MapReduce如何调优
Map阶段优化
1、在代码书写时优化,如尽量避免在map端创建变量等,因为map端是循环调用的,创建变量会增加内存的消耗,尽量将创建变量放到setup方法中
2、配置调优,可以在集群配置和任务运行时进行调优,如:调优总的原则给shufflfflffle过程尽量多提供内存空间,在map端,可以通过避免多次溢出写磁盘来获得最佳性能(相关配置io.sort.*,io.sort.mb),在reduce端,中间数据全部驻留在内存时,就能获得最佳性能,但是默认情况下,这是不可能发生的,因为一般情况所有内存都预留给reduce含函数(如需修改 需要配置mapred.inmem.merge.threshold,mapred.job.reduce.input.buffffer.percent)如果能够根据情况对shufflfflffle过程进行调优,对于提供MapReduce性能很有帮助。 一个通用的原则是给shufflfflffle过程分配尽可能大的内存,当然你需要确保map和reduce有足够的内存来运行业务逻辑。因此在实现Mapper和Reducer时,应该尽量减少内存的使用,例如避免在Map中不断地叠加。 运行map和reduce任务的JVM,内存通过mapred.child.java.opts属性来设置,尽可能设大内存。容器的内存大小通过mapreduce.map.memory.mb和mapreduce.reduce.memory.mb来设置,默认都是1024M。可以通过以下方法提高排序和缓存写入磁盘的效率:
1、调整mapreduce.task.io.sort.mb大小,从而避免或减少缓存溢出的数量。当调整这个参数时,最好同时检测Map任务的JVM的堆大小,并必要的时候增加堆空间。
2、mapreduce.task.io.sort.factor属性的值提高100倍左右,这可以使合并处理更快,并减少磁盘的访问。
3、为K-V提供一个更高效的自定义序列化工具,序列化后的数据占用空间越少,缓存使用
率就越高。
4、提供更高效的Combiner(合并器),使Map任务的输出结果聚合效率更高。
5、提供更高效的键比较器和值的分组比较器。输出依赖于作业中Reduce任务的数量,下面是一些优化建议:
1、压缩输出,以节省存储空间,同时也提升HDFS写入吞吐量 2、避免写入带外端文件(out-of[1]band side fifile)作为Reduce任务的输出 3、根据作业输出文件的消费者的需求,可以分割的压缩技术或许适合
4、以较大块容量设置,写入较大的HDFS文件,有助于减少Map任务数Map/Reduce端调优通用优化 Hadoop默认使用4KB作为缓冲,这个算是很小的,可以通过io.fifile.buffffer.size来调高缓冲池大小。map端优化 避免写入多个spill文件可能达到最好的性能,一个spill文件是最好的。通过估计map的输出大小,设置合理的mapreduce.task.io.sort.*属性,使得spill文件数量最小。例如尽可能调大mapreduce.task.io.sort.mb。
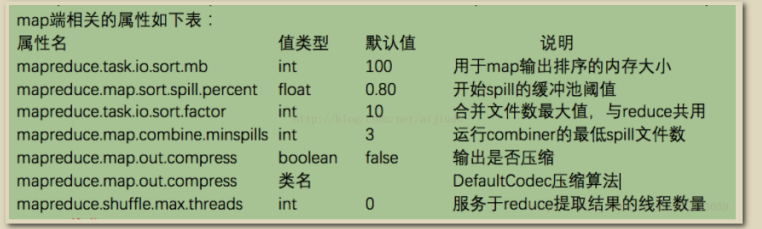
reduce端优化
如果能够让所有数据都保存在内存中,可以达到最佳的性能。通常情况下,内存都保留给reduce函数,但是如果reduce函数对内存需求不是很高,将mapreduce.reduce.merge.inmem.threshold(触发合并的map输出文件数)设为0,mapreduce.reduce.input.buffffer.percent(用于保存map输出文件的堆内存比例)设为1.0,可以达到很好的性能提升。在TB级别数据排序性能测试中,Hadoop就是通过将reduce的中间数据都保存在内存中胜利的。

内存调优
Hadoop处理数据时,出现内存溢出的处理方法?(内存调优)
1、Mapper/Reducer阶段JVM内存溢出(一般都是堆)
1)JVM堆(Heap)内存溢出:堆内存不足时,一般会抛出如下异常:
第一种:“java.lang.OutOfMemoryError:” GC overhead limit exceeded;
第二种:“Error: Java heapspace”异常信息;
第三种:“running beyondphysical memory limits.Current usage: 4.3 GB of 4.3 GBphysical memoryused; 7.4 GB of 13.2 GB virtual memory used. Killing container”。
2) 栈内存溢出:抛出异常为:java.lang.StackOverflflowError
常会出现在SQL中(SQL语句中条件组合太多,被解析成为不断的递归调用),或MR代码中有递归调用。这种深度的递归调用在栈中方法调用链条太长导致的。出现这种错误一般说明程序写的有问题。
2、MRAppMaster内存不足
如果作业的输入的数据很大,导致产生了大量的Mapper和Reducer数量,致使MRAppMaster(当前作业的管理者)的压力很大,最终导致MRAppMaster内存不足,作业跑了一般出现了OOM信息
异常信息为:
Exception: java.lang.OutOfMemoryError thrown from theUncaughtExceptionHandler in thread
"Socket Reader #1 for port 30703
Halting due to Out Of Memory Error...
