Oracle学习笔记(五)
如何查询硬解析问题:

--捕获出需要使用绑定变量的SQL drop table t_bind_sql purge; create table t_bind_sql as select sql_text,module from v$sqlarea;
alter table t_bind_sql add sql_text_wo_constants varchar2(1000);
create or replace function
remove_constants( p_query in varchar2 ) return varchar2
as
l_query long;
l_char varchar2(10);
l_in_quotes boolean default FALSE;
begin
for i in 1 .. length( p_query )
loop
l_char := substr(p_query,i,1);
if ( l_char = '''' and l_in_quotes )
then
l_in_quotes := FALSE;
elsif ( l_char = '''' and NOT l_in_quotes )
then
l_in_quotes := TRUE;
l_query := l_query || '''#';
end if;
if ( NOT l_in_quotes ) then
l_query := l_query || l_char;
end if;
end loop;
l_query := translate( l_query, '0123456789', '@@@@@@@@@@' );
for i in 0 .. 8 loop
l_query := replace( l_query, lpad('@',10-i,'@'), '@' );
l_query := replace( l_query, lpad(' ',10-i,' '), ' ' );
end loop;
return upper(l_query);
end;
/
update t_bind_sql set sql_text_wo_constants = remove_constants(sql_text);
commit; ---执行完上述动作后,以下SQL语句可以完成未绑定变量语句的统计
set linesize 266
col sql_text_wo_constants format a30
col module format a30
col CNT format 999999 select sql_text_wo_constants, module,count(*) CNT
from t_bind_sql
group by sql_text_wo_constants,module
having count(*) > 100
order by 3 desc; --注:可以考虑试验如下脚本
drop table t purge;
create table t(x int); select * from v$mystat where rownum=1;
begin
for i in 1 .. 100000
loop
execute immediate
'insert into t values ( '||i||')';
end loop;
commit;
end;
/ 附:贴出部分执行结果
------------------------------------------------------------------------------------------------------
SQL> ---执行完上述动作后,以下SQL语句可以完成未绑定变量语句的统计
SQL> set linesize 266
SQL> col sql_text_wo_constants format a30
SQL> col module format a30
SQL> col CNT format 999999
SQL> select sql_text_wo_constants, module,count(*) CNT
2 from t_bind_sql
3 group by sql_text_wo_constants,module
4 having count(*) > 100
5 order by 3 desc; SQL_TEXT_WO_CONSTANTS MODULE CNT
------------------------------ ------------------------------ -------
INSERT INTO T VALUES ( @) SQL*Plus 7366
绑定变量的不适合场景:
---1.构建T表,数据,及主键
VARIABLE id NUMBER
COLUMN sql_id NEW_VALUE sql_id
DROP TABLE t;
CREATE TABLE t
AS
SELECT rownum AS id, rpad('*',100,'*') AS pad
FROM dual
CONNECT BY level <= 1000;
ALTER TABLE t ADD CONSTRAINT t_pk PRIMARY KEY (id);
---2.收集统计信息
BEGIN
dbms_stats.gather_table_stats(
ownname => user,
tabname => 't',
estimate_percent => 100,
method_opt => 'for all columns size skewonly'
);
END;
/
---3.查询T表当前的分布情况
SELECT count(id), count(DISTINCT id), min(id), max(id) FROM t;
---4.发现当前情况下,可以区分出数据分布情况而正确使用执行计划
set linesize 1000
set autotrace traceonly explain
SELECT count(pad) FROM t WHERE id < 990;
SELECT count(pad) FROM t WHERE id < 10; ---5.现在将id的值该为变量实验一下绑定变量的SQL是否能使用直方图
--首先代入990,发现执行计划是走全表扫描,很正确
EXECUTE :id := 990;
SELECT count(pad) FROM t WHERE id < :id;
---6.接着代入10,发现仍然走全表扫描
EXECUTE :id := 10;
SELECT count(pad) FROM t WHERE id < :id; ---7.把共享池清空,很重要的一步,保证硬解析
