oralce学习笔记(二)
分区清理:
--范围分区示例
drop table range_part_tab purge;
--注意,此分区为范围分区
create table range_part_tab (id number,deal_date date,area_code number,contents varchar2(4000))
partition by range (deal_date)
(
partition p1 values less than (TO_DATE('2012-02-01', 'YYYY-MM-DD')),
partition p2 values less than (TO_DATE('2012-03-01', 'YYYY-MM-DD')),
partition p3 values less than (TO_DATE('2012-04-01', 'YYYY-MM-DD')),
partition p4 values less than (TO_DATE('2012-05-01', 'YYYY-MM-DD')),
partition p5 values less than (TO_DATE('2012-06-01', 'YYYY-MM-DD')),
partition p6 values less than (TO_DATE('2012-07-01', 'YYYY-MM-DD')),
partition p7 values less than (TO_DATE('2012-08-01', 'YYYY-MM-DD')),
partition p8 values less than (TO_DATE('2012-09-01', 'YYYY-MM-DD')),
partition p9 values less than (TO_DATE('2012-10-01', 'YYYY-MM-DD')),
partition p10 values less than (TO_DATE('2012-11-01', 'YYYY-MM-DD')),
partition p11 values less than (TO_DATE('2012-12-01', 'YYYY-MM-DD')),
partition p12 values less than (TO_DATE('2013-01-01', 'YYYY-MM-DD')),
partition p_max values less than (maxvalue)
)
; --以下是插入2012年一整年日期随机数和表示福建地区号含义(591到599)的随机数记录,共有10万条,如下:
insert into range_part_tab (id,deal_date,area_code,contents)
select rownum,
to_date( to_char(sysdate-365,'J')+TRUNC(DBMS_RANDOM.VALUE(0,365)),'J'),
ceil(dbms_random.value(590,599)),
rpad('*',400,'*')
from dual
connect by rownum <= 100000;
commit; --分区原理分析之普通表插入
drop table norm_tab purge;
create table norm_tab (id number,deal_date date,area_code number,contents varchar2(4000));
insert into norm_tab(id,deal_date,area_code,contents)
select rownum,
to_date( to_char(sysdate-365,'J')+TRUNC(DBMS_RANDOM.VALUE(0,365)),'J'),
ceil(dbms_random.value(590,599)),
rpad('*',400,'*')
from dual
connect by rownum <= 100000;
commit; --观察范围分区表的分区消除带来的性能优势
set linesize 1000
set autotrace traceonly
set timing on
select *
from range_part_tab
where deal_date >= TO_DATE('2012-09-04', 'YYYY-MM-DD')
and deal_date <= TO_DATE('2012-09-07', 'YYYY-MM-DD'); --比较相同语句,普通表无法用到DEAL_DATE条件进行分区消除的情况
select *
from norm_tab
where deal_date >= TO_DATE('2012-09-04', 'YYYY-MM-DD')
and deal_date <= TO_DATE('2012-09-07', 'YYYY-MM-DD'); --分区原理分析之普通表与分区表在段分配上的差异
SET LINESIZE 666
set pagesize 5000
column segment_name format a20
column partition_name format a20
column segment_type format a20
select segment_name,
partition_name,
segment_type,
bytes / 1024 / 1024 "字节数(M)",
tablespace_name
from user_segments
where segment_name IN('RANGE_PART_TAB','NORM_TAB');
分区表的性能:

普通表:

把一个表分成了多个段,提高了性能。
避免SQL中的函数调用:
drop table people purge;
drop table sex purge; create table people (first_name varchar2(200),last_name varchar2(200),sex_id number);
create table sex (name varchar2(20), sex_id number);
insert into people (first_name,last_name,sex_id) select object_name,object_type,1 from dba_objects;
insert into sex (name,sex_id) values ('男',1);
insert into sex (name,sex_id) values ('女',2);
insert into sex (name,sex_id) values ('不详',3);
commit; create or replace function get_sex_name(p_id sex.sex_id%type) return sex.name%type is
v_name sex.name%type;
begin
select name
into v_name
from sex
where sex_id=p_id;
return v_name;
end;
/ 以下两种写法是等价的,都是为了查询people 表信息,同时通过sex 表,获取人员的性别 信息。
select sex_id,
first_name||' '||last_name full_name,
get_sex_name(sex_id) gender
from people; select p.sex_id,
p.first_name||' '||p.last_name full_name,
sex.name
from people p, sex
where sex.sex_id=p.sex_id;
但是通过autotrace 比较观察发现两种写法性能上存在巨大差异
第一种:

第二种:

表连接的性能一定比函数调用的高。
减少SQL中的函数调用:
drop table t1 purge;
drop table t2 purge;
create table t1 as select * from dba_objects;
create table t2 as select * from dba_objects;
update t2 set object_id=rownum;
commit; create or replace function f_deal1(p_name in varchar2)
return varchar2 deterministic
is
v_name varchar2(200);
begin
-- select substr(upper(p_name),1,4) into v_name from dual;
v_name:=substr(upper(p_name),1,4);
return v_name;
end;
/ create or replace function f_deal2(p_name in varchar2)
return varchar2 deterministic
is
v_name varchar2(200);
begin
select substr(upper(p_name),1,4) into v_name from dual;
-- v_name:=substr(upper(p_name),1,4);
return v_name;
end;
/ set autotrace traceonly statistics
set linesize 1000 select * from t1 where f_deal1(object_name)='FILE';
select * from t1 where f_deal2(object_name)='FILE' ; CREATE INDEX IDX_OBJECT_NAME ON T1(f_deal2(object_name)); select * from t1 where f_deal2(object_name)='FILE' ; select f_deal1(object_name) from t1 ;
select f_deal2(object_name) from t1 ; select f_deal2(t1.object_name)
from t1, t2
where t1.object_id = t2.object_id
and t2.object_type LIKE '%PART%'; select *
from t2, (select f_deal2(t1.object_name), object_ID from t1) t
where t2.object_id = t.object_id
and t2.object_type LIKE '%PART%'; select name from (select rownum rn ,f_deal2(t1.object_name) name from t1) where rn>=10 and rn<=12;
select name from (select rownum rn ,f_deal2(t1.object_name) name from t1 where rownum<=12) where rn>=10 ; select name from (select rownum rn ,f_deal2(t1.object_name) name from t1) where rn<=12;
select f_deal2(t1.object_name) name from t1 where rownum<=12; select f_deal2(t1.object_name) name from t1 where object_id=9999999999999;
select * from t1 where f_deal2(t1.object_name)='AAAA'
select * from t1 where f_deal1(t1.object_name)='AAAA'
性能对比:

集合写法提高性能。
create or replace procedure proc_insert
as
begin
for i in 1 .. 100000
loop
insert into t values (i);
end loop;
commit;
end;
/ drop table t purge;
create table t ( x int );
set timing on
begin
for i in 1 .. 100000
loop
insert into t values (i);
end loop;
commit;
end;
/ --集合写法改造: drop table t purge;
create table t ( x int );
insert into t select rownum from dual connect by level<=100000;
commit;
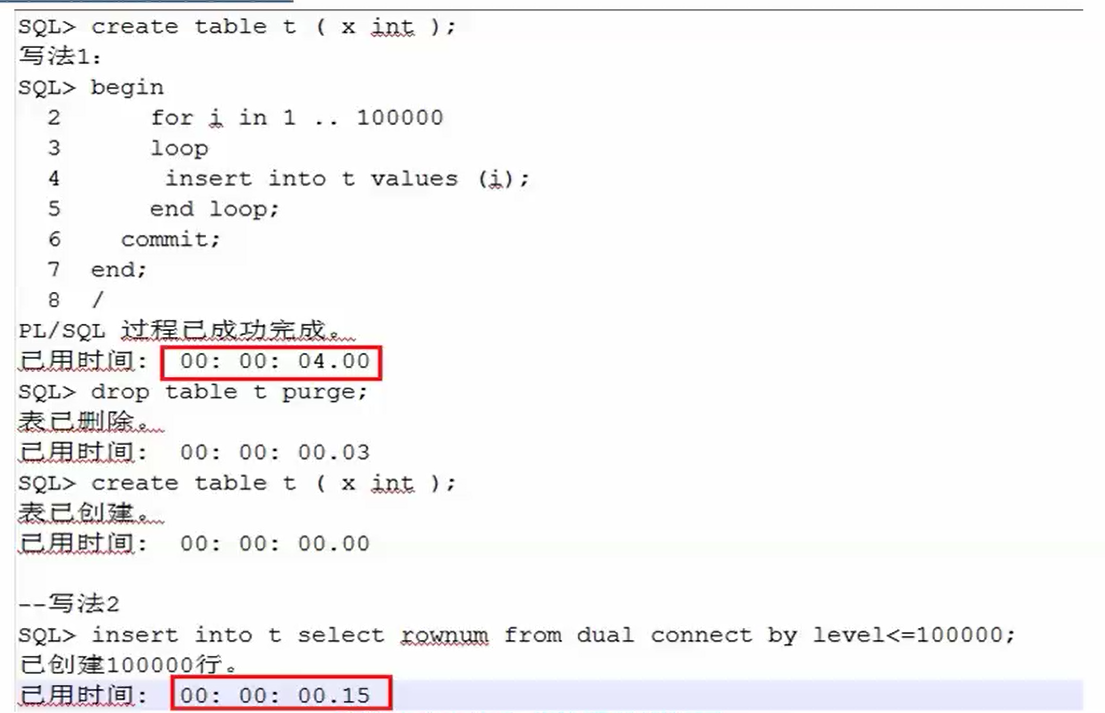
只取你需要的列,访问视图变的更快。
drop table t1 cascade constraints purge;
drop table t2 cascade constraints purge;
create table t1 as select * from dba_objects;
create table t2 as select * from dba_objects where rownum<=10000;
update t1 set object_id=rownum ;
update t2 set object_id=rownum ;
commit; create or replace view v_t1_join_t2
