原生xgboost中如何输出feature_importance
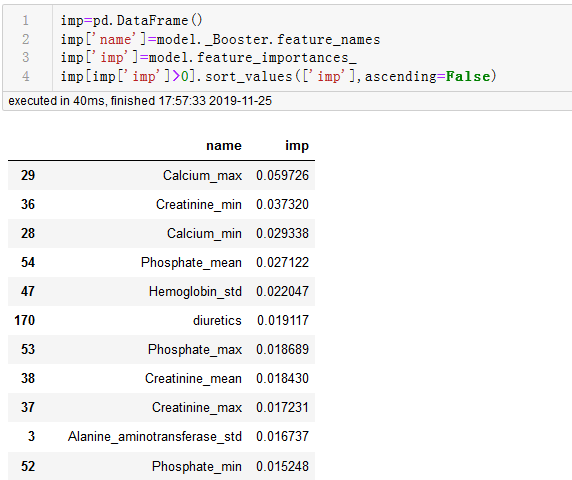
网上教程基本都是清一色的使用sklearn版本,此时的XGBClassifier有自带属性feature_importances_,而特征名称可以通过model._Booster.feature_names获取,但是对应原生版本,也就是通过DMatrix构造,通过model.train训练的模型,如何获取feature_importance?而且,二者获取的feature_importance又有何不同?
1.通过阅读官方文档https://xgboost.readthedocs.io/en/latest/python/python_api.html,发现sklearn版本初始化时会指定一个默认参数

显而易见,最后获取的feature_importances_就是gain得到的

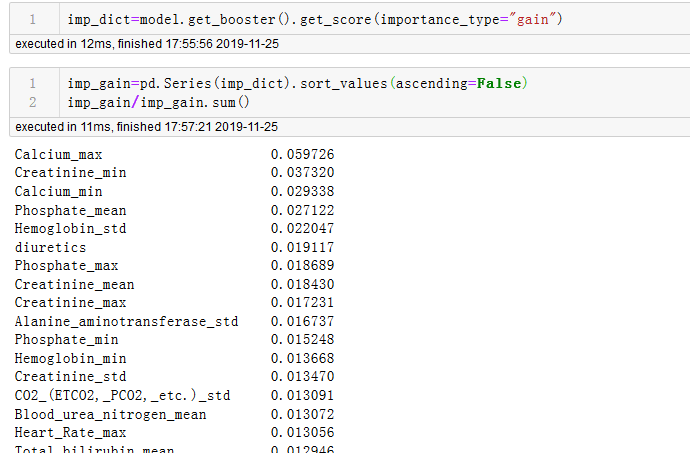
2.而原生版本初始化时没有importance_type参数,真正获取feature_importance时通过model.get_score(importance_type="gain")获取,(另外一个方法get_fscore()就是get_score(importance_type="weight"),二者实现一样。)
注意这里默认参数是"weight",就是指每个特征被用于分割的使用次数。如果对标skelearn版本需要指定“gain”,这里gain是指平均增益,另外,skelearn版本返回的importance是0-1形式,而原生版本返回的是很大的小数形式,对标的话可以通过除以总和得到,结果如图
3.至于什么时候用weight,什么时候用gain,其实各有说法。实际上,判断特征重要性共有三个维度,而在实际中,三个选项中的每个选项的功能重要性排序都非常不同
1. 权重。在所有树中一个特征被用来分裂数据的次数。
2. 覆盖。在所有树中一个特征被用来分裂数据的次数,并且有多少数据点通过这个分裂点。
3. 增益。使用特征分裂时平均训练损失的减少量
是什么使得衡量特征重要性的度量好或者坏?
如何比较一种特征归因方法与另一种特征归因方法并不容易。我们可以度量每种方法的最终用户性能,例如数据清理、偏差检测等。但这些只是对特征归因方法好坏的间接测量。在这里,我们将定义两个属性,我们认为任何好的特征归因方法应该遵循:
1. 一致性。每当我们更改模型以使其更依赖于某个特征时,该特征的归因重要性不应该降低。
2. 准确性。所有特征重要性的总和应该等于模型的总重要性。(例如,如果重要性由R²值测量,那么每个特征的属性应该与完整模型的R²相等)
如果一致性不成立,那么我们不能比较任意两个模型之间的归因重要性,因为具有较高分配归因特征,并不意味着模型实际上更多地依赖于该特征。
如果精度未能保持,那么我们不知道每个特征的属性如何组合以表示整个模型的输出。我们不能在方法完成后对归因进行规范化,因为这可能会破坏方法的一致性
这里推荐使用shap,可以全面的判断特征重要性,而且对xgboost和lightgbm都有集成,可视化也相当不错。详细可看https://github.com/slundberg/shap
附:lightgbm和xgboost类似,https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.Booster.html?highlight=importance#lightgbm.Booster.feature_importance