ALTER SYSTEM FLUSH SHARED_POOL;
---8.代入10,发现可以使用直方图,执行计划为索引读,很正常
EXECUTE :id := 10;
SELECT count(pad) FROM t WHERE id < :id;
---9.代入990后,发现异常,仍然走索引读,这个时候由于返回大部分数据,应该全表扫描才对。
EXECUTE :id := 990;
SELECT count(pad) FROM t WHERE id < :id;
---明白了,这个就是传说中的绑定变量窥视! 附:贴出部分执行结果
------------------------------------------------------------------------------------------------------
SQL> SELECT count(pad) FROM t WHERE id < 990;
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 105 | 7 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 105 | | |
|* 2 | TABLE ACCESS FULL| T | 990 | 101K| 7 (0)| 00:00:01 |
---------------------------------------------------------------------------
SQL> SELECT count(pad) FROM t WHERE id < 10;
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 105 | 3 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 105 | | |
| 2 | TABLE ACCESS BY INDEX ROWID| T | 9 | 945 | 3 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | T_PK | 9 | | 2 (0)| 00:00:01 |
------------------------------------------------------------------------------------- SQL> EXECUTE :id := 990;
PL/SQL 过程已成功完成。
SQL> SELECT count(pad) FROM t WHERE id < :id;
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 105 | 3 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 105 | | |
| 2 | TABLE ACCESS BY INDEX ROWID| T | 50 | 5250 | 3 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | T_PK | 9 | | 2 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
SQL> EXECUTE :id := 10;
SQL> SELECT count(pad) FROM t WHERE id < :id;
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 105 | 3 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 105 | | |
| 2 | TABLE ACCESS BY INDEX ROWID| T | 50 | 5250 | 3 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | T_PK | 9 | | 2 (0)| 00:00:01 |
-------------------------------------------------------------------------------------

sql的逻辑读变零:
drop table t purge;
create table t as select * from dba_objects;
insert into t select * from t;
commit;
set autotrace on
set timing on
set linesize 1000
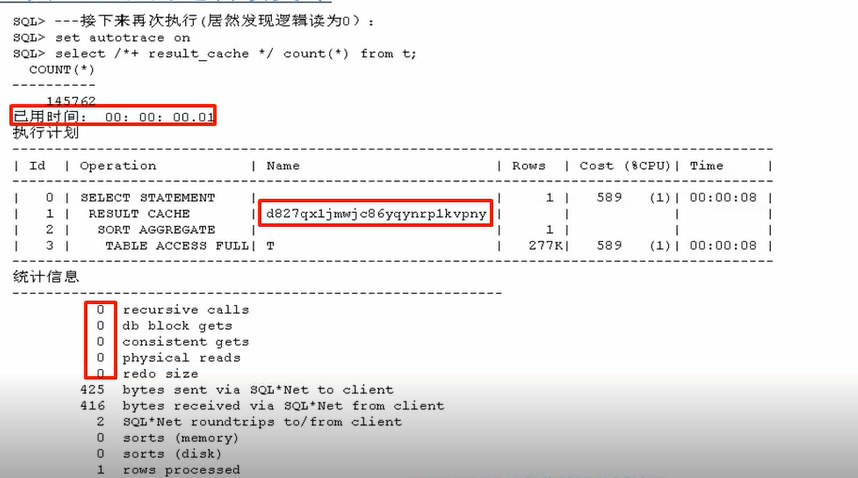
select /*+ result_cache */ count(*) from t; ---接下来再次执行(居然发现逻辑读为0):
set autotrace on
select /*+ result_cache */ count(*) from t; 附:贴出部分执行结果
------------------------------------------------------------------------------------------------------
SQL> ---接下来再次执行(居然发现逻辑读为0):
SQL> set autotrace on
SQL> select /*+ result_cache */ count(*) from t;
COUNT(*)
----------
145762
已用时间: 00: 00: 00.01
执行计划
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 589 (1)| 00:00:08 |
| 1 | RESULT CACHE | d827qx1jmwjc86yqynrp1kvpny | | | |
| 2 | SORT AGGREGATE | | 1 | | |
| 3 | TABLE ACCESS FULL| T | 277K| 589 (1)| 00:00:08 |
------------------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
0 consistent gets
0 physical reads
0 redo size
425 bytes sent via SQL*Net to client
416 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
