spark 机器学习 随机森林 原理(一)
1.什么是随机森林
顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决 策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一 类被选择最多,就预测这个样本为那一类。
我们可以这样比喻随机森林算法:每一棵决策树就是一个精通于某一个窄领域的专家(因为我们 从M个特征中选择m个让每一棵决策树进行行学习),这样在随机森林中就有了了很多个精通不不同领 域的专家,对一个新的问题(新的输入数据),可以用不不同的角度去看待它,最终由各个专家, 投票得到结果
2.Bootstraping(随机且有放回地抽取)
Leo Breiman于1994年提出的Bagging(又称Bootstrap aggregation,引导聚集)是最基本的集成技术之一。Bagging基于统计学中的bootstraping(自助法),该方法使得评估许多复杂模型的统计数据更可行。
2.1bootstrap方法的流程如下:假设有尺寸为N的样本X。我们可以从该样本中有放回地随机均匀抽取N个样本,以创建一个新样本。换句话说,我们从尺寸为N的原样本中随机选择一个元素,并重复此过程N次。选中所有元素的可能性是一样的,因此每个元素被抽中的概率均为1/N。
2.2假设我们从一个袋子中抽球,每次抽一个。在每一步中,将选中的球放回袋子,这样下一次抽取是等概率的,即,从同样数量的N个球中抽取。注意,因为我们把球放回了,新样本中可能有重复的球。让我们把这个新样本称为X1。
重复这一过程M次,我们创建M个bootstrap样本X1,……,XM。最后,我们有了足够数量的样本,可以计算原始分布的多种统计数据。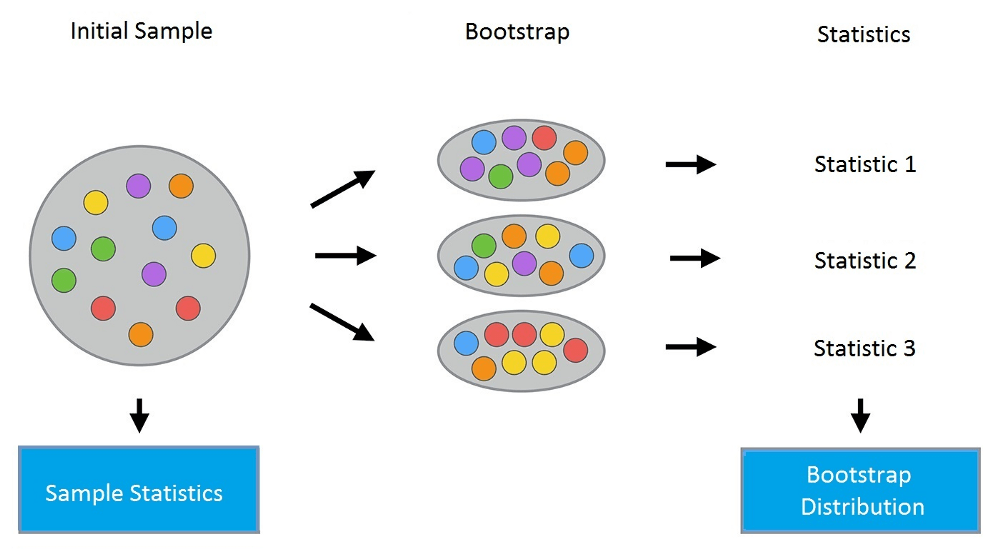
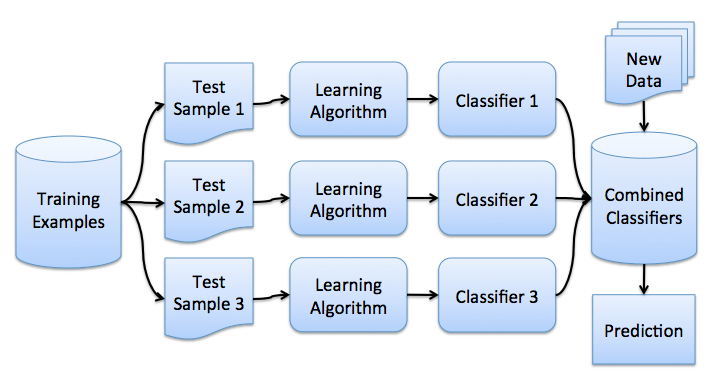
3. Bagging
理解了bootstrap概念之后,我们来介绍bagging。
假设我们有一个训练集X。我们使用bootstrap生成样本X1, …, XM。现在,我们在每个bootstrap样本上分别训练分类器ai(x)。最终分类器将对所有这些单独的分类器的输出取均值。在分类情形下,该技术对应投票(voting):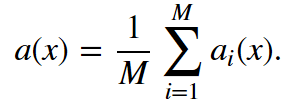
