Bagging 和RF的区别
跑训练无聊看了看别人的面经,发现自己一时半会答不上来,整理一下。
一、Bagging介绍
先看一个Bagging的一个概念图(图来自https://www.cnblogs.com/nickchen121/p/11214797.html)
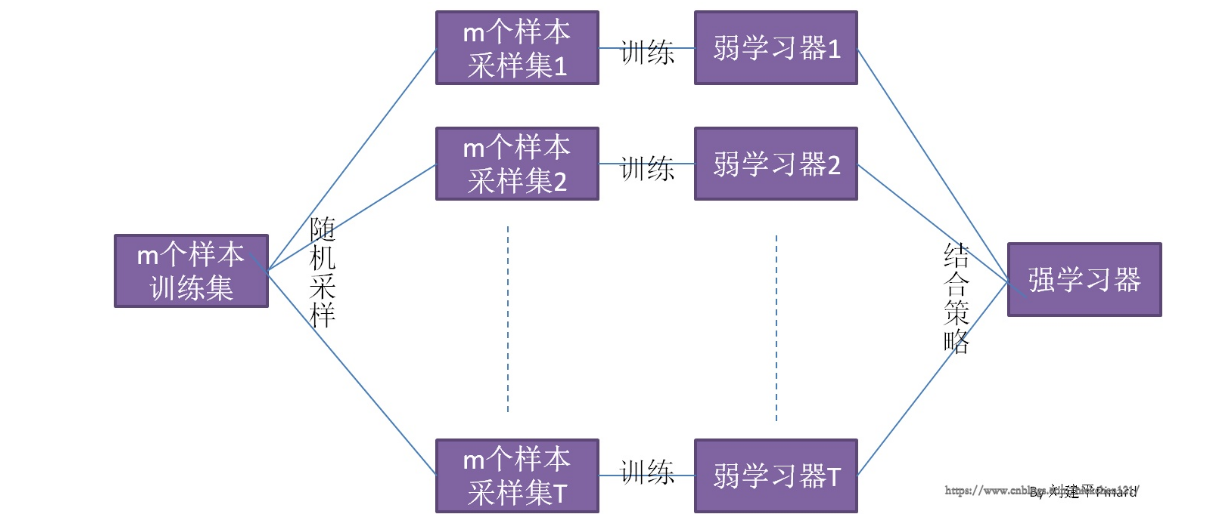
从上图可以看出,Bagging的弱学习器之间的确没有boosting那样的联系。它的特点在“随机采样”。那么什么是随机采样?随机采样(bootsrap)就是从我们的训练集里面采集固定个数的样本,但是每采集一个样本后,都将样本放回。也就是说,之前采集到的样本在放回后有可能继续被采集到。 对于我们的Bagging算法,一般会随机采集和训练集样本数m一样个数的样本。这样得到的采样集和训练集样本的个数相同,但是样本内容不同。如果我们对有m个样本训练集做T次的随机采样,则由于随机性,T个采样集各不相同。
注意到这和GBDT的子采样是不同的。GBDT的子采样是无放回采样,而Bagging的子采样是放回采样。对于一个样本,它在某一次含m个样本的训练集的随机采样中,每次被采集到的概率是$\frac{1}{m}$。不被采集到的概率为$1-(\frac{1}{m})$。如果m次采样都没有被采集中的概率是$(1-\frac{1}{m})^m$.当m趋近于无穷的时候,$(1-\frac{1}{m})^m$趋近于$\frac{1}{e}$。也就是说,在bagging的每轮随机采样中,训练集中大约有36.8%的数据没有被采样集采集中。对于这部分大约36.8%的没有被采样到的数据,我们常常称之为袋外数据(Out Of Bag, 简称OOB)。这些数据没有参与训练集模型的拟合因此可以用来检测模型的泛化能力。Bagging算法流程如下所示:

二、 RF介绍
理解了Bagging算法自然就好理解RF了。 RF是Bagging的一个改进,它的思想仍然是bagging,但是进行了独有的改进。首先,RF选择CART作为弱学习器(这点和GBRT类似),其次RF对决策树做了改进,对于普通的决策树,我们会在节点上所有的n个样本特征中选择一个最优的特征来做决策树的左右子树划分,但是RF通过随机选择节点上的一部分样本特征,这个数字小于n,记作$n_{sub}$。然后在这些随机选择的$n_{sub}$中选择一个最优的特征来做决策树的左右子树叶划分。这样进一步增强了模型的泛化能力。如果$n_{sub}$越小,则此时的RF的CART决策树和普通的CART决策树没有什么区别。$n_{sub}$越小,RF越鲁棒,对应的其拟合的程度会变差,对应的方差小,bias偏大。实际的使用过程中就需要用CV来选择一个合适的值。
(Bagging和RF主要的区别应该是RF使用的是CART,且RF对CART划分的规则上做了一些修改,不是对所有属性选择最优,而是随机选取一部分属性,然后从这部分属性中选最优)
Bagging 和RF的区别的更多相关文章
- Bagging和Boosting的区别(面试准备)
Baggging 和Boosting都是模型融合的方法,可以将弱分类器融合之后形成一个强分类器,而且融合之后的效果会比最好的弱分类器更好. Bagging: 先介绍Bagging方法: Bagging ...
