Redis读写分离技术解析
背景
云数据库Redis版不管主从版还是集群规格,replica作为备库不对外提供服务,只有在发生HA的时候,replica提升为master后才承担读写流量。这种架构读写请求都在master上完成,一致性较高,但性能受到master数量的限制。经常有用户数据较少,但因为流量或者并发太高而不得不升级到更大的集群规格。
为满足读多写少的业务场景,最大化节约用户成本,云数据库Redis版推出了读写分离规格,为用户提供透明、高可用、高性能、高灵活的读写分离服务。
架构
Redis集群模式有redis-proxy、master、replica、HA等几个角色。在读写分离实例中,新增read-only replica角色来承担读流量,replica作为热备不提供服务,架构上保持对现有集群规格的兼容性。redis-proxy按权重将读写请求转发到master或者某个read-only replica上;HA负责监控DB节点的健康状态,异常时发起主从切换或重搭read-only replica,并更新路由。
一般来说,根据master和read-only replica的数据同步方式,可以分为两种架构:星型复制和链式复制。
星型复制
星型复制就是将所有的read-only replica直接和master保持同步,每个read-only replica之间相互独立,任何一个节点异常不影响到其他节点,同时因为复制链比较短,read-only replica上的复制延迟比较小。
Redis是单进程单线程模型,主从之间的数据复制也在主线程中处理,read-only replica数量越多,数据同步对master的CPU消耗就越严重,集群的写入性能会随着read-only replica的增加而降低。此外,星型架构会让master的出口带宽随着read-only replica的增加而成倍增长。Master上较高的CPU和网络负载会抵消掉星型复制延迟较低的优势,因此,星型复制架构会带来比较严重的扩展问题,整个集群的性能会受限于master。
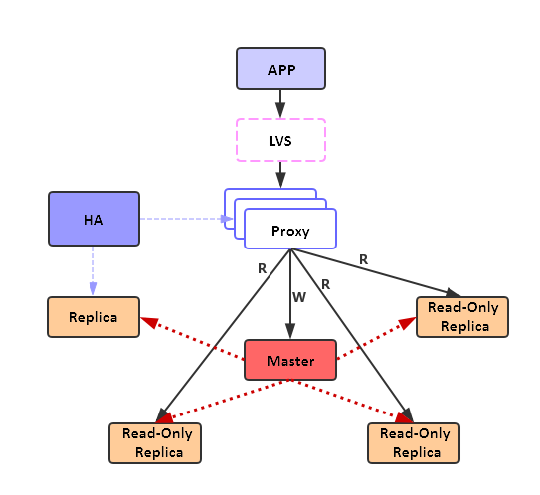
链式复制
链式复制将所有的read-only replica组织成一个复制链,如下图所示,master只需要将数据同步给replica和复制链上的第一个read-only replica。
链式复制解决了星型复制的扩展问题,理论上可以无限增加read-only replica的数量,随着节点的增加整个集群的性能也可以基本上呈线性增长。
链式复制的架构下,复制链越长,复制链末端的read-only replica和master之间的同步延迟就越大,考虑到读写分离主要使用在对一致性要求不高的场景下,这个缺点一般可以接受。但是如果复制链中的某个节点异常,会导致下游的所有节点数据都会大幅滞后。更加严重的是这可能带来全量同步,并且全量同步将一直传递到复制链的末端,这会对服务带来一定的影响。为了解决这个问题,读写分离的Redis都使用阿里云优化后的binlog复制版本,最大程度的降低全量同步的概率。
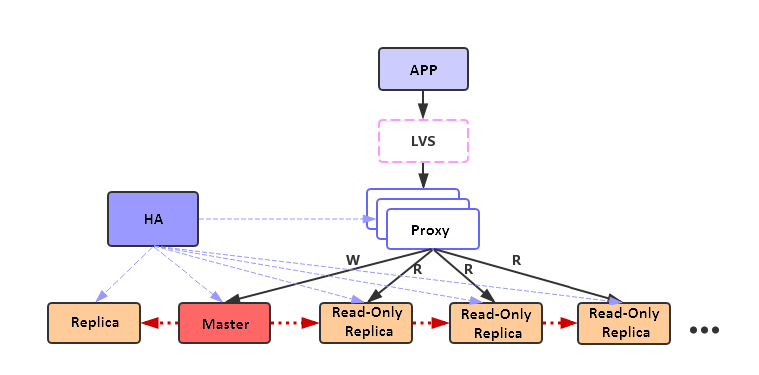
结合上述的讨论和比较,Redis读写分离选择链式复制的架构。
Redis读写分离优势
透明兼容
读写分离和普通集群规格一样,都使用了redis-proxy做请求转发,多分片令使用存在一定的限制,但从主从升级单分片读写分离,或者从集群升级到多分片的读写分离集群可以做到完全兼容。