4.袋外误差(OOBE)
我们知道,在构建每棵树时,我们对训练集使用了不同的bootstrap sample(随机且有放回地抽取)。所以对于每棵树而言(假设对于第k棵树),大约有1/3的训练实例没有参与第k棵树的生成,它们称为第k棵树的oob样本。
而这样的采样特点就允许我们进行oob估计,它的计算方式如下:
1对每个样本,计算它作为oob样本的树对它的分类情况(约1/3的树);
2然后以简单多数投票作为该样本的分类结果;
3最后用误分个数占样本总数的比率作为随机森林的oob误分率。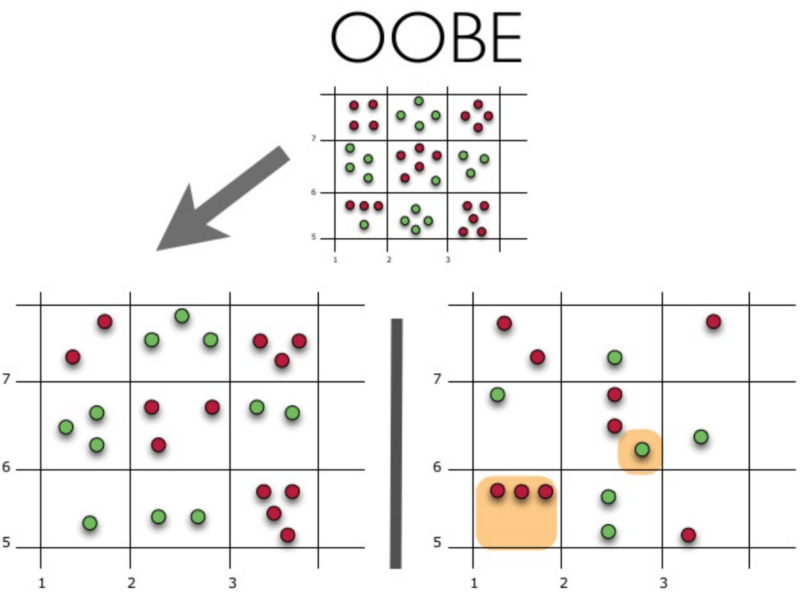
示意图上方为原始数据集。我们将其分为训练集(左)和测试集(右)。在测试集上,我们绘制一副网格,完美地实施了分类。现在,我们应用同一副网格于测试集,以估计分类的正确率。我们可以看到,分类器在4个未曾在训练中使用的数据点上给出了错误的答案。而测试集中共有15个数据点,这15个数据点未在训练中使用。因此,我们的分类器的精确度为11/15 * 100% = 73.33%.
总结一下,每个基础算法在约63%的原始样本上训练。该算法可以在剩下的约37%的样本上验证。袋外估计不过是基础算法在训练过程中留置出来的约37%的输入上的平均估计。
5.随机森林流程
5.1设样本数等于n,特征维度数等于d。
5.2选择集成中单个模型的数目M。
5.3对于每个模型m,选择特征数dm < d。所有模型使用相同的dm值。
5.4对每个模型m,通过在整个d特征集合上随机选择dm个特征创建一个训练集。
5.5训练每个模型。
5.6通过组合M中的所有模型的结果,应用所得集成模型于新输入。
spark 机器学习 随机森林 原理(一)的更多相关文章
- spark 机器学习 随机森林 实现(二)
通过天气,温度,风速3个特征,建立随机森林,判断特征的优先级结果 天气 温度 风速结果(0否,1是)天气(0晴天,1阴天,2下雨)温度(0热,1舒适,2冷)风速(0没风,1微风,2大风)1 1:0 2 ...
- 使用基于Apache Spark的随机森林方法预测贷款风险
使用基于Apache Spark的随机森林方法预测贷款风险 原文:Predicting Loan Credit Risk using Apache Spark Machine Learning R ...
