Apache Spark源码走读之22 -- 浅谈mllib中线性回归的算法实现
欢迎转载,转载请注明出处,徽沪一郎。
概要
本文简要描述线性回归算法在Spark MLLib中的具体实现,涉及线性回归算法本身及线性回归并行处理的理论基础,然后对代码实现部分进行走读。
线性回归模型
机器学习算法是的主要目的是找到最能够对数据做出合理解释的模型,这个模型是假设函数,一步步的推导基本遵循这样的思路
- 假设函数
- 为了找到最好的假设函数,需要找到合理的评估标准,一般来说使用损失函数来做为评估标准
- 根据损失函数推出目标函数
- 现在问题转换成为如何找到目标函数的最优解,也就是目标函数的最优化
具体到线性回归来说,上述就转换为


梯度下降法
那么如何求得损失函数的最优解,针对最小二乘法来说可以使用梯度下降法。

算法实现

随机梯度下降


正则化

如何解决这些问题呢?可以采用收缩方法(shrinkage method),收缩方法又称为正则化(regularization)。
主要是岭回归(ridge regression)和lasso回归。通过对最小二乘估计加
入罚约束,使某些系数的估计为0。

线性回归的代码实现
上面讲述了一些数学基础,在将这些数学理论用代码来实现的时候,最主要的是把握住相应的假设函数和最优化算法是什么,有没有相应的正则化规则。
对于线性回归,这些都已经明确,分别为
- Y = A*X + B 假设函数
- 随机梯度下降法
- 岭回归或Lasso法,或什么都没有
那么Spark mllib针对线性回归的代码实现也是依据该步骤来组织的代码,其类图如下所示
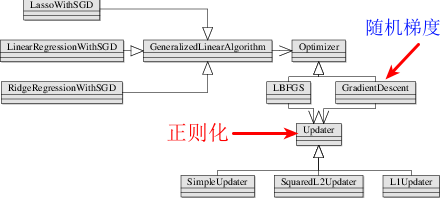
函数调用路径