函数的逻辑读变成零:
drop table t;
CREATE TABLE T AS SELECT * FROM DBA_OBJECTS; CREATE OR REPLACE FUNCTION F_NO_RESULT_CACHE RETURN NUMBER AS
V_RETURN NUMBER;
BEGIN
SELECT COUNT(*) INTO V_RETURN FROM T;
RETURN V_RETURN;
END;
/ set autotrace on statistics SELECT F_NO_RESULT_CACHE FROM DUAL;
--看调用F_NO_RESULT_CACHE执行第2次后的结果
SELECT F_NO_RESULT_CACHE FROM DUAL; CREATE OR REPLACE FUNCTION F_RESULT_CACHE RETURN NUMBER RESULT_CACHE AS
V_RETURN NUMBER;
BEGIN
SELECT COUNT(*) INTO V_RETURN FROM T;
RETURN V_RETURN;
END;
/ SELECT F_RESULT_CACHE FROM DUAL;
--看调用F_RESULT_CACHE执行第2次后的结果
SELECT F_RESULT_CACHE FROM DUAL; --以下细节是探讨关于如何保证在数据变化后,结果的正确性
SELECT COUNT(*) FROM T;
SELECT F_RESULT_CACHE(1) FROM DUAL;
DELETE T WHERE ROWNUM = 1;
SELECT COUNT(*) FROM T;
SELECT F_RESULT_CACHE(1) FROM DUAL;
COMMIT;
SELECT F_RESULT_CACHE(1) FROM DUAL; EXEC DBMS_RESULT_CACHE.FLUSH
CREATE OR REPLACE FUNCTION F_RESULT_CACHE(P_IN NUMBER)
RETURN NUMBER RESULT_CACHE RELIES_ON (T) AS
V_RETURN NUMBER;
BEGIN
SELECT COUNT(*) INTO V_RETURN FROM T;
RETURN V_RETURN;
END;
/ SELECT COUNT(*) FROM T;
SELECT F_RESULT_CACHE(1) FROM DUAL;
SELECT F_RESULT_CACHE(1) FROM DUAL;
DELETE T WHERE ROWNUM = 1;
SELECT COUNT(*) FROM T;
SELECT F_RESULT_CACHE(1) FROM DUAL; ---添加了RELIES_ON语句后,Oracle会根据依赖对象自动INVALIDATE结果集,从而保证RESULT CACHE的正确性。 附:贴出部分执行结果
------------------------------------------------------------------------------------------------------
SQL> --看调用F_NO_RESULT_CACHE执行第2次后的结果
SQL> SELECT F_NO_RESULT_CACHE FROM DUAL; F_NO_RESULT_CACHE
-----------------
72883
统计信息
---------------------------------------------------
1 recursive calls
0 db block gets
1043 consistent gets
0 physical reads
0 redo size
434 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed SQL> --看调用F_RESULT_CACHE执行第2次后的结果
SQL> SELECT F_RESULT_CACHE FROM DUAL; F_RESULT_CACHE
--------------
72883
统计信息
---------------------------------------------------
0 recursive calls
0 db block gets
0 consistent gets
0 physical reads
0 redo size
431 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed

keep让sql跑的更快:
--前提:必须保证db_keep_cache_size值不为0,所以首先有如下操作:
--设置100M这么大。
alter system set db_keep_cache_size=100M;
drop table t;
create table t as select * from dba_objects;
create index idx_object_id on t(object_id); --未执行KEEP命令,通过如下查询出BUFFER_POOL列值为DEFAULT,表示未KEEP。 select BUFFER_POOL from user_tables where TABLE_NAME='T';
select BUFFER_POOL from user_indexes where INDEX_NAME='IDX_OBJECT_ID'; alter index idx_object_id storage(buffer_pool keep);
--以下将索引全部读进内存
select /*+index(t,idx_object_id)*/ count(*) from t where object_id is not null;
--以下将数据全部读进内存
alter table t storage(buffer_pool keep);
select /*+full(t)*/ count(*) from t; --执行KEEP操作后,通过如下查询出BUFFER_POOL列值为KEEP,表示已经KEEP成功了 select BUFFER_POOL from user_tables where TABLE_NAME='T';
select BUFFER_POOL from user_indexes where INDEX_NAME='IDX_OBJECT_ID'; 附:贴出部分执行结果
