hbase 使用
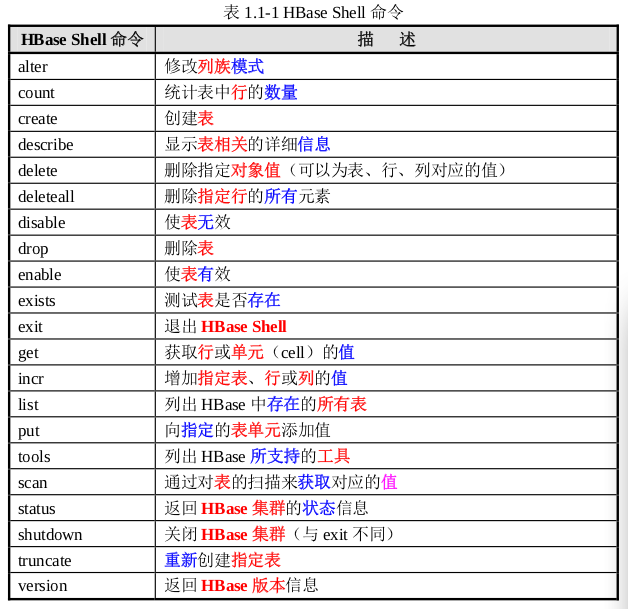
hbase shell命令的使用
再使用hbase 命令之前先检查一下hbase是否运行正常
hadoop@Master:/usr/hbase/bin$ jps
HMaster
NameNode
SecondaryNameNode
Jps
TaskTracker
DataNode
HQuorumPeer
JobTracker
HRegionServer
如果运行不正常的话,关闭hbase后重新启动一下
stop-hbase.sh
start-hbase.sh
1. status命令
hbase(main)::> status
servers, dead, 3.0000 average load
2. version命令
hbase(main)::> version
0.94., r1524863, Fri Sep :: UTC
3. create 命令
创建一个名为 test 的表,这个表只有一个列为 cf。其中表名、列都要用单引号括起来,并以逗号隔开。
hbase(main)::> create 'test', 'cf'
row(s) in 10.3830 seconds
4. list 命令
查看当前 HBase 中具有哪些表。
hbase(main)::> list
TABLE
test
row(s) in 0.3590 seconds
5. put 命令
使用 put 命令向表中插入数据,参数分别为表名、行名、列名和值,其中列名前需要列族最为前缀,时间戳由系统自动生成。
格式: put 表名,行名,列名([列族:列名]),值
例子:
加入一行数据,行名称为“row1”,列族“cf”的列名为”(空字符串)”,值位 value1。
我这里插入3条记录
hbase(main)::> put 'test', 'row1', 'cf:a', 'value1'
row(s) in 0.2350 seconds hbase(main)::> put 'test', 'row2', 'cf:b', 'value2'
row(s) in 0.0350 seconds hbase(main)::> put 'test', 'row3', 'cf:c', 'value3'
row(s) in 0.0040 seconds
6. describe 命令
查看表“test”的构造。
hbase(main)::> describe 'test'
DESCRIPTION ENABLED
'test', {NAME => 'cf', DATA_BLOCK_ENCODING => 'NONE true
', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '',
VERSIONS => '', COMPRESSION => 'NONE', MIN_VERSIO
NS => '', TTL => '', KEEP_DELETED_CELLS
=> 'false', BLOCKSIZE => '', IN_MEMORY => 'fal
se', ENCODE_ON_DISK => 'true', BLOCKCACHE => 'true'
}
row(s) in 1.6630 seconds
7.get 命令
a.查看表“test”中的行“row2”的相关数据。
hbase(main)::> get 'test','row2'
COLUMN CELL
cf:b timestamp=, value=value2
row(s) in 0.4500 seconds
b.查看表“test”中行“row2”列“cf :b”的值。
hbase(main)::> get 'test','row2', 'cf:b'
COLUMN CELL
cf:b timestamp=, value=value2
row(s) in 0.3090 seconds
或者
hbase(main)::> get 'test', 'row2', {COLUMN=>'cf:b'}
hbase(main)::> get 'test', 'row2', {COLUMNS=>'cf:b'}
备注:COLUMN 和 COLUMNS 是不同的,scan 操作中的 COLUMNS 指定的是表的列族, get操作中的 COLUMN 指定的是特定的列,COLUMNS 的值实质上为“列族:列修饰符”。COLUMN 和 COLUMNS 必须为大写。
8. scan 命令
a. 查看表“test”中的所有数据。
hbase(main)::> scan 'test'
ROW COLUMN+CELL
row1 column=cf:a, timestamp=, value=value1
row2 column=cf:b, timestamp=, value=value2
row3 column=cf:c, timestamp=, value=value3
row(s) in 0.0770 seconds
注意:
scan 命令可以指定 startrow,stoprow 来 scan 多个 row。
例如:
scan 'user_test',{COLUMNS =>'info:username',LIMIT =>, STARTROW => 'test', STOPROW=>'test2'}
b.查看表“scores”中列族“course”的所有数据。
hbase(main)::> scan 'scores', {COLUMN => 'grad'}
hbase(main)::> scan 'scores', {COLUMN=>'course:math'}
hbase(main)::> scan 'scores', {COLUMNS => 'course'}
hbase(main)::> scan 'scores', {COLUMNS => 'course'}
9.count 命令——统计出表中有多少条记录
hbase(main)::> count 'test'
row(s) in 1.6530 seconds
10. exists 命令——查看表是否存在
hbase(main)::> exists 'test'
Table test does exist
row(s) in 1.1620 seconds
11. incr 命令
给‘test’这个列增加 uid 字段,并使用counter实现递增
连续执行incr以上,COUNTER VALUE 的值会递增,通过get_counter
hbase(main)::> incr 'test', 'row2', 'uid',
COUNTER VALUE = hbase(main)::> incr 'test', 'row2', 'uid',
COUNTER VALUE =
查看表可以看到:
hbase(main)::> scan 'test'
ROW COLUMN+CELL
row1 column=uid:, timestamp=, value=buym:
row2 column=uid:, timestamp=, value=\x00\x00\x00\x
\x00\x00\x00\x05
row2 column=uid:, timestamp=, value=buym:
row(s) in 0.0790 seconds
12. delete 命令
删除表“test”中行为“row3”, 列族“cf”中的“c”。
hbase(main)::> delete 'test','row3','cf:c'
row(s) in 0.4640 seconds
13. truncate 命令——将表删除后再重新创建
hbase(main)::> truncate 'test'
Truncating 'test' table (it may take a while):
- Disabling table...
