解读SQL Server 2014可更新列存储索引——存储机制
概述
SQL Server 2014被号称是微软数据库的一个革命性版本,其性能的提升的幅度是有史以来之最。
可更新的列存储索引作为SQL Server 2014的一个关键功能之一,在提升数据库的查询性能方面贡献非常突出。据微软统计,在面向OLAP查询统计类系统中,相比其他SQL传统版本的数据库,报表查询的性能最大可提升上十倍。
下面我们从存储的角度来了解下SQL Server 2014的可更新列存储索引。
什么是列存储
微软为了提升SQL Server的查询性能,更好的支持大数据分析,早在SQL Server 2012中就引入了列存储的技术,
列存储的本质是将一个张表按照不同的列拆分,然后每一列单独存储,这样一来,存储的单位由原来的每一行变成了每一列。
像下面这张表,表中10个列分布在10个页面中,在page1中包括了表中ROW1到ROWn中列C1的数据,在page2中包括ROW1到ROWn中列C2的数据,后面依次类推。

备注:我之前有博文做过简单介绍,大家可以参考这个地址:http://www.cnblogs.com/i6first/p/3217584.html
这样做的好处就是:
- 更好的数据压缩,减少磁盘的空间占用
数据的相似性越高、重复的值越多,压缩的效果就越明显。
列存储中的每一列数属于同一种数据类型,表达的是同一个数据概念(比如都是性别),内容重复度很高,因此相比行压缩和页压缩而言,压缩效率会更好。
这样一来不仅可以有效节省磁盘空间,而且可以在同样的内存中记录更多的数据,提升查询的性能。
- 提升查询的性能
在一个查询中,我们往往只是想获取表中我们感兴趣的一列或者某几列的数据,
传统的查询做法必须把表中的所有的数据都扫描一遍,从而筛选出这些指定的列,
当表中包含的列比较多、数据量时,这种查询的效率的就会很低,
但如果使用了列存储,因为每一个列都是集中且彼此独立地存储,查询时只需要扫描这些指定列所在的存储区域就好了,不需要读其他不需要列的数据。查询的范围就小了很多。
比如这个查询:
select c1 from myuser1
因为mytable表中所有的C1列都是集中存储的,一次查询只扫描C1列的存储区域就好了。
什么是列存储索引
在传统的表上创建列存储索引后便可实现表的列存储。
在SQL Server 2014中,有两种列存储索引:列非聚集索引和列聚集索引。
(1)、列非聚集索引的特点
- 跟非聚集索引一样,创建列非聚集索引时必须为索引列创建一个副本,占用额外的磁盘空间,不过因为数据压缩的原因,其占用的空间会比较小
- 列非聚集索引的表是不可以更新的
备注:SQL Server 2012上只能建列非聚集索引,不能建列聚集索引。
(2)、列聚集索引的特点
- 索引页就是数据页,高压缩率大大减少磁盘空间的占用
- 可以对表进行更新
- 列聚集索引必须是表的唯一索引,如果表中存在聚集索引或者非聚集索引,则必须删除原来的索引才能创建列存储索引
- 只有企业版、开发版、评估版中才能使用
- 不会改变列的物理存储顺序,其目的主要是为了提升性能和实现较高的数据压缩
备注:读者可以访问此地址,了解更多关于列聚集索引相关特性及使用限制。另外,下文如无特别说明,所描述的列存储均是包含列聚集索引的存储结构。
创建列聚集索引
列存储索引创建时不需要指定列名,索引一旦创建完成,表中所有的行就会以列的方式存储。
CREATE CLUSTERED COLUMNSTORE INDEX ci_myUser ON MyUser1; GO
为了更好的说明在列聚集索引创建时“行表”——>“列存储”的过程,我做了一张简图,并对每个序号的说明如下:
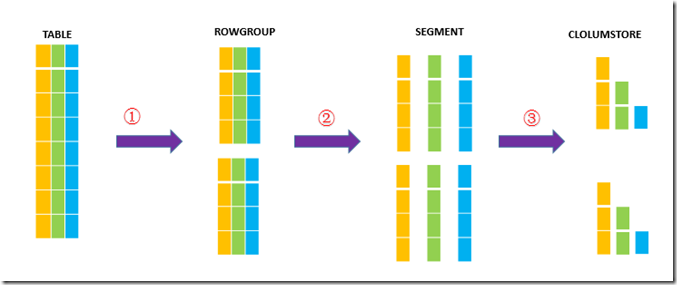
