redis分享
Redis介绍
port 7000:服务端口。
daemonize yes:修改服务为后台运行。
pidfile /var/run/redis_7000.pid:指定不同的pid文件。
logfile "/var/redis/7000.log":指定log日志路径。
dir /opt/redis-cluster/redis-7000:这个指定rdb,aof文件的路径配置。
requirepass ibethfy:客户端访问需要密码验证。
scan cursor [match pattern] [count number]
cursor是必需参数,实际上cursor是一个游标,第一次遍历从0开始,每
次scan遍历完都会返回当前游标的值,直到游标值为0,表示遍历结束。
match pattern是可选参数,它的作用的是做模式的匹配,这点和keys的模式匹配很像。
count number是可选参数,它的作用是表明每次要遍历的键个数,默认值是10,此参数可以适当增大
scan 0 match * count 3
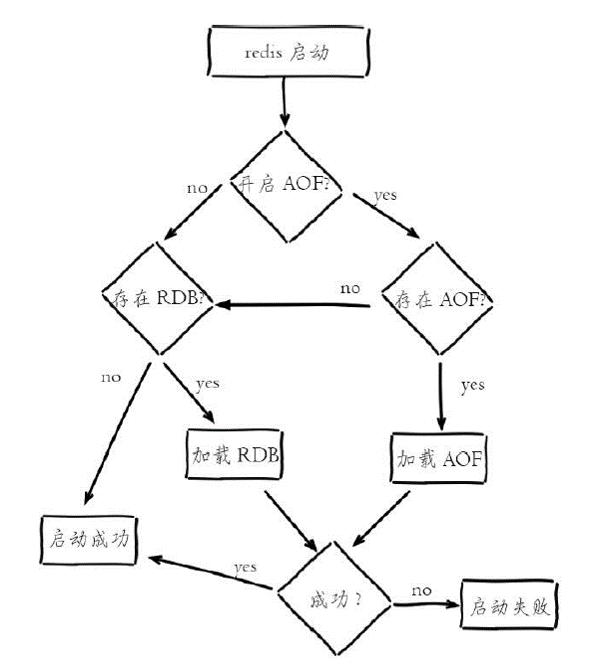
1、使用save相关配置,如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。可配置多个。
2、如果从节点执行全量复制操作,主节点自动执行bgsave生成RDB文件并发送给从节点。
3、执行debug reload命令重新加载Redis时,也会自动触发save操作。
4、默认情况下执行shutdown命令时,如果没有开启AOF持久化功能则自动执行bgsave。
bgsave流程:
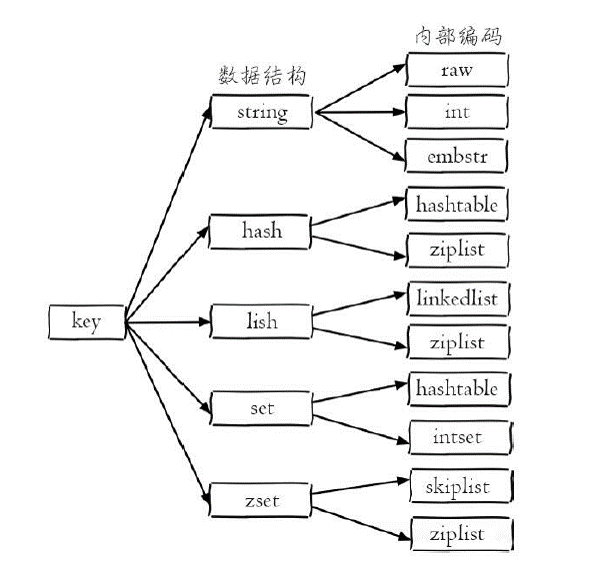
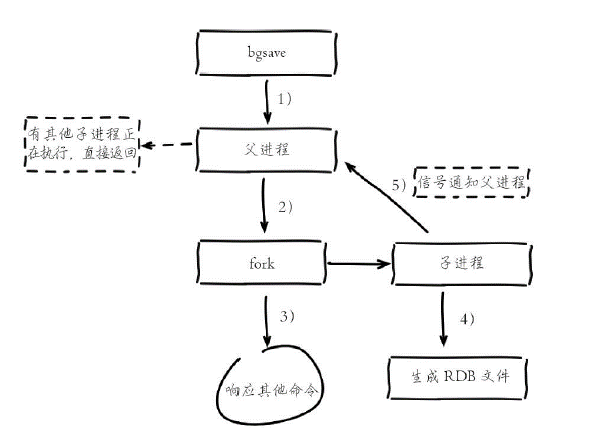
1)执行bgsave命令,Redis父进程判断当前是否存在正在执行的子进程,如RDB/AOF子进程,如果存在bgsave命令直接返回。
2)父进程执行fork操作创建子进程,fork操作过程中父进程会阻塞,通过info stats命令查看latest_fork_usec选项,可以获取最近一个fork操作的耗时,单位为微秒。
3)父进程fork完成后,bgsave命令返回“Background saving started”信息并不再阻塞父进程,可以继续响应其他命令。
4)子进程创建RDB文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换。执行lastsave命令可以获取最后一次生成RDB的时间,对应info统计的rdb_last_save_time选项。