train->run,run函数的处理逻辑
- 利用最优化算法来求得最优解,optimizer.optimize
- 根据最优解创建相应的回归模型, createModel
runMiniBatchSGD是真正计算Gradient和Loss的地方
def runMiniBatchSGD(data: RDD[(Double, Vector)],gradient: Gradient,updater: Updater,stepSize: Double,numIterations: Int,regParam: Double,miniBatchFraction: Double,initialWeights: Vector): (Vector, Array[Double]) = {val stochasticLossHistory = new ArrayBuffer[Double](numIterations)val numExamples = data.count()val miniBatchSize = numExamples * miniBatchFraction// if no data, return initial weights to avoid NaNsif (numExamples == 0) {logInfo("GradientDescent.runMiniBatchSGD returning initial weights, no data found")return (initialWeights, stochasticLossHistory.toArray)}// Initialize weights as a column vectorvar weights = Vectors.dense(initialWeights.toArray)val n = weights.size/*** For the first iteration, the regVal will be initialized as sum of weight squares* if it's L2 updater; for L1 updater, the same logic is followed.*/var regVal = updater.compute(weights, Vectors.dense(new Array[Double](weights.size)), 0, 1, regParam)._2for (i (c, v) match { case ((grad, loss), (label, features)) =>val l = gradient.compute(features, label, bcWeights.value, Vectors.fromBreeze(grad))(grad, loss + l)},combOp = (c1, c2) => (c1, c2) match { case ((grad1, loss1), (grad2, loss2)) =>(grad1 += grad2, loss1 + loss2)})/*** NOTE(Xinghao): lossSum is computed using the weights from the previous iteration* and regVal is the regularization value computed in the previous iteration as well.*/stochasticLossHistory.append(lossSum / miniBatchSize + regVal)val update = updater.compute(weights, Vectors.fromBreeze(gradientSum / miniBatchSize), stepSize, i, regParam)weights = update._1regVal = update._2}logInfo("GradientDescent.runMiniBatchSGD finished. Last 10 stochastic losses %s".format(stochasticLossHistory.takeRight(10).mkString(", ")))(weights, stochasticLossHistory.toArray)}
上述代码中最需要引起重视的部分是aggregate函数的使用,先看下aggregate函数的定义
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U = {// Clone the zero value since we will also be serializing it as part of tasksvar jobResult = Utils.clone(zeroValue, sc.env.closureSerializer.newInstance())val cleanSeqOp = sc.clean(seqOp)val cleanCombOp = sc.clean(combOp)val aggregatePartition = (it: Iterator[T]) => it.aggregate(zeroValue)(cleanSeqOp, cleanCombOp)val mergeResult = (index: Int, taskResult: U) => jobResult = combOp(jobResult, taskResult)sc.runJob(this, aggregatePartition, mergeResult)jobResult}
aggregate函数有三个入参,一是初始值ZeroValue,二是seqOp,三为combOp.
- seqOp seqOp会被并行执行,具体由各个executor上的task来完成计算
- combOp combOp则是串行执行, 其中combOp操作在JobWaiter的taskSucceeded函数中被调用
为了进一步加深对aggregate函数的理解,现举一个小小例子。启动spark-shell后,运行如下代码
val z = sc. parallelize (List (1 ,2 ,3 ,4 ,5 ,6),2)z.aggregate (0)(math.max(_, _), _ + _)// 运 行 结 果 为 9res0: Int = 9
仔细观察一下运行时的日志输出, aggregate提交的job由一个stage(stage0)组成,由于整个数据集被分成两个partition,所以为stage0创建了两个task并行处理。
LeastSquareGradient
讲完了aggregate函数的执行过程, 回过头来继续讲组成seqOp的gradient.compute函数。
LeastSquareGradient用来计算梯度和误差,注意cmopute中cumGraident会返回改变后的结果。这里计算公式依据的就是cost-function中的▽Q(w)
class LeastSquaresGradient extends Gradient {override def compute(data: Vector, label: Double, weights: Vector): (Vector, Double) = {val brzData = data.toBreezeval brzWeights = weights.toBreezeval diff = brzWeights.dot(brzData) - labelval loss = diff * diffval gradient = brzData * (2.0 * diff)(Vectors.fromBreeze(gradient), loss)}override def compute(data: Vector,label: Double,weights: Vector,cumGradient: Vector): Double = {val brzData = data.toBreezeval brzWeights = weights.toBreeze//dot表示点积,是接受在实数R上的两个向量并返回一个实数标量的二元运算,它的结果是欧几里得空间的标准内积。//两个向量的点积写作a·b。点乘的结果叫做点积,也称作数量积val diff = brzWeights.dot(brzData) - label//下面这句话完成y += a*xbrzAxpy(2.0 * diff, brzData, cumGradient.toBreeze)diff * diff}}
在上述代码中频繁出现breeze相关的函数,你一定会很好奇,这是个什么新鲜玩艺。
说 开 了 其 实 一 点 也 不 稀 奇, 由 于 计 算 中 有 大 量 的 矩 阵(Matrix)及 向量(Vector)计算,为了更好支持和封装这些计算引入了breeze库。
Breeze, Epic及Puck是scalanlp中三大支柱性项目, 具体可参数www.scalanlp.org
正则化过程
根据本次迭代出来的梯度和误差对权重系数进行更新,这个时候就需要用上正则化规则了。也就是下述语句会触发权重系数的更新
val update = updater.compute(weights, Vectors.fromBreeze(gradientSum / miniBatchSize), stepSize, i, regParam)
以岭回归为例,看其更新过程的代码实现。