Halting due to Out Of Memory Error...
Halting due to Out Of Memory Error...
3、非JVM内存溢出
异常信息一般为:java.lang.OutOfMemoryError:Direct buffffer memory
自己申请使用操作系统的内存,没有控制好,出现了内存泄露,导致的内存溢出。错误解决参数调优
1、Mapper/Reducer阶段JVM堆内存溢出参数调优
目前MapReduce主要通过两个组参数去控制内存:(将如下参数调大)
Maper:
mapreduce.map.java.opts=-Xmx2048m(默认参数,表示jvm堆内存,注意是mapreduce不是mapred)
mapreduce.map.memory.mb=2304(container的内存)
Reducer:
mapreduce.reduce.java.opts=-=-Xmx2048m(默认参数,表示jvm堆内存)
mapreduce.reduce.memory.mb=2304(container的内存)
注意:因为在yarn container这种模式下,map/reduce task是运行在Container之中的,所以上面提到的mapreduce.map(reduce).memory.mb大小都大于mapreduce.map(reduce).java.opts值的大小。mapreduce.{map|reduce}.java.opts能够通过Xmx设置JVM最大的heap的使用,一般设置为0.75倍的memory.mb,因为需要为java code等预留些空间
2、MRAppMaster:
yarn.app.mapreduce.am.command-opts=-Xmx1024m(默认参数,表示jvm堆内存)yarn.app.mapreduce.am.resource.mb=1536(container的内存)注意在Hive ETL里面,按照如下方式设置:set mapreduce.map.child.java.opts="-Xmx3072m"(注:-Xmx设置时一定要用引号,不加引号各种错误)set mapreduce.map.memory.mb=3288
或
set mapreduce.reduce.child.java.opts="xxx"
set mapreduce.reduce.memory.mb=xxx
涉及YARN参数:
•yarn.scheduler.minimum-allocation-mb (最小分配单位1024M)
•yarn.scheduler.maximum-allocation-mb (8192M)
•yarn.nodemanager.vmem-pmem-ratio (虚拟内存和物理内存之间的比率默认 2.1)
•yarn.nodemanager.resource.memory.mb
Yarn的ResourceManger(简称RM)通过逻辑上的队列分配内存,CPU等资源给application,默认情况下RM允许最大AM申请Container资源为8192MB(“yarn.scheduler.maximum-allocation-mb“),默认情况下的最小分配资源为1024M(“yarn.scheduler.minimum-allocation-mb“),AM只能以增量(”yarn.scheduler.minimum-allocation-mb“)和不会超过(“yarn.scheduler.maximum-allocationmb“)的值去向RM申请资源,AM负责将(“mapreduce.map.memory.mb“)和
(“mapreduce.reduce.memory.mb“)的值规整到能被(“yarn.scheduler.minimum-allocation-mb“)整除,RM会拒绝申请内存超过8192MB和不能被1024MB整除的资源请求。(不同配置会有不同)
数据输入优化阶段:
(1)合并小文件:在执行MR任务前将小文件进行合并,大量的小文件会产生大量的Map任务,增大Map任务装载次数,而任务的装载比较耗时,从而导致MR运行较慢。
(2)采用CombineTextInputFormat来作为输入,解决输入端大量小文件场景。
2 HDFS小文件解决方案
HDFS小文件弊端
HDFS上每个文件都要在NameNode上建立一个索引,这个索引的大小约为150byte,这样当小文件比较多的时候,就会产生很多的索引文件,一方面会大量占用NameNode的内存空间,另一方面就是索引文件过大使得索引速度变慢。
小文件的优化无非以下几种方式:
(1)在数据采集的时候,就将小文件或小批数据合成大文件再上传HDFS。
(2)在业务处理之前,在HDFS上使用MapReduce程序对小文件进行合并。
(3)在MapReduce处理时,可采用CombineTextInputFormat提高效率。
小文件解决方案
1.Hadoop Archive
是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将多个小文件打包成一个HAR文件,这样就减少了NameNode的内存使用。
2.Sequence File
Sequence File由一系列的二进制key/value组成,如果key为文件名,value为文件内容,则可以将大批小文件合并成一个大文件。
3.CombineFileInputFormat
CombineFileInputFormat是一种新的InputFormat,用于将多个文件合并成一个单独的Split,另外,它会考虑数据的存储位置。
4.开启JVM重用
对于大量小文件Job,可以开启JVM重用会减少45%运行时间。
JVM重用原理:一个Map运行在一个JVM上,开启重用的话,该Map在JVM上运行完毕后,JVM继续运行其他Map。
具体设置:mapreduce.job.jvm.numtasks值在10-20之间。
MapReduce如何调优的更多相关文章
- MapReduce参数调优
原文链接:http://blog.javachen.com/2014/06/24/tuning-in-mapreduce/ 本文主要记录Hadoop 2.x版本中MapReduce参数调优,不涉及Ya ...