------------------------------------------------------------------------------------------------------ --未执行KEEP命令,通过如下查询出BUFFER_POOL列值为DEFAULT,表示未KEEP。
select BUFFER_POOL from user_tables where TABLE_NAME='T';
BUFFER_POOL
-------------------
DEFAULT select BUFFER_POOL from user_indexes where INDEX_NAME='IDX_OBJECT_ID'; BUFFER_POOL
-------------------
DEFAULT --执行KEEP操作后,通过如下查询出BUFFER_POOL列值为KEEP,表示已经KEEP成功了
select BUFFER_POOL from user_tables where TABLE_NAME='T'; BUFFER_POOL
-------------------
KEEP select BUFFER_POOL from user_indexes where INDEX_NAME='IDX_OBJECT_ID'; BUFFER_POOL
-------------------
KEEP

查看系统各维度规律:
select s.snap_date,
decode(s.redosize, null, '--shutdown or end--', s.currtime) "TIME",
to_char(round(s.seconds/60,2)) "elapse(min)",
round(t.db_time / 1000000 / 60, 2) "DB time(min)",
s.redosize redo,
round(s.redosize / s.seconds, 2) "redo/s",
s.logicalreads logical,
round(s.logicalreads / s.seconds, 2) "logical/s",
physicalreads physical,
round(s.physicalreads / s.seconds, 2) "phy/s",
s.executes execs,
round(s.executes / s.seconds, 2) "execs/s",
s.parse,
round(s.parse / s.seconds, 2) "parse/s",
s.hardparse,
round(s.hardparse / s.seconds, 2) "hardparse/s",
s.transactions trans,
round(s.transactions / s.seconds, 2) "trans/s"
from (select curr_redo - last_redo redosize,
curr_logicalreads - last_logicalreads logicalreads,
curr_physicalreads - last_physicalreads physicalreads,
curr_executes - last_executes executes,
curr_parse - last_parse parse,
curr_hardparse - last_hardparse hardparse,
curr_transactions - last_transactions transactions,
round(((currtime + 0) - (lasttime + 0)) * 3600 * 24, 0) seconds,
to_char(currtime, 'yy/mm/dd') snap_date,
to_char(currtime, 'hh24:mi') currtime,
currsnap_id endsnap_id,
to_char(startup_time, 'yyyy-mm-dd hh24:mi:ss') startup_time
from (select a.redo last_redo,
a.logicalreads last_logicalreads,
a.physicalreads last_physicalreads,
a.executes last_executes,
a.parse last_parse,
a.hardparse last_hardparse,
a.transactions last_transactions,
lead(a.redo, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_redo,
lead(a.logicalreads, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_logicalreads,
lead(a.physicalreads, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_physicalreads,
lead(a.executes, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_executes,
lead(a.parse, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_parse,
lead(a.hardparse, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_hardparse,
lead(a.transactions, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_transactions,
b.end_interval_time lasttime,
lead(b.end_interval_time, 1, null) over(partition by b.startup_time order by b.end_interval_time) currtime,
lead(b.snap_id, 1, null) over(partition by b.startup_time order by b.end_interval_time) currsnap_id,
b.startup_time
from (select snap_id,
dbid,
instance_number,
sum(decode(stat_name, 'redo size', value, 0)) redo,