as select t2.object_id,t2.object_name,t1.object_type,t1.owner from t1,t2
where t1.object_id=t2.object_id; set autotrace traceonly
set linesize 1000
select * from v_t1_join_t2;
select object_id,object_name from v_t1_join_t2; alter table T1 add constraint pk_object_id primary key (OBJECT_ID);
alter table T2 add constraint fk_objecdt_id foreign key (OBJECT_ID) references t1 (OBJECT_ID);

只取你所需的列,索引无需回表。
drop table t purge;
create table t as select * from dba_objects;
create index idx_object_id on t(object_id,object_type); set linesize 1000
set autotrace traceonly
select object_id,object_type from t where object_id=28;
/
select * from t where object_id=28;
/
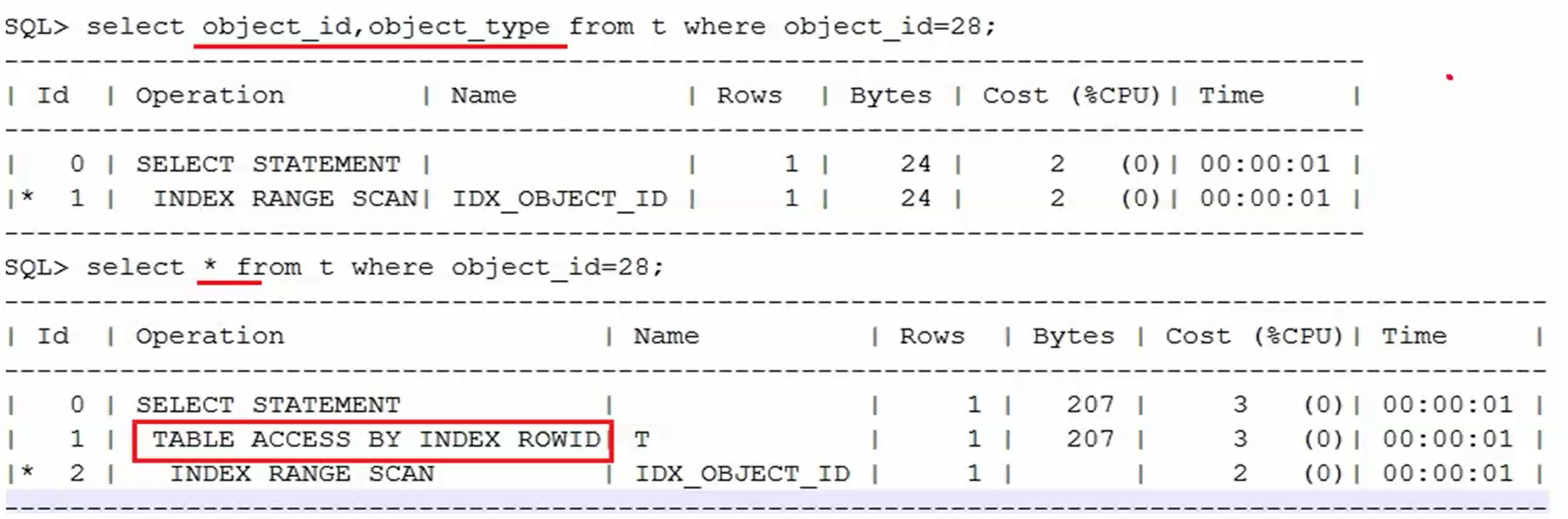
只取所需要的列,表连接提速了。
--环境构造
--研究Nested Loops Join访问次数前准备工作
DROP TABLE t1 CASCADE CONSTRAINTS PURGE;
DROP TABLE t2 CASCADE CONSTRAINTS PURGE;
CREATE TABLE t1 (
id NUMBER NOT NULL,
n NUMBER,
contents VARCHAR2(4000)
)
;
CREATE TABLE t2 (
id NUMBER NOT NULL,
t1_id NUMBER NOT NULL,
n NUMBER,
contents VARCHAR2(4000)
)
;
execute dbms_random.seed(0);
INSERT INTO t1
SELECT rownum, rownum, dbms_random.string('a', 50)
FROM dual
CONNECT BY level <= 100
ORDER BY dbms_random.random;
INSERT INTO t2 SELECT rownum, rownum, rownum, dbms_random.string('b', 50) FROM dual CONNECT BY level <= 100000
ORDER BY dbms_random.random;
COMMIT;
select count(*) from t1;
select count(*) from t2; --Merge Sort Join取所有字段的情况
alter session set statistics_level=all ;
set linesize 1000
SELECT /*+ leading(t2) use_merge(t1)*/ *
FROM t1, t2
WHERE t1.id = t2.t1_id; select * from table(dbms_xplan.display_cursor(null,null,'allstats last')); ---Merge Sort Join取部分字段的情况
SELECT /*+ leading(t2) use_merge(t1)*/ t1.id
FROM t1, t2
WHERE t1.id = t2.t1_id;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));

改写以下sql语句:
IDEP的SQL语句。
该语句存在性能问题,执行非常缓慢,极耗CPU,为了实现行列转换的需求,具体如下:
select distinct to_char(a.svcctx_id),
to_char(0),
to_char(nvl((select peer_id
from dcc_ne_config
where peer_name = a.peer),
0)),
to_char(a.priority),
to_char(nvl((select peer_id
from dcc_ne_config
where peer_name = b.peer),
0)),
to_char(b.priority),
to_char(nvl((select peer_id
from dcc_ne_config
where peer_name = c.peer),
0)),
to_char(c.priority)
from (select hopbyhop,
svcctx_id,
substr(cause,
instr(cause, 'Host = ') + 7,
instr(cause, 'Priority = ') - instr(cause, 'Host = ') - 11) peer,
substr(cause,
instr(cause, 'Priority = ') + 11,
instr(cause, 'reachable = ') -
instr(cause, 'Priority = ') - 13) priority
from dcc_sys_log
where cause like '%SC路由应答%'
and hopbyhop in (select distinct hopbyhop from dcc_sys_log)) a,
(select hopbyhop,
svcctx_id,
substr(cause,
instr(cause, 'Host = ') + 7,
instr(cause, 'Priority = ') - instr(cause, 'Host = ') - 11) peer,
substr(cause,
instr(cause, 'Priority = ') + 11,
instr(cause, 'reachable = ') -
instr(cause, 'Priority = ') - 13) priority
from dcc_sys_log
where cause like '%SC路由应答%'
and hopbyhop in (select distinct hopbyhop from dcc_sys_log)) b,
(select hopbyhop,
svcctx_id,
substr(cause,
instr(cause, 'Host = ') + 7,
instr(cause, 'Priority = ') - instr(cause, 'Host = ') - 11) peer,
substr(cause,
instr(cause, 'Priority = ') + 11,
instr(cause, 'reachable = ') -
instr(cause, 'Priority = ') - 13) priority
from dcc_sys_log
where cause like '%SC路由应答%'
and hopbyhop in (select distinct hopbyhop from dcc_sys_log)) c
where a.hopbyhop = b.hopbyhop
and a.hopbyhop = c.hopbyhop
and a.peer <> b.peer
and a.peer <> c.peer
and b.peer <> c.peer
and a.priority <> b.priority
and a.priority <> c.priority
and b.priority <> c.priority 执行计划: Execution Plan
----------------------------------------------------------
Plan hash value: 408096778 --------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1941 | 159K| | 18E(100)|999:59:59 |
|* 1 | TABLE ACCESS FULL | DCC_NE_CONFIG | 1 | 28 | | 3 (0)| 00:00:01 |
|* 2 | TABLE ACCESS FULL | DCC_NE_CONFIG | 1 | 28 | | 3 (0)| 00:00:01 |
|* 3 | TABLE ACCESS FULL | DCC_NE_CONFIG | 1 | 28 | | 3 (0)| 00:00:01 |
| 4 | HASH UNIQUE | | 1941 | 159K| | 18E(100)|999:59:59 |
| 5 | MERGE JOIN | | 18E| 15E| | 18E(100)|999:59:59 |
| 6 | MERGE JOIN | | 18E| 15E| | 32P(100)|999:59:59 |
| 7 | MERGE JOIN | | 1147T| 79P| | 1018T(100)|999:59:59 |
| 8 | SORT JOIN | | 746T| 36P| 85P| 101G (95)|999:59:59 |
|* 9 | HASH JOIN | | 746T| 36P| 70M| 4143M(100)|999:59:59 |
| 10 | TABLE ACCESS FULL | DCC_SYS_LOG | 4939K| 14M| | 14325 (1)| 00:02:52 |
|* 11 | HASH JOIN | | 151M| 7530M| 8448K| 366K (93)| 01:13:19 |
|* 12 | TABLE ACCESS FULL| DCC_SYS_LOG | 246K| 5547K| | 14352 (2)| 00:02:53 |
|* 13 | TABLE ACCESS FULL| DCC_SYS_LOG | 246K| 6994K| | 14352 (2)| 00:02:53 |
|* 14 | FILTER | | | | | | |
|* 15 | SORT JOIN | | 246K| 5547K| 15M| 16046 (2)| 00:03:13 |
|* 16 | TABLE ACCESS FULL | DCC_SYS_LOG | 246K| 5547K| | 14352 (2)| 00:02:53 |
|* 17 | SORT JOIN | | 4939K| 14M| 113M| 27667 (2)| 00:05:32 |
| 18 | TABLE ACCESS FULL | DCC_SYS_LOG | 4939K| 14M| | 14325 (1)| 00:02:52 |
|* 19 | SORT JOIN | | 4939K| 14M| 113M| 27667 (2)| 00:05:32 |
| 20 | TABLE ACCESS FULL | DCC_SYS_LOG | 4939K| 14M| | 14325 (1)| 00:02:52 |
-------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 1 - filter("PEER_NAME"=SUBSTR(:B1,INSTR(:B2,'Host = ')+7,INSTR(:B3,'Priority =
')-INSTR(:B4,'Host = ')-11))
2 - filter("PEER_NAME"=SUBSTR(:B1,INSTR(:B2,'Host = ')+7,INSTR(:B3,'Priority =
')-INSTR(:B4,'Host = ')-11))
3 - filter("PEER_NAME"=SUBSTR(:B1,INSTR(:B2,'Host = ')+7,INSTR(:B3,'Priority =
')-INSTR(:B4,'Host = ')-11))
9 - access("HOPBYHOP"="HOPBYHOP")
11 - access("HOPBYHOP"="HOPBYHOP")
filter(SUBSTR("CAUSE",INSTR("CAUSE",'Host = ')+7,INSTR("CAUSE",'Priority =
')-INSTR("CAUSE",'Host = ')-11)<>SUBSTR("CAUSE",INSTR("CAUSE",'Host =
')+7,INSTR("CAUSE",'Priority = ')-INSTR("CAUSE",'Host = ')-11) AND
SUBSTR("CAUSE",INSTR("CAUSE",'Priority = ')+11,INSTR("CAUSE",'reachable =
')-INSTR("CAUSE",'Priority = ')-13)<>SUBSTR("CAUSE",INSTR("CAUSE",'Priority =
')+11,INSTR("CAUSE",'reachable = ')-INSTR("CAUSE",'Priority = ')-13))
12 - filter("CAUSE" LIKE '%SC路由应答%')
13 - filter("CAUSE" LIKE '%SC路由应答%')