- Dropping table...
- Creating table...
row(s) in 5.6480 seconds
14. disbale、drop 命令
通过“disable”和“drop”命令删除“test”表。
hbase(main)::> disable 'test'
hbase(main)::> drop 'test'
row(s) in 3.9310 seconds
hbase 使用的更多相关文章
- Mapreduce的文件和hbase共同输入
Mapreduce的文件和hbase共同输入 package duogemap; import java.io.IOException; import org.apache.hadoop.co ...
- Redis/HBase/Tair比较
KV系统对比表 对比维度 Redis Redis Cluster Medis Hbase Tair 访问模式 支持Value大小 理论上不超过1GB(建议不超过1MB) 理论上可配置(默认配置1 ...
- Hbase的伪分布式安装
Hbase安装模式介绍 单机模式 1> Hbase不使用HDFS,仅使用本地文件系统 2> ZooKeeper与Hbase运行在同一个JVM中 分布式模式– 伪分布式模式1> 所有进 ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
- Spark读写Hbase的二种方式对比
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 一.传统方式 这种方式就是常用的TableInputFormat和TableOutputForm ...
- 深入学习HBase架构原理
HBase定义 HBase 是一个高可靠.高性能.面向列.可伸缩的分布式存储系统,利用Hbase技术可在廉价PC Server上搭建 大规模结构化存储集群. HBase 是Google Bigtabl ...
- hbase协处理器编码实例
Observer协处理器通常在一个特定的事件(诸如Get或Put)之前或之后发生,相当于RDBMS中的触发器.Endpoint协处理器则类似于RDBMS中的存储过程,因为它可以让你在RegionSer ...
- hbase集群安装与部署
1.相关环境 centos7 hadoop2.6.5 zookeeper3.4.9 jdk1.8 hbase1.2.4 本篇文章仅涉及hbase集群的搭建,关于hadoop与zookeeper的相关部 ...
- 从零自学Hadoop(22):HBase协处理器
阅读目录 序 介绍 Observer操作 示例下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,Sour ...
- Hbase安装和错误
集群规划情况: djt1 active Hmaster djt2 standby Hmaster djt3 HRegionServer 搭建步骤: 第一步:配置conf/regionservers d ...
随机推荐
- .NET读取Office文件内容(word、excel、ppt)
引用命名空间 using Microsoft.Office.Core; using Word = Microsoft.Office.Interop.Word; using Excel = Micros ...
- paip.输入法编程---词库多意义条目分割 python实现.
paip.输入法编程---词库多意义条目分割 python实现. ==========子标题 python mysql 数据库操作 多字符分隔,字符串分割 字符列表循环 作者 老哇的爪子 Attil ...
- iOS开发——高级技术&调用地图功能的实现
调用地图功能的实现 一:苹果自带地图 学习如逆水行舟,不进则退.古人告诉我们要不断的反思和总结,日思则日精,月思则月精,年思则年精.只有不断的尝试和总结,才能让我们的工作和生活更加 轻松愉快和美好.连 ...
- java历史集合类对比
- android定位GPS定位 代码实现
package com.lx.util; import android.content.Context; import android.content.SharedPreferences; imp ...
- C#类、接口、虚方法和抽象方法0322
虚拟方法和抽象方法有什么区别与联系: 1.抽象方法只有声明没有实现代码,需要在子类中实现:虚拟方法有声明和实现代码,并且可以在子类中重写,也可以不重写使用父类的默认实现. 2.抽象类不能被实例化(不可 ...
- python常用sql语句
#coding=utf-8 import MySQLdb conn = MySQLdb.Connect(host = '127.0.0.1',port=3306,user='root',passwd= ...
- [推荐]PMO学习贴大集合
[推荐]PMO学习贴大集合 http://wenku.baidu.com/view/a9b19bd4240c844769eaeed9.html http://wenku.baidu.com/view/ ...
- ffmpeg mp3 to m3u8
ffmpeg -i Sunshine.mp3 -c:a libmp3lame -b:a 128k -map 0:0 -f segment -segment_time 10 -segment_list ...
- 我所理解的JavaScript闭包
目录 一.闭包(Closure) 1.1.什么是闭包? 1.2.为什么要用闭包(作用)? 1.2.1.保护函数内的变量安全. 1.2.2.通过访问外部变量,一个闭包可以暂时保存这些变量的上下文环境,当 ...