LR 算法总结--斯坦福大学机器学习公开课学习笔记
在有监督学习里面有几个逻辑上的重要组成部件[3],初略地分可以分为:模型,参数 和 目标函数。(此部分转自 XGBoost 与 Boosted Tree)
一、模型和参数
模型指给定输入xi如何去预测 输出 yi。我们比较常见的模型如线性模型(包括线性回归和logistic regression)采用

二、目标函数:损失 + 正则
模型和参数本身指定了给定输入我们如何做预测,但是没有告诉我们如何去寻找一个比较好的参数,这个时候就需要目标函数登场了。一般的目标函数包含下面两项

常见的误差函数有平方误差、交叉熵等,而对于线性模型常见的正则化项有L2正则和L1正则。
三、优化算法
讲了这么多有监督学习的基本概念,为什么要讲这些呢? 是因为这几部分包含了机器学习的主要成分,也是机器学习工具设计中划分模块比较有效的办法。其实这几部分之外,还有一个优化算法,就是给定目标函数之后怎么学的问题。之所以我没有讲优化算法,是因为这是大家往往比较熟悉的“机器学习的部分”。而有时候我们往往只知道“优化算法”,而没有仔细考虑目标函数的设计的问题,比较常见的例子如决策树的学习,大家知道的算法是每一步去优化gini entropy,然后剪枝,但是没有考虑到后面的目标是什么。
然后看逻辑回归(LR)算法,主要参考斯坦福大学机器学习公开课,http://www.iqiyi.com/playlist399002502.html
逻辑回归是一种分类算法,而不是一种回归。逻辑回归采用sigmod函数,这是一个自变量取值在整个实数空间,因变量取值在0-1之间的函数,可以将变量的变化映射到0-1之间,从而获得概率值。
sigmod函数形式如下
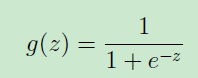
通过将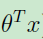 代入sigmod函数,可以得到如下形式:
代入sigmod函数,可以得到如下形式:

这样我们得到了模型和参数,下一步我们确定目标函数,逻辑回归的损失函数是交叉熵函数,求得参数采用的优化算法是最大似然。
假设
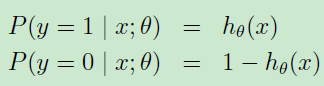
可以更加简洁的写作
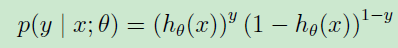
根据最大似然算法,所求的模型应该使得取得样本的情况的概率越大越好,假设样本相互之间都是独立的,则可以如下表示用模型取得样本情况的概率

也就是独立事件同时发生的概率。为了方便处理,取log则
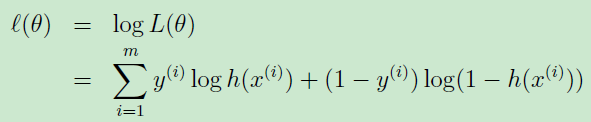
这也就是逻辑回归的损失函数。
求解这个目标函数采用随机梯度下降的方法即可,