14 - filter(SUBSTR("CAUSE",INSTR("CAUSE",'Host = ')+7,INSTR("CAUSE",'Priority =
')-INSTR("CAUSE",'Host = ')-11)<>SUBSTR("CAUSE",INSTR("CAUSE",'Host =
')+7,INSTR("CAUSE",'Priority = ')-INSTR("CAUSE",'Host = ')-11) AND
SUBSTR("CAUSE",INSTR("CAUSE",'Host = ')+7,INSTR("CAUSE",'Priority =
')-INSTR("CAUSE",'Host = ')-11)<>SUBSTR("CAUSE",INSTR("CAUSE",'Host =
')+7,INSTR("CAUSE",'Priority = ')-INSTR("CAUSE",'Host = ')-11) AND
SUBSTR("CAUSE",INSTR("CAUSE",'Priority = ')+11,INSTR("CAUSE",'reachable =
')-INSTR("CAUSE",'Priority = ')-13)<>SUBSTR("CAUSE",INSTR("CAUSE",'Priority =
')+11,INSTR("CAUSE",'reachable = ')-INSTR("CAUSE",'Priority = ')-13) AND
SUBSTR("CAUSE",INSTR("CAUSE",'Priority = ')+11,INSTR("CAUSE",'reachable =
')-INSTR("CAUSE",'Priority = ')-13)<>SUBSTR("CAUSE",INSTR("CAUSE",'Priority =
')+11,INSTR("CAUSE",'reachable = ')-INSTR("CAUSE",'Priority = ')-13))
15 - access("HOPBYHOP"="HOPBYHOP")
filter("HOPBYHOP"="HOPBYHOP")
16 - filter("CAUSE" LIKE '%SC路由应答%')
17 - access("HOPBYHOP"="HOPBYHOP")
filter("HOPBYHOP"="HOPBYHOP")
19 - access("HOPBYHOP"="HOPBYHOP")
filter("HOPBYHOP"="HOPBYHOP") Statistics
----------------------------------------------------------
54 recursive calls
0 db block gets
128904 consistent gets
5549 physical reads
0 redo size
1017 bytes sent via SQL*Net to client
1422 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
0 rows processed
改写方法:
----第1次改造---- 动作:将NE_STATE单独成WITH子句,并用ROWNUM>=0来告知ORACLE中间记录数的情况
不过我觉的有点奇怪,以前用ROWNUM是为了让视图不要拆开与其他表关联,做
为一个整体,和今天的效果不一样,今天感觉是起到改变表驱动顺序的作用。
效果:改进了表驱动的顺序,WITH部分的视图结果集小,在前面驱动才是正确的,原先没有ROWNUM时变成在后面驱动。
具体可以通过UE的比较工具来比较老脚本的执行计划可清晰看出,改变驱动顺序后速度从3000秒提升到50秒。
第1次改造后的SQL语句如下:
with ne_state as
( select distinct dsl1.peer_id peer_id,
nvl(ne_disconnect_info.ne_state, 1) ne_state
from dcc_sys_log dsl1,
(select distinct dnl.peer_id peer_id,
decode(action,
'disconnect',
0,
'connect',
0,
1) ne_state
from dcc_sys_log dsl, dcc_ne_log dnl
where dsl.peer_id = dnl.peer_id
and ((dsl.action = 'disconnect' and
dsl.cause = '关闭对端') or
(dsl.action = 'connect' and
dsl.cause = '连接主机失败'))
and dsl.log_time =
(select max(log_time)
from dcc_sys_log
where peer_id = dnl.peer_id
and log_type = '对端交互')) ne_disconnect_info
where dsl1.peer_id = ne_disconnect_info.peer_id(+) and rownum>=0)
select distinct ne_state.peer_id peer_name,
to_char(ne_state.ne_state) peer_state,
(case
when ne_state.ne_state = 0 then
to_char(0)
else
(select distinct to_char(nvl(ne_active.active, 0))
from dcc_sys_log,
(select peer_id,
decode(action,
'active',
1,
'de-active',
0,
0) active,
max(log_time)
from dcc_sys_log
where action = 'active'
or action = 'de-active'
group by (peer_id, action)) ne_active
where dcc_sys_log.peer_id = ne_active.peer_id(+)
and dcc_sys_log.peer_id = ne_state.peer_id)
end) peer_active,
(case
when ne_state.ne_state = 0 then
to_char(0)
else
(to_char(nvl((select count(*)
from dcc_ne_log
where dcc_ne_log.result <> 1
and peer_id = ne_state.peer_id
and log_time between
trunc(sysdate) and sysdate
group by (peer_id)),
0)))
end) err_cnt,
(case
when ne_state.ne_state = 0 then
to_char(0)
else
(to_char(nvl((select count(*)
from dcc_ne_log in_dnl
where in_dnl.direction = 'recv'
and in_dnl.peer_id =
ne_state.peer_id
and log_time between
trunc(sysdate) and sysdate),
0)))
end) recv_cnt,
(case
when ne_state.ne_state = 0 then
to_char(0)
else
(to_char(nvl((select sum(length)
from dcc_ne_log in_dnl
where in_dnl.direction = 'recv'
and in_dnl.peer_id =
ne_state.peer_id
and log_time between
trunc(sysdate) and sysdate),
0)))
end) recv_byte,
(case
when ne_state.ne_state = 0 then
to_char(0)
else
(to_char(nvl((select count(*)
from dcc_ne_log in_dnl
where in_dnl.direction = 'send'
and in_dnl.peer_id =
ne_state.peer_id
and log_time between
trunc(sysdate) and sysdate),
0)))
end) send_cnt,
(case
when ne_state.ne_state = 0 then
to_char(0)
else
(to_char(nvl((select sum(length)
from dcc_ne_log in_dnl
where in_dnl.direction = 'send'
and in_dnl.peer_id =
ne_state.peer_id
and log_time between
trunc(sysdate) and sysdate),
0)))
end) send_byte
from dcc_ne_log,ne_state
where ne_state.peer_id = dcc_ne_log.peer_id(+); 第1次改造后的SQL执行计划如下:
SELECT STATEMENT, GOAL = ALL_ROWS 34310 7 336
HASH UNIQUE 6001 119421 6448734
MERGE JOIN OUTER 4414 119421 6448734
INDEX RANGE SCAN IDEPTEST IDX_DCC_SYS_LOG_PEER 596 119421 2866104
SORT JOIN 3818 2 60
VIEW IDEPTEST 3817 2 60
SORT GROUP BY 3817 2 84
TABLE ACCESS BY INDEX ROWID IDEPTEST DCC_SYS_LOG 3816 30 1260
INDEX RANGE SCAN IDEPTEST IDX_DCC_SYS_LOG_PEER 596 119421
SORT GROUP BY NOSORT 302 1 31
FILTER
TABLE ACCESS BY INDEX ROWID IDEPTEST DCC_NE_LOG 302 1 31
INDEX RANGE SCAN IDEPTEST IDX_DCC_NE_LOG_TIME 21 7302
SORT AGGREGATE 1 33
FILTER
TABLE ACCESS BY INDEX ROWID IDEPTEST DCC_NE_LOG 302 540 17820
INDEX RANGE SCAN IDEPTEST IDX_DCC_NE_LOG_TIME 21 7302
SORT AGGREGATE 1 37
FILTER
TABLE ACCESS BY INDEX ROWID IDEPTEST DCC_NE_LOG 302 540 19980
INDEX RANGE SCAN IDEPTEST IDX_DCC_NE_LOG_TIME 21 7302
SORT AGGREGATE 1 33
FILTER
TABLE ACCESS BY INDEX ROWID IDEPTEST DCC_NE_LOG 302 503 16599
INDEX RANGE SCAN IDEPTEST IDX_DCC_NE_LOG_TIME 21 7302
SORT AGGREGATE 1 37
FILTER
TABLE ACCESS BY INDEX ROWID IDEPTEST DCC_NE_LOG 302 503 18611
INDEX RANGE SCAN IDEPTEST IDX_DCC_NE_LOG_TIME 21 7302
HASH UNIQUE 34310 7 336
HASH JOIN OUTER 34309 1299 62352
VIEW IDEPTEST 34222 7 189
HASH UNIQUE 34222 7 336
COUNT
FILTER
HASH JOIN RIGHT OUTER 33949 4896255 235020240
VIEW IDEPTEST 28574 10 240
HASH UNIQUE 28574 10 1160
HASH JOIN 28573 1561 181076
HASH JOIN 28486 3874 368030
VIEW SYS VW_SQ_1 14365 41 1353
HASH GROUP BY 14365 41 2624
TABLE ACCESS FULL IDEPTEST DCC_SYS_LOG 14092 4895849 313334336
TABLE ACCESS FULL IDEPTEST DCC_SYS_LOG 14107 2462339 152665018
INDEX FAST FULL SCAN IDEPTEST IDX_DCC_NE_LOG_PEER 86 85428 1793988
INDEX FAST FULL SCAN IDEPTEST IDX_DCC_SYS_LOG_PEER 5347 4896255 117510120
INDEX FAST FULL SCAN IDEPTEST IDX_DCC_NE_LOG_PEER 86 85428 1793988 ---第2次改造---- 动作:构造dcc_ne_log_time的WITH子句.
效果:多次调用这个后,系统内部优化,产生自带临时表SYS_TEMP_0FD9D661A_2F9A0F1,
多次调用SYS_TEMP_0FD9D661A_2F9A0F1而非调用dcc_ne_log是有差别的,调用SYS_TEMP_0FD9D661A_2F9A0F1
极大的提升了性能,从50秒缩短为14秒!