- [大牛翻译系列]Hadoop(16)MapReduce 性能调优:优化数据序列化
6.4.6 优化数据序列化 如何存储和传输数据对性能有很大的影响.在这部分将介绍数据序列化的最佳实践,从Hadoop中榨出最大的性能. 压缩压缩是Hadoop优化的重要部分.通过压缩可以减少作业输出数 ...
- [大牛翻译系列]Hadoop(15)MapReduce 性能调优:优化MapReduce的用户JAVA代码
6.4.5 优化MapReduce用户JAVA代码 MapReduce执行代码的方式和普通JAVA应用不同.这是由于MapReduce框架为了能够高效地处理海量数据,需要成百万次调用map和reduc ...
- [大牛翻译系列]Hadoop(11)MapReduce 性能调优:诊断一般性能瓶颈
6.2.4 任务一般性能问题 这部分将介绍那些对map和reduce任务都有影响的性能问题. 技术37 作业竞争和调度器限制 即便map任务和reduce任务都进行了调优,但整个作业仍然会因为环境原因 ...
- [大牛翻译系列]Hadoop(8)MapReduce 性能调优:性能测量(Measuring)
6.1 测量MapReduce和环境的性能指标 性能调优的基础系统的性能指标和实验数据.依据这些指标和数据,才能找到系统的性能瓶颈.性能指标和实验数据要通过一系列的工具和过程才能得到. 这部分里,将介 ...
- MapReduce性能调优记录
MapReduce原理 要知道怎么对MapReduce作业进行调优前提条件是需要对Map-Reduce的过程了然于胸. Map-Reduce运行原理图: Map Side 1.从磁盘读取数据并分片 默 ...
- MapReduce内存调优
内存调优 Hadoop处理数据时,出现内存溢出的处理方法?(内存调优) 1.Mapper/Reducer阶段JVM内存溢出(一般都是堆) 1)JVM堆(Heap)内存溢出:堆内存不足时,一般会抛出如下 ...
- [大牛翻译系列]Hadoop(14)MapReduce 性能调优:减小数据倾斜的性能损失
6.4.4 减小数据倾斜的性能损失 数据倾斜是数据中的常见情况.数据中不可避免地会出现离群值(outlier),并导致数据倾斜.这些离群值会显著地拖慢MapReduce的执行.常见的数据倾斜有以下几类 ...
- [大牛翻译系列]Hadoop(13)MapReduce 性能调优:优化洗牌(shuffle)和排序阶段
6.4.3 优化洗牌(shuffle)和排序阶段 洗牌和排序阶段都很耗费资源.洗牌需要在map和reduce任务之间传输数据,会导致过大的网络消耗.排序和合并操作的消耗也是很显著的.这一节将介绍一系列 ...
随机推荐
- PatchMatch笔记
关键词: slanted surfaces: 倾斜的平面 fronto-parallel windows: ??? remedy: 补救 disparity: 视差图 对每一个像素都估计一个3D平面. ...
- Spring中Bean命名源码分析
Spring中Bean命名源码分析 一.案例代码 首先是demo的整体结构 其次是各个部分的代码,代码本身比较简单,不是我们关注的重点 配置类 /** * @Author Helius * @Crea ...
- Linux基础(01)开发环境的搭建
内核源码下载 : https://blog.csdn.net/u011375704/article/details/81866427 1.在虚拟机安装Ubuntu 14.04版本 (安装时设置好用户名 ...
- Scala Collection Method
接收一元函数 map 转换元素,主要应用于不可变集合 (1 to 10).map(i => i * i) (1 to 10).flatMap(i => (1 to i).map(j =&g ...
- Jenkins教程(四)安装BlueOcean与Maven构建
前言 本文旨在使用BlueOcean实现构建可视化与使用Maven构建上一节Jenkins教程(三)添加凭据与流水线拉取Git代码拉下来的代码 什么是Blue Ocean Blue Ocean 重新思 ...
- 【题解】Luogu P5471 [NOI2019]弹跳
原题传送门 先考虑部分分做法: subtask1: 暴力\(O(nm)\)枚举,跑最短路 subtask2: 吧一行的点压到vector中并排序,二分查找每一个弹跳装置珂以到达的城市,跑最短路 sub ...
- mvc中hangfire全局简单配置
public void Configuration(IAppBuilder app) { ConfigureAuth(app); //指定使用Sql ...
- asp.net core web的导入导出excel功能
这里主要记录下asp.net core web页面上进行导入导出excel的操作. 主要是导入,因为现在使用的很多前端框架(例如kendo ui)本身就有导出的功能. 这里使用到EPPlus.Core ...
- session中删除数组中的某一个值 - 购物车例子 - jsp
这篇随笔简单的讲一下在session中移除数组中的某一项内容,比如这里有一个购物车其中有两件商品,需要移除其中洗发水这一件商品. 其实在这个session对象中存储了一个数组,在订购页面时选择商品加入 ...
- String类的方法应用
String类的几个方法的应用示例: using System;using System.Collections.Generic;using System.Linq;using System.Text ...