【idea】scala&sbt+idea安装配置与测试
一、IDEA安装
下载Community版的IDEA,Ultimate是免费试用版(相当于用到后面要给钱的)
ideaIC-2019.2.3.tar.gz
解压IDEA:
tar -zxvf ideaIC-2019.2.3.tar.gz
查看目录:
[hadoop@hadoop01 idea-IC-192.6817.14]$ ls -ll total 52 drwxrwxr-x. 2 hadoop hadoop 4096 Oct 2 22:08 bin -rw-r--r--. 1 hadoop hadoop 14 Sep 24 12:43 build.txt -rw-r--r--. 1 hadoop hadoop 1914 Sep 24 12:43 Install-Linux-tar.txt drwxrwxr-x. 7 hadoop hadoop 83 Oct 2 22:08 jbr drwxrwxr-x. 4 hadoop hadoop 8192 Oct 2 22:08 lib drwxrwxr-x. 2 hadoop hadoop 4096 Oct 2 22:08 license -rw-r--r--. 1 hadoop hadoop 11352 Sep 24 12:43 LICENSE.txt -rw-r--r--. 1 hadoop hadoop 128 Sep 24 12:43 NOTICE.txt drwxrwxr-x. 43 hadoop hadoop 4096 Oct 2 22:08 plugins -rw-r--r--. 1 hadoop hadoop 370 Sep 24 12:46 product-info.json drwxrwxr-x. 2 hadoop hadoop 35 Oct 2 22:08 redist
启动iedea:
[hadoop@hadoop01 bin]$ ./idea.sh OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release. Startup Error: Unable to detect graphics environment
报错:Unable to detect graphics environment
解决办法:不要在外面通过远程的方式执行此启动命令,要在linux图形界面中打开终端来执行此命令
在linux终端中执行命令启动idia:
[hadoop@hadoop01 ~]$ cd idea-IC-192.6817.14 [hadoop@hadoop01 idea-IC-192.6817.14]$ bin/idea.sh OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
下载安装scala插件
将 scala-intellij-bin-2019.2.3.zip 放在 scala主目录plugins文件夹里
注:scala插件一定要与idea版本对应,如我的就是:scala-intellij-bin-2019.2.3.zip对应ideaIC-2019.2.3.tar.gz
再在启动的idea中找到setting里面的plugins中选择install plugin from disk…

选中插件包

最后重启idea,即可。
二、IDEA
Normal
0
7.8 磅
0
2
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:普通表格;
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0cm 5.4pt 0cm 5.4pt;
mso-para-margin:0cm;
mso-para-margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:10.5pt;
mso-bidi-font-size:11.0pt;
font-family:等线;
mso-ascii-font-family:等线;
mso-ascii-theme-font:minor-latin;
mso-fareast-font-family:等线;
mso-fareast-theme-font:minor-fareast;
mso-hansi-font-family:等线;
mso-hansi-theme-font:minor-latin;
mso-font-kerning:1.0pt;}
使用
创建scala新工程
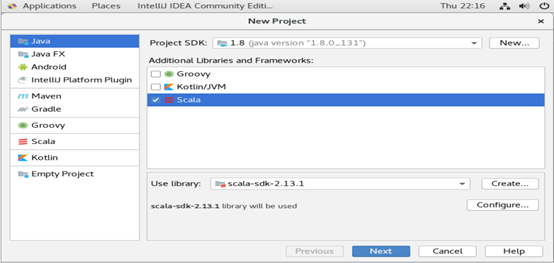
注:选择IDEA 便是创建普通的Scala
项目(注:IJ IDEA版本的不同,这里IDEA可能显示成Scala,不过这个并没有什么影响)
工程的基本页面设置:

其中:
project name :工程名称
project location :工程文件地址
jdk :使用的java version
版本,未找到时,自己选择jdk的安装目录
scala SDK :使用scala版本,未找到时,自己选择scala的安装目录
