Python进阶:程序界的垃圾分类回收
垃圾回收是 Python 自带的机制,用于自动释放不会再用到的内存空间;
什么是内存泄漏呢?
- 内存泄漏,并不是说你的内存出现了信息安全问题,被恶意程序利用了,而是指程序本身没有设计好,导致程序未能释放已不再使用的内存。
- 内存泄漏也不是指你的内存在物理上消失了,而是意味着代码在分配了某段内存后,因为设计错误,失去了对这段内存的控制,从而造成了内存的浪费。
计数引用
Python 中一切皆对象。当这个对象的引用计数(指针数)为 0 的时候,说明这个对象永不可达,自然它也就成为了垃圾,需要被回收。
例:
# 显示当前 python 程序占用的内存大小
def show_memory_info(hint):
pid = os.getpid()
p = psutil.Process(pid) info = p.memory_full_info()
memory = info.uss / 1024. / 1024
print('{} memory used: {} MB'.format(hint, memory))
def func():
show_memory_info('initial')
a = [i for i in range(10000000)]
show_memory_info('after a created') func()
show_memory_info('finished') ########## 输出 ##########
程序初始化时占的内存为6MB,接着创建了一个列表a,由于a还没被回收,因此占的内存升到了200MB,当函数返回后,a的引用计数为0,a被回收,内存又恢复到了7MB。
如果把a变成全局变量,函数返回后,引用计数依然大于0,于是对象就不会被垃圾回收,依然占着大量的内存
def func():
show_memory_info('initial')
global a
a = [i for i in range(10000000)]
show_memory_info('after a created') func()
show_memory_info('finished') ########## 输出 ########## # initial memory used: 6.67578125 MB
# after a created memory used: 199.30859375 MB
# finished memory used: 199.30859375 MB
或者把列表返回,在主程序中接收,引用依然存在,垃圾回收就不会被触发,大量内存仍然被占用着
def func():
show_memory_info('initial')
a = [i for i in range(10000000)]
show_memory_info('after a created')
return a a = func()
show_memory_info('finished') ########## 输出 ########## # initial memory used: 6.6484375 MB
# after a created memory used: 199.2890625 MB
# finished memory used: 199.2890625 MB
看一下 Python 内部的引用计数机制
import sys a = [] # 两次引用,一次来自 a,一次来自 getrefcount
print(sys.getrefcount(a)) def func(a):
# 四次引用,a,python 的函数调用栈,函数参数,和 getrefcount
print(sys.getrefcount(a)) func(a) # 两次引用,一次来自 a,一次来自 getrefcount,函数 func 调用已经不存在
print(sys.getrefcount(a)) ########## 输出 ########## 2
4
2
sys.getrefcount() 这个函数,可以查看一个变量的引用次数。这段代码本身应该很好理解,不过别忘了,getrefcount 本身也会引入一次计数。另一个要注意的是,在函数调用发生的时候,会产生额外的两次引用,一次来自函数栈,另一个是函数参数。
又如:
import sys a = [] print(sys.getrefcount(a)) # 两次 b = a print(sys.getrefcount(a)) # 三次 c = b
d = b
e = c
f = e
g = d print(sys.getrefcount(a)) # 八次 ########## 输出 ########## 2
3
8
a、b、c、d、e、f、g 这些变量全部指代的是同一个对象,而 sys.getrefcount() 函数并不是统计一个指针,而是要统计一个对象被引用的次数,所以最后一共会有八次引用。
手动释放内存,应该怎么做呢? 方法同样很简单。只需要先调用 del a 来删除一个对象;然后强制调用 gc.collect(),即可手动启动垃圾回收。
import gc
import os
import psutil
# 显示当前 python 程序占用的内存大小
def show_memory_info(hint):
pid = os.getpid()
p = psutil.Process(pid) info = p.memory_full_info()
memory = info.uss / 1024. / 1024
print('{} memory used: {} MB'.format(hint, memory)) show_memory_info('initial') a = [i for i in range(10000000)] show_memory_info('after a created') del a
gc.collect() show_memory_info('finish')
print(a) initial memory used: 6.54296875 MB
after a created memory used: 199.17578125 MB
finish memory used: 7.26171875 MB
Traceback (most recent call last):
File "Coroutine.py", line 24, in <module>
print(a)
NameError: name 'a' is not defined
循环引用
观察代码:
def func():
show_memory_info('initial')
a = [i for i in range(10000000)]
b = [i for i in range(10000000)]
show_memory_info('after a, b created')
a.append(b)
b.append(a) func()
show_memory_info('finished') ########## 输出 ##########
initial memory used: 6.625 MB
after a, b created memory used: 392.08984375 MB
finished memory used: 392.08984375 MB
这里,a 和 b 互相引用,并且,作为局部变量,在函数 func 调用结束后,a 和 b 这两个指针从程序意义上已经不存在了。但是,很明显,依然有内存占用!为什么呢?因为互相引用,导致它们的引用数都不为 0。
处理这种情况,可以调用显式调用 gc.collect() ,来启动垃圾回收。
Python 使用标记清除(mark-sweep)算法和分代收集(generational),来启用针对循环引用的自动垃圾回收。
调试内存泄漏
objgraph,一个非常好用的可视化引用关系的包.