5)进程发送信号给父进程表示完成,父进程更新统计信息。
RDB优缺点
优点
缺点

Redis使用单线程响应命令,如果每次写AOF文件命令都直接追加到硬盘,那么性能完全取决于当前硬盘负载。先写入缓冲区aof_buf中,还有另一个好处,Redis可以提供多种缓冲区同步硬盘的策略,在性能和安全性方面做出平衡。
AOF重写触发机制
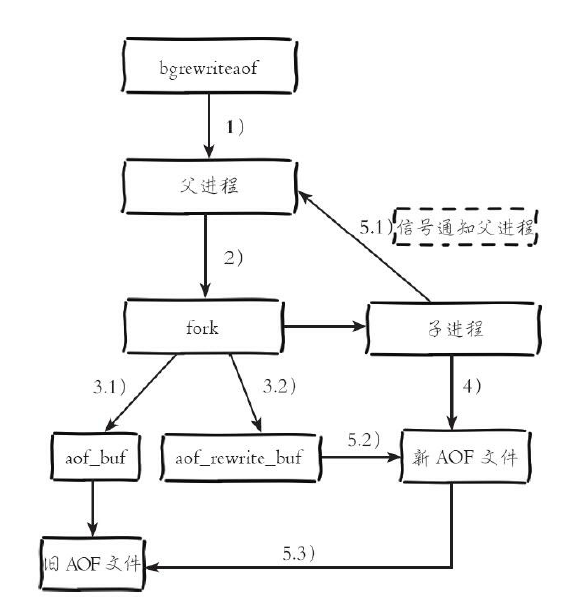
1)执行AOF重写请求。
如果当前进程正在执行AOF重写,请求不执行并返回如下响应:
ERR Background append only file rewriting already in progress
334
如果当前进程正在执行bgsave操作,重写命令延迟到bgsave完成之后再
执行,返回如下响应:
Background append only file rewriting scheduled
2)父进程执行fork创建子进程,开销等同于bgsave过程。
3.1)主进程fork操作完成后,继续响应其他命令。所有修改命令依然写
入AOF缓冲区并根据appendfsync策略同步到硬盘,保证原有AOF机制正确
性。
3.2)由于fork操作运用写时复制技术,子进程只能共享fork操作时的内
存数据。由于父进程依然响应命令,Redis使用“AOF重写缓冲区”保存这部
分新数据,防止新AOF文件生成期间丢失这部分数据。
4)子进程根据内存快照,按照命令合并规则写入到新的AOF文件。每
次批量写入硬盘数据量由配置aof-rewrite-incremental-fsync控制,默认为
32MB,防止单次刷盘数据过多造成硬盘阻塞。
5.1)新AOF文件写入完成后,子进程发送信号给父进程,父进程更新
统计信息,具体见info persistence下的aof_*相关统计。
5.2)父进程把AOF重写缓冲区的数据写入到新的AOF文件。
5.3)使用新AOF文件替换老文件,完成AOF重写。
集群扩容
集群迁移
redis分享的更多相关文章
- 【无私分享:ASP.NET CORE 项目实战(第十一章)】Asp.net Core 缓存 MemoryCache 和 Redis
目录索引 [无私分享:ASP.NET CORE 项目实战]目录索引 简介 经过 N 久反复的尝试,翻阅了网上无数的资料,GitHub上下载了十几个源码参考, Memory 和 Redis 终于写出一个 ...
- 国内外三个不同领域巨头分享的Redis实战经验及使用场景
Redis不是比较成熟的memcache或者Mysql的替代品,是对于大型互联网类应用在架构上很好的补充.现在有越来越多的应用也在纷纷基于Redis做架构的改造.首先简单公布一下Redis平台实际情况 ...
