数据挖掘系列(4)使用weka做关联规则挖掘
前面几篇介绍了关联规则的一些基本概念和两个基本算法,但实际在商业应用中,写算法反而比较少,理解数据,把握数据,利用工具才是重要的,前面的基础篇是对算法的理解,这篇将介绍开源利用数据挖掘工具weka进行管理规则挖掘。
weka数据集格式arff
arff标准数据集简介
weka的数据文件后缀为arff(Attribute-Relation File Format,即属性关系文件格式),arff文件分为注释、关系名、属性名、数据域几大部分,注释用百分号开头%,关系名用@relation申明,属性用@attribute什么,数据域用@data开头,看这个示例数据集(安装weka后,可在weka的安装目录/data下找到weather.numeric.arff):
%weather dataset
@relation weather @attribute outlook {sunny, overcast, rainy}
@attribute temperature numeric
@attribute humidity numeric
@attribute windy {TRUE, FALSE}
@attribute play {yes, no} @data
sunny,85,85,FALSE,no
sunny,80,90,TRUE,no
overcast,83,86,FALSE,yes
rainy,70,96,FALSE,yes
rainy,68,80,FALSE,yes
rainy,65,70,TRUE,no
overcast,64,65,TRUE,yes
sunny,72,95,FALSE,no
sunny,69,70,FALSE,yes
rainy,75,80,FALSE,yes
sunny,75,70,TRUE,yes
overcast,72,90,TRUE,yes
overcast,81,75,FALSE,yes
rainy,71,91,TRUE,no
当数据是数值型,在属性名的后面加numeric,如果是离散值(枚举值),就用一个大括号将值域列出来。@data下一行后为数据记录,数据为矩阵形式,即每一个的数据元素个数相等,若有缺失值,就用问号?表示。
arff稀疏数据集
我们做关联规则挖掘,比如购物篮分析,我们的购物清单数据肯定是相当稀疏的,超市的商品种类有上10000种,而每个人买东西只会买几种商品,这样如果用矩阵形式表示数据显然浪费了很多的存储空间,我们需要用稀疏数据表示,看我们的购物清单示例(basket.txt):
freshmeat dairy confectionery
freshmeat confectionery
cannedveg frozenmeal beer fish
dairy wine
freshmeat wine fish
fruitveg softdrink
beer
fruitveg frozenmeal
fruitveg fish
fruitveg freshmeat dairy cannedveg wine fish
fruitveg fish
dairy cannedmeat frozenmeal fish
数据集的每一行表示一个去重后的购物清单,进行关联规则挖掘时,我们可以先把商品名字映射为id号,挖掘的过程只有id号就是了,到规则挖掘出来之后再转回商品名就是了,retail.txt是一个转化为id号的零售数据集,数据集的前面几行如下:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
30 31 32
33 34 35
36 37 38 39 40 41 42 43 44 45 46
38 39 47 48
38 39 48 49 50 51 52 53 54 55 56 57 58
32 41 59 60 61 62
3 39 48
63 64 65 66 67 68
32 69