sum(decode(stat_name,
'session logical reads',
value,
0)) logicalreads,
sum(decode(stat_name,
'physical reads',
value,
0)) physicalreads,
sum(decode(stat_name, 'execute count', value, 0)) executes,
sum(decode(stat_name,
'parse count (total)',
value,
0)) parse,
sum(decode(stat_name,
'parse count (hard)',
value,
0)) hardparse,
sum(decode(stat_name,
'user rollbacks',
value,
'user commits',
value,
0)) transactions
from dba_hist_sysstat
where stat_name in
('redo size',
'session logical reads',
'physical reads',
'execute count',
'user rollbacks',
'user commits',
'parse count (hard)',
'parse count (total)')
group by snap_id, dbid, instance_number) a,
dba_hist_snapshot b
where a.snap_id = b.snap_id
and a.dbid = b.dbid
and a.instance_number = b.instance_number
order by end_interval_time)) s,
(select lead(a.value, 1, null) over(partition by b.startup_time order by b.end_interval_time) - a.value db_time,
lead(b.snap_id, 1, null) over(partition by b.startup_time order by b.end_interval_time) endsnap_id
from dba_hist_sys_time_model a, dba_hist_snapshot b
where a.snap_id = b.snap_id
and a.dbid = b.dbid
and a.instance_number = b.instance_number
and a.stat_name = 'DB time') t
where s.endsnap_id = t.endsnap_id
order by s.snap_date ,time desc;
找到提交过频繁的语句:
--检查是否有过分提交的语句(关键是得到sid就好办了,代入V$SESSION就可知道是什么进程,接下来还可以知道V$SQL)
set linesize 1000
column sid format 99999
column program format a20
column machine format a20
column logon_time format date
column wait_class format a10
column event format a32
column sql_id format 9999
column prev_sql_id format 9999
column WAIT_TIME format 9999
column SECONDS_IN_WAIT format 9999
--提交次数最多的SESSION select t1.sid, t1.value, t2.name
from v$sesstat t1, v$statname t2
where t2.name like '%user commits%'
and t1.STATISTIC# = t2.STATISTIC#
and value >= 10000
order by value desc; --取得SID既可以代入到V$SESSION 和V$SQL中去分析
--得出SQL_ID
select t.SID,
t.PROGRAM,
t.EVENT,
t.LOGON_TIME,
t.WAIT_TIME,
t.SECONDS_IN_WAIT,
t.SQL_ID,
t.PREV_SQL_ID
from v$session t
where sid in(194) ; --根据sql_id或prev_sql_id代入得到SQL
select t.sql_id,
t.sql_text,
t.EXECUTIONS,
t.FIRST_LOAD_TIME,
t.LAST_LOAD_TIME
from v$sqlarea t
where sql_id in ('ccpn5c32bmfmf'); --也请关注一下这个:
select * from v$active_session_history where session_id=194 --在别的session先执行如下试验脚本
drop table t purge;
create table t(x int); select * from v$mystat where rownum=1;
begin
for i in 1 .. 100000 loop
insert into t values (i);
commit;
end loop;
end;
/ 附:贴出部分执行结果
------------------------------------------------------------------------------------------------------
SQL> select t1.sid, t1.value, t2.name
2 from v$sesstat t1, v$statname t2
3 where t2.name like '%user commits%'
4 and t1.STATISTIC# = t2.STATISTIC#
5 and value >= 10000
6 order by value desc;
SID VALUE NAME
------ ---------- -------------------------
132 100003 user commits SQL> select t.SID,
2 t.PROGRAM,
3 t.EVENT,
4 t.LOGON_TIME,
5 t.WAIT_TIME,
6 t.SECONDS_IN_WAIT,
7 t.SQL_ID,
