Redis和数据库一致性
1、实时同步
对强一致要求比较高的,应采用实时同步方案,即查询缓存查询不到再从DB查询,保存到缓存;
更新缓存时,先更新数据库,再将缓存的设置过期(建议不要去更新缓存内容,直接设置缓存过期)。
为什么不去更新缓存内容,而是设置缓存过期呢?
答:我们先来了解两个概念
1.1. 缓存穿透
缓存穿透是指查询一个数据库中一定不存在的数据,由于缓存是不命中时需要从数据库中查询,查不到数据则不写入缓存,这就将导致这个不存在的数据每次请求都要到数据库中查询,造成缓存穿透。
你可以通俗的理解,直接把缓存穿透了,没有利用到缓存。。。
举例:
If(redis存在此key){
查询redis值
}else{
查询数据库,如果能查到数据,就写入到redis中
}
这一段代码逻辑就会造成缓存穿透的恶果。。
你想,假设这个查询数据库中永远没有值,那么这个redis中这个key是不是就不会创建,那么代码就永远只走查询数据库这段代码,跟redis没关系了。。
解决缓存穿透很简单,就是数据库查询不到也要缓存结果,不过缓存结果赋值为空而已,但它的过期时间会很短,最长不超过五分钟。
If(redis存在此key){
Var redisValue=查询redis值
返回值
}else{
查询数据库.
If(能查到数据){
就写入到redis中
}else{
如果查询不到,也写到redis中,只不过值是空值
}
}
要注意的点:
第一,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间 ( 如果是攻击,问题更严重 ),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
第二,缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为 5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
第三,Insert时需要事先移除要查询的key,否则即便DB中有值也查询不到(当然也可以设置空缓存的过期时间)
1.2. 缓存雪崩
如果缓存集中在一段时间内失效,发生大量的缓存穿透,所有的查询都落在数据库上,造成了缓存雪崩。
这个没有完美解决办法,但可以分析用户行为,尽量让失效时间点均匀分布。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。
解决方法
1. 加锁排队. 限流-- 限流算法. 1.计数 2.滑动窗口 3. 令牌桶Token Bucket 4.漏桶 leaky bucket [1]
在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
SETNX,是「SET if Not eXists」的缩写,也就是只有不存在的时候才设置,可以利用它来实现锁的效果。
2.数据预热
可以通过缓存reload机制,预先去更新缓存,再即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀
3.做二级缓存,或者双缓存策略。
A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期。
4.缓存永远不过期
这里的“永远不过期”包含两层意思:
(1) 从缓存上看,确实没有设置过期时间,这就保证了,不会出现热点key过期问题,也就是“物理”不过期。
(2) 从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期.
从实战看,这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,但是对于一般的互联网功能来说这个还是可以忍受。
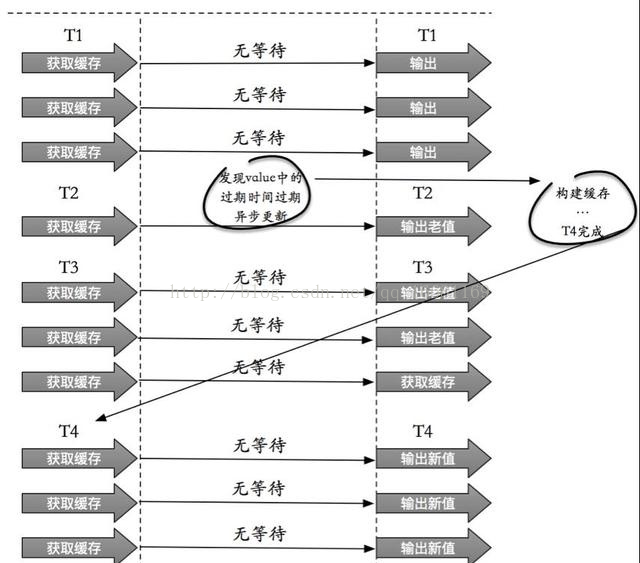
1.3. 热点Key
热点key:某个key访问非常频繁,当key失效的时候有大量的线程来构建缓存,导致负载增加,系统崩溃。
解决办法:
1、使用锁,单机用synchronized,lock等,分布式用分布式锁
2、缓存过期时间不设置,而是设置在key对应的value里。如果检测到存的时间超过过期时间则异步更新缓存
3、在value设置一个比过期时间t0小的过期时间值t1,当t1过期的时候,延长t1并做更新缓存操作
4、设置标签缓存,标签缓存设置过期时间,标签缓存过期后,需要异步更新实际缓存
2、异步队列
对于并发程度较高的,可采用异步队列的方式同步,可采用kafka等消息中间件处理消息生产和消费。
3、使用阿里的同步工具canal
canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB)。
起源:早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求。不过早期的数据库同步业务,主要是基于trigger的方式获取增量变更,不过从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务,从此开启了一段新纪元。
基于日志增量订阅&消费支持的业务:
数据库镜像
数据库实时备份
多级索引 (卖家和买家各自分库索引)
search build
业务cache刷新
价格变化等重要业务消息
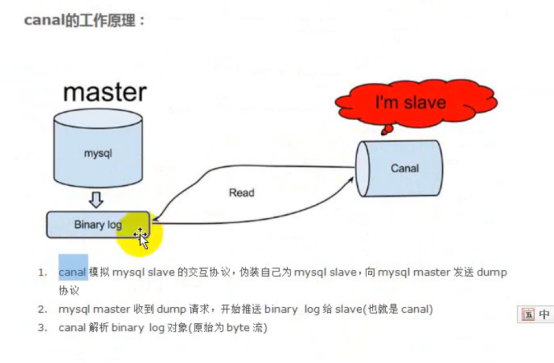
简单来说,Canal 会将自己伪装成 MySQL 从节点(Slave),并从主节点(Master)获取 Binlog,解析和贮存后供下游消费端使用。Canal 包含两个组成部分:服务端和客户端。服务端负责连接至不同的 MySQL 实例,并为每个实例维护一个事件消息队列;客户端则可以订阅这些队列中的数据变更事件,处理并存储到数据仓库中
原理相对比较简单:
- canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
- mysql master收到dump请求,开始推送binary log给slave(也就是canal)
- canal解析binary log对象(原始为byte流)

Redis和数据库一致性的更多相关文章
- Redis与数据库同步问题
缓存数据与持久化数据的一致性,这个问题总结了一下(看到了一个不错的博文),其实就是读和写,还有就是要注意谁先谁后的问题. Redis 是一个高性能的key-value数据库. redis的出现,很大程 ...