这个数据集的商品有16469个,一个购物的商品数目远少于商品中数目,因此要用稀疏数据表,weka支持稀疏数据表示,但我在运用apriori算法时有问题,先看一下weka的稀疏数据要求:稀疏数据和标准数据的其他部分都一样,唯一不同就是@data后的数据记录,示例如下(basket.arff):
@relation 'basket'
@attribute fruitveg {F, T}
@attribute freshmeat {F, T}
@attribute dairy {F, T}
@attribute cannedveg {F, T}
@attribute cannedmeat {F, T}
@attribute frozenmeal {F, T}
@attribute beer {F, T}
@attribute wine {F, T}
@attribute softdrink {F, T}
@attribute fish {F, T}
@attribute confectionery {F, T}
@data
{1 T, 2 T, 10 T}
{1 T, 10 T}
{3 T, 5 T, 6 T, 9 T}
{2 T, 7 T}
{1 T, 7 T, 9 T}
{0 T, 8 T}
{6 T}
{0 T, 5 T}
{0 T, 9 T}
{0 T, 1 T, 2 T, 3 T, 7 T, 9 T}
{0 T, 9 T}
{2 T, 4 T, 5 T, 9 T}
可以看到
freshmeat dairy confectionery
freshmeat confectionery
表示为了:
{1 T, 2 T, 10 T}
{1 T, 10 T
稀疏数据的表示格式为:{<属性列号><空格><值>,...,<属性列号><空格><值>},注意每条记录要用大括号,属性列号不是id号,属性列号是从0开始的,即第一个@attribute 后面的属性是第0个属性,T表示数据存在。
规则挖取
我们先用标准数据集normalBasket.arff[1]试一下,weka的apriori算法和FPGrowth算法。
1、安装好weka后,打开选择Explorer
2、打开文件
3、选择关联规则挖掘,选择算法
4、设置参数
参数主要是选择支持度(lowerBoundMinSupport),规则评价机制metriType(见上一篇)及对应的最小值,参数设置说明如下[2]:
. car 如果设为真,则会挖掘类关联规则而不是全局关联规则。
. classindex 类属性索引。如果设置为-,最后的属性被当做类属性。
. delta 以此数值为迭代递减单位。不断减小支持度直至达到最小支持度或产生了满足数量要求的规则。
. lowerBoundMinSupport 最小支持度下界。
. metricType 度量类型。设置对规则进行排序的度量依据。可以是:置信度(类关联规则只能用置信度挖掘),提升度(lift),杠杆率(leverage),确信度(conviction)。
在 Weka中设置了几个类似置信度(confidence)的度量来衡量规则的关联程度,它们分别是:
a) Lift : P(A,B)/(P(A)P(B)) Lift=1时表示A和B独立。这个数越大(>),越表明A和B存在于一个购物篮中不是偶然现象,有较强的关联度.
b) Leverage :P(A,B)-P(A)P(B)Leverage=0时A和B独立,Leverage越大A和B的关系越密切
c) Conviction:P(A)P(!B)/P(A,!B) (!B表示B没有发生) Conviction也是用来衡量A和B的独立性。从它和lift的关系(对B取反,代入Lift公式后求倒数)可以看出,这个值越大, A、B越关联。
. minMtric 度量的最小值。
. numRules 要发现的规则数。
. outputItemSets 如果设置为真,会在结果中输出项集。