①:首先,表被拆分成一个或者多个行组(ROW GROUP);
一般而言,每个行组中的行数必须满足最小为102,400、最大1,048,576后才能转换成列存储。但如果直接在表上创建列存储索引时,这条规则可以“忽视”,因为即使表的行数少于102,400,也可以形成能够转接为列存储的行组。
其实简单想想也能理解,因为索引创建时,SQL Server不可能等着表着行数增大到102,400后再去形成列存储。
在下面我演示了一个示例,表MyUser1有102行数据,我在表上创建了一个列存储索引,大家可以看到只有一个包含了102行的行组,且该行组已经转换为列存储了。
SELECT COUNT(*)AS rows_count FROM myuser1
SELECT i.object_id, object_name(i.object_id) AS TableName, i.name
AS IndexName,
CSRowGroups.state_description,CSRowGroups.row_group_id,CSRowGroups.total_rows, CSRowGroups.*, 100*(total_rows - ISNULL(deleted_rows,0))/total_rows AS PercentFull
FROM sys.indexes AS i JOIN sys.column_store_row_groups AS CSRowGroups
ON i.object_id = CSRowGroups.object_id
AND i.index_id = CSRowGroups.index_id --WHERE object_name(i.object_id) = '<table_name>'
ORDER BY object_name(i.object_id), i.name, CSRowGroups.row_group_id;
图中,该表只有一个行组,行组ID为0(row_group_id),因为state_description为compressed(下文会详细介绍state_description的值所代表的意义),说明该行组已经按照列方式存储了。


②:将行组按列划分列块;
行组在达到指定的大小后(102400-1048576),必须按照列进行拆分,每一列形成一个列块。每个列块包含了这一列的所有数据。
再来看我的示例,表MyUser1一共有33列,按照列块的定义,就会有33个列块。
SELECT max_column_id_used FROM SYS.TABles WHERE OBJECT_ID=OBJECT_ID('MYUSER1')
SELECT i.name, p.object_id, p.index_id, i.type_desc,
COUNT(*) AS number_of_segments FROM sys.column_store_segments AS s
INNER JOIN sys.partitions AS p
ON s.hobt_id =
p.hobt_id INNER JOIN sys.indexes AS i
ON p.object_id = i.object_id
GROUP BY i.name, p.object_id, p.index_id,
i.type_desc ; GO
图示:myuser1表的列数33。
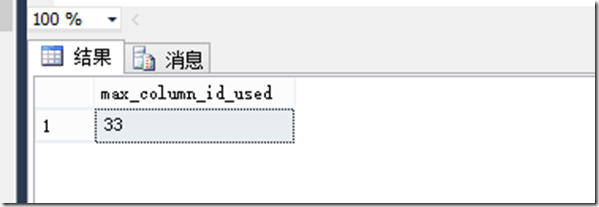
图示:myuser1表的列块数33(number_of_segments)。

③:每个列块被压缩后存储在物理磁盘上;
步骤2中列块的形成不是目的,只是手段。
列块必须压缩后才能真正按照列方式存储,根据MSDN说法,压缩后形成的列存储最大可以节省7倍的磁盘空间,