用户和redis-proxy建立连接,redis-proxy会识别出客户端连接发送过来的请求是读还是写,然后按照权重作负载均衡,将请求转发到后端不同的DB节点中,写请求转发给master,读操作转发给read-only replica(master默认也提供读,可以通过权重控制)。
用户只需要购买读写分离规格的实例,直接使用任何客户端即可直接使用,业务不用做任何修改就可以开始享受读写分离服务带来的巨大性能提升,接入成本几乎为0。
高可用
高可用模块(HA)监控所有DB节点的健康状态,为整个实例的可用性保驾护航。master宕机时自动切换到新主。如果某个read-only replica宕机,HA也能及时感知,然后重搭一个新的read-only replica,下线宕机节点。
除HA之外,redis-proxy也能实时感知每个read-only replica的状态。在某个read-only replica异常期间,redis-proxy会自动降低这个节点的权重,如果发现某个read-only replica连续失败超过一定次数以后,会暂时屏蔽异常节点,直到异常消失以后才会恢复其正常权重。
redis-proxy和HA一起做到尽量减少业务对后端异常的感知,提高服务可用性。
高性能
对于读多写少的业务场景,直接使用集群版本往往不是最合适的方案,现在读写分离提供了更多的选择,业务可以根据场景选择最适合的规格,充分利用每一个read-only replica的资源。
目前单shard对外售卖1 master + 1/3/5 read-only replica多种规格(如果有更大的需求可以提工单反馈),提供60万QPS和192 MB/s的服务能力,在完全兼容所有命令的情况下突破单机的资源限制。后续将去掉规格限制,让用户根据业务流量随时自由的增加或减少read-only replica数量。
| 规格 | QPS | 带宽 |
|---|---|---|
| 1 master | 8-10万读写 | 10-48 MB |
| 1 master + 1 read-only replica | 10万写 + 10万读 | 20-64 MB |
| 1 master + 3 read-only replica | 10万写 + 30万读 | 40-128 MB |
| 1 master + 5 read-only replica | 10万写 + 50万读 | 60-192 MB |
Redis读写分离技术解析的更多相关文章
- MySQL读写分离技术
1.简介 当今MySQL使用相当广泛,随着用户的增多以及数据量的增大,高并发随之而来.然而我们有很多办法可以缓解数据库的压力.分布式数据库.负载均衡.读写分离.增加缓存服务器等等.这里我们将采用读写分 ...
- MySQL主从复制技术与读写分离技术amoeba应用
MySQL主从复制技术与读写分离技术amoeba应用 前言:眼下在搭建一个人才站点,估计流量会非常大,须要用到分布式数据库技术,MySQL的主从复制+读写分离技术.读写分离技术有官方的MySQL-pr ...
- Django中MySQL读写分离技术
最近需要用到Django的MySQL读写分离技术,查了一些资料,把方法整理了下来. 在Django里实现对MySQL的读写分离,实际上就是将不同的读写请求按一定的规则路由到不同的数据库上(可以是不同类 ...
