日志收集系统ELK搭建
一、ELK简介
在传统项目中,如果在生产环境中,有多台不同的服务器集群,如果生产环境需要通过日志定位项目的Bug的话,需要在每台节点上使用传统的命令方式查询,这样效率非常低下。因此我们需要集中化的管理日志,ELK则应运而生。ELK=ElasticSeach+Logstash+Kibana,日志收集原理如下所示。
1、每台服务器集群节点安装Logstash日志收集系统插件
2、每台服务器节点将日志输入到Logstash中
3、Logstash将该日志格式化为json格式,根据每天创建不同的索引,输出到ElasticSearch中
4、浏览器使用安装Kibana查询日志信息

二、Elastic Search
2.1 简介
ElasticSearch是一个分布式搜索服务,提供的是一组Restful API,底层基于Lucene,采用多shard(分片)的方式保证数据安全,并且提供自动resharding的功能。是目前全文搜索引擎的首选,可以快速的存储、搜索和分析海量数据。
2.2 安装
1.官网下载最新版本,地址是:https://www.elastic.co/cn/downloads/elasticsearch,下载下来的最新版本是:elasticsearch-7.4.2-linux-x86_64.tar.gz;
2.解压:# tar zxvf elasticsearch-7.4.2-linux-x86_64.tar.gz
3. # cd elasticsearch-7.4.2,配置config里的elasticsearch.yml文件,配置如下。
cluster.name: es-application
node.name: es-node-1
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.1.169"]
cluster.initial_master_nodes: ["es-node-1"]
path.data: /var/data/es
path.logs: /var/log/es
4.常见问题
(1)can not run elasticsearch as root
解决思路:为了安全不允许使用root用户启动,需要新建一个es的账户,如下所示。
# adduser es
# passwd es
# chown -R es elasticsearch-7.4.2
# su elasticsearch
启动ES:
# ./bin/elasticsearch
(2)max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
解决思路: 切换到root用户修改 # vim /etc/security/limits.conf,在最后面追加下面内容,其中es 是启动ES的用户,不是root。
es hard nofile 65536
es soft nofile 65536
(3)max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决思路:切换到root用户修改配置sysctl.conf
#vi /etc/sysctl.conf
添加下面配置:
vm.max_map_count=655360
并执行命令:
sysctl -p
2.3 启动
后台启动:./elasticsearch -d
停止命令:./elasticsearch -stop
2.4 验证
访问 ip:9200,成功显示如下json信息
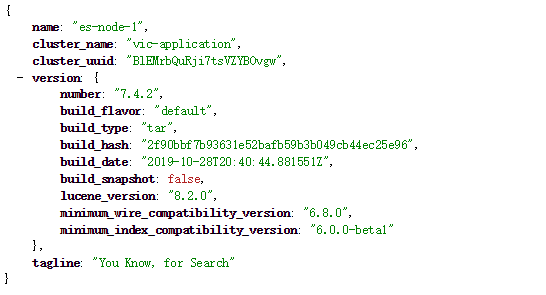
2.5 ES Head
推荐安装chrome插件,也可以下载安装包进行安装。
三、Logstash
3.1 简介
Logstash 是一个完全开源的工具,它可以对你的日志进行收集、过滤、分析,支持大量的数据获取方法,并将其存储供以后使用(如搜索)。
3.2 安装与配置
1.解压logstash-7.4.2,修改logstash-7.4.2/config的logstash.conf文件;
2.logstash.conf文件配置如下:
input {
tcp {
mode => "server"
host => "192.168.1.169"
port => 4560
codec => json_lines
}
}
output {
elasticsearch {
hosts => "192.168.1.169:9200"
index => "springboot-logstash-%{+YYYY.MM.dd}"
}
}
3.执行命令:# ../bin/logstash -f logstash.conf
3.3 Spring boot集成Logstash
1.pom文件里引入jar包
<!--logstash-->
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>6.2</version>
</dependency>
2.修改logback-spring.xml
<!--logstash地址-->
<springProperty scope="context" name="LOGSTASH_ADDRESS" source="logstash.address"/> <!--输出到logstash的appender-->
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!--可以访问的logstash日志收集端口-->
<destination>${LOGSTASH_ADDRESS}</destination>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"app": "java-study",
"level": "%-5level",
"thread": "%thread",
"logger": "%logger{50} %M %L ",
"message": "%msg"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender> <root level="INFO">
<appender-ref ref="LOGSTASH"/>
</root>
3.yml添加配置
logstash:
address: 192.168.1.169:4560
四、Kibana
4.1 简介
Kibana 是一个基于浏览器页面的Elasticsearch前端展示工具,也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
4.2 安装与配置
1.解压kibana-7.4.2-linux-x86_64.tar.gz,并修改配置文件kibana.yml
server.port: 5601
server.host: "192.168.1.169"
server.name: "kibana"
elasticsearch.hosts: ["http://192.168.1.169:9200"]
xpack.reporting.encryptionKey: "a_random_string"
xpack.security.encryptionKey: "something_at_least_32_characters"
2.执行命令 # ./kibana --allow-root
3.配置日期格式
4.create index pattern
5.保存自定义筛选字段,供后续筛选

日志收集系统ELK搭建的更多相关文章
- 日志收集系统elk
目录 elk简介 官方帮助 rsyslog rsyslog日志采集介绍与使用 综合实验 案例一: 单机ELK部署 案例二. JAVA环境配置,部署 filebeat+Elasticsearch apa ...