第2次改造后SQL语句如下:
with ne_state as
(select distinct dsl1.peer_id peer_id,
nvl(ne_disconnect_info.ne_state, 1) ne_state
from dcc_sys_log dsl1,
(select distinct dnl.peer_id peer_id,
decode(action,
'disconnect',
0,
'connect',
0,
1) ne_state
from dcc_sys_log dsl, dcc_ne_log dnl
where dsl.peer_id = dnl.peer_id
and ((dsl.action = 'disconnect' and
dsl.cause = '关闭对端') or
(dsl.action = 'connect' and
dsl.cause = '连接主机失败'))
and dsl.log_time =
(select max(log_time)
from dcc_sys_log
where peer_id = dnl.peer_id
and log_type = '对端交互')) ne_disconnect_info
where dsl1.peer_id = ne_disconnect_info.peer_id(+) and rownum>=0),
dcc_ne_log_time as (select * from dcc_ne_log where log_time between trunc(sysdate) and sysdate )
select distinct ne_state.peer_id peer_name,
to_char(ne_state.ne_state) peer_state,
(case
when ne_state.ne_state = 0 then
to_char(0)
else
(select distinct to_char(nvl(ne_active.active, 0))
from dcc_sys_log,
(select peer_id,
decode(action,
'active',
1,
'de-active',
0,
0) active,
max(log_time)
from dcc_sys_log
where action = 'active'
or action = 'de-active'
group by (peer_id, action)) ne_active
where dcc_sys_log.peer_id = ne_active.peer_id(+)
and dcc_sys_log.peer_id = ne_state.peer_id)
end) peer_active,
(case
when ne_state.ne_state = 0 then
to_char(0)
else
(to_char(nvl((select count(*)
from dcc_ne_log_time
where dcc_ne_log_time.result <> 1
and peer_id = ne_state.peer_id
group by (peer_id)),
0)))
end) err_cnt,
(case
when ne_state.ne_state = 0 then
to_char(0)
else
(to_char(nvl((select count(*)
from dcc_ne_log_time in_dnl
where in_dnl.direction = 'recv'
and in_dnl.peer_id =
ne_state.peer_id),
0)))
end) recv_cnt,
(case
when ne_state.ne_state = 0 then
to_char(0)
else
(to_char(nvl((select sum(length)
from dcc_ne_log_time in_dnl
where in_dnl.direction = 'recv'
and in_dnl.peer_id =
ne_state.peer_id),
0)))
end) recv_byte,
(case
when ne_state.ne_state = 0 then
to_char(0)
else
(to_char(nvl((select count(*)
from dcc_ne_log_time in_dnl
where in_dnl.direction = 'send'
and in_dnl.peer_id =
ne_state.peer_id),
0)))
end) send_cnt,
(case
when ne_state.ne_state = 0 then
to_char(0)
else
(to_char(nvl((select sum(length)
from dcc_ne_log_time in_dnl
where in_dnl.direction = 'send'
and in_dnl.peer_id =
ne_state.peer_id),
0)))
end) send_byte
from dcc_ne_log_time,ne_state
where ne_state.peer_id = dcc_ne_log_time.peer_id(+); 第2次改造后的SQL执行计划如下:
SELECT STATEMENT, GOAL = ALL_ROWS 34584 7 336
HASH UNIQUE 6001 119421 6448734
MERGE JOIN OUTER 4414 119421 6448734
INDEX RANGE SCAN IDEPTEST IDX_DCC_SYS_LOG_PEER 596 119421 2866104
SORT JOIN 3818 2 60
VIEW IDEPTEST 3817 2 60
SORT GROUP BY 3817 2 84
TABLE ACCESS BY INDEX ROWID IDEPTEST DCC_SYS_LOG 3816 30 1260
INDEX RANGE SCAN IDEPTEST IDX_DCC_SYS_LOG_PEER 596 119421
SORT GROUP BY NOSORT 58 7 238
VIEW IDEPTEST 58 7302 248268
TABLE ACCESS FULL SYS SYS_TEMP_0FD9D661A_2F9A0F1 58 7302 1891218
SORT AGGREGATE 1 53
VIEW IDEPTEST 58 7302 387006
TABLE ACCESS FULL SYS SYS_TEMP_0FD9D661A_2F9A0F1 58 7302 1891218
SORT AGGREGATE 1 57
VIEW IDEPTEST 58 7302 416214
TABLE ACCESS FULL SYS SYS_TEMP_0FD9D661A_2F9A0F1 58 7302 1891218
SORT AGGREGATE 1 53
VIEW IDEPTEST 58 7302 387006
TABLE ACCESS FULL SYS SYS_TEMP_0FD9D661A_2F9A0F1 58 7302 1891218
SORT AGGREGATE 1 57
VIEW IDEPTEST 58 7302 416214
TABLE ACCESS FULL SYS SYS_TEMP_0FD9D661A_2F9A0F1 58 7302 1891218
TEMP TABLE TRANSFORMATION
LOAD AS SELECT
COUNT
FILTER
FILTER
TABLE ACCESS BY INDEX ROWID IDEPTEST DCC_NE_LOG 302 7302 1891218
INDEX RANGE SCAN IDEPTEST IDX_DCC_NE_LOG_TIME 21 7302
HASH UNIQUE 34282 7 336
HASH JOIN OUTER 34281 7 336
VIEW IDEPTEST 34222 7 189
HASH UNIQUE 34222 7 336
COUNT
FILTER
HASH JOIN RIGHT OUTER 33949 4896255 235020240
VIEW IDEPTEST 28574 10 240
HASH UNIQUE 28574 10 1160
HASH JOIN 28573 1561 181076
HASH JOIN 28486 3874 368030
VIEW SYS VW_SQ_1 14365 41 1353
HASH GROUP BY 14365 41 2624
TABLE ACCESS FULL IDEPTEST DCC_SYS_LOG 14092 4895849 313334336
TABLE ACCESS FULL IDEPTEST DCC_SYS_LOG 14107 2462339 152665018
INDEX FAST FULL SCAN IDEPTEST IDX_DCC_NE_LOG_PEER 86 85428 1793988
INDEX FAST FULL SCAN IDEPTEST IDX_DCC_SYS_LOG_PEER 5347 4896255 117510120
VIEW IDEPTEST 58 7302 153342
TABLE ACCESS FULL SYS SYS_TEMP_0FD9D661A_2F9A0F1 58 7302 1891218 ----第3次改进----- 动作:部分SQL进行等价改写
将 select distinct to_char(nvl(ne_active.active, 0))
from dcc_sys_log,
(select peer_id,
decode(action,
'active',
1,
'de-active',
0,
0) active,
max(log_time)
from dcc_sys_log
where action = 'active'
or action = 'de-active'
group by (peer_id, action)) ne_active
where dcc_sys_log.peer_id = ne_active.peer_id(+)
and dcc_sys_log.peer_id = ne_state.peer_id
修改为:
NVL((select '1' from dcc_sys_log where peer_id = ne_state.peer_id and action = 'active' and rownum=1),'0') 效果:改写的写法dcc_sys_log表的扫描1次数,而未改写时是扫描dcc_sys_log表2次
性能提升,执行速度由15秒变为10秒
第3次改造后的SQL语句如下:
with ne_state as
(select distinct dsl1.peer_id peer_id,
nvl(ne_disconnect_info.ne_state, 1) ne_state
from dcc_sys_log dsl1,
(select distinct dnl.peer_id peer_id,
decode(action,
'disconnect',
0,
'connect',
0,
1) ne_state
from dcc_sys_log dsl, dcc_ne_log dnl
where dsl.peer_id = dnl.peer_id
and ((dsl.action = 'disconnect' and
dsl.cause = '关闭对端') or
(dsl.action = 'connect' and
dsl.cause = '连接主机失败'))
and dsl.log_time =
(select max(log_time)
from dcc_sys_log
where peer_id = dnl.peer_id
and log_type = '对端交互')) ne_disconnect_info
where dsl1.peer_id = ne_disconnect_info.peer_id(+) and rownum>=0),
dcc_ne_log_time as (select * from dcc_ne_log where log_time between trunc(sysdate) and sysdate )
select distinct ne_state.peer_id peer_name,
to_char(ne_state.ne_state) peer_state,
(case
when ne_state.ne_state = 0 then
to_char(0)
else
NVL((select '1' from dcc_sys_log where peer_id = ne_state.peer_id and action = 'active' and rownum=1),'0')
end) peer_active,
(case
when ne_state.ne_state = 0 then
to_char(0)
else
(to_char(nvl((select count(*)
from dcc_ne_log_time
where dcc_ne_log_time.result <> 1
and peer_id = ne_state.peer_id
group by (peer_id)),
0)))
end) err_cnt,
(case
when ne_state.ne_state = 0 then
to_char(0)
else
(to_char(nvl((select count(*)
from dcc_ne_log_time in_dnl
where in_dnl.direction = 'recv'
and in_dnl.peer_id =
ne_state.peer_id),
0)))
end) recv_cnt,
(case
when ne_state.ne_state = 0 then
to_char(0)
else
(to_char(nvl((select sum(length)
from dcc_ne_log_time in_dnl
where in_dnl.direction = 'recv'
and in_dnl.peer_id =
ne_state.peer_id),
0)))
end) recv_byte,
(case
when ne_state.ne_state = 0 then
to_char(0)
else
(to_char(nvl((select count(*)
from dcc_ne_log_time in_dnl
where in_dnl.direction = 'send'
and in_dnl.peer_id =
ne_state.peer_id),
0)))
end) send_cnt,
(case
when ne_state.ne_state = 0 then
to_char(0)
else
(to_char(nvl((select sum(length)
from dcc_ne_log_time in_dnl
where in_dnl.direction = 'send'
and in_dnl.peer_id =
ne_state.peer_id),
0)))
end) send_byte
from dcc_ne_log_time,ne_state
where ne_state.peer_id = dcc_ne_log_time.peer_id(+); 第3次改造后的SQL执行计划如下:
SELECT STATEMENT, GOAL = ALL_ROWS 34584 7 336
COUNT STOPKEY