安装:
pip install graphviz
pip install xdot
pip install objgraph
windows的话要除了装以上库还要在官网https://graphviz.gitlab.io/_pages/Download/Download_windows.html下载,然后设置环境变量 Path增加C:\Program Files (x86)\Graphviz2.38\bin,在CMD输入dot -version验证。
通过下面这段代码和生成的引用调用图,你能非常直观地发现,有两个 list 互相引用,说明这里极有可能引起内存泄露。
import objgraph a = [1, 2, 3]
b = [4, 5, 6] a.append(b)
b.append(a) objgraph.show_refs([a])
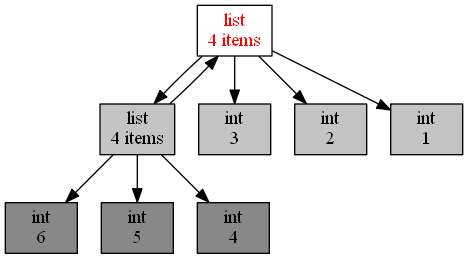
注:在windows中可能会提示:
Graph written to C:\Users\Public\Documents\Wondershare\CreatorTemp\objgraph-wwcqiie_.dot (8 nodes)
Image renderer (dot) not found, not doing anything else
这时只要在打开dot文件所在的路径,然后CMD中执行
dot .\objgraph-yclwfpzr.dot -Tpng -o image.png
就可以生成文件。
另一个非常有用的函数,是 show_backrefs()。以下是调用show_backrefs()生成的图片。
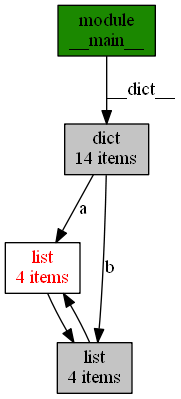
参考
极客时间《Python核心技术与实战》专栏
Python进阶:程序界的垃圾分类回收的更多相关文章
- 【python进阶】Garbage collection垃圾回收2
前言 在上一篇文章[python进阶]Garbage collection垃圾回收1,我们讲述了Garbage collection(GC垃圾回收),画说Ruby与Python垃圾回收,Python中 ...
- 【python进阶】Garbage collection垃圾回收1
前言 GC垃圾回收在python中是很重要的一部分,同样我将分两次去讲解Garbage collection垃圾回收,此篇为Garbage collection垃圾回收第一篇,下面开始今天的说明~~~ ...
- python进阶(7)垃圾回收机制
Python垃圾回收 基于C语言源码底层,让你真正了解垃圾回收机制的实现 引用计数器 标记清除 分代回收 缓存机制 Python的C源码(3.8.2版本) 1.引用计数器 1.1环状双向链表 refc ...
- Python进阶 - 对象,名字以及绑定
Python进阶 - 对象,名字以及绑定 1.一切皆对象 Python哲学: Python中一切皆对象 1.1 数据模型-对象,值以及类型 对象是Python对数据的抽象.Python程序中所有的数据 ...
- python进阶篇
python进阶篇 import 导入模块 sys.path:获取指定模块搜索路径的字符串集合,可以将写好的模块放在得到的某个路径下,就可以在程序中import时正确找到. import sys ...