点击finish后,进入设计主页面
这个时候,第一次系统会对设置进行索引。
这里需要指出,IDEA对新工程的索引需要时间,长短视虚拟机的配置而定
在src处右键new—package,准备创建一个scala包
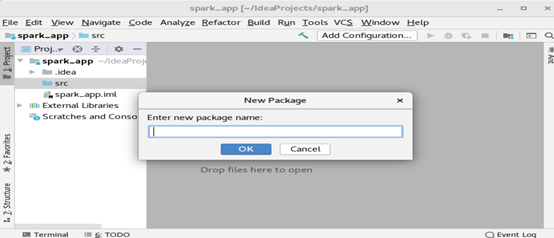
Package name :com.hadoop
配置工程结构(project structure),为了导入spark依赖包
依次选择主界面的file-- project structure,在弹出的对话框中选择librarie --+--java,选择虚拟机中已安装spark目录下的jars下所有的jar包
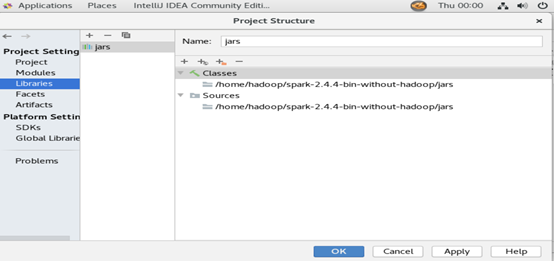
点击OK后,系统会再次进行索引
创建scala类
在com.hadoop包上右键new
– scala class,弹出如下界面
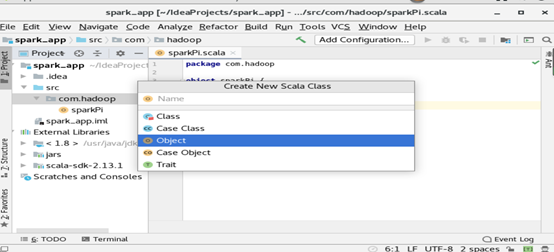
输入sparkPi,并选择object
运行之前,需要修改运行参数
在主界面选择run菜单中的edit configurations ,在弹出的对话框中左上角点击“+”,在弹出的列表中,选择application,填写运行参数:
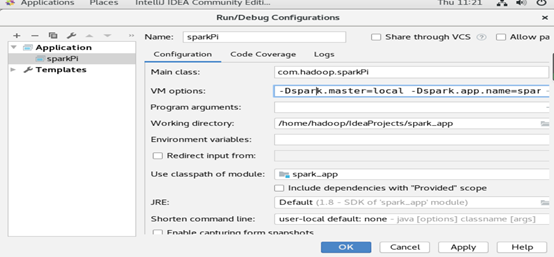
修改的参数有三个:
Name :sparkPi
Main class:com.hadoop.sparkPi
VM options :-Dspark.master=local
-Dspark.app.name=sparkPi
注:VM options 也可以不填写,但是要在代码中加入
.setMaster("local").setAppName("sparkPi")
填写完成后,直接点击OK
三、测试
1、测试程序:
package com.hadoop import scala.math.random
import org.apache.spark._ object sparkPi { def main(args: Array[String]) { println("Hello, World!")
}
}
Run程序后,结果如下:
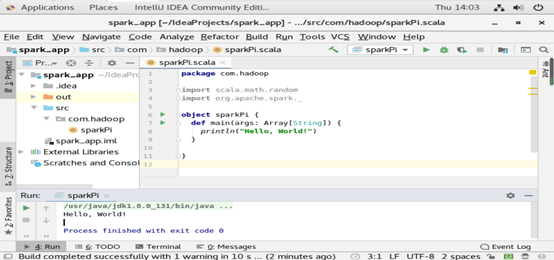
2、编写工程:
package com.hadoop import scala.math.random
import org.apache.spark._ object sparkPi {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("sparkPi")
val spark = new SparkContext(conf)
val slices = if (args.length > 0) args(0).toInt else 2
val n = 10000 * slices
val count = spark.parallelize(1 to n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x * x + y * y <) 1 else 0
}.reduce(_ + _)
println("Pi is roughly " + 4.0 * count / n)
spark.stop()
}
}
第一次运行结果:
报错:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/fs/FSDataInputStream
at org.apache.spark.SparkConf.loadFromSystemProperties(SparkConf.scala:76)
at org.apache.spark.SparkConf.<init>(SparkConf.scala:71)
at org.apache.spark.SparkConf.<init>(SparkConf.scala:58)
at com.hadoop.sparkPi$.main(sparkPi.scala:9)
at com.hadoop.sparkPi.main(sparkPi.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.fs.FSDataInputStream
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:335)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 5 more
原因:缺少对应的依赖包
解决办法:下载spark-2.4.4-bin-hadoop2.6,将里面jars包拷贝进去,或者直接重新配置spark-2.4.4-bin-hadoop2.6
第二次运行结果:
报错:
Exception in thread "main" java.lang.IllegalArgumentException: System memory 425197568 must be at least 471859200.