TABLE ACCESS BY INDEX ROWID IDEPTEST DCC_SYS_LOG 3816 1 35
INDEX RANGE SCAN IDEPTEST IDX_DCC_SYS_LOG_PEER 596 119421
SORT GROUP BY NOSORT 58 7 238
VIEW IDEPTEST 58 7302 248268
TABLE ACCESS FULL SYS SYS_TEMP_0FD9D662A_2F9A0F1 58 7302 1891218
SORT AGGREGATE 1 44
VIEW IDEPTEST 58 7302 321288
TABLE ACCESS FULL SYS SYS_TEMP_0FD9D662A_2F9A0F1 58 7302 1891218
SORT AGGREGATE 1 57
VIEW IDEPTEST 58 7302 416214
TABLE ACCESS FULL SYS SYS_TEMP_0FD9D662A_2F9A0F1 58 7302 1891218
SORT AGGREGATE 1 44
VIEW IDEPTEST 58 7302 321288
TABLE ACCESS FULL SYS SYS_TEMP_0FD9D662A_2F9A0F1 58 7302 1891218
SORT AGGREGATE 1 57
VIEW IDEPTEST 58 7302 416214
TABLE ACCESS FULL SYS SYS_TEMP_0FD9D662A_2F9A0F1 58 7302 1891218
TEMP TABLE TRANSFORMATION
LOAD AS SELECT
FILTER
TABLE ACCESS BY INDEX ROWID IDEPTEST DCC_NE_LOG 302 7302 1891218
INDEX RANGE SCAN IDEPTEST IDX_DCC_NE_LOG_TIME 21 7302
HASH UNIQUE 34282 7 336
HASH JOIN OUTER 34281 7 336
VIEW IDEPTEST 34222 7 189
HASH UNIQUE 34222 7 336
COUNT
FILTER
HASH JOIN RIGHT OUTER 33949 4896255 235020240
VIEW IDEPTEST 28574 10 240
HASH UNIQUE 28574 10 1160
HASH JOIN 28573 1561 181076
HASH JOIN 28486 3874 368030
VIEW SYS VW_SQ_1 14365 41 1353
HASH GROUP BY 14365 41 2624
TABLE ACCESS FULL IDEPTEST DCC_SYS_LOG 14092 4895849 313334336
TABLE ACCESS FULL IDEPTEST DCC_SYS_LOG 14107 2462339 152665018
INDEX FAST FULL SCAN IDEPTEST IDX_DCC_NE_LOG_PEER 86 85428 1793988
INDEX FAST FULL SCAN IDEPTEST IDX_DCC_SYS_LOG_PEER 5347 4896255 117510120
VIEW IDEPTEST 58 7302 153342
TABLE ACCESS FULL SYS SYS_TEMP_0FD9D662A_2F9A0F1 58 7302 1891218 ---第4次改造----
动作:将所有标量子查询改造为单独一个表关联写法
效果:将标量子查询的多次扫描,降低为将表扫描次仅1次,执行时间从10秒缩短为7秒 with ne_state as
(select distinct dsl1.peer_id peer_id,
nvl(ne_disconnect_info.ne_state, 1) ne_state
from dcc_sys_log dsl1,
(select distinct dnl.peer_id peer_id,
decode(action,
'disconnect',
0,
'connect',
0,
1) ne_state
from dcc_sys_log dsl, dcc_ne_log dnl
where dsl.peer_id = dnl.peer_id
and ((dsl.action = 'disconnect' and
dsl.cause = '关闭对端') or
(dsl.action = 'connect' and
dsl.cause = '连接主机失败'))
and dsl.log_time =
(select max(log_time)
from dcc_sys_log
where peer_id = dnl.peer_id
and log_type = '对端交互')) ne_disconnect_info
where dsl1.peer_id = ne_disconnect_info.peer_id(+) and rownum>=0),
dcc_ne_log_time as (select peer_id
,COUNT(CASE WHEN RESULT <> 1 THEN 1 END) err_cnt
,COUNT(CASE WHEN direction = 'recv' THEN 1 END) recv_cnt
,SUM(CASE WHEN direction = 'recv' THEN length END) recv_byte
,COUNT(CASE WHEN direction = 'send' THEN 1 END) send_cnt
,SUM(CASE WHEN direction = 'send' THEN length END) send_byte
from dcc_ne_log
where log_time >=trunc(sysdate) ---- between trunc(sysdate) and sysdate
GROUP BY peer_id)
select distinct ne_state.peer_id peer_name,
to_char(ne_state.ne_state) peer_state,
(case
when ne_state.ne_state = 0 then
to_char(0)
else
NVL((select '1' from dcc_sys_log where peer_id = ne_state.peer_id and action = 'active' and rownum=1),'0')
end) peer_active,
decode(ne_state.ne_state,0,'0',nvl(dnlt.ERR_CNT,0)) ERR_CNT, ---注意NVL改造
decode(ne_state.ne_state,0,'0',nvl(dnlt.recv_cnt,0)) recv_cnt,
decode(ne_state.ne_state,0,'0',nvl(dnlt.recv_byte,0)) recv_byte,
decode(ne_state.ne_state,0,'0',nvl(dnlt.send_cnt,0)) send_cnt,
decode(ne_state.ne_state,0,'0',nvl(dnlt.send_byte,0)) send_byte
from ne_state ,dcc_ne_log_time dnlt
where ne_state.peer_id=dnlt.peer_id(+) 第4次改造后的SQL执行计划
SELECT STATEMENT, GOAL = ALL_ROWS 34231 7 791
COUNT STOPKEY
TABLE ACCESS BY INDEX ROWID IDEPTEST DCC_SYS_LOG 3816 1 35
INDEX RANGE SCAN IDEPTEST IDX_DCC_SYS_LOG_PEER 596 119421
HASH UNIQUE 34231 7 791
HASH JOIN OUTER 34230 7 791
VIEW IDEPTEST 34222 7 189
HASH UNIQUE 34222 7 336
COUNT
FILTER
HASH JOIN RIGHT OUTER 33949 4896255 235020240
VIEW IDEPTEST 28574 10 240
HASH UNIQUE 28574 10 1160
HASH JOIN 28573 1561 181076
HASH JOIN 28486 3874 368030
VIEW SYS VW_SQ_1 14365 41 1353
HASH GROUP BY 14365 41 2624
TABLE ACCESS FULL IDEPTEST DCC_SYS_LOG 14092 4895849 313334336
TABLE ACCESS FULL IDEPTEST DCC_SYS_LOG 14107 2462339 152665018
INDEX FAST FULL SCAN IDEPTEST IDX_DCC_NE_LOG_PEER 86 85428 1793988
INDEX FAST FULL SCAN IDEPTEST IDX_DCC_SYS_LOG_PEER 5347 4896255 117510120
VIEW IDEPTEST 8 7 602
HASH GROUP BY 8 7 280
TABLE ACCESS BY INDEX ROWID IDEPTEST DCC_NE_LOG 7 108 4320
INDEX RANGE SCAN IDEPTEST IDX_DCC_NE_LOG_TIME 2 108 ---第5次改造 如下部分(即我改造后语句的第一个WITH的地方),觉的非常怪异
外面用 action和cause,里面在查最大时间用的是log_type = '对端交互'
根据我的经验常识来看,需求应该是log_type = '对端交互'同时作用于内外,即找出log_type = '对端交互'的最近一条记录,
然后看它的action和cause是否满足要求,难道不是这样吗,这样才顺畅嘛。
select distinct dsl1.peer_id peer_id,
nvl(ne_disconnect_info.ne_state, 1) ne_state
from dcc_sys_log dsl1,
(select distinct dnl.peer_id peer_id,
decode(action,
'disconnect',
0,
'connect',
0,
1) ne_state
from dcc_sys_log dsl, dcc_ne_log dnl
where dsl.peer_id = dnl.peer_id
and ((dsl.action = 'disconnect' and
dsl.cause = '关闭对端') or
(dsl.action = 'connect' and
dsl.cause = '连接主机失败'))
and dsl.log_time =
(select max(log_time)
from dcc_sys_log
where peer_id = dnl.peer_id
and log_type = '对端交互')) ne_disconnect_info
where dsl1.peer_id = ne_disconnect_info.peer_id(+) and rownum>=0 如果我猜测的是对的,代码就应该改写为如下(增加and log_type = '对端交互' ):
把数据限于log_type = '对端交互'的那些。如果有哪个peer_id不存在 log_type = '对端交互',
那么这个peer_id不在新写法中出现。之前的旧写法包括所有。 select distinct dsl1.peer_id peer_id,
nvl(ne_disconnect_info.ne_state, 1) ne_state
from dcc_sys_log dsl1,
(select distinct dnl.peer_id peer_id,
decode(action,
'disconnect',
0,
'connect',
0,
1) ne_state
from dcc_sys_log dsl, dcc_ne_log dnl
where dsl.peer_id = dnl.peer_id
and ((dsl.action = 'disconnect' and
dsl.cause = '关闭对端') or
(dsl.action = 'connect' and
dsl.cause = '连接主机失败'))
and log_type = '对端交互'
and dsl.log_time =
(select max(log_time)
from dcc_sys_log
where peer_id = dnl.peer_id
and log_type = '对端交互')) ne_disconnect_info
where dsl1.peer_id = ne_disconnect_info.peer_id(+) and rownum>=0 以下改写可以完善取最大日期的记录的方法,可进一步减少扫描次数 SELECT a.peer_id,
CASE WHEN dnl.peer_id IS NOT NULL AND str IN ('disconnect关闭对端','connect连接主机失败') THEN '0' ELSE '1' END ne_state
FROM (SELECT peer_id,MIN(action||cause) KEEP(DENSE_RANK LAST ORDER BY log_time) str
FROM dcc_sys_log dsl
WHERE log_type = '对端交互'
GROUP BY peer_id
) a,(SELECT DISTINCT peer_id FROM dcc_ne_log) dnl
WHERE a.peer_id = dnl.peer_id(+) 经过5次改造后,最终完善优化版代码如下: with ne_state as
(SELECT a.peer_id,
CASE WHEN dnl.peer_id IS NOT NULL AND str IN ('disconnect关闭对端','connect连接主机失败') THEN '0' ELSE '1' END ne_state
FROM (SELECT peer_id,MIN(action||cause) KEEP(DENSE_RANK LAST ORDER BY log_time) str
FROM dcc_sys_log dsl
WHERE log_type = '对端交互'
GROUP BY peer_id
) a,(SELECT DISTINCT peer_id FROM dcc_ne_log) dnl
WHERE a.peer_id = dnl.peer_id(+)),
dcc_ne_log_time as (select peer_id
,COUNT(CASE WHEN RESULT <> 1 THEN 1 END) err_cnt
,COUNT(CASE WHEN direction = 'recv' THEN 1 END) recv_cnt
,SUM(CASE WHEN direction = 'recv' THEN length END) recv_byte
,COUNT(CASE WHEN direction = 'send' THEN 1 END) send_cnt
,SUM(CASE WHEN direction = 'send' THEN length END) send_byte
from dcc_ne_log