- Spark mllib 随机森林算法的简单应用(附代码)
此前用自己实现的随机森林算法,应用在titanic生还者预测的数据集上.事实上,有很多开源的算法包供我们使用.无论是本地的机器学习算法包sklearn 还是分布式的spark mllib,都是非常不错 ...
- 机器学习——随机森林,RandomForestClassifier参数含义详解
1.随机森林模型 clf = RandomForestClassifier(n_estimators=200, criterion='entropy', max_depth=4) rf_clf = c ...
- 【Spark机器学习速成宝典】模型篇06随机森林【Random Forests】(Python版)
目录 随机森林原理 随机森林代码(Spark Python) 随机森林原理 参考:http://www.cnblogs.com/itmorn/p/8269334.html 返回目录 随机森林代码(Sp ...
- 【机器学习实战】第7章 集成方法(随机森林和 AdaBoost)
第7章 集成方法 ensemble method 集成方法: ensemble method(元算法: meta algorithm) 概述 概念:是对其他算法进行组合的一种形式. 通俗来说: 当做重 ...
- 什么是机器学习的分类算法?【K-近邻算法(KNN)、交叉验证、朴素贝叶斯算法、决策树、随机森林】
1.K-近邻算法(KNN) 1.1 定义 (KNN,K-NearestNeighbor) 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类 ...
- Spark随机森林实现学习
前言 最近阅读了spark mllib(版本:spark 1.3)中Random Forest的实现,发现在分布式的数据结构上实现迭代算法时,有些地方与单机环境不一样.单机上一些直观的操作(递归),在 ...
- 机器学习(六)—随机森林Random Forest
1.什么是随机采样? Bagging可以简单的理解为:放回抽样,多数表决(分类)或简单平均(回归): Bagging的弱学习器之间没有boosting那样的联系,不存在强依赖关系,基学习器之间属于并列 ...
随机推荐
- nodejs爬虫如何设置动态ip以及userAgent
nodejs爬虫如何设置动态ip以及userAgent 转https://blog.csdn.net/u014374031/article/details/78833765 前言 在写nodejs爬虫 ...
- vue---发送数据请求的一些列的问题
使用vue做数据请求,首先考虑的是封装请求方法request.js import axios from 'axios' import Qs from 'qs' // 创建一个axios实例 const ...
- elasticsearch jestclient api
1.es search sroll 可以遍历索引下所有数据 public class TestDemo { @Test public void searchSroll() { JestClientFa ...
- 纯CSS样式实现数字加减按钮的最佳方案
前言: 对于数字加减按钮的实现,以前用过不少方案,诸如: 1.使用背景图片——这种效果比较好,缺点是样式控制有点复杂了,还需要使用图片: 2.直接使用“+”“-”——这种方法简单粗暴,最容易实现,缺点 ...
- cesharp 完美支持flash
直接上代码: cefSettings.CefCommandLineArgs.Add("enable-npapi", "1"); //cefSettings.Ce ...
- Python - Django - 使用 Bootstrap 样式修改注册页
reg2 函数: from django.shortcuts import render, HttpResponse from app01 import models def reg2(request ...
- [LeetCode] 582. Kill Process 终止进程
Given n processes, each process has a unique PID (process id) and its PPID (parent process id). Each ...
- SpringBoot 跨域 Access-Control-Allow-Origin
跨域(CORS)是指不同域名之间相互访问. 跨域,指的是浏览器不能执行其他网站的脚本,它是由浏览器的同源策略所造成的,是浏览器对于JavaScript所定义的安全限制策略. 只要协议,子域名,主域名, ...
- SQL查询无限层级结构的所有下级,所有上级(即所有的子孙曾孙等等)
表名:tb_menu 内容如下: 查询ID为3的所有无限层下级会员 WITH TAS( SELECT * FROM tb_menu WHERE id=3 UNION ALL SELECT a.* F ...
- 使用Centos7.5+Nginx+Gunicorn+Django+Python3部署blog项目
项目开发环境是 Python3.5.2+Django1.10.6+Sqlite3+Centos7.5+Nginx1.12.2+Gunicorn 发布出来供需要的同学借鉴参考.文中如有错误请多多指正! ...