Please increase heap size using the --driver-memory option or spark.driver.memory in Spark configuration.
原因:Spark是非常依赖内存的计算框架,在虚拟环境下使用local模式时,实际上是使用多线程的形式模拟集群进行计算,因而对于计算机的内存有一定要求,这是典型的因为计算机内存不足而抛出的异常。
解决办法:
在下面这出代码后面添加:“.set("spark.testing.memory","2147480000")”,其实上面的错误提醒了的,如“Please increase heap size using the --driver-memory option or spark.driver.memory in Spark configuration.”
val conf = new SparkConf().setMaster("local").setAppName("sparkPi") //添加后
第三次运行(成功):
结果:Pi is roughly 3.1304

附_完整测试代码:
package com.hadoop import scala.math.random
import org.apache.spark._ object sparkPi {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("sparkPi").set("spark.testing.memory","2147480000") Normal
0 7.8 磅
0
2 false
false
false EN-US
ZH-CN
X-NONE /* Style Definitions */
table.MsoNormalTable
{mso-style-name:普通表格;
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0cm 5.4pt 0cm 5.4pt;
mso-para-margin:0cm;
mso-para-margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:10.5pt;
mso-bidi-font-size:11.0pt;
font-family:等线;
mso-ascii-font-family:等线;
mso-ascii-theme-font:minor-latin;
mso-fareast-font-family:等线;
mso-fareast-theme-font:minor-fareast;
mso-hansi-font-family:等线;
mso-hansi-theme-font:minor-latin;
mso-font-kerning:1.0pt;} val spark = new SparkContext(conf)
val slices = if (args.length > 0) args(0).toInt else 2
val n = 10000 * slices
val count = spark.parallelize(1 to n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x * x + y * y <) 1 else 0
}.reduce(_ + _)
println("Pi is roughly " + 4.0 * count / n)
spark.stop()
}
}
v\:* {behavior:url(#default#VML);}
o\:* {behavior:url(#default#VML);}
w\:* {behavior:url(#default#VML);}
.shape {behavior:url(#default#VML);}
Normal
0
false
7.8 磅
0
2
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:普通表格;
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0cm 5.4pt 0cm 5.4pt;
mso-para-margin:0cm;
mso-para-margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:10.5pt;
mso-bidi-font-size:11.0pt;
font-family:等线;
mso-ascii-font-family:等线;
mso-ascii-theme-font:minor-latin;
mso-fareast-font-family:等线;
mso-fareast-theme-font:minor-fareast;
mso-hansi-font-family:等线;
mso-hansi-theme-font:minor-latin;
mso-font-kerning:1.0pt;}
【idea】scala&sbt+idea安装配置与测试的更多相关文章
- Spark之路 --- Windows Scala 开发环境安装配置
JDK安装 JDK安装包下载 到Oracle官网下载JDK. 传送门 下载之前要记得勾选上同意协议然后选择相应的版本(Windows/Linux, 32/64) JDK安装及验证 按提示完成安装,安装 ...
- Scala系统学习(二):Scala开发环境安装配置
Scala可以安装在任何基于UNIX/Linux或基于Windows的系统上.在您的机器上开始安装Scala之前,必须在计算机上安装Java 1.8或更高版本. 下面请按照以下步骤安装Scala. 步 ...