where log_time >=trunc(sysdate) ---- between trunc(sysdate) and sysdate
GROUP BY peer_id)
select distinct ne_state.peer_id peer_name,
to_char(ne_state.ne_state) peer_state,
(case
when ne_state.ne_state = 0 then
to_char(0)
else
NVL((select '1' from dcc_sys_log where peer_id = ne_state.peer_id and action = 'active' and rownum=1),'0')
end) peer_active,
decode(ne_state.ne_state,0,'0',nvl(dnlt.ERR_CNT,0)) ERR_CNT, ---注意NVL改造
decode(ne_state.ne_state,0,'0',nvl(dnlt.recv_cnt,0)) recv_cnt,
decode(ne_state.ne_state,0,'0',nvl(dnlt.recv_byte,0)) recv_byte,
decode(ne_state.ne_state,0,'0',nvl(dnlt.send_cnt,0)) send_cnt,
decode(ne_state.ne_state,0,'0',nvl(dnlt.send_byte,0)) send_byte
from ne_state ,dcc_ne_log_time dnlt
where ne_state.peer_id=dnlt.peer_id(+) 执行计划:
SELECT STATEMENT, GOAL = ALL_ROWS 14880 71 19667
COUNT STOPKEY
TABLE ACCESS BY INDEX ROWID IDEPTEST DCC_SYS_LOG 3235 1 35
INDEX RANGE SCAN IDEPTEST IDX_DCC_SYS_LOG_PEER 505 100809
HASH UNIQUE 14880 71 19667
HASH JOIN OUTER 14878 19100 5290700
HASH JOIN RIGHT OUTER 14657 49 12446
VIEW IDEPTEST 65 10 880
HASH GROUP BY 65 10 430
TABLE ACCESS BY INDEX ROWID IDEPTEST DCC_NE_LOG 64 1388 59684
INDEX RANGE SCAN IDEPTEST IDX_DCC_NE_LOG_TIME 7 1388
VIEW IDEPTEST 14592 49 8134
SORT GROUP BY 14592 49 3479
TABLE ACCESS FULL IDEPTEST DCC_SYS_LOG 14316 4939225 350684975
INDEX FAST FULL SCAN IDEPTEST IDX_DCC_NE_LOG_PEER 220 176424 4057752
group by的合并sql:
select decode(so.sFileName, 'SNP_20', 'SNP', 'HNIC_2', 'HNIC', 'IBRC_2', 'IBRC', 'IISMP_', 'IISMP', 'NIC_20', 'NIC', 'NIG_20', 'NIG', 'IIC_20', 'IIC', 'HIIC_2', 'HIIC', 'CA.D.A', 'CA.D.ATSR', 'ULH_20', 'ULH', 'IBRST_', 'IBRST', so.sFileName) 业务名称,
so.sFileCount 合并前文件个数,
so.sRecordNum 合并前总记录数,
ta.tFileCount 合并后文件个数,
ta.tRecordNum 合并后总记录数,
NVL(so1.sFileCount, 0) 合并前当天文件个数,
NVL(so1.sRecordNum, 0) 合并前当天文件总记录数,
NVL(so2.sFileCount, 0) 合并前昨天文件个数,
NVL(so2.sRecordNum, 0) 合并前昨天文件总记录数
from (select substr(a.file_name, 1, 6) sfileName,
count(*) sFileCount,
sum(sRecordNum) sRecordNum
from (select distinct bsf.file_name,
bsf.record_num sRecordNum,
bsf.create_time
from BUSINESS_SEND_FILELIST bsf, IDEP_PLUGIN_AUTO_RELATION ipar
where bsf.file_id = ipar.bus_file_id
and trunc(ipar.relation_time) = to_date('2010-08-05', 'yyyy-mm-dd')) a
group by substr(a.file_name, 1, 6)
order by substr(a.file_name, 1, 6)) so
LEFT JOIN
(select substr(a.file_name, 1, 6) sfileName,
count(*) sFileCount,
sum(sRecordNum) sRecordNum
from (select distinct bsf.file_name,
bsf.record_num sRecordNum,
bsf.create_time
from BUSINESS_SEND_FILELIST bsf, IDEP_PLUGIN_AUTO_RELATION ipar
where bsf.file_id = ipar.bus_file_id
and trunc(ipar.relation_time) = to_date('2010-08-05', 'yyyy-mm-dd')
AND FILE_NAME LIKE '%20100805%') a
group by substr(a.file_name, 1, 6)
order by substr(a.file_name, 1, 6)) so1
ON (so.sFileName = so1.sFileName)
LEFT JOIN
(select substr(a.file_name, 1, 6) sfileName,
count(*) sFileCount,
sum(sRecordNum) sRecordNum
from (select distinct bsf.file_name,
bsf.record_num sRecordNum,
bsf.create_time
from BUSINESS_SEND_FILELIST bsf, IDEP_PLUGIN_AUTO_RELATION ipar
where bsf.file_id = ipar.bus_file_id
and trunc(ipar.relation_time) = to_date('2010-08-05', 'yyyy-mm-dd')
AND FILE_NAME not LIKE '%20100805%') a
group by substr(a.file_name, 1, 6)
order by substr(a.file_name, 1, 6)) so2
ON (so.sFileName = so2.sFileName)
LEFT JOIN
(select substr(a.file_name, 1, 6) tFileName,
count(*) tFileCount,
sum(record_num) tRecordNum
from (select distinct ipsf.file_name,
ipsf.record_num
from idep_plugin_send_filelist ipsf
where trunc(ipsf.create_time) = to_date('2010-08-05', 'yyyy-mm-dd')
and remark = '处理成功') a
group by substr(a.file_name, 1, 6)
order by substr(a.file_name, 1, 6)) ta
ON (so.sFileName = ta.tFileName)
where so.sFileName not like 'MVI%'
union
select so.sFileName,
so.sFileCount,
(so.sRecordNum - (so.sFileCount * 2)) sRecordNum,
ta.tFileCount,
ta.tRecordNum,
NVL(so1.sFileCount, 0),
(nvl(so1.sRecordNum, 0) - (nvl(so1.sFileCount, 0) * 2)),
NVL(so2.sFileCount, 0),
(nvl(so2.sRecordNum, 0) - (nvl(so2.sFileCount, 0) * 2))
from (select substr(a.file_name, 1, 3) sfileName,
count(*) sFileCount,
sum(sRecordNum) sRecordNum
from (select distinct bsf.file_name,
bsf.record_num sRecordNum,
bsf.create_time
from BUSINESS_SEND_FILELIST bsf, IDEP_PLUGIN_AUTO_RELATION ipar
where bsf.file_id = ipar.bus_file_id
and trunc(ipar.relation_time) = to_date('2010-08-05', 'yyyy-mm-dd')) a
group by substr(a.file_name, 1, 3)
order by substr(a.file_name, 1, 3)) so
LEFT JOIN
(select substr(a.file_name, 1, 3) sfileName,
count(*) sFileCount,
sum(sRecordNum) sRecordNum
from (select distinct bsf.file_name,
bsf.record_num sRecordNum,
bsf.create_time
from BUSINESS_SEND_FILELIST bsf, IDEP_PLUGIN_AUTO_RELATION ipar
where bsf.file_id = ipar.bus_file_id
and trunc(ipar.relation_time) = to_date('2010-08-05', 'yyyy-mm-dd')
AND FILE_NAME LIKE 'MVI100805%') a
group by substr(a.file_name, 1, 3)
order by substr(a.file_name, 1, 3)) so1
ON (so.sFileName = so1.sFileName)
LEFT JOIN
(select substr(a.file_name, 1, 3) sfileName,
count(*) sFileCount,
sum(sRecordNum) sRecordNum
from (select distinct bsf.file_name,
bsf.record_num sRecordNum,
bsf.create_time
from BUSINESS_SEND_FILELIST bsf, IDEP_PLUGIN_AUTO_RELATION ipar
where bsf.file_id = ipar.bus_file_id
and trunc(ipar.relation_time) = to_date('2010-08-05', 'yyyy-mm-dd')
AND FILE_NAME not LIKE 'MVI100805%') a
group by substr(a.file_name, 1, 3)
order by substr(a.file_name, 1, 3)) so2
ON (so.sFileName = so2.sFileName)
LEFT JOIN
(select substr(a.file_name, 1, 3) tFileName,
count(*) tFileCount,
sum(record_num) tRecordNum
from (select distinct ipsf.file_name,
ipsf.record_num
from idep_plugin_send_filelist ipsf
where trunc(ipsf.create_time) = to_date('2010-08-05', 'yyyy-mm-dd')
and remark = '处理成功') a
group by substr(a.file_name, 1, 3)
order by substr(a.file_name, 1, 3)) ta
ON (so.sFileName = ta.tFileName)
WHERE so.sFileName = 'MVI' ---这里有错吧,感觉应该是 WHERE so.sFileName like 'MVI%',确实没错,因为这里是截取过的了 注意点: 1.将trunc(ipar.relation_time) = to_date('2010-08-05', 'yyyy-mm-dd') 等等类似之处改写为如下,要避免对列进行运算,这样会
导致用不上索引,除非是建立了函数索引。
ipsf.create_time >= to_date('2010-08-05', 'yyyy-mm-dd') and ipsf.create_time < to_date('2010-08-05', 'yyyy-mm-dd')+1 2. 确保IDEP_PLUGIN_AUTO_RELATION的relation_time有索引
确保idep_plugin_send_filelist的create_time列有索引 3.可通过CASE WHEN 语句进一步减少表扫描次数,如(count(CASE WHEN FILE_NAME LIKE '%20100805%' THEN 1 END) sFileCount1),
类似如上的修改,可以等价改写,将本应用的表扫描从8次减少为4次。 代码改写如下:
select decode(so.sFileName, 'SNP_20', 'SNP', 'HNIC_2', 'HNIC', 'IBRC_2', 'IBRC', 'IISMP_', 'IISMP', 'NIC_20', 'NIC', 'NIG_20', 'NIG', 'IIC_20', 'IIC', 'HIIC_2', 'HIIC', 'CA.D.A', 'CA.D.ATSR', 'ULH_20', 'ULH', 'IBRST_', 'IBRST', so.sFileName) 业务名称,
so.sFileCount 合并前文件个数,
so.sRecordNum 合并前总记录数,
ta.tFileCount 合并后文件个数,
ta.tRecordNum 合并后总记录数,
NVL(so.sFileCount1, 0) 合并前当天文件个数,
NVL(so.sRecordNum1, 0) 合并前当天文件总记录数,
NVL(so.sFileCount2, 0) 合并前昨天文件个数,
NVL(so.sRecordNum2, 0) 合并前昨天文件总记录数
from (select substr(a.file_name, 1, 6) sfileName,
count(*) sFileCount,