- 自己编写redis客户端[deerlet-redis-client],分享与招募。
引言 最近工作上有需要使用redis,于是便心血来潮打算自己写一个Java客户端.经过两天的努力,目前该客户端已经基本成型.不过可惜的是,由于redis的命令众多,因此LZ还需要慢慢扩展它去支持更多的 ...
- (转)国内外三个不同领域巨头分享的Redis实战经验及使用场景
随着应用对高性能需求的增加,NoSQL逐渐在各大名企的系统架构中生根发芽.这里我们将为大家分享社交巨头新浪微博.传媒巨头Viacom及图片分享领域佼佼者Pinterest带来的Redis实践,首先我们 ...
- Session for Tornado(Redis) - 代码分享
Session for Tornado(Redis) - 代码分享 Session for Tornado(Redis) session id的生成借用了web.py. 使用了 redis 的 h ...
- 做个简单的Redis监控(源码分享)
Redis监控 Redis 是目前应用广泛的NoSQL,我做的项目中大部分都是与Redis打交道,发现身边的朋友也更多人在用,相对于memcached 来说,它的优势也确实是可圈可点.在随着业务,数据 ...
- Redis基本使用及百亿数据量中的使用技巧分享(附视频地址及观看指南)
作者:依乐祝 原文地址:https://www.cnblogs.com/yilezhu/p/9941208.html 主讲人:大石头 时间:2018-11-10 晚上20:00 地点:钉钉群(组织代码 ...
- 知乎技术分享:从单机到2000万QPS并发的Redis高性能缓存实践之路
本文来自知乎官方技术团队的“知乎技术专栏”,感谢原作者陈鹏的无私分享. 1.引言 知乎存储平台团队基于开源Redis 组件打造的知乎 Redis 平台,经过不断的研发迭代,目前已经形成了一整套完整自动 ...
- [翻译] C# 8.0 新特性 Redis基本使用及百亿数据量中的使用技巧分享(附视频地址及观看指南) 【由浅至深】redis 实现发布订阅的几种方式 .NET Core开发者的福音之玩转Redis的又一傻瓜式神器推荐
[翻译] C# 8.0 新特性 2018-11-13 17:04 by Rwing, 1179 阅读, 24 评论, 收藏, 编辑 原文: Building C# 8.0[译注:原文主标题如此,但内容 ...
随机推荐
- seaborn总结
Seaborn 数据可视化基础 介绍 Matplotlib 是支持 Python 语言的开源绘图库,因为其支持丰富的绘图类型.简单的绘图方式以及完善的接口文档,深受 Python 工程师.科研学者.数 ...
- iOS---------开发中 weak和assign的区别
weak和assign的区别-正确使用weak.assign 一.区别 1.修饰变量类型的区别weak只可以修饰对象.如果修饰基本数据类型,编译器会报错-“Property with ‘weak’ a ...
- Playbook剧本初识
目录 1.Playbook剧本初识 2.Playbook变量使用 3.Playbook变量注册 4.Playbook条件语句 5.Playbook循环语句 6.Playbook异常处理 7.Playb ...
- 26-限制容器对CPU的使用
默认设置下,所有容器可以平等地使用 host CPU 资源并且没有限制. Docker 可以通过 -c 或 --cpu-shares 设置容器使用 CPU 的权重.如果不指定,默认值为 1024. 与 ...
- 微信小程序中换行,空格(多个空格)写法
在小程序中HTML的网页实体无法正常使用,小程序中的写法为: 一.空格,换行 <text>你好!\t七月流火啊!\n我在下一行</text> \t 空格( 多个只会显示一个空格 ...
- 示例:Oracle表锁、行锁模拟和处理
for update模拟锁表 --session 1 SQL> select * from tt for update; --session 2 SQL> update tt set id ...
- Master Note: Undo 空间使用率高 (Doc ID 1578639.1)
Master Note: High Undo Space Usage (Doc ID 1578639.1) APPLIES TO: Oracle Database Cloud Schema Servi ...
- 以太网驱动的流程浅析(五)-mii_bus初始化以及phy id的获取【原创】
以太网驱动的流程浅析(五)-mii_bus初始化以及phy id的获取 Author:张昺华 Email:920052390@qq.com Time:2019年3月23日星期六 此文也在我的个人公众号 ...
- java8-10-Stream的终止操作
Stream的终止操作 * allMatch 是否匹配所有 * anyMatch 是否匹配一个 * noneMatch 是否没有匹配一个 * findFirst 返回第一个 * count ...
- Builder模式的演示
Builder模式的演示 package com.mozq.mb.mb01.pojo; /* 类的某些参数给出了默认值,但是一旦设置了就不可变.使用Builder模式来创建. */ public cl ...