工程搭建(四)——日志功能log4net
目录 前言 log4net 依然是,NuGet引用第三方类库 整合LogUtil 小结 前言 一个完整的项目工程离不开日志文件的记录,而记录文件的方法也有很多,可以自己通过Stream去实现文件的读写 ...
- 新手学习selenium路线图(老司机亲手绘制)
前言: 最近群里有不少小白,想入手selenium,但是一直没找到学习路线,还没入门就迷路了,于是小编亲手绘制了一幅学习路线图.希望能帮助小白快速入门,帮助已经入门的,尽快提升! 学习selenium ...
- jdk_Windows基础环境配置
JAVA环境配置 windows 系统环境变量配置: JAVA_HOME C:\Java\jdk1.8.0_25 Path %JAVA_HOME%\bin; classpath .;%JAVA_HOM ...
- Maven项目添加ojdbc8
1.找到Oracle中的ojdbc8,它的位置在Oracle客户端 2.找到它的位置后,把你放ojdbc8的位置复制,改如下代码"D:\ojdbc8.jar"为你的ojdbc8位置 ...
- HTML+JavaScript自己动手做日历
当我们需要在页面中显示某月的事项,或是选择某一段日期时,常常要使用到日历组件.这一组件同样有着许多现成的类库,然而亲自动手开发一个日历,从中了解其实现原理也是非常必要的.在本例中我们就将制作一款非常经 ...
- HDU 6363
题意略. 思路: 这里有两个结论需要注意: 1.gcd(a ^ x - 1,a ^ y - 1) = a ^ gcd(x,y) - 1 2.gcd(fib[x],fib[y]) = fib[gcd(x ...
- Leetcode之回溯法专题-90. 子集 II(Subsets II)
Leetcode之回溯法专题-90. 子集 II(Subsets II) 给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集). 说明:解集不能包含重复的子集. 示例: 输入 ...
- xib上的控件属性为什么要使用weak
常规中,从xib拖出一个控件时,系统会自动生成一段代码,如下: 从这个图片中,可以看到控件的属性都是用的weak,这是为什么呢? 首先,如果把weak修改成strong其实也是可以的,但是会出现一个问 ...
- 数据结构C线性表现实
linearList.h #ifndef _INC_STDIO_8787 #define _INC_STDIO_8787 #include <stdio.h> #include <m ...
- Linux的权限属性信息1到10位分别什么意思
要设置权限,就需要知道文件的一些基本属性和权限的分配规则. 在Linux中,ls命令常用来查看文件的属性,用于显示文件的文件名和相关属性. #ls -l 路径 [ls -l 等价于 ...