sum(sRecordNum) sRecordNum,
count(CASE WHEN FILE_NAME LIKE '%20100805%' THEN 1 END) sFileCount1,
sum(CASE WHEN FILE_NAME LIKE '%20100805%' THEN sRecordNum END) sRecordNum1,
count(CASE WHEN FILE_NAME NOT LIKE '%20100805%' THEN 1 END) sFileCount2,
sum(CASE WHEN FILE_NAME NOT LIKE '%20100805%' THEN sRecordNum END) sRecordNum2
from (select distinct bsf.file_name,
bsf.record_num sRecordNum,
bsf.create_time
from BUSINESS_SEND_FILELIST bsf, IDEP_PLUGIN_AUTO_RELATION ipar
where bsf.file_id = ipar.bus_file_id
and ipar.relation_time >= to_date('2010-08-05', 'yyyy-mm-dd')
and ipar.relation_time < to_date('2010-08-05', 'yyyy-mm-dd')+1) a
group by substr(a.file_name, 1, 6)
order by substr(a.file_name, 1, 6)) so
LEFT JOIN
(select substr(a.file_name, 1, 6) tFileName,
count(*) tFileCount,
sum(record_num) tRecordNum
from (select distinct ipsf.file_name,
ipsf.record_num
from idep_plugin_send_filelist ipsf
where ipsf.create_time >= to_date('2010-08-05', 'yyyy-mm-dd')
and ipsf.create_time < to_date('2010-08-05', 'yyyy-mm-dd')+1
and remark = '处理成功') a
group by substr(a.file_name, 1, 6)
order by substr(a.file_name, 1, 6)) ta
ON (so.sFileName = ta.tFileName)
where so.sFileName not like 'MVI%'
union select so.sFileName,
so.sFileCount,
(so.sRecordNum - (so.sFileCount * 2)) sRecordNum,
ta.tFileCount,
ta.tRecordNum,
NVL(so.sFileCount1, 0),
(nvl(so.sRecordNum1, 0) - (nvl(so.sFileCount1, 0) * 2)),
NVL(so.sFileCount2, 0),
(nvl(so.sRecordNum2, 0) - (nvl(so.sFileCount2, 0) * 2))
from (select substr(a.file_name, 1, 3) sfileName,
count(*) sFileCount,
sum(sRecordNum) sRecordNum,
count(CASE WHEN FILE_NAME LIKE 'MVI100805%' THEN 1 END) sFileCount1,
sum(CASE WHEN FILE_NAME LIKE 'MVI100805%' THEN sRecordNum END) sRecordNum1,
count(CASE WHEN FILE_NAME NOT LIKE 'MVI100805%' THEN 1 END) sFileCount2,
sum(CASE WHEN FILE_NAME NOT LIKE 'MVI100805%' THEN sRecordNum END) sRecordNum2
from (select distinct bsf.file_name,
bsf.record_num sRecordNum,
bsf.create_time
from BUSINESS_SEND_FILELIST bsf, IDEP_PLUGIN_AUTO_RELATION ipar
where bsf.file_id = ipar.bus_file_id
and ipar.relation_time >= to_date('2010-08-05', 'yyyy-mm-dd')
and ipar.relation_time < to_date('2010-08-05', 'yyyy-mm-dd')+1) a
group by substr(a.file_name, 1, 3)
order by substr(a.file_name, 1, 3)) so
LEFT JOIN
(select substr(a.file_name, 1, 3) tFileName,
count(*) tFileCount,
sum(record_num) tRecordNum
from (select distinct ipsf.file_name,
ipsf.record_num
from idep_plugin_send_filelist ipsf
where ipsf.create_time >= to_date('2010-08-05', 'yyyy-mm-dd')
and ipsf.create_time < to_date('2010-08-05', 'yyyy-mm-dd')+1
and remark = '处理成功') a
group by substr(a.file_name, 1, 3)
order by substr(a.file_name, 1, 3)) ta
ON (so.sFileName = ta.tFileName)
WHERE so.sFileName = 'MVI' 最终版
select decode(so.sFileName, 'SNP_20', 'SNP', 'HNIC_2', 'HNIC', 'IBRC_2', 'IBRC', 'IISMP_', 'IISMP', 'NIC_20', 'NIC', 'NIG_20', 'NIG', 'IIC_20', 'IIC', 'HIIC_2', 'HIIC', 'CA.D.A', 'CA.D.ATSR', 'ULH_20', 'ULH', 'IBRST_', 'IBRST', so.sFileName) 业务名称,
so.sFileCount 合并前文件个数,
case when so.sfilename like 'MVI%' then (so.sRecordNum - (so.sFileCount * 2)) else so.sRecordNum end 合并前总记录数,
ta.tFileCount 合并后文件个数,
ta.tRecordNum 合并后总记录数,
NVL(so.sFileCount1, 0) 合并前当天文件个数,
case when so.sfilename like 'MVI%'
then (nvl(so.sRecordNum1, 0) - (nvl(so.sFileCount1, 0) * 2))
else NVL(so.sRecordNum1, 0) end 合并前当天文件总记录数,
NVL(so.sFileCount2, 0) 合并前昨天文件个数,
case when so.sfilename like 'MVI%'
then (nvl(so.sRecordNum2, 0) - (nvl(so.sFileCount2, 0) * 2))
else NVL(so.sRecordNum2, 0) end 合并前昨天文件总记录数
from (select substr(a.file_name, 1, CASE WHEN a.file_name like 'MVI%' THEN 3 ELSE 6 END) sfileName,
count(*) sFileCount,
sum(sRecordNum) sRecordNum,
count(CASE WHEN (FILE_NAME LIKE '%20100805%' AND FILE_NAME not like 'MVI%') OR (FILE_NAME LIKE 'MVI100805%' AND FILE_NAME like 'MVI%') THEN 1 END) sFileCount1,
sum (CASE WHEN (FILE_NAME LIKE '%20100805%' AND FILE_NAME not like 'MVI%') OR (FILE_NAME LIKE 'MVI100805%' AND FILE_NAME like 'MVI%') THEN sRecordNum END) sRecordNum1,
count(CASE WHEN (FILE_NAME NOT LIKE '%20100805%' AND FILE_NAME not like 'MVI%') OR (FILE_NAME NOT LIKE 'MVI100805%' AND FILE_NAME like 'MVI%') THEN 1 END) sFileCount2,
sum (CASE WHEN (FILE_NAME NOT LIKE '%20100805%' AND FILE_NAME not like 'MVI%') OR (FILE_NAME NOT LIKE 'MVI100805%' AND FILE_NAME like 'MVI%') THEN sRecordNum END) sRecordNum2
from (select distinct bsf.file_name,
bsf.record_num sRecordNum,
bsf.create_time
from BUSINESS_SEND_FILELIST bsf, IDEP_PLUGIN_AUTO_RELATION ipar
where bsf.file_id = ipar.bus_file_id
and ipar.relation_time >= to_date('2010-08-05', 'yyyy-mm-dd')
and ipar.relation_time < to_date('2010-08-05', 'yyyy-mm-dd')+1) a
group by substr(a.file_name, 1, CASE WHEN a.file_name like 'MVI%' THEN 3 ELSE 6 END)
order by substr(a.file_name, 1, CASE WHEN a.file_name like 'MVI%' THEN 3 ELSE 6 END)) so
LEFT JOIN
(select substr(a.file_name, 1, CASE WHEN a.file_name like 'MVI%' THEN 3 ELSE 6 END) tFileName,
count(*) tFileCount,
sum(record_num) tRecordNum
from (select distinct ipsf.file_name,
ipsf.record_num
from idep_plugin_send_filelist ipsf
where ipsf.create_time >= to_date('2010-08-05', 'yyyy-mm-dd')
and ipsf.create_time < to_date('2010-08-05', 'yyyy-mm-dd')+1
and remark = '处理成功') a
group by substr(a.file_name, 1, CASE WHEN a.file_name like 'MVI%' THEN 3 ELSE 6 END)
order by substr(a.file_name, 1, CASE WHEN a.file_name like 'MVI%' THEN 3 ELSE 6 END)) ta
ON (so.sFileName = ta.tFileName)
with as
该语句存在性能问题,执行非常缓慢,极耗CPU,为了实现行列转换的需求,具体如下:
select distinct to_char(a.svcctx_id),
to_char(0),
to_char(nvl((select peer_id
from dcc_ne_config
where peer_name = a.peer),
0)),
to_char(a.priority),
to_char(nvl((select peer_id
from dcc_ne_config
where peer_name = b.peer),
0)),
to_char(b.priority),
to_char(nvl((select peer_id
from dcc_ne_config
where peer_name = c.peer),
0)),
to_char(c.priority)
from (select hopbyhop,
svcctx_id,
substr(cause,
instr(cause, 'Host = ') + 7,
instr(cause, 'Priority = ') - instr(cause, 'Host = ') - 11) peer,
substr(cause,
instr(cause, 'Priority = ') + 11,
instr(cause, 'reachable = ') -
instr(cause, 'Priority = ') - 13) priority
from dcc_sys_log
where cause like '%SC路由应答%'
and hopbyhop in (select distinct hopbyhop from dcc_sys_log)) a,
(select hopbyhop,
svcctx_id,
substr(cause,
instr(cause, 'Host = ') + 7,
instr(cause, 'Priority = ') - instr(cause, 'Host = ') - 11) peer,
substr(cause,
instr(cause, 'Priority = ') + 11,
instr(cause, 'reachable = ') -
instr(cause, 'Priority = ') - 13) priority
from dcc_sys_log
where cause like '%SC路由应答%'
and hopbyhop in (select distinct hopbyhop from dcc_sys_log)) b,
(select hopbyhop,
svcctx_id,
substr(cause,
instr(cause, 'Host = ') + 7,
instr(cause, 'Priority = ') - instr(cause, 'Host = ') - 11) peer,
substr(cause,
instr(cause, 'Priority = ') + 11,
instr(cause, 'reachable = ') -
instr(cause, 'Priority = ') - 13) priority
from dcc_sys_log
where cause like '%SC路由应答%'
and hopbyhop in (select distinct hopbyhop from dcc_sys_log)) c