- 四步完成NodeJS安装,配置和测试
四步完成NodeJS安装,配置和测试 NodeJS 官网地址: http://nodejs.org/ 第一步:在官网点击 ’ INSTALL ’,下载相应的版本(我的机器是Win7专业版 64bit) ...
- django安装配置及测试
django安装之前我们假设你已经安装了python,和mysql(不是必须的):(如果没有google一下挺简单不介绍了)下面直接介绍django的安装配置:到下面连接可以下载www.djangop ...
- NodeJS、NPM安装配置与测试步骤(windows版本)
1.windows下的NodeJS安装是比较方便的(v0.6.0版本之后,支持windows native),只需要登陆官网(http://nodejs.org/),便可以看到首页的"INS ...
- sbt 以及 IDEA sbt 插件安装配置教程(转)
1. 在Windows中安装sbt 下载 官网: http://www.scala-sbt.org/ github: https://github.com/sbt/sbt/releases/downl ...
- Elasticsearch安装配置和测试
官方教程:https://www.elastic.co/guide/en/elasticsearch/reference/master/_installation.html 中文教程:https:// ...
- MySQL安装配置及测试
1. 安装包下载 点击下载地址:https://dev.mysql.com/downloads/installer/打开页面,滑到较底端,按如下选择下载: 会弹出一个注册登录页面,可以不用管,直接点击 ...
- redhat enterprixe 5.0 下DHCP服务器rpm安装配置及其测试
一.了解DHCP DHCP服务提供动态指定IP地址和配置参数的机制.有动态和静态两种方式. 二.rpm安装 因为配过Samba,所以感觉挺简单. 首先找到主程序和几个附属程序的rpm的安装包.应该都是 ...
随机推荐
- 【转】Python访问oracle数据库,DPI-1047: Cannot locate a 64-bit Oracle Client library: "The specified module could not be found"
使用python连接Oracle,出现如下错误: DPI-1047: Cannot locate a 64-bit Oracle Client library: "The specified ...
- java算法 -- 基数排序
基数排序(英语:Radix sort)是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较.由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排 ...
- BIM数据格式中IFC的标准及格式
传统工程数据往往零散且片段的储存在各个不同的地方,数据格式也有各种不同的形式互相搭配,最常见的有图形(施工图.大样图.断面图.流程图等).文字(各种说明文件).数字(各种统计.数量或价格数据),这些数 ...
- linux : 各个发行版中修改python27默认编码为utf-8
该方法可解决robot报错:'ascii' codec can't encode character u'\xf1' in position 16: ordinal not in range(128 ...
- 【视频开发】RTSP SERVER(基于live555)详细设计
/* *本文基于LIVE555的嵌入式的RTSP流媒体服务器一个设计文档,个中细节现剖于此,有需者可参考指正,同时也方便后期自己查阅.(本版本是基于2011年的live555) 作者:llf_17@q ...
- PHP设计模式 - 享元模式
运用共享技术有效的支持大量细粒度的对象 享元模式变化的是对象的存储开销 享元模式中主要角色: 抽象享元(Flyweight)角色:此角色是所有的具体享元类的超类,为这些类规定出需要实现的公共接口.那些 ...
- LeetCode 503. 下一个更大元素 II(Next Greater Element II)
503. 下一个更大元素 II 503. Next Greater Element II 题目描述 给定一个循环数组(最后一个元素的下一个元素是数组的第一个元素),输出每个元素的下一个更大元素.数字 ...
- This view is not constrained, it only has designtime positions, so it will jump to (0,0) unless you
Android Studio报错 这个视图只是编辑时位置,在运行时视图会跳转到(0,0) 解决办法: 在Design界面下,有个魔棒工具,Infer Constrains,点击之后就可以了
- JAVAWEB实现增删查改(图书信息管理)之修改功能实现
首先通过点击index.jsp页面的修改按钮,获取该行的id:↓ 其次,跳转到updateBooks.jsp页面进行修改信息,页面代码如下:↓ <%@ page import="Boo ...
- Java基础笔试练习(十一)
1.下面的方法,当输入为2的时候返回值是多少? public static int getValue(int i) { int result = 0; switch (i) { case 1: res ...