- Redis读写分离(三)
1.redis高并发跟整个系统的高并发之间的关系 redis,要搞高并发的话,不可避免,要把底层的缓存搞得很好 mysql,高并发,做到了,那么也是通过一系列复杂的分库分表,订单系统,事务要求的,QP ...
- redis读写分离及可用性设计
Redis缓存架构设计 对于下面两个架构图,有如下想法: 1)redis主从复制模式,为了解决master读写压力,对master进行写操作,对slave进行读操作. 2)而在分片集群中,如果对部分分 ...
- Redis读写分离的简单配置
Master进行写操作,可能只需要一台Master.进行写操作,关闭数据持久化. Slave进行读操作,可能需要多台Slave.进行读操作,打开数据持久化. 假设初始配置有Master服务器为A,sl ...
- 【MySQL】剖析MySQL读写分离技术
主从技术的一个基本流程图: 如何实现主从复制的呢: MySQL Master(主节点) 1>当一个请求来时,首先由[mysqld]写入到我们的主[data]中 2>然后[mysqld]将 ...
- redis 主从复制+读写分离+哨兵
1.redis读写分离应用场景 当数据量变得庞大的时候,读写分离还是很有必要的.同时避免一个redis服务宕机,导致应用宕机的情况,我们启用sentinel(哨兵)服务,实现主从切换的功能.redis ...
- 在 Istio 中实现 Redis 集群的数据分片、读写分离和流量镜像
Redis 是一个高性能的 key-value 存储系统,被广泛用于微服务架构中.如果我们想要使用 Redis 集群模式提供的高级特性,则需要对客户端代码进行改动,这带来了应用升级和维护的一些困难.利 ...
随机推荐
- TensorFlow的数据读取机制
一.tensorflow读取机制图解 首先需要思考的一个问题是,什么是数据读取?以图像数据为例,读取的过程可以用下图来表示 假设我们的硬盘中有一个图片数据集0001.jpg,0002.jpg,0003 ...
- 【学习笔记】字符串—马拉车(Manacher)
[学习笔记]字符串-马拉车(Manacher) 一:[前言] 马拉车用于求解连续回文子串问题,效率极高. 其核心思想与 \(kmp\) 类似:继承. --引自 \(yyx\) 学姐 二:[算法原理] ...
- 利用kibana学习 elasticsearch restful api (DSL)
利用kibana学习 elasticsearch restful api (DSL) 1.了解elasticsearch基本概念Index: databaseType: tableDocument: ...
- Caused by: java.lang.ClassCastException: org.springframework.web.SpringServletContainerInitializer cannot be cast to javax.servlet.ServletContainerInitializer。。。。。检查一下servlet-api是否冲突了?
原因:jar包发生冲突.在我的pom.xml文件中 <dependency> <groupId>javax.servlet</groupId> ...
- 好久没写原生的PHP调用数据库代码了分享个
好久没写原生的PHP代码调用数据库了 eader("Content-type: text/html; charset=utf-8"); $time=$symptoms=$attr= ...
- eclipse使用SVN来检索项目
file——import——搜索框输入SVN——点击SVN检索项目 ——输入想要检索的地址
- 大数据Excel导出方案
static void Main(string[] args) { Excel.Application app = new Excel.Application(); Excel._Workbook r ...
- NetCoreApi框架搭建三、JWT授权验证)
1.首先还是粘贴大神的链接 虽然说大神的博客已经讲得很详细了,但是此处还是自己动手好点. 首先配置Startup Swagger的验证 2.新建一个项目存放tokenmodel和生成token并且存入 ...
- 浅谈Nginx以及特性
Nginx以及特性 1.Nginx是什么? Nginx是一个高性能的HTTP和反向代理轻量级web服务器,特点:占用内存少,处理并发能力强.Nginx专为性能优化而开发,性能是其最重要的考量 ,能经受 ...
- Java中的equals与==
package demo; public class Test { public static void main(String[] args) { String str1 = new String( ...