8 t.PREV_SQL_ID
9 from v$session t
10 where sid in(132); SID PROGRAM EVENT LOGON_TIME WAIT_TIME SECONDS_IN_WAIT SQL_ID PREV_SQL_ID
------ -------------------- ---------------------------------------------------------------------- --------------------------
132 sqlplus.exe SQL*Net message from client 13-11月-13 0 77 ccpn5c32bmfmf SQL> select t.sql_id,
2 t.sql_text,
3 t.EXECUTIONS,
4 t.FIRST_LOAD_TIME,
5 t.LAST_LOAD_TIME
6 from v$sqlarea t
7 where sql_id in ('ccpn5c32bmfmf');
SQL_ID SQL_TEXT EXECUTIONS FIRST_LOAD_TIME LAST_LOAD_TIME
------------------------------------------------------------------------------------------------------------------------------------
ccpn5c32bmfmfbegin for i in 1 .. 100000 loop 1 2013-11-13/16:13:56 13-11月-13
insert into t values (i);
commit;
end loop;
end;

日志归档相关案例:
--1、redo大量产生必然是由于大量产生"块改变"。从awr视图中找出"块改变"最多的segments
select * from (
SELECT to_char(begin_interval_time, 'YYYY_MM_DD HH24:MI') snap_time,
dhsso.object_name,
SUM(db_block_changes_delta)
FROM dba_hist_seg_stat dhss,
dba_hist_seg_stat_obj dhsso,
dba_hist_snapshot dhs
WHERE dhs.snap_id = dhss. snap_id
AND dhs.instance_number = dhss. instance_number
AND dhss.obj# = dhsso. obj#
AND dhss.dataobj# = dhsso.dataobj#
AND begin_interval_time> sysdate - 60/1440
GROUP BY to_char(begin_interval_time, 'YYYY_MM_DD HH24:MI'),
dhsso.object_name
order by 3 desc)
where rownum<=5; --2、从awr视图中找出步骤1中排序靠前的对象涉及到的SQL
SELECT to_char(begin_interval_time, 'YYYY_MM_DD HH24:MI'),
dbms_lob.substr(sql_text, 4000, 1),
dhss.instance_number,
dhss.sql_id,
executions_delta,
rows_processed_delta
FROM dba_hist_sqlstat dhss, dba_hist_snapshot dhs, dba_hist_sqltext dhst
WHERE UPPER(dhst.sql_text) LIKE '%这里写对象名大写%'
AND dhss.snap_id = dhs.snap_id
AND dhss.instance_Number = dhs.instance_number
AND dhss.sql_id = dhst.sql_id; --3、从ASH相关视图中找出执行这些SQL的session、module、machine
select * from dba_hist_active_sess_history WHERE sql_id = '';
select * from v$active_session_history where sql_Id = ''; --4. dba_source 看看是否有存储过程包含这个SQL --以下操作产生大量的redo,可以用上述的方法进行跟踪
drop table test_redo purge;
create table test_redo as select * from dba_objects;
insert into test_redo select * from test_redo;
insert into test_redo select * from test_redo;
insert into test_redo select * from test_redo;
insert into test_redo select * from test_redo;
insert into test_redo select * from test_redo;
exec dbms_workload_repository.create_snapshot();
Oracle学习笔记(五)的更多相关文章
- Oracle学习笔记五 SQL命令(三):Group by、排序、连接查询、子查询、分页
GROUP BY和HAVING子句 GROUP BY子句 用于将信息划分为更小的组每一组行返回针对该组的单个结果 --统计每个部门的人数: Select count(*) from emp group ...
- Oracle学习笔记(五)
七.查询 1.基本查询语句 select 列名字,列名字 from 表名字 例如 select user_a_id from userinfo; 2.在SQL*PLUS中设置格式 (1)设置新的字段名 ...
- Oracle学习笔记三 SQL命令
SQL简介 SQL 支持下列类别的命令: 1.数据定义语言(DDL) 2.数据操纵语言(DML) 3.事务控制语言(TCL) 4.数据控制语言(DCL)
- C#可扩展编程之MEF学习笔记(五):MEF高级进阶
好久没有写博客了,今天抽空继续写MEF系列的文章.有园友提出这种系列的文章要做个目录,看起来方便,所以就抽空做了一个,放到每篇文章的最后. 前面四篇讲了MEF的基础知识,学完了前四篇,MEF中比较常用 ...
