Python实现王者荣耀小助手(一)
简单来说网络爬虫,是指抓取万维网信息的程序或者脚本,Python在网络爬虫有很大优势,今天我们用Python实现获取王者荣耀相关数据,做一个小助手:
前期准备,环境搭建:
Python2.7
sys模块提供了许多函数和变量来处理 Python 运行时环境的不同部分;
urllib模块提供了一系列用于操作URL的功能,爬虫所需要的功能,基本上在urllib中都能找到,学习这个标准库,可以更加深入的理解后面更加便利的requests库;
requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多,因为是第三方库,所以使用前需要cmd命令安装,pip install requests ;
Python在GUI编程实现图形界面,Python 提供了多个图形开发界面的库,Tkinter,tkMessageBox;
首先获取英雄图片,代码如下:

# -*- coding: utf-8 -*-
#!/usr/bin/env python
# @Time : 2018/6/15 17:12
# @Desc :
# @File : KingGlory.py
# @Software: PyCharm
"""
导入库
"""
import urllib
import requests,sys
"""
统一编码
"""
reload(sys)
sys.setdefaultencoding('utf-8') """
获取英雄图片
"""
def DownloadHeroImage(url):
req=requests.get(url=url).json()
HeroNum=len(req['list'])
print "一共有%d个英雄"%HeroNum
HeroImagesPath="HeroiImages"
HeroList=req['list']
for Hero in HeroList:
HeroImageUrl=Hero['cover']
HeroName=Hero['name']+".jpg"
FileName=HeroImagesPath+"/"+HeroName
print "正在下载%s的图片"%Hero['name']
urllib.urlretrieve(url=HeroImageUrl, filename=FileName) 执行方法如下: if __name__ == '__main__':
# 英雄列表URL地址
heros_url = "http://gamehelper.gm825.com/wzry/hero/list?channel_id=90009a&app_id=h9044j&game_id=7622&game_name=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80&vcode=12.0.3&version_code=1203&cuid=2654CC14D2D3894DBF5808264AE2DAD7&ovr=6.0.1&device=Xiaomi_MI+5&net_type=1&client_id=1Yfyt44QSqu7PcVdDduBYQ%3D%3D&info_ms=fBzJ%2BCu4ZDAtl4CyHuZ%2FJQ%3D%3D&info_ma=XshbgIgi0V1HxXTqixI%2BKbgXtNtOP0%2Fn1WZtMWRWj5o%3D&mno=0&info_la=9AChHTMC3uW%2BfY8%2BCFhcFw%3D%3D&info_ci=9AChHTMC3uW%2BfY8%2BCFhcFw%3D%3D&mcc=0&clientversion=&bssid=VY%2BeiuZRJ%2FwaXmoLLVUrMODX1ZTf%2F2dzsWn2AOEM0I4%3D&os_level=23&os_id=dc451556fc0eeadb&resolution=1080_1920&dpi=480&client_ip=192.168.0.198&pdunid=a83d20d8"
DownloadHeroImage(heros_url)
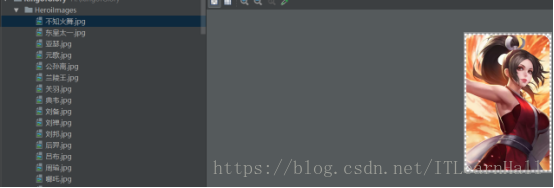
执行结果如下:

Python实现王者荣耀小助手(一)的更多相关文章
- Python实现王者荣耀小助手(二)
接下来我们获取英雄和武器信息,详细代码KingGlory.py如下(代码中有详细注解): # -*- coding: utf-8 -*- #!/usr/bin/env python # @Time : ...
- python爬虫王者荣耀高清皮肤大图背景故事通用爬虫
wzry-spider python通用爬虫-通用爬虫爬取静态网页,面向小白 基本上纯python语法切片索引,少用到第三方爬虫网络库 这是一只小巧方便,强大的爬虫,由python编写 主要实现了: ...
- python实现王者荣耀英图片收集
一个python写的小爬虫项目,爬虫相关的很容易写,关键是怎么找到爬取图片的位置. 图片位置分析 hero_list_url = 'http://pvp.qq.com/web201605/js/her ...
