程序员修神之路--用NOSql给高并发系统加速(送书)

随着互联网大潮的到来,越来越多网站,应用系统需要海量数据的支撑,高并发、低延迟、高可用、高扩展等要求在传统的关系型数据库中已经得不到满足,或者说关系型数据库应对这些需求已经显得力不从心了。关系型数据库经过几十年的发展已经很成熟,强大的sql语句支持,完美的ACID属性的支持,使得关系型数据库广泛应用于各种各样的应用系统中,但是应用的场景广泛并非意味着完美。
- 由于关系型数据库是按行进行存储的,在某些只统计一列的需求场景下,也需要把整行读入内存,导致了一个小小的统计需求高IO的缺点
- 关系型数据库无法存储数据结构,比如:一个商品可以从属于多个分类,业务上的从属关系体现到存储上是一个列表而已,但是关系型数据库需要把这些关系存储为多行,无法直接存储为一个列表。
- 关系型数据库中的存储单位表的架构是强约束,操作不存在的列会报出异常,而且添加、更新、删除列必须执行DDL语句,如果表的现存数据量比较大,会出现长时间锁表的现象。
- 关系型数据库全文搜索功能普通比较弱,用like去匹配关键词的时候,数据量比较大的情况下会出现慢查询的现象。
- 关系型数据库基于表格的关系模型使得很难添加新的或不同种类的关联信息。
由于以上这些诸多问题,便诞生了以“NOSQL”为口号的很多解决方案。在某些关系型数据库不擅长的领域,Nosql表现的很出色。上天是公平的,给你打开了一扇窗户,必会给你关上半扇门,NoSql是以牺牲ACID某个或者某些特性为代价的。