由于sigmod函数的如下特性
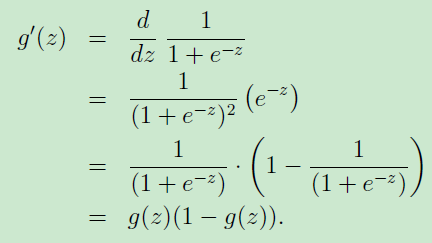
可以简单的将求梯度的式子简化如下

这样就可以通过样本不停的更新,直至找到满足要求的参数。
3: Principles of Data Mining, David Hand et al,2001. Chapter 1.5 Components of Data Mining Algorithms, 将数据挖掘算法解构为四个组件:1)模型结构(函数形式,如线性模型),2)评分函数(评估模型拟合数据的质量,如似然函数,误差平方和,误分类率),3)优化和搜索方法(评分函数的优化和模型参数的求解),4)数据管理策略(优化和搜索时对数据的高效访问)。
LR 算法总结--斯坦福大学机器学习公开课学习笔记的更多相关文章
- Andrew N.G的机器学习公开课学习笔记(一):机器学习的动机与应用
机器学习由对于人工智能的研究而来,是一个综合性和应用性学科,可以用来解决计算机视觉/生物学/机器人和日常语言等各个领域的问题,机器学习的目的是让计算机具有像人类的学习能力,这样做是因为我们发现,计算机 ...
- Stanford大学机器学习公开课(二):监督学习应用与梯度下降
本课内容: 1.线性回归 2.梯度下降 3.正规方程组 监督学习:告诉算法每个样本的正确答案,学习后的算法对新的输入也能输入正确的答案 1.线性回归 问题引入:假设有一房屋销售的数据如下: 引 ...
- Stanford大学机器学习公开课(三):局部加权回归、最小二乘的概率解释、逻辑回归、感知器算法
(一)局部加权回归 通常情况下的线性拟合不能很好地预测所有的值,因为它容易导致欠拟合(under fitting).如下图的左图.而多项式拟合能拟合所有数据,但是在预测新样本的时候又会变得很糟糕,因为 ...
- Stanford大学机器学习公开课(五):生成学习算法、高斯判别、朴素贝叶斯
(一)生成学习算法 在线性回归和Logistic回归这种类型的学习算法中我们探讨的模型都是p(y|x;θ),即给定x的情况探讨y的条件概率分布.如二分类问题,不管是感知器算法还是逻辑回归算法,都是在解 ...
- Stanford大学机器学习公开课(四):牛顿法、指数分布族、广义线性模型
(一)牛顿法解最大似然估计 牛顿方法(Newton's Method)与梯度下降(Gradient Descent)方法的功能一样,都是对解空间进行搜索的方法.其基本思想如下: 对于一个函数f(x), ...
- Stanford大学机器学习公开课(六):朴素贝叶斯多项式模型、神经网络、SVM初步
(一)朴素贝叶斯多项式事件模型 在上篇笔记中,那个最基本的NB模型被称为多元伯努利事件模型(Multivariate Bernoulli Event Model,以下简称 NB-MBEM).该模型有多 ...
- Web Mining and Big Data 公开课学习笔记 ---lecture1
1.1 LOOK Finding "stuff" on the web or computer or room or hidden in data Finding documen ...
- Web Mining and Big Data 公开课学习笔记 ---lecture0
0.1 课程主要内容:Big data technologies , Machine Learning and AI 0.6 OUTLINE: predict the future using ...
- 传智播客c/c++公开课学习笔记--邮箱账户的破解与邮箱安全防控
一.SMTP协议 SMTP(SimpleMail Transfer Protocol)即简单邮件传输协议. SMTP协议属于TCP/IP协议簇,通过SMTP协议所指定的server,就能够把E-mai ...
随机推荐
- 【转】学习ARM为什么首选IMAX6??
ARM作为目前嵌入式行业主流的架构,已经让越来越多从事电子行业的朋友了解,并且高校对于嵌入式的学习,很多直接从ARM开始,目前ARM的嵌入式培训也越来越多,足以说明现在嵌入式行业有多火.目前主流的AR ...
- kubernetes(k8s)与其架构
1. kubernetes简介 kubernetes,简称K8s,是用8代替8个字符“ubernete”而成的缩写.是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是 ...
- MapReduce工程(IDEA)
MapReduce工程(IDEA) hadoop 1. maven工程 1.1 创建maven工程 1.2 修改配置文件 1.3 Mapper类 1.4 Reduces类 1.5 Driver类 1. ...
- tomcat日志分割
1.下载(最新版本)并解压,cd进入安装目录 # wget http://cronolog.org/download/cronolog-1.6.2.tar.gz # tar zxvf cronolo ...
- php桥接模式(bridge pattern)
有点通了 <?php /* The bridge pattern is used when we want to decouple a class or abstraction from its ...
- httprunner学习3-extract提取token值参数关联(上个接口返回的token,传给下个接口请求参数)
前言 如何将上个接口的返回token,传给下个接口当做请求参数?这是最常见的一个问题了. 解决这个问题其实很简单,我们只需取出token值,设置为一个中间变量a,下个接口传这个变量a就可以了.那么接下 ...
- 安卓QQ聊天记录导出、备份完全攻略
发到知乎竟然被删掉,我也不知道我到底违反了哪条.唉,别人的毕竟是别人的.虽然博客园也是别人的 前言 我对聊天记录的备份比较执着,也在这上面折腾过不少.碰到过不少令人头疼的麻烦,在这里分享一下经验. 关 ...
- canvas小案列-绚丽多彩的倒计时
本次随笔中,我将实现一个绚丽的倒计时效果,这个效果主要是结合canvas和js实现的,具体代码如下 index.html文件 <!DOCTYPE html> <html> &l ...
- flayboard(纯属娱乐,别人做的)
<iframe id="iframe" src="" frameborder="0" width="100%" h ...
- Objective-C多态:动态类型识别+动态绑定+动态加载
http://blog.csdn.net/tskyfree/article/details/7984887 一.Objective-C多态 1.概念:相同接口,不同的实现 来自不同类可以定义共享相同名 ...