在如下示例中,我做了两个表,simpletable上有列聚集索引,simpletable_nocci上没有列聚集索引,只有聚集索引,每张表都包含了1048577行数据,且数据内容完全相同。
我们通过sp_spaceused来查看下两个表的磁盘空间占用情况,
sp_spaceused 'simpletable_nocci'
GO sp_spaceused
'simpletable'
GO
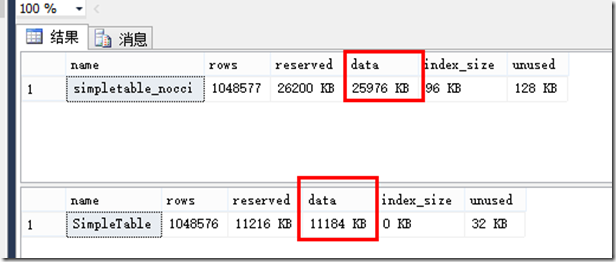
显然,simpletable_nocci的磁盘空间占用亮是simpletable的2倍多。
INSERT和BULK INSERT
在含有列聚集索引的表插入的行需要经过行——行组——列块——列存储的过程。这与传统表中插入数据是不同的。。
下面我们通过两种SQL Server insert方法来了解列存储中插入数据的过程。
(1) INSERT
Insert,也称为TRICKLE Insert,我们通常使用的insert into就是TRICKLE Insert。
在SQL 2014中,每次insert的行不会直接写入到列存储中,
因为这样会产生大量的索引碎片,而且这种零散的插入不能获得很好的压缩效果,影响列存储和查询的性能。
对于这些新插入的数据,SQL 2014中引入了DELTA STORE临时表,
新些插入的行还是按照行的方式存储在DELTA STORE中,并可以通过B-Tree进行检索。也就说,DELTA STORE其实传统表的存储结构一样,也是行式存储。
如图:
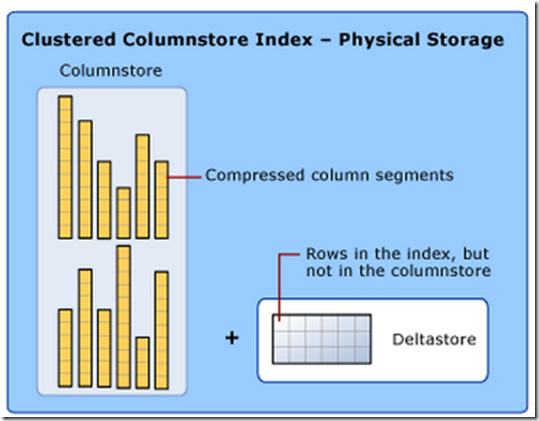
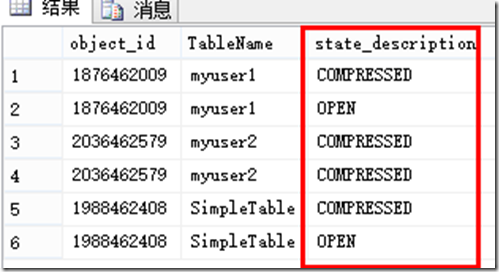
当DELTA STORE中行组的行数达到所要求的1048,576行时,该行组就会被标记为CLSOED,不再允许新数据插入。
然后SQL 2014的后台进程Move Truple扫描到CLSOED的行组时,会将该行组从delta store迁到列存储,最后将该行组标记为COMPRESSED。
如图:

RowGroup1的Row已经达到行组的最大值,该行组被标记为CLOSED,表示不能在接受新数据插入。
RowGroup2的Row小于1048576行,即使满足行组要求的最小值,也还是在OPEN状态,直到达到行组最大大小。
行组的状态可以通过如下语句查询得到:
SELECT i.object_id, object_name(i.object_id) AS TableName, CSRowGroups.state_description
FROM sys.indexes AS i JOIN sys.column_store_row_groups AS CSRowGroups
ON i.object_id = CSRowGroups.object_id
AND i.index_id = CSRowGroups.index_id --WHERE object_name(i.object_id) = '<table_name>'
ORDER BY object_name(i.object_id), i.name, row_group_id;
(2)BULK INSERT
Bulk insert可以理解为一种高性能的插入方法,Bulk Insert常常用于大数据导入操作,其性能要比Trickle Insert好很多,
(有兴趣的读者可以自己验证下,插入相同行的数据,哪个更快一点。)
也正是基于此,Bulk Insert在列存储中插入数据的方法与和Trickle Insert也有些区别。