原生xgboost中如何输出feature_importance的更多相关文章
- 原生js中slice()方法和splice()区别
slice()方法和splice()方法都是原生js中对数组操作的方法. slice(),返回一个新的数组,该方法可从已有的数组中返回选定的元素.例如:arrObject(start,end),sta ...
- 【温故知新】——原生js中常用的四种循环方式
一.引言 本文主要是利用一个例子,讲一下原生js中常用的四种循环方式的使用与区别: 实现效果: 在网页中弹出框输入0 网页输出“欢迎下次光临” 在网页中弹出框输入1 网页输出“查询中……” 在 ...
- 关于原生js中函数的三种角色和jQuery源码解析
原生js中的函数有三种角色: 分两大种: 1.函数(最主要的角色)2.普通对象(辅助角色):函数也可以像对象一样设置属于本身的私有属性和方法,这些东西和实例或者私有变量没有关系两种角色直接没有必然的关 ...
- python平台下实现xgboost算法及输出的解释
python平台下实现xgboost算法及输出的解释 1. 问题描述 近来, 在python环境下使用xgboost算法作若干的机器学习任务, 在这个过程中也使用了其内置的函数来可视化树的结果, ...
- XGBoost中参数调整的完整指南(包含Python中的代码)
(搬运)XGBoost中参数调整的完整指南(包含Python中的代码) AARSHAY JAIN, 2016年3月1日 介绍 如果事情不适合预测建模,请使用XGboost.XGBoost算法已 ...
- JS中如何输出空格
JS中如何输出空格 在写JS代码的时候,大家可以会发现这样现象: document.write(" 1 2 3 "); 结果: 1 2 ...
- unity导出工程导入到iOS原生工程中详细步骤
一直想抽空整理一下unity原生工程导入iOS原生工程中的详细步骤.做iOS+vuforia+unity开发这么长时间了.从最初的小小白到现在的小白.中间趟过了好多的坑.也有一些的小小收货.做一个喜欢 ...
- [转]使用Maven添加依赖项时(Add Dependency)时,没有提示项目可用,并且在Console中,输出: Unable to update index for central|http://repo1.maven.org/maven2 。
使用Maven添加依赖项时(Add Dependency)时,没有提示项目可用,并且在Console中,输出: Unable to update index for central|http://re ...
- 原生JS中apply()方法的一个值得注意的用法
今天在学习vue.js的render时,遇到需要重复构造多个同类型对象的问题,在这里发现原生JS中apply()方法的一个特殊的用法: var ary = Array.apply(null, { &q ...
随机推荐
- ubuntu之路——day8.3 RMSprop
RMSprop: 全称为root mean square prop,提及这个算法就不得不提及上篇博文中的momentum算法 首先来看看momentum动量梯度下降法的过程: 在RMSprop中: C ...
- java 跳出多重循环
public class Main { public static void main(String[] args) { System.out.println("start"); ...
- 咏南跨平台中间件支持LINUX和WINDOWS插件架构
咏南跨平台中间件支持LINUX和WINDOWS插件架构
- linux网卡参数NM_CONTROLLED【转】
安装操作系统时,自动生成的网卡配置文件,/etc/sysconfig/network-scripts/ifcfg-eth0里面有如下的参数:NM_CONTROLLED=yes说明 Network ma ...
- storcli64和smartctl定位硬盘的故障信息
storcli64可对LSIRAID卡基本操作进行管理,本文主要是对LSIRAID卡常使用到的命令进行介绍 https://www.cnblogs.com/wangl-blog/archive/201 ...
- zookeeper/kafka的部署
Ubuntu中安装zookeeper及kafka并配置环境变量 首先安装zookeeper zookeeper需要jdk环境,请在jdk安装完成的情况下安装zookeeper1.从官网下载zook ...
- 高性能计算 —— 中国金融服务业创新发展的助推剂 & 微软
“高性能计算 —— 中国金融服务业创新发展的助推剂“六大盘点 - 微软 - 博客园https://www.cnblogs.com/stbchina/archive/2011/12/02/HPC-in- ...
- Mysql的三种数据类型
Mysql的三种数据类型 1.数值类型 2.日期和时间类型 3.字符串类型 00x1 [数值类型] 00x2 [日期和时间类型] 00x3 [字符串类型]
- 【转载】 clusterdata-2011-2 谷歌集群数据分析(三)
原文地址: https://blog.csdn.net/yangss123/article/details/78306270 由于原文声明其原创文章不得允许不可转载,故这里没有转载其正文内容. --- ...
- Python3基础 str __add__ 拼接,原字符串不变
Python : 3.7.3 OS : Ubuntu 18.04.2 LTS IDE : pycharm-community-2019.1.3 ...