where a.hopbyhop = b.hopbyhop
and a.hopbyhop = c.hopbyhop
and a.peer <> b.peer
and a.peer <> c.peer
and b.peer <> c.peer
and a.priority <> b.priority
and a.priority <> c.priority
and b.priority <> c.priority 执行计划: Execution Plan
----------------------------------------------------------
Plan hash value: 408096778 --------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1941 | 159K| | 18E(100)|999:59:59 |
|* 1 | TABLE ACCESS FULL | DCC_NE_CONFIG | 1 | 28 | | 3 (0)| 00:00:01 |
|* 2 | TABLE ACCESS FULL | DCC_NE_CONFIG | 1 | 28 | | 3 (0)| 00:00:01 |
|* 3 | TABLE ACCESS FULL | DCC_NE_CONFIG | 1 | 28 | | 3 (0)| 00:00:01 |
| 4 | HASH UNIQUE | | 1941 | 159K| | 18E(100)|999:59:59 |
| 5 | MERGE JOIN | | 18E| 15E| | 18E(100)|999:59:59 |
| 6 | MERGE JOIN | | 18E| 15E| | 32P(100)|999:59:59 |
| 7 | MERGE JOIN | | 1147T| 79P| | 1018T(100)|999:59:59 |
| 8 | SORT JOIN | | 746T| 36P| 85P| 101G (95)|999:59:59 |
|* 9 | HASH JOIN | | 746T| 36P| 70M| 4143M(100)|999:59:59 |
| 10 | TABLE ACCESS FULL | DCC_SYS_LOG | 4939K| 14M| | 14325 (1)| 00:02:52 |
|* 11 | HASH JOIN | | 151M| 7530M| 8448K| 366K (93)| 01:13:19 |
|* 12 | TABLE ACCESS FULL| DCC_SYS_LOG | 246K| 5547K| | 14352 (2)| 00:02:53 |
|* 13 | TABLE ACCESS FULL| DCC_SYS_LOG | 246K| 6994K| | 14352 (2)| 00:02:53 |
|* 14 | FILTER | | | | | | |
|* 15 | SORT JOIN | | 246K| 5547K| 15M| 16046 (2)| 00:03:13 |
|* 16 | TABLE ACCESS FULL | DCC_SYS_LOG | 246K| 5547K| | 14352 (2)| 00:02:53 |
|* 17 | SORT JOIN | | 4939K| 14M| 113M| 27667 (2)| 00:05:32 |
| 18 | TABLE ACCESS FULL | DCC_SYS_LOG | 4939K| 14M| | 14325 (1)| 00:02:52 |
|* 19 | SORT JOIN | | 4939K| 14M| 113M| 27667 (2)| 00:05:32 |
| 20 | TABLE ACCESS FULL | DCC_SYS_LOG | 4939K| 14M| | 14325 (1)| 00:02:52 |
-------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 1 - filter("PEER_NAME"=SUBSTR(:B1,INSTR(:B2,'Host = ')+7,INSTR(:B3,'Priority =
')-INSTR(:B4,'Host = ')-11))
2 - filter("PEER_NAME"=SUBSTR(:B1,INSTR(:B2,'Host = ')+7,INSTR(:B3,'Priority =
')-INSTR(:B4,'Host = ')-11))
3 - filter("PEER_NAME"=SUBSTR(:B1,INSTR(:B2,'Host = ')+7,INSTR(:B3,'Priority =
')-INSTR(:B4,'Host = ')-11))
9 - access("HOPBYHOP"="HOPBYHOP")
11 - access("HOPBYHOP"="HOPBYHOP")
filter(SUBSTR("CAUSE",INSTR("CAUSE",'Host = ')+7,INSTR("CAUSE",'Priority =
')-INSTR("CAUSE",'Host = ')-11)<>SUBSTR("CAUSE",INSTR("CAUSE",'Host =
')+7,INSTR("CAUSE",'Priority = ')-INSTR("CAUSE",'Host = ')-11) AND
SUBSTR("CAUSE",INSTR("CAUSE",'Priority = ')+11,INSTR("CAUSE",'reachable =
')-INSTR("CAUSE",'Priority = ')-13)<>SUBSTR("CAUSE",INSTR("CAUSE",'Priority =
')+11,INSTR("CAUSE",'reachable = ')-INSTR("CAUSE",'Priority = ')-13))
12 - filter("CAUSE" LIKE '%SC路由应答%')
13 - filter("CAUSE" LIKE '%SC路由应答%')
14 - filter(SUBSTR("CAUSE",INSTR("CAUSE",'Host = ')+7,INSTR("CAUSE",'Priority =
')-INSTR("CAUSE",'Host = ')-11)<>SUBSTR("CAUSE",INSTR("CAUSE",'Host =
')+7,INSTR("CAUSE",'Priority = ')-INSTR("CAUSE",'Host = ')-11) AND
SUBSTR("CAUSE",INSTR("CAUSE",'Host = ')+7,INSTR("CAUSE",'Priority =
')-INSTR("CAUSE",'Host = ')-11)<>SUBSTR("CAUSE",INSTR("CAUSE",'Host =
')+7,INSTR("CAUSE",'Priority = ')-INSTR("CAUSE",'Host = ')-11) AND
SUBSTR("CAUSE",INSTR("CAUSE",'Priority = ')+11,INSTR("CAUSE",'reachable =
')-INSTR("CAUSE",'Priority = ')-13)<>SUBSTR("CAUSE",INSTR("CAUSE",'Priority =
')+11,INSTR("CAUSE",'reachable = ')-INSTR("CAUSE",'Priority = ')-13) AND
SUBSTR("CAUSE",INSTR("CAUSE",'Priority = ')+11,INSTR("CAUSE",'reachable =
')-INSTR("CAUSE",'Priority = ')-13)<>SUBSTR("CAUSE",INSTR("CAUSE",'Priority =
')+11,INSTR("CAUSE",'reachable = ')-INSTR("CAUSE",'Priority = ')-13))
15 - access("HOPBYHOP"="HOPBYHOP")
filter("HOPBYHOP"="HOPBYHOP")
16 - filter("CAUSE" LIKE '%SC路由应答%')
17 - access("HOPBYHOP"="HOPBYHOP")
filter("HOPBYHOP"="HOPBYHOP")
19 - access("HOPBYHOP"="HOPBYHOP")
filter("HOPBYHOP"="HOPBYHOP") Statistics
----------------------------------------------------------
54 recursive calls
0 db block gets
128904 consistent gets
5549 physical reads
0 redo size
1017 bytes sent via SQL*Net to client
1422 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
0 rows processed ------
with t as
(select hopbyhop,
svcctx_id,
substr(cause,
instr(cause, 'Host = ') + 7,
instr(cause, 'Priority = ') - instr(cause, 'Host = ') - 11) peer,
substr(cause,
instr(cause, 'Priority = ') + 11,
instr(cause, 'reachable = ') -
instr(cause, 'Priority = ') - 13) selet * from t1,t2, t
where t....
oralce学习笔记(二)的更多相关文章
- WPF的Binding学习笔记(二)
原文: http://www.cnblogs.com/pasoraku/archive/2012/10/25/2738428.htmlWPF的Binding学习笔记(二) 上次学了点点Binding的 ...
- AJax 学习笔记二(onreadystatechange的作用)
AJax 学习笔记二(onreadystatechange的作用) 当发送一个请求后,客户端无法确定什么时候会完成这个请求,所以需要用事件机制来捕获请求的状态XMLHttpRequest对象提供了on ...
- [Firefly引擎][学习笔记二][已完结]卡牌游戏开发模型的设计
源地址:http://bbs.9miao.com/thread-44603-1-1.html 在此补充一下Socket的验证机制:socket登陆验证.会采用session会话超时的机制做心跳接口验证 ...
- JMX学习笔记(二)-Notification
Notification通知,也可理解为消息,有通知,必然有发送通知的广播,JMX这里采用了一种订阅的方式,类似于观察者模式,注册一个观察者到广播里,当有通知时,广播通过调用观察者,逐一通知. 这里写 ...
- java之jvm学习笔记二(类装载器的体系结构)
java的class只在需要的时候才内转载入内存,并由java虚拟机的执行引擎来执行,而执行引擎从总的来说主要的执行方式分为四种, 第一种,一次性解释代码,也就是当字节码转载到内存后,每次需要都会重新 ...
- Java IO学习笔记二
Java IO学习笔记二 流的概念 在程序中所有的数据都是以流的方式进行传输或保存的,程序需要数据的时候要使用输入流读取数据,而当程序需要将一些数据保存起来的时候,就要使用输出流完成. 程序中的输入输 ...
- 《SQL必知必会》学习笔记二)
<SQL必知必会>学习笔记(二) 咱们接着上一篇的内容继续.这一篇主要回顾子查询,联合查询,复制表这三类内容. 上一部分基本上都是简单的Select查询,即从单个数据库表中检索数据的单条语 ...
- NumPy学习笔记 二
NumPy学习笔记 二 <NumPy学习笔记>系列将记录学习NumPy过程中的动手笔记,前期的参考书是<Python数据分析基础教程 NumPy学习指南>第二版.<数学分 ...
- Learning ROS for Robotics Programming Second Edition学习笔记(二) indigo tools
中文译著已经出版,详情请参考:http://blog.csdn.net/ZhangRelay/article/category/6506865 Learning ROS for Robotics Pr ...
- Redis学习笔记二 (BitMap算法分析与BitCount语法)
Redis学习笔记二 一.BitMap是什么 就是通过一个bit位来表示某个元素对应的值或者状态,其中的key就是对应元素本身.我们知道8个bit可以组成一个Byte,所以bitmap本身会极大的节省 ...
随机推荐
- centos8.0安装docker
背景简介: 前两天红帽正式发布了RHEL8,网上同时也有了CentOS8,一直在接触容器方面,为了尝鲜,下载了CentOS8,并尝试安装docker,不料竟然还报了个错(缺少依赖),故及时记录一下,方 ...
- zabbix 同步ldap帐号脚本
1.界面配置ldap验证(略) 2.mysql导入ldap帐号信息 #!/usr/bin/env python# -*- coding:utf-8 -*- import pymysqlimport c ...
- [Gamma阶段]第七次Scrum Meeting
Scrum Meeting博客目录 [Gamma阶段]第七次Scrum Meeting 基本信息 名称 时间 地点 时长 第七次Scrum Meeting 19/06/3 大运村寝室6楼 25min ...
- WPF,回车即是tab
正在做的WPF项目,客户需要在文本框里输入后按回车即跳到下一个框框,和tab一样的 上网搜索了下解决方案:如下: 在文本框外围 的grid加上KeyDown事件,代码里写上: /// <summ ...
- Transaction-Mybatis源码
github地址:https://github.com/dchack/Mybatis-source-code-learn (欢迎star) TransactionFactory 官方文档: 在 MyB ...
- python 实现一个简单tcp epoll socket
python 实现一个epoll server #!/usr/bin/env python #-*- coding:utf-8 -*- import socket import select impo ...
- Mac home目录下,创建文件夹,修改权限
http://php-note.com/article/detail/35e782e145a94042923946cb142b5cd1 1.关闭 SIP 2.sudo mount -uw /
- 使用全备+binlog日志恢复数据库
1.binlog日志类型 Statement 只记录执行的sql语句,磁盘占用少,但是恢复的时候容易出问题.InodeDB不能使用Statement . Row 记录修改后的具体数据,磁盘占用较多 M ...
- xmlrpc与jsonrpc
RPC是Remote Procedure Call的缩写,翻译成中文就是远程过程调用,是一种在本地的机器上调用远端机器上的一个过程(方法)的技术,这个过程也被大家称为“分布式计算”,是为了提高各个分立 ...
- css3写下雨效果
css3写下雨效果<pre><div class="xiayuxiaoguo"></div></pre> <pre>.x ...