当一次Bulk Insert的数据达到行组的最小值102,400时,该行组可以不经过delta Store而直接按照列方式存储。
这里需要引起我们注意的是,之前我们说Trickle Insert的列存储形成过程,不仅要求行组达到1048576,而且还必须先存储在delta Store中。
由此可见在大批量的数据导入中,Bulk insert是首选的方法。
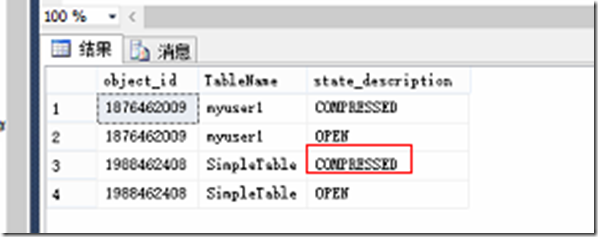
下面的实例中,我将一个含有102,400的t1.txt通过bulk insert导入到数据库中,可以看到该行组的结果直接变为COMPRESSED。
bulk insertBULK INSERT simpletable FROM 'd:\temp\t1.txt'
t1.txt的格式如下:
不过如果一次Bulk Insert插入的数据大于一个行组但小于两个行组时,多出的这部分数据必须也存储在delta Store中。
DELETE和UPDATE
因为列聚集索引的表可能同时包含行存储的delta store和列存储,所以在处理删除和更新时,两个不同区域会有所不同。
(1)delete
我们先看删除操作:
- 如果删除的行在列存储中,SQL Server只是从逻辑上删除它,其占用的物理空间并不会释放
SQL Server 2014 的delete bitmap是用来跟踪列存储中的每一个记录删除情况的表,它跟delta store一样也是基于行和B-tree的方式存储。
当某一行需要被删除时,delete bitmap会将该行对应的bit标记为删除状态,实际上行的所在的物理区域没有发生变化。
这样就要求所有的查询语句必须先扫描delete bitmap,对于哪些已被记为删除的记录就不要到物理存储查找了,也不需要出现在查询的结果中。

- 如果删除的行在Delta Store中,这跟传统行存储的删除方式没有区别,SQL Server会从逻辑上和物理上都删除该数据。
(2)update
理解了insert和delete后,我们再来看update就非常简单了。
- 如果update发生在列存储中
SQL Server会将该行在delete bitmap中bit标记为删除状态,同时插入一新行到delta store中。
- 如果update发生在delta store中
SQL Server直接更新delta store中这行的数据。
结论
尽管SQL Server 2014的列存储已经支持数据更新,但并不意味着生产环境下的报表能够从中获益。
列存储天生是为OLAP设计,其数据特征更趋向于静态,即使是数据的导入,微软也建议使用bulk insert,
所以如果数据库的日常操作中存在大量的增、删、改等操作,使用列存储的技术可能会适得其反。
解读SQL Server 2014可更新列存储索引——存储机制的更多相关文章
- SQL Server 2014新特性:分区索引重建
<single_partition_rebuild_index_option> ::= { SORT_IN_TEMPDB = { ON | OFF } | MAXDOP = m ...
- 谈谈我的微软特约稿:《SQL Server 2014 新特性:IO资源调控》
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 撰写经历(Experience) 特约稿正文(Content-body) 第一部分:生活中资源 ...
- SQL Server 2014 新特性:IO资源调控
谈谈我的微软特约稿:<SQL Server 2014 新特性:IO资源调控> 2014-07-01 10:19 by 听风吹雨, 570 阅读, 16 评论, 收藏, 收藏 一.本文所涉及 ...