- Bagging和Boosting的区别
转:http://www.cnblogs.com/liuwu265/p/4690486.html Bagging和Boosting都是将已有的分类或回归算法通过一定方式组合起来,形成一个性能更加强大的 ...
- GBDT和RF的区别
去XX公司实习的时候,被问过,傻逼的我当时貌似都答错了,原谅全靠自学的我,了解甚少 RF随着树的增加不会过拟合 GBDT随着树的增加会过拟合 RF还会对特征进行random,例如特征的个数m=sqrt ...
- Jackknife,Bootstraping, bagging, boosting, AdaBoosting, Rand forest 和 gradient boosting的区别
引自http://blog.csdn.net/xianlingmao/article/details/7712217 Jackknife,Bootstraping, bagging, boosting ...
- Bagging和Boosting 概念及区别
Bagging和Boosting都是将已有的分类或回归算法通过一定方式组合起来,形成一个性能更加强大的分类器,更准确的说这是一种分类算法的组装方法.即将弱分类器组装成强分类器的方法. 首先介绍Boot ...
- bagging 和boosting的概念和区别
1.先弄清楚模型融合中的投票的概念 分为软投票和硬投票,硬投票就是几个模型预测的哪一类最多,最终模型就预测那一类,在投票相同的情况下,投票结果会按照分类器的排序选择排在第一个的分类器结果.但硬投票有个 ...
- Bagging和Boosting 概念及区别(转)
Bagging和Boosting都是将已有的分类或回归算法通过一定方式组合起来,形成一个性能更加强大的分类器,更准确的说这是一种分类算法的组装方法.即将弱分类器组装成强分类器的方法. 首先介绍Boot ...
- Jackknife,Bootstrap, Bagging, Boosting, AdaBoost, RandomForest 和 Gradient Boosting的区别
Bootstraping: 名字来自成语“pull up by your own bootstraps”,意思是依靠你自己的资源,称为自助法,它是一种有放回的抽样方法,它是非参数统计中一种重要的估计统 ...
- 随机森林(Random Forest),决策树,bagging, boosting(Adaptive Boosting,GBDT)
http://www.cnblogs.com/maybe2030/p/4585705.html 阅读目录 1 什么是随机森林? 2 随机森林的特点 3 随机森林的相关基础知识 4 随机森林的生成 5 ...
随机推荐
- my97Date如何多选日期且无重复日期
最终的效果是: 首先引用my97Date的js WdatePicker.js html代码 <textarea cols="" name="txtNoUseDate ...
- 迁移生产环境的GItLab11.3.5到新的服务器
在新的服务器上 rpm安装git 首先停止,Gitlab服务 root@localhost # gitlab-ctl stop 参考了 以下链接: https://blog.csdn.net/liul ...
- Django 缓存配置的多种方式
django 的缓存配置有多种方式,主要包含以下几种: 1.开发调试模式 2.内存模式 3.使用文件 4.直接使用数据库 5.使用redis或者memcache 这里主要是记录一下那些不常用,但是在微 ...
- 【Linux】查看端口和进程
netstat -tunlp ps -ef|grep process_name
- Spring Data学习中心
Spring Data 概览 Spring Data的使命是为数据访问提供熟悉且一致的基于Spring的编程模型,同时仍保留底层数据存储的特殊特性. 它使数据访问技术,关系数据库和非关系数据库,map ...
- 浅谈BST(二叉查找树)
目录 BST的性质 BST的建立 BST的检索 BST的插入 BST求前驱/后继 BST的节点删除 复杂度 平衡树 BST的性质 树上每个节点上有个值,这个值叫关键码 每个节点的关键码大于其任意左侧子 ...
- 《Machine Learning - 李宏毅》视频笔记(完结)
https://www.youtube.com/watch?v=CXgbekl66jc&list=PLJV_el3uVTsPy9oCRY30oBPNLCo89yu49 https://www. ...
- nginx 日志之 access_log分割
如果任由访问日志写下去,日志文件会变得越来越大,甚至是写满磁盘. 所以,我们需要想办法把日志做切割,比如每天生成一个新的日志,旧的日志按规定时间删除即可. 实现日志切割可以通过写shell脚本或者系统 ...
- zabbix解决监控图形中文乱码
原文: https://blog.csdn.net/xujiamin0022016/article/details/86541783 zabbix 4解决监控图形中文乱码首先在windows里找到你想 ...
- C# 获得本地通用网卡信息
可以通过使用命名空间下的ManagementObjectSearcher类及其方法Get来获得通用网卡信息. 其中,最重要的是ManagementObjectSearcher构造函数的输入参数,可以传 ...