class SquaredL2Updater extends Updater {override def compute(weightsOld: Vector,gradient: Vector,stepSize: Double,iter: Int,regParam: Double): (Vector, Double) = {// add up both updates from the gradient of the loss (= step) as well as// the gradient of the regularizer (= regParam * weightsOld)// w' = w - thisIterStepSize * (gradient + regParam * w)// w' = (1 - thisIterStepSize * regParam) * w - thisIterStepSize * gradientval thisIterStepSize = stepSize / math.sqrt(iter)val brzWeights: BV[Double] = weightsOld.toBreeze.toDenseVectorbrzWeights :*= (1.0 - thisIterStepSize * regParam)brzAxpy(-thisIterStepSize, gradient.toBreeze, brzWeights)val norm = brzNorm(brzWeights, 2.0)(Vectors.fromBreeze(brzWeights), 0.5 * regParam * norm * norm)}}
结果预测
计算出权重系数(weights)和截距intecept,就可以用来创建线性回归模型LinearRegressionModel,利用模型的predict函数来对观测值进行预测
class LinearRegressionModel (override val weights: Vector,override val intercept: Double)extends GeneralizedLinearModel(weights, intercept) with RegressionModel with Serializable {override protected def predictPoint(dataMatrix: Vector,weightMatrix: Vector,intercept: Double): Double = {weightMatrix.toBreeze.dot(dataMatrix.toBreeze) + intercept}}
注意LinearRegression的构造函数需要权重(weights)和截距(intercept)作为入参,对新的变量做出预测需要调用predictPoint
一个完整的示例程序
在spark-shell中执行如下语句来亲自体验一下吧。
import org.apache.spark.mllib.regression.LinearRegressionWithSGDimport org.apache.spark.mllib.regression.LabeledPointimport org.apache.spark.mllib.linalg.Vectors// Load and parse the dataval data = sc.textFile("mllib/data/ridge-data/lpsa.data")val parsedData = data.map { line =>val parts = line.split(',')LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(' ').map(_.toDouble)))}// Building the modelval numIterations = 100val model = LinearRegressionWithSGD.train(parsedData, numIterations)// Evaluate model on training examples and compute training errorval valuesAndPreds = parsedData.map { point =>val prediction = model.predict(point.features)(point.label, prediction)}val MSE = valuesAndPreds.map{case(v, p) => math.pow((v - p), 2)}.mean()println("training Mean Squared Error = " + MSE)
小结
再次强调,找到对应的假设函数,用于评估的损失函数,最优化求解方法,正则化规则
Apache Spark源码走读之22 -- 浅谈mllib中线性回归的算法实现的更多相关文章
- Apache Spark源码走读之7 -- Standalone部署方式分析
欢迎转载,转载请注明出处,徽沪一郎. 楔子 在Spark源码走读系列之2中曾经提到Spark能以Standalone的方式来运行cluster,但没有对Application的提交与具体运行流程做详细 ...
- Apache Spark源码走读之16 -- spark repl实现详解
欢迎转载,转载请注明出处,徽沪一郎. 概要 之所以对spark shell的内部实现产生兴趣全部缘于好奇代码的编译加载过程,scala是需要编译才能执行的语言,但提供的scala repl可以实现代码 ...
- Apache Spark源码走读之13 -- hiveql on spark实现详解
欢迎转载,转载请注明出处,徽沪一郎 概要 在新近发布的spark 1.0中新加了sql的模块,更为引人注意的是对hive中的hiveql也提供了良好的支持,作为一个源码分析控,了解一下spark是如何 ...
- Apache Spark源码走读之23 -- Spark MLLib中拟牛顿法L-BFGS的源码实现
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文就拟牛顿法L-BFGS的由来做一个简要的回顾,然后就其在spark mllib中的实现进行源码走读. 拟牛顿法 数学原理 代码实现 L-BFGS算法中使 ...
- Apache Spark源码走读之18 -- 使用Intellij idea调试Spark源码
欢迎转载,转载请注明出处,徽沪一郎. 概要 上篇博文讲述了如何通过修改源码来查看调用堆栈,尽管也很实用,但每修改一次都需要编译,花费的时间不少,效率不高,而且属于侵入性的修改,不优雅.本篇讲述如何使用 ...
- Apache Spark源码走读之6 -- 存储子系统分析
欢迎转载,转载请注明出处,徽沪一郎. 楔子 Spark计算速度远胜于Hadoop的原因之一就在于中间结果是缓存在内存而不是直接写入到disk,本文尝试分析Spark中存储子系统的构成,并以数据写入和数 ...
- Apache Spark源码走读之17 -- 如何进行代码跟读
欢迎转载,转载请注明出处,徽沪一郎 概要 今天不谈Spark中什么复杂的技术实现,只稍为聊聊如何进行代码跟读.众所周知,Spark使用scala进行开发,由于scala有众多的语法糖,很多时候代码跟着 ...
- Apache Spark源码走读之5 -- DStream处理的容错性分析
欢迎转载,转载请注明出处,徽沪一郎,谢谢. 在流数据的处理过程中,为了保证处理结果的可信度(不能多算,也不能漏算),需要做到对所有的输入数据有且仅有一次处理.在Spark Streaming的处理机制 ...
- Apache Spark源码走读之11 -- sql的解析与执行
欢迎转载,转载请注明出处,徽沪一郎. 概要 在即将发布的spark 1.0中有一个新增的功能,即对sql的支持,也就是说可以用sql来对数据进行查询,这对于DBA来说无疑是一大福音,因为以前的知识继续 ...
随机推荐
- 信与信封问题(codevs 1222)
题目描述 Description John先生晚上写了n封信,并相应地写了n个信封将信装好,准备寄出.但是,第二天John的儿子Small John将这n封信都拿出了信封.不幸的是,Small Joh ...
- ***git 本地提交后如果让服务器上的GIT 自动更新拉取
Q: 最近配了个服务器,用的GIT,本地提交后服务器必须再拉取一下才能更新出来..求个提交后自动更新的方法 A: 最佳工具 git hook post-update.sample 改名为post-up ...
- Java Hour 12 Generic
有句名言,叫做10000小时成为某一个领域的专家.姑且不辩论这句话是否正确,让我们到达10000小时的时候再回头来看吧. 本文作者Java 现经验约为12 Hour,请各位不吝赐教. 泛型程序设计 为 ...
- JNI,NDK
jni的调用过程 1)安装和下载Cygwin,下载Android NDK 2)在ndk项目中JNI接口的设计 3)使用C/C++实现本地方法 4)JNI生成动态链接库.so文件 5)将动态链接库复制到 ...
- Rotating Sentences
#include<bits/stdc++.h> #define N 110 int main(void) { char s[N][N]; int i, j, k, max; , memse ...
- sql 遍历结果print和表格形式
select * from tb_province --省 pID pName1 北京市2 天津市3 上海市4 重庆市5 河北省6 山西省....... select * from tb_city - ...
- Jquery用途
封装JS,开源,操作方便,提高开发效率. 轻量级,选择器强大,浏览器兼容.
- 在JavaScript中,this关键字指什么?
指向对象.window.方法. 例子1 function a(){//当前调用栈是a,因此a的调用位置是全局作用域 console.log('a'); b();// b的调用位置 } function ...
- python 代码片段9
#coding=utf-8 # 字符串指示符号 r表示raw u表示unicode mystring=u'this is unicode!--by' print mystring # 'raw'表示告 ...
- BZOJ3809: Gty的二逼妹子序列
Description Autumn和Bakser又在研究Gty的妹子序列了!但他们遇到了一个难题. 对于一段妹子们,他们想让你帮忙求出这之内美丽度∈[a,b]的妹子的美丽度的种类数. 为了方 ...