- SQL Server 2014新特性探秘(3)-可更新列存储聚集索引
简介 列存储索引其实在在SQL Server 2012中就已经存在,但SQL Server 2012中只允许建立非聚集列索引,这意味着列索引是在原有的行存储索引之上的引用了底层的数据,因此会 ...
- 在SQL Server 2014里可更新的列存储索引 (Updateable Column Store Indexes)
传统的关系数据库服务引擎往往并不是对超大量数据进行分析计算的最佳平台,为此,SQL Server中开发了分析服务引擎去对大笔数据进行分析计算.当然,对于数据的存放平台SQL Server数据库引擎而言 ...
- SQL Server 2014 聚集列存储
SQL Server 自2012以来引入了列存储的概念,至今2016对列存储的支持已经是非常友好了.由于我这边线上环境主要是2014,所以本文是以2014为基础的SQL Server 的列存储的介绍. ...
- SQL Server ->> ColumnStore Index(列存储索引)
Columnstored index是SQL Server 2012后加入的重大特性,数据不再以heap或者B Tree的形式存储(row level)存储在每一个数据库文件的页里面,而是以列为单位存 ...
- 在SQL Server 2014里,如何用资源调控器压制你的存储?
在今天的文章里,我想谈下SQL Server 2014里非常酷的提升:现在你终于可以根据需要的IOPS来压制查询!资源调控器(Resource Governor)自SQL Server 2008起引入 ...
- SQL Server 2014 SP2发布下载:数十项更新修复
微软发布了数据库工具SQL Server 2014 SP2服务包下载,本次更新集合了数十项更新修复,涉及安全和功能性补丁,使用SQL Server 2014的用户应该及时安装该服务包. 文件内容 版本 ...
随机推荐
- Linux(centos)系统各个目录的作用详解
Linux(centos)系统各个目录的作用详解 文件系统的类型 LINUX有四种基本文件系统类型:普通文件.目录文件.连接文件和特殊文件,可用file命令来识别. 普通文件:如文本文件.C语言元代码 ...
- Spring中Aware相关接口原理
Spring中提供一些Aware相关接口,像是BeanFactoryAware. ApplicationContextAware.ResourceLoaderAware.ServletContextA ...
- Intel 82599 万兆网卡
http://www.cnblogs.com/zhuyp1015/archive/2012/08/23/2653264.html http://bbs.chinaunix.net/thread-424 ...
- laravel 表单验证
$this->validate($request, [ 'sn' =>['regex:/^\d{6}$/','required'], 'user' => ['numeric','mi ...
- LightOJ 1313 - Protect the Mines(凸包)
1313 - Protect the Mines PDF (English) Statistics Forum Time Limit: 2 second(s) Memory Limit: 32 M ...
- xcode archive 一直是灰色的
把配置选择为device才能选build and archive的,模拟器的肯定不能build and anchive
- jQuery数组处理汇总
jQuery数组处理汇总 有段时间没写什么了, 打算把jquery中的比较常用的数组处理方法汇总一下 $.each(array, [callback])遍历,很常用 1 2 3 4 5 6 7 8 ...
- getpid 与 gettid 与 pthread_self
获取进程的PID(process ID) #include <unistd.h> pid_t getpid(void); 获取线程的TID(thread ID) 1)gettid或者类似g ...
- Highcharts 的实际实践一
题记: 原先是想用chart.js 这个轻量级来完成我的需求的,结果基于我的数据不规则,所以实现不了. 我的需求: XX后台系统会产生有些报警日志. 我负责把这些数据按照图标的方式来展示. 这写报警日 ...
- HTML5和CSS3基础教程(第8版)-读书笔记
第1章 网页的构造块 一个网页主要包括以下三个部分: n 文本内容(text content):在页面上让访问者了解页面内容的纯文字. n 对其他文件的引用(referen ...