- ELK+kafka构建日志收集系统
ELK+kafka构建日志收集系统 原文 http://lx.wxqrcode.com/index.php/post/101.html 背景: 最近线上上了ELK,但是只用了一台Redis在 ...
- 快速搭建应用服务日志收集系统(Filebeat + ElasticSearch + kibana)
快速搭建应用服务日志收集系统(Filebeat + ElasticSearch + kibana) 概要说明 需求场景,系统环境是CentOS,多个应用部署在多台服务器上,平时查看应用日志及排查问题十 ...
- 用ElasticSearch,LogStash,Kibana搭建实时日志收集系统
用ElasticSearch,LogStash,Kibana搭建实时日志收集系统 介绍 这套系统,logstash负责收集处理日志文件内容存储到elasticsearch搜索引擎数据库中.kibana ...
- ELK 日志收集系统
传统系统日志收集的问题 在传统项目中,如果在生产环境中,有多台不同的服务器集群,如果生产环境需要通过日志定位项目的Bug的话,需要在每台节点上使用传统的命令方式查询,这样效率非常底下. 通常,日志被分 ...
- 搭建日志收集系统时使用客户端连接etcd遇到的问题
问题: 在做日志收集系统时使用到etcd,其中server端在linux上,首先安装第三方包(windows)(安装过程可能会有问题,我遇到的是连接谷歌官网请求超时,如果已经出现下面的两个文件夹并且文 ...
- [转载] 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
原文: http://www.36dsj.com/archives/25042 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要有日志收集系统.消息系统.分布式服务 ...
- 基于Flume的美团日志收集系统(一)架构和设计
美团的日志收集系统负责美团的所有业务日志的收集,并分别给Hadoop平台提供离线数据和Storm平台提供实时数据流.美团的日志收集系统基于Flume设计和搭建而成. <基于Flume的美团日志收 ...
- 基于Flume的美团日志收集系统(一)架构和设计【转】
美团的日志收集系统负责美团的所有业务日志的收集,并分别给Hadoop平台提供离线数据和Storm平台提供实时数据流.美团的日志收集系统基于Flume设计和搭建而成. <基于Flume的美团日志收 ...
随机推荐
- ML.NET学习笔记 ---- 系列文章
机器学习框架ML.NET学习笔记[1]基本概念与系列文章目录 机器学习框架ML.NET学习笔记[2]入门之二元分类 机器学习框架ML.NET学习笔记[3]文本特征分析 机器学习框架ML.NET学习笔记 ...
- 2019-2020-1 20199301《Linux内核原理与分析》第九周作业
第八章 进程的切换和系统的一般执行过程 进程的调度实际与进程的切换 ntel定义的中断类型 硬中断:就是CPU的两根引脚(可屏蔽中断和不可屏蔽中断) 软中断/异常:包括除零错误.系统调用.调试断点等在 ...
- c#的参数调用
c#的参数传递有三种方式:值传递,和c一样,引用传递,类似与c++,但形式不一样输出参数,这种方式可以返回多个值,这种有点像c中的指针传递,但其实不太一样.值传递不细说,c中已经很详细了引用传递实例如 ...
- Evaluation of fast-convergence algorithm for ICA-based blind source separation of real convolutive mixture
实际卷积混合情况下,基于ICA的盲源分离算法快速收敛性能评估[1]. 提出了一种新的盲源分离算法,该算法将独立分量分析ICA和波束形成BF相结合,通过优化算法来解决盲源分离的低收敛问题.该方法由以下三 ...
- vigil deb 包制作
前边有写过简单rpm 包的制作,现在制作一个简单的deb 包. deb 包的制作是通过源码编译+ fpm 环境准备 rust curl https://sh.rustup.rs -sSf | sh 配 ...
- Log4net 单独创建配置文件(三)
1.建立ASP.Net空的Web程序,添加Default.aspx窗体 2.添加web配置文件命名为:log4net.config,添加配置 <?xml version="1.0&qu ...
- svn项目迁移至gitlab
关于svn项目迁移有人可能会说,新建一个git项目,把原来的代码直接扔进去提交不完了吗.恩,是的,没错.但是为了保留之前的历史提交记录,还是得做下面的步骤 首先确保本地正常安装配置好git,具体步骤不 ...
- CF1237E 【Balanced Binary Search Trees】
首先我们要注意到一个性质:由于根与右子树的根奇偶性相同,那么根的奇偶性与\(N\)相同 然后我们发现对于一个完美树,他的左右两个儿子都是完美树 也就是说,一颗完美树是由两棵完美树拼成的 注意到另一个性 ...
- ImageView.ScaleType
前言 对ImageView.ScaleType,学习安卓需掌握.以官方链接:http://android.xsoftlab.net/reference/android/widget/ImageView ...
- JAVA中Stringbuffer的append( )方法
Stringbuffer是动态字符串数组,append( )是往动态字符串数组添加,跟“xxxx”+“yyyy”相当‘+’号. 跟String不同的是Stringbuffer是放一起的,String1 ...