- 用python的requests第三方模块抓取王者荣耀所有英雄的皮肤
本文使用python的第三方模块requests爬取王者荣耀所有英雄的图片,并将图片按每个英雄为一个目录存入文件夹中,方便用作桌面壁纸 下面时具体的代码,已通过python3.6测试,可以成功运行: ...
- python 爬取王者荣耀高清壁纸
代码地址如下:http://www.demodashi.com/demo/13104.html 一.前言 打过王者的童鞋一般都会喜欢里边设计出来的英雄吧,特别想把王者荣耀的英雄的高清图片当成电脑桌面 ...
- Python3 类与对象之王者荣耀对战小游戏
王者荣耀对战小游戏 # 定义英雄: 亚瑟 class Arthur: hero_type = 'Tank' def __init__(self, attack_value=164, armor=98, ...
- 利用python爬取王者荣耀英雄皮肤图片
前两天看到同学用python爬下来LOL的皮肤图片,感觉挺有趣的,我也想试试,于是决定来爬一爬王者荣耀的英雄和皮肤图片. 首先,我们找到王者的官网http://pvp.qq.com/web201605 ...
- python学习--第二天 爬取王者荣耀英雄皮肤
今天目的是爬取所有英雄皮肤 在爬取所有之前,先完成一张皮肤的爬取 打开anacond调出编译器Jupyter Notebook 打开王者荣耀官网 下拉找到位于网页右边的英雄/皮肤 点击[+更多] 进入 ...
- 20行Python代码爬取王者荣耀全英雄皮肤
引言王者荣耀大家都玩过吧,没玩过的也应该听说过,作为时下最火的手机MOBA游戏,咳咳,好像跑题了.我们今天的重点是爬取王者荣耀所有英雄的所有皮肤,而且仅仅使用20行Python代码即可完成. 准备工作 ...
随机推荐
- 初识Django,了解一下大概流程
学习Django一个礼拜了,对其有了一个大概的了解,自己画了一个简单的图,虽然有点丑,但是基本上已经把自己所想已经表达 写完这篇随笔之后发现自己逻辑表述的有点不太清晰,有点乱,哪里不对,希望各位指正 ...
- js 判断对象是否为空
利用JSON.stringify var objData = {};JSON.stringify(objData) ==="{}" // true 第二种用原声js 方法 Obje ...
- 第一天 hello world 启程
#include<stdio.h> int main() { printf(" Hello world"); return 0; }
- Head First设计模式——观察者模式
1.气象监测应用,错误示范 有一个气象站,分别有三个装置:温度感应装置,湿度感应装置,气压感应装置.WeathData对象跟踪气象站数据,WeathData有MeasurmentsChanged()方 ...
- 一起来看一下Java中的Annotation注解
目录: 一. 什么是Annotation 二. Annotation的作用 2.1 编译器使用到的注解 2.2 .class文件使用到的注解 2.3 运行期读取的注解 三. 定义Annotation ...
- Myeclipse 反编译工具插件
JadClipse是java的反编译工具,是命令行执行,反编译出来的源文件可读性较高.可惜用起来不太方便.还好 找到myeclipse下的插件,叫JadClipse,安装好之后,只要双击.class文 ...
- hdfs 文件系统命令操作
hdfs 文件系统命令操作 [1]hdfs dfs -ls [目录]. 显示所有文件 hdfs dfs -ls -h /user/20170214.txt 显示文件时,文件大小以人易读的形式显示 [2 ...
- day07整理(内置方法\循环判断)
目录 一.上节课回顾 (一)if判断 1.单分支结构 2.双分支结构 3.多分支结构 (二)for循环 1.for + break 2.for + continue 3.for循环嵌套 (三)robu ...
- ajax同步请求与异步请求的区别
ajax 区别: async:布尔值,用来说明请求是否为异步模式.async是很重要的,因为它是用来控制JavaScript如何执行该请求. 当设置为true时,将以异步模式发送该请求,JavaScr ...
- 什么是Viewport
什么是Viewport 手机浏览器是把页面放在一个虚拟的“窗口”(viewport)中,通常这个虚拟的“窗口”(viewport)比屏幕宽,这样就不用把每个网页挤到很小的窗口中(这样会破坏没有针对手机 ...