- Redis 当成数据库在使用和可靠的分布式锁,Redlock 真的可行么?
怎样做可靠的分布式锁,Redlock 真的可行么? https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html ...
- Redis和数据库 数据同步问题
Redis和数据库同步问题 缓存充当数据库 比如说Session这种访问非常频繁的数据,就适合采用这种方案:当然了,既然没有涉及到数据库,那么也就不会存在一致性问题: 缓存充当数据库热点缓存 读操作 ...
- 如何保证Redis与数据库的数据一致性
一般来说,只要你用到了缓存,不管是Redis还是memcache,就可能会涉及到数据库缓存与数据的一致性问题,这里我们以Redis为例. 我们该如何保证Redis与数据库的一致性呢? So easy: ...
- Redis单机数据库的实现原理
本文主要介绍Redis的数据库结构,Redis两种持久化的原理:RDB持久化.AOF持久化,以及Redis事件分类及执行原理.最后,分别介绍了单机班Redid客户端和Redis服务器的使用和实现原理. ...
- Redis和数据库的数据一致性问题
在数据读多写少的情况下作为缓存来使用,恐怕是Redis使用最普遍的场景了.当使用Redis作为缓存的时候,一般流程是这样的. 如果缓存在Redis中存在,即缓存命中,则直接返回数据 如果Redis中没 ...
- Redis 与 数据库处理数据的两种模式
Redis 是一个高性能的key-value数据库. redis的出现,很大程度补偿了memcached这类key-value存储的不足,在部 分场合可以对关系数据库起到很好的补充作用.它提供了Pyt ...
- 快速搭建Redis缓存数据库
之前一篇随笔——Redis安装及主从配置已经详细的介绍过Redis的安装于配置.本文要讲的是如何在已经安装过Redis的机器上快速的创建出一个新的Redis缓存数据库. 一.环境介绍 1) Linux ...
- Redis 与 数据库处理数据的两种模式(转)
Redis 是一个高性能的key-value数据库. redis的出现,很大程度补偿了memcached这类key-value存储的不足,在部 分场合可以对关系数据库起到很好的补充作用.它提供了Pyt ...
随机推荐
- ng-zorror-antd------Input输入框
使用 ng-zorror-antd 来美化界面,带着问题挖掘技术: 一:基本使用 效果图: 问题一:如何人为控制输入框长度,如上效果图,让一个输入框长,一个输入框短?(注意:该输入框是最简单的输入框, ...
- Linux服务管理之ntp
NTP是网络时间协议(Network Time Protocol),它是用来同步网络中各个计算机的时间的协议. 在计算机的世界里,时间非常地重要,例如对于火箭发射这种科研活动,对时间的统一性和准确性要 ...
- github1:workq
https://github.com/taf2/workq https://github.com/erez-strauss/lockfree_mpmc_queue 多生产者 多消费者 队列 < ...
- python面试题以及答案
目录 Python基础篇 1:为什么学习Python 2:通过什么途径学习Python 3:谈谈对Python和其他语言的区别 Python的优势: 4:简述解释型和编译型编程语言 5:Python的 ...
- python中的__init__(self)是什么意思呢
python中的__init__(self)是什么意思呢 init(self)这个时类的初始化函数 1 2 3 4 class Obj: def init(self): print 1 obj = O ...
- IEnumerable、IEnumerator接口(如何增加迭代器功能)
IEnumerable.IEnumerator接口封装了迭代器功能,有了它,我们不需要将内部集合暴露出去,外界只需要访问我的迭代器接口方法即可遍历数据. 在C#中,使用foreach语句来遍历集合.f ...
- Margin和padding失效
太久不写原生果然不行,Margin和padding对div有效,对span失效,原因就不解释了(元素性质,块状之类的)
- js面向对象杂谈
**万丈高楼平地起** 1. 通过命名规范创建具有私有属性的对象: 以__开头的对象为私有对象,但是实际是能访问到的. 2. 通过自执行函数中,return出来一个对象,return旁边的地方都可以写 ...
- SWA2G422&485JK2G基础篇: 硬件使用说明
开发板板载介绍(当前使用的测试板,以后期最终版为准) 一,实物图 硬件说明 一,开发板主控芯片说明: 1. 单片机: STM32F103RET6 2. GPRS模块: Air202 二,开发板外设说明 ...
- mysql实现行转列功能
实现从图一转行成图二的功能: 图一: 图二: 建表语句: CREATE TABLE `t_user_score` ( `id` ) NOT NULL AUTO_INCREMENT COMMENT '主 ...