- (转)Qt Model/View 学习笔记 (五)——View 类
Qt Model/View 学习笔记 (五) View 类 概念 在model/view架构中,view从model中获得数据项然后显示给用户.数据显示的方式不必与model提供的表示方式相同,可以与 ...
- java之jvm学习笔记五(实践写自己的类装载器)
java之jvm学习笔记五(实践写自己的类装载器) 课程源码:http://download.csdn.net/detail/yfqnihao/4866501 前面第三和第四节我们一直在强调一句话,类 ...
- Learning ROS for Robotics Programming Second Edition学习笔记(五) indigo computer vision
中文译著已经出版,详情请参考:http://blog.csdn.net/ZhangRelay/article/category/6506865 Learning ROS for Robotics Pr ...
- oracle学习笔记第一天
oracle学习笔记第一天 --oracle学习的第一天 --一.几个基础的关键字 1.select select (挑选) 挑选出显示的--列--(可以多列,用“,”隔开,*表示所有列),为一条 ...
- Typescript 学习笔记五:类
中文网:https://www.tslang.cn/ 官网:http://www.typescriptlang.org/ 目录: Typescript 学习笔记一:介绍.安装.编译 Typescrip ...
- ES6学习笔记<五> Module的操作——import、export、as
import export 这两个家伙对应的就是es6自己的 module功能. 我们之前写的Javascript一直都没有模块化的体系,无法将一个庞大的js工程拆分成一个个功能相对独立但相互依赖的小 ...
随机推荐
- 在ubuntu更新时,出现错误E: Some index files failed to download, they have been ignored, or old ones used inst
原文:https://blog.csdn.net/tian_ciomp/article/details/51339635 在ubuntu更新时,出现错误E: Some index files fail ...
- 更改用户host留下的坑
前言: 我们在创建数据库用户的时候都会指定host,即一个完整的用户可描述为 'username'@'host' .创建用户时不显式指定host则默认为%,%代表所有ip段都可以使用这个用户,我们也 ...
- JMETER 生成测试报告
JMETER测试报告样例 JMETER 提供的生成测试报告功能,能够生成漂亮的HTML测试报告. 上图是测试统计图 20个用户并发,测试时长一分钟,发起流程320次,没有出错,TPS为6.5,平均发起 ...
- Python从零开始——基础语法
- alpine基础镜像使用
关于Alpine的相关知识,可以参考下边的链接 https://yeasy.gitbooks.io/docker_practice/content/cases/os/alpine.html 一. al ...
- [TJOI2015]弦论(后缀自动机)
传送门 题意: 对给定字符串\(s\),求其第\(k\)小子串,重复串被计入以及不被计入这两种情况都需考虑. 思路: 首先构建后缀自动机,之后就考虑在后缀自动机上\(dp\). 我们知道如果要考虑重复 ...
- 网络编程 UDP协议 TCP局域网客户端与服务端上传下载电影示例
UDP协议 (了解) 称之为数据包协议,又称不可靠协议. 特点: 1) 不需要建立链接. 2) 不需要知道对方是否收到. 3) 数据不安全 4) 传输速度快 5)能支持并发 6) 不会粘包 7) 无需 ...
- POJ2536-Gopher II-(匈牙利算法)
题意:n只老鼠,m个洞,s秒逃命,逃命速度为v,一个洞只能保住一只老鼠,最少多少只老鼠会被老鹰抓到. 题解:找出每只老鼠有哪些洞可以保命,建立二分图,算出最大匹配,不是求保住命的老鼠,而是求被抓住的老 ...
- IConvertible接口
IConvertible接口:定义特定的方法,这些方法将实现引用或值类型的值转换为具有等效值的公共语言运行库类型. 公共语言运行库类型包括: Boolean.SByte.Byte.Int16.UInt ...
- 10 使用 OpenCV、Kafka 和 Spark 技术进行视频流分析
问题引起 基于分布式计算框架Spark的室内防盗预警系统 首先用摄像头录一段视频,存在电脑里,下载一个ffmpeg的软件对视频进行处理,处理成一张张图片,然后通过hadoop里边的一个文件系统叫做hd ...