count(*) count(1) count(字段) 区别
count(*) count(1) count(字段) 区别
count(*)和count(字段)
count(*)和count(字段)使用的目的是不一样的,在必须要使用count(字段)的时候还是要用的,只是在统计表全部行数的时候count(*)就是最佳的选择了。
count(字段)就不一样了,为了去除字段列中包含的NULL行,mysql必须读取该col的每一行的值,然后确认下是否为NULL,然后在进行计数。因此count(*)应该是比count(字段)快的。
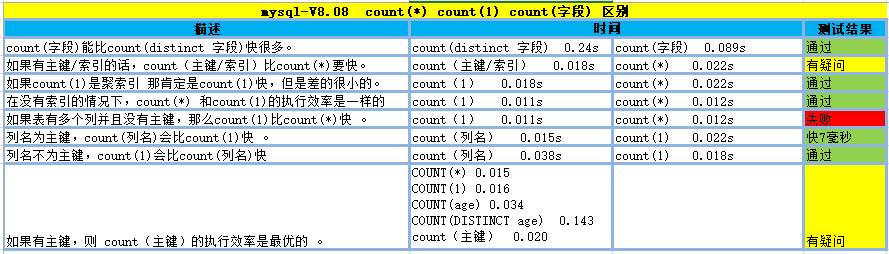
count(字段)能比count(distinct 字段)快很多。
如果有主键/索引的话,count(主键/索引)比count(*)要快。
如果你的表只有一个字段的话那count(*)就是最快的啦。
count(*) count(1) 两者比较
主要还是要count(1)所相对应的数据字段。
如果count(1)是聚索引,id,那肯定是count(1)快。但是差的很小的。
因为count(*)自动会优化指定到那一个字段。所以没必要去count(1),用count(*),sql会帮你完成优化的。
当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了!
从执行计划来看,count(1)和count(*)的效果是一样的。 但是在表做过分析之后,count(1)会比count(*)的用时少些(1w以内数据量),不过差不了多少。
在没有索引的情况下,count(*) 和count(1)的执行效率是一样的,不存在所谓的单列扫描和多列扫描的问题,因为count(*) 和count(1)都类似获取表的行数。
如果表有多个列并且没有主键,那么count(1) 和count(*)效率差不多 。
count(1) and count(字段) 区别是
(1) count(1) 会统计表中第一列所有的记录数,包含字段为null 的记录。
(2) count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。即不统计字段为null 的记录。
列名为主键,count(列名)会比count(1)快 。
列名不为主键,count(1)会比count(列名)快,因为count(列名)要计判断是否为null,而count(1)类似于获取表的行数。
如果有主键,则 count(主键)的执行效率是最优的 。
如果没有主键/索引的话,count(1)会比count(列名)快。
count(*) count(1) count(字段) 区别的更多相关文章
- 关于数据库优化1——关于count(1),count(*),和count(列名)的区别,和关于表中字段顺序的问题
1.关于count(1),count(*),和count(列名)的区别 相信大家总是在工作中,或者是学习中对于count()的到底怎么用更快.一直有很大的疑问,有的人说count(*)更快,也有的人说 ...
- Count(*), Count(1) 和Count(字段)的区别
1. count(1) and count(*) 当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了! 从执行计划来看,count(1)和count(*)的 ...
- MySQL学习笔记:count(1)、count(*)、count(字段)的区别
关于数据库中行数统计,无论是MySQL还是Oracle,都有一个函数可以使用,那就是COUNT. 但是,就是这个常用的COUNT函数,却暗藏着很多玄机,尤其是在面试的时候,一不小心就会被虐.不信的话请 ...
- count(1)、count(*)、count(字段)的区别
count(1)和count(*): 都为统计所有记录数,包括null 执行效率上:当数据量1W+时count(*)用时较少,1w以内count(1)用时较少 count(字段): 统计字段列的行数, ...
- COUNT(1)和COUNT(*)区别
项目经常用到count(1),但是和count(*)什么区别? 从下面实验结果来看,Count (*)和Count(1)查询结果是一样的,都包括对NULL的统计,而count(列名) 是不包括NULL ...
- select count(*)和select count(1)的区别 (转)
A 一般情况下,Select Count (*)和Select Count(1)两着返回结果是一样的 假如表沒有主键(Primary key), 那么count(1)比count(*)快, 如果有主键 ...
- count(*)、count(1)和count(列名)的区别
count(*).count(1)和count(列名)的区别 1.执行效果上: l count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL l count(1)包 ...
- count(1)、count(*)与count(列名)的执行区别
执行效果: 1. count(1) and count(*) 当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了! 从执行计划来看,count(1)和coun ...
- count(*)与count(1)、count('xxx')等在使用语法方面的区别
语法方面: 区别就是:没有区别!!! “*”号是通配符: “*”号是通配符 “*”号是通配符 使用"*"号和使用其他数字和任意非字段字符在使用方面没有任何语法错误; 至于效率方面是 ...
随机推荐
- 设计模式之JDK动态代理源码分析
这里查看JDK1.8.0_65的源码,通过debug学习JDK动态代理的实现原理 大概流程 1.为接口创建代理类的字节码文件 2.使用ClassLoader将字节码文件加载到JVM 3.创建代理类实例 ...
- golang测试
简述 Go语言中自带有一个轻量级的测试框架testing和自带的go test命令来实现单元测试和性能测试. go test [-c] [-i] [build flags] [packages] [f ...
- C程序回顾
1.字符串操作 C中,字符串以一维数组的方式存储.字符串结束标志\0,可用scanf("%s",c);输入,以空格作为输入字符串之间的分隔符. 字符串处理函数:puts(str); ...
- jmeter中如何引用Java
通过source()获取java文件: vars.get,获取参数type_id的值
- Mysql insert on update
数据库 Mysql INSERT INTO table (column_list) VALUES (value_list) ON DUPLICATE KEY UPDATE c1 = v1, c2 = ...
- python应用-craps赌博游戏
from random import randint face1=randint(1,6) face2=randint(1,6) first_point=face1+face2 print('玩家摇出 ...
- Elasticsearch 待办
日期格式:yyyy-MM-dd,改为 yyyy-MM-dd HH:mm:ss.SSS:实体类路径:https://github.com/cag2050/spring_boot_elasticsearc ...
- 12、Python函数高级(命名空间、作用域、装饰器)
一.名称空间和作用域 1.命名空间(Namespace) 命名空间是从名称到对象的映射,大部分的命名空间都是通过 Python 字典来实现的. 命名空间提供了在项目中避免名字冲突的一种方法.各个命名空 ...
- JavaScrip学习之路
本文参考资料:<JavaScript权威指南> 第六章:对象 6.1 创建对象 var book={ "main title":"javaScript&quo ...
- Tic-Tac-Toe-(暴力模拟)
https://ac.nowcoder.com/acm/contest/847/B #include<algorithm> #include<cstring> #include ...