- Python进阶(三十五)-Fiddler命令行和HTTP断点调试
Python进阶(三十五)-Fiddler命令行和HTTP断点调试 一. Fiddler内置命令 上一节(使用Fiddler进行抓包分析)中,介绍到,在web session(与我们通常所说的se ...
- python进阶02 特殊方法与特殊属性
python进阶02 特殊方法与特殊属性 一.初始化.析构 1.初始化 # python中有很多双下划线开头且以下划线结尾的固定方法,它们会在特定的时机被触发执行,这便是特殊方法 # 在实例化的时候就 ...
- Python进阶----线程基础,开启线程的方式(类和函数),线程VS进程,线程的方法,守护线程,详解互斥锁,递归锁,信号量
Python进阶----线程基础,开启线程的方式(类和函数),线程VS进程,线程的方法,守护线程,详解互斥锁,递归锁,信号量 一丶线程的理论知识 什么是线程: 1.线程是一堆指令,是操作系统调度 ...
- Python进阶----进程间数据隔离, join阻塞等待, 进程属性, 僵尸进程和孤儿进程, 守护进程
Python进阶----进程间数据隔离, join阻塞等待, 进程属性, 僵尸进程和孤儿进程, 守护进程 一丶获取进程以及父进程的pid 含义: 进程在内存中开启多个,操作系统如何区分这些进程, ...
随机推荐
- OI歌曲汇总
在学习的间隙,我们广大的OIer创作了许多广为人知的歌曲 这里来个总结 (持续更新ing......) Lemon OI 葛平 Lemon OI chen_zhe Lemon OI kkksc03 膜 ...
- linux patch 简单学习
使用patch 我们可以方便的进行软件补丁包处理,以下演示一个简单的c 项目补丁处理 原代码 app.c #include <stdio.h> int main(){ printf(&qu ...
- 异步编程(回调函数,promise)
一.回调函数 ①概念:一般情况下,程序会时常通过API调用库里所预先备好的函数.但是有些库函数却要求应用先传给它一个函数,好在合适的时候调用,以完成目标任务.这个被传入的.后又被调用的函数就称为回调函 ...
- 《RabbitMQ 实战》读书笔记
MQ的好处: 1.业务上接口(系统扩展性变强) 2.性能提升(同步变异步,效率提高,还方便做负载均衡) 3.技术兼容(可以连接各种不同语言的系统,作为粘合剂) 读书笔记: 1.消息队列的应用场景:系统 ...
- SQL基础-建表
一.建表 1.创建表的两种方式 *客户端工具 *SQL语句 2.使用SQL语句创建表 表名和字段名不能使用中文:(一般为字母开头,字母.数字.下划线组成的字符串): CREATE TABLE关键字后跟 ...
- LG4074【WC2013】糖果公园 【树上莫队,带修莫队】
题目描述:给出一棵 \(n\) 个点的树,点有颜色 \(C_i\),长度为 \(m\) 的数组 \(V\) 和长度为 \(n\) 的数组 \(W\).有两种操作: 将 \(C_x\) 修改为 \(y\ ...
- A. Vova and Train ( Codeforces Round #515 (Div. 3) )
题意:一条 L 长的路,一列车长在这条路的 l 到 r 之间,只有在 v 倍数时有灯,但是在 l 到 r 之间的灯是看不见的,问最大看见的灯的个数? 题解:L / v 表示总共的灯的个数, r / v ...
- nginx 平滑重启的实现方法
一.背景 在服务器开发过程中,难免需要重启服务加载新的代码或配置,如果能够保证server重启的过程中服务不间断,那重启对于业务的影响可以降为0.最近调研了一下nginx平滑重启,觉得很有意思,记录下 ...
- Eclipse R语言开发环境搭建 StatET插件
StatET 官网 http://www.walware.de/goto/statet Installation 点击菜单栏 help --> Install New Software 配置R语 ...
- Kafka(四) —— KafkaProducer源码阅读
一.doSend()方法 Kafka中的每一条消息都对应一个ProducerRecord对象. public class ProducerRecord<K, V> { private fi ...