NoSQL并不是银弹,更多的时候是关系型数据库一个有力补充,或者是特定场景下优于关系型数据库的一种解决方案


NoSQL,泛指非关系型的数据库。现在大家更喜欢翻译成:not only sql

根据NoSQL的存储等特性,大体可以分为以下几类
- 键值(Key-Value)存储数据库。相关的产品:Redis、Riak、SimpleDB、Chordless、Scalaris、Memcached。主要解决关系数据库无法存储数据结构的问题。
- 列存储数据库。相关产品:BigTable、HBase、Cassandra、HadoopDB、GreenPlum、PNUTS。解决关系数据库大数据场景下的 I/O 问题
- 文档数据库。相关产品:MongoDB、CouchDB、ThruDB、CloudKit、Perservere、Jackrabbit。解决关系数据库强 schema 约束的问题。
- 图形数据库。相关产品:Neo4J、OrientDB、InfoGrid、GraphDB。主要解决大量复杂、互连接、低结构化的图结构场合,如社交网络、推荐系统等
- 全文搜索引擎。相关产品:Elasticsearch。主要解决关系数据库的全文搜索性能问题。
由此可见,没有哪一种NoSql是完美的,每一种Nosql都有自己擅长的领域,这也是我们做系统架构中要考虑的重要因素。
场景1
电商的商品设计过程中,每种商品的属性都不同,属性数目不同,属性名不同,同一个商品有可能会属于多个分类,而且随着业务的发展,很多商品会增加新的属性,而且最令程序员头疼莫过于每种属性都有可能有搜索的可能性(当然搜索可以利用搜索引擎来实现)。遇到这样的需求场景,如果利用关系型数据库来存储的话,表的字段会非常多,而且字段的定义非常令人头疼。
这样的场景非常适合NOsql中的文档型数据库,比如MongoDB。文档型数据库新增字段非常简单,不像关系型数据库需要先执行DDL来增加字段,直接可以利用程序来进行读写,历史数据就算是没有相应的字段也不会有异常的情况发生。最重要的一点,文档型数据库很擅长存储复杂结构的数据,一般情况下业务上可以利用表现能力很强的json数据结构。
{
"Id":1,
"ProductName":"杜蕾斯加强版",
"Price":100,
"Type":[
1,
2,
4
],
"Length":20,
"Height":2
}如果所有商品信息都用mongodb来存储的话,有的场景并不是十分完美。比如商品被成功购买之后扣库存的问题,联合查询的问题,由于Nosql天生对ACID支持不足的原因,一个事务性的操作很难在Nosql中实现,所以设计系统的时候在很多情况下是关系数据库+Nosql 来共同实现业务。
场景2
很多具体的业务中都有记录数据然后进行统计的需求场景,比如那些统计uv,pv的系统。日志型的数据量非常大,而且还有可能有峰值的出现,如果用关系型数据库来存储,很有可能在IO上会出现瓶颈,而且有可能会影响其他正常的业务,更不幸的是当执行统计语句的时候,性能更是差强人意。这样的日志型统计业务很适合HBase这样的列式Nosql,业务上要统计一天的uv,pv数据,HBase很适合统计某一列数据的场景,因为只需要把对应的列进行统计即可,不像关系型数据库那样需要把所有行都加载进内存,而且列式存储一般比行式存储拥有更大的压缩比例,占用的磁盘空间会更少。
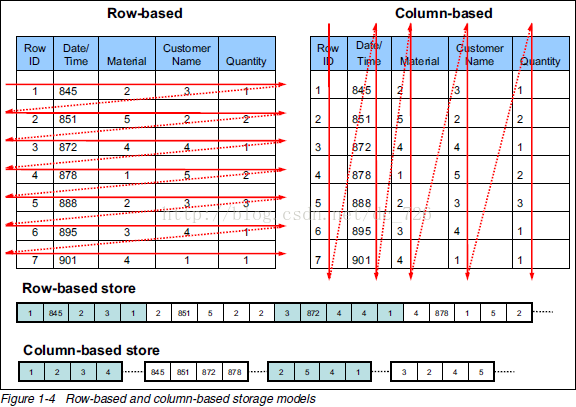
列式存储的应用场景有一定的限制,一般用于统计和大数据的分析中。
场景3
在多数高并发系统中都存在缓存的设计,而缓存的一般数据结构都是K-V结构。缓存是一种提高系统性能的有效手段,因其需要提供快速访问的特性,一般缓存都放置于内存当中。比如现在我们要设计一个用户管理系统,每个用户信息可以做缓存以便提供高速的访问,由于很多系统都采用分布式的部署方式,所以采用进程内的缓存方式并不可取,这个时候就需要有一种高速的外部存储来提供这种业务,这正是kv型Nosql的典型应用场景之一。其中以redis为代表,具体的业务中可以以用户id为key,用户的信息为value存储在redis中,而且redis在3.0之后可以做集群了,在高可用和扩展上更能助力业务方。redis支持的数据类型很多,在不同的场景下选择不同的数据类型。
场景4
当一个系统有搜索的业务时候,如果搜索的条件是一些简单的类型搜索,关系型数据库还可以满足,但是如果有全文搜索,就是我们平时sql写的like ‘%xx%’这样的搜索,关系型数据库可能并不是最好的选择,全文搜索引擎类型的Nosql也许是一个更好的解决方案,其中以Elasticsearch 为代表。全文搜索引擎的搜索的条件可以随意排列组合,并且可以实现关系型数据库like方式的模糊匹配。
全文搜索引擎的技术原理称为“倒排索引”(inverted index),是一种索引方法,其基本原理是建立单词到文档的索引。与之相对是,是“正排索引”,其基本原理是建立文档到单词的索引。
场景5
在社交系统中最常见例子就是社会网络中人与人之间的关系。关系型数据库用于存储“关系型”数据的效果并不好,其查询复杂、缓慢、超出预期,而图形数据库的独特设计恰恰弥补了这个缺陷,解决关系型数据库存储和处理复杂关系型数据功能较弱的问题。其中以Neo4j为代表。想深入研究的同学请移步百度。
无论是关系型数据库还是nosql数据库都不是银弹,每一种事物都有它最善长的领域。设计一个好的系统,需要综合考虑各种因素,根据具体的业务场景来选择最合适的解决方案。


记得微信扫码识别,领取技术书籍哦

程序员修神之路--用NOSql给高并发系统加速(送书)的更多相关文章
- 程序员修神之路--kubernetes是微服务发展的必然产物
菜菜哥,我昨天又请假出去面试了 战况如何呀? 多数面试题回答的还行,但是最后让我介绍微服务和kubernetes的时候,挂了 话说微服务和kubernetes内容确实挺多的 那你给我大体介绍一下呗 可 ...
- 程序员修神之路--redis做分布式锁可能不那么简单
菜菜哥,复联四上映了,要不要一起去看看? 又想骗我电影票,对不对? 呵呵,想去看了叫我呀 看来你工作不饱和呀 哪有,这两天我刚基于redis写了一个分布式锁,很简单 不管你基于什么做分布式锁,你觉得很 ...
- 程序员修神之路--🤠分布式高并发下Actor模型如此优秀🤠
写在开始 一般来说有两种策略用来在并发线程中进行通信:共享数据和消息传递.使用共享数据方式的并发编程面临的最大的一个问题就是数据条件竞争.处理各种锁的问题是让人十分头痛的一件事. 传统多数流行的语言并 ...
- 程序员修神之路--设计一套RPC框架并非易事
菜菜哥,我最近终于把Socket通信调通了 这么底层的东西你现在都会了,恭喜你离涨薪又进一步呀 http协议不也是利用的Socket吗 可以这么说,http协议是基于TCP协议的,底层的数据传输可以说 ...
- 程序员修神之路--为什么有了SOA,我们还用微服务?
菜菜哥,我最近需要做一个项目,老大让我用微服务的方式来做 那挺好呀,微服务现在的确很流行 我以前在别的公司都是以SOA的方式,SOA也是面向服务的方式呀 的确,微服务和SOA有相同之处 面向服务的架构 ...
- 程序员修神之路--打通Docker镜像发布容器运行流程
菜菜哥,我看了一下docker相关的内容,但是还是有点迷糊 还有哪不明白呢? 如果我想用docker实现所谓的云原生,我的项目该怎么发布呢? 这还是要详细介绍一下docker了 Docker 是一个开 ...
- 程序员修仙之路--优雅快速的统计千万级别uv(留言送书)
菜菜,咱们网站现在有多少PV和UV了? Y总,咱们没有统计pv和uv的系统,预估大约有一千万uv吧 写一个统计uv和pv的系统吧 网上有现成的,直接接入一个不行吗? 别人的不太放心,毕竟自己写的,自己 ...
- 程序员修仙之路--优雅快速的统计千万级别uv
菜菜,咱们网站现在有多少PV和UV了? Y总,咱们没有统计pv和uv的系统,预估大约有一千万uv吧 写一个统计uv和pv的系统吧 网上有现成的,直接接入一个不行吗? 别人的不太放心,毕竟自己写的,自己 ...
- 程序员修仙之路- CXO让我做一个计算器!!
菜菜呀,个税最近改革了,我得重新计算你的工资呀,我需要个计算器,你开发一个吧 CEO,CTO,CFO于一身的CXO X总,咱不会买一个吗? 菜菜 那不得花钱吗,一块钱也是钱呀··这个计算器支持加减乘除 ...
随机推荐
- VS2013日常使用若干技巧+快捷键
1.注释的方法 1)sqlserver中,单行注释:— — 多行注释:/* 代码 */ 2)C#中,单行注释:// 多行注释:/* 代码 */ 3)C#中多行注释的快捷方式:先选中你要注 ...
- 在?MySQL事务隔离级别了解一下?
事务的四大ACID 属性:Atomicity 原子性.Consistency 一致性.Isolation 隔离性.Durability 持久性. 原子性: 事务是最小的执行单位不可分割,强调事务的不可 ...
- 跟着大彬读源码 - Redis 3 - 服务器如何响应客户端请求?(下)
继续我们上一节的讨论.服务器启动了,客户端也发送命令了.接下来,就要到服务器"表演"的时刻了. 1 服务器处理 服务器读取到命令请求后,会进行一系列的处理. 1.1 读取命令请求 ...
- BASE64Encoder及BASE64Decoder的正确用法
一直以来Base64的加密解密都是使用sun.misc包下的BASE64Encoder及BASE64Decoder的sun.misc.BASE64Encoder/BASE64Decoder类.这人个类 ...
- java接口自动化(一) - 接口自动化测试整体认知 - 开山篇(超详解)
简介 了解什么是接口和为什么要做接口测试.并且知道接口自动化测试应该学习哪些技术以及接口自动化测试的落地过程.其实这些基本上在python接口自动化的文章中已经详细的介绍过了,不清楚的可以过去看看.了 ...
- U盘被写保护大全解
相信大家的U盘在使用的过程中多或少都有出现过一些问题,写保护,程序写蹦而造成的逻辑错误,或者在使用过程中因电脑而中毒,内部零件损伤等等各种各样倒霉的错误. 简单了解一下是个什么东西吧.U盘写保护其实就 ...
- MyBatis从入门到精通(1):MyBatis入门
作为一个自学Java的自动化专业211大学本科生,在学习和实践过程中"趟了不少雷",所以有志于建立一个适合同样有热情学习Java技术的参考"排雷手册". 最近在 ...
- 2019暑假集训 Intervals
题目描述 给定n个闭区间[ai,bi]和n个整数ci.你需要构造一个整数集合Z,使得对于任意i,Z中满足ai<=x<=bi的x不少于ci个.求Z集合中包含的元素个数的最小值. 输入 第一 ...
- 【模拟】(正解树状数组)-校长的问题-C++-计蒜客
描述 学校中有 n 名学生,学号分别为 1 - n.再一次考试过后,学校按照学生的分数排了一个名次(分数一样,按照名字的字典序排序).你是一名老师,你明天要和校长汇报这次考试的考试情况,校长询问的方式 ...
- Android问题解决
1.clean之后R文件消失 clean之后R文件消失是因为布局的XML文件存在错误,无法编译你的资源文件,所以无法自动生成R文件,在Problem.LogCat等界面查看错误的原因,把错误改正即可: ...