. removeAllMissingCols 移除全部为缺省值的列。 . significanceLevel 重要程度。重要性测试(仅用于置信度)。 . upperBoundMinSupport 最小支持度上界。 从这个值开始迭代减小最小支持度。 . verbose 如果设置为真,则算法会以冗余模式运行。
设置好参数后点击start运行可以看到Apriori的运行结果: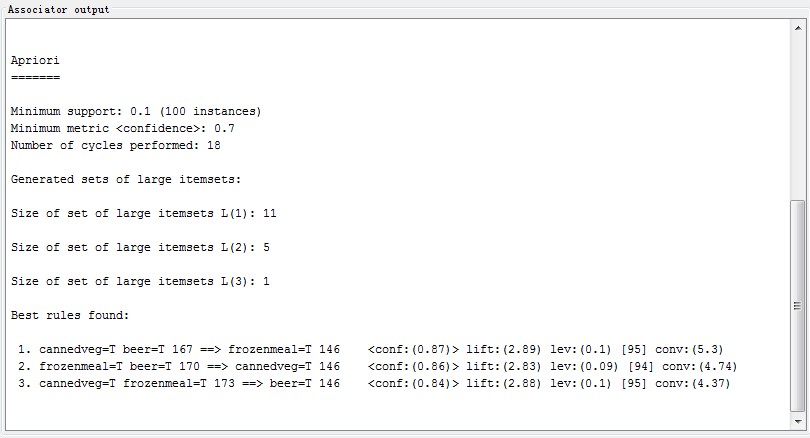
FPGrowth运行的结果是一样的:
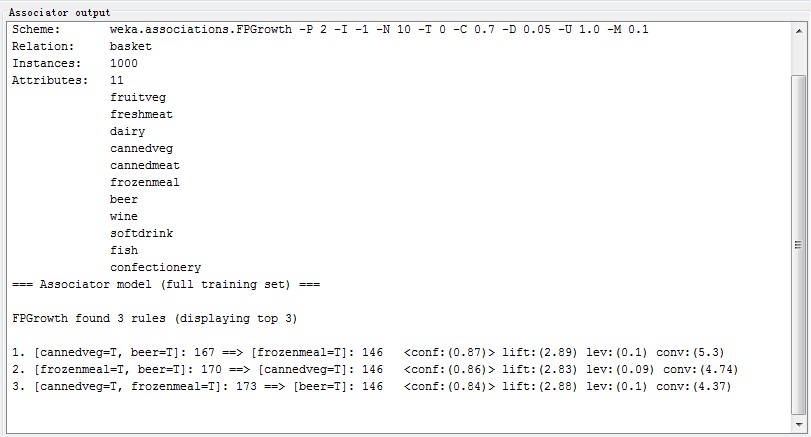
每条规则都带有出现次数、自信度、相关度等数值。
下面测一个大一点的数据集retail.arff[1](retail.arff是由retail.txt转化而来,为了不造成误解,我在id好前加了一个"I",比如2变为I2),这个数据用的稀疏数据表示方法,数据记录有88162条,用Apriori算法在我的2G电脑上跑不出来,直接内存100%,用FPGrowth可以轻松求出,看一下运行结果:
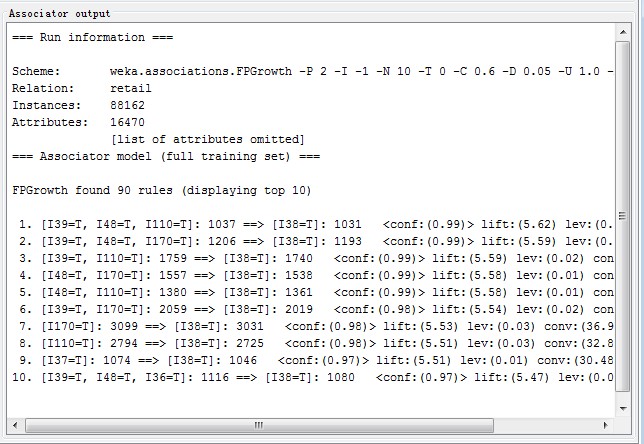
其他参数可以自己调整比较。
参考文献:
[1].本文用的所有数据集basket.txt,basket.arff,normalBasket.arff,retail.txt,retail.arff都在这里可下载.
[2].weka Apriori算法实例操作详解:http://blog.csdn.net/haosijia929/article/details/5596939
感谢阅读,欢迎回帖交流
转置请注明出处:www.cnblogs.com/fengfenggirl
数据挖掘系列(4)使用weka做关联规则挖掘的更多相关文章
- 数据挖掘系列(5)使用mahout做海量数据关联规则挖掘
上一篇介绍了用开源数据挖掘软件weka做关联规则挖掘,weka方便实用,但不能处理大数据集,因为内存放不下,给它再多的时间也是无用,因此需要进行分布式计算,mahout是一个基于hadoop的分布式数 ...
- 数据挖掘系列 (1) 关联规则挖掘基本概念与 Aprior 算法
转自:http://www.cnblogs.com/fengfenggirl/p/associate_apriori.html 数据挖掘系列 (1) 关联规则挖掘基本概念与 Aprior 算法 我计划 ...
- 数据挖掘系列(1)关联规则挖掘基本概念与Aprior算法
整理数据挖掘的基本概念和算法,包括关联规则挖掘.分类.聚类的常用算法,敬请期待.今天讲的是关联规则挖掘的最基本的知识. 关联规则挖掘在电商.零售.大气物理.生物医学已经有了广泛的应用,本篇文章将介绍一 ...
- 大数据挖掘: FPGrowth初识--进行商品关联规则挖掘
@(hadoop)[Spark, MLlib, 数据挖掘, 关联规则, 算法] [TOC] 〇.简介 经典的关联规则挖掘算法包括Apriori算法和FP-growth算法.Apriori算法多次扫描交 ...
- 数据挖掘算法之-关联规则挖掘(Association Rule)
在数据挖掘的知识模式中,关联规则模式是比较重要的一种.关联规则的概念由Agrawal.Imielinski.Swami 提出,是数据中一种简单但很实用的规则.关联规则模式属于描述型模式,发现关联规则的 ...
- 数据挖掘算法之关联规则挖掘(一)apriori算法
关联规则挖掘算法在生活中的应用处处可见,几乎在各个电子商务网站上都可以看到其应用 举个简单的例子 如当当网,在你浏览一本书的时候,可以在页面中看到一些套餐推荐,本书+有关系的书1+有关系的书2+... ...
- 数据挖掘算法之-关联规则挖掘(Association Rule)(购物篮分析)
在各种数据挖掘算法中,关联规则挖掘算是比較重要的一种,尤其是受购物篮分析的影响,关联规则被应用到非常多实际业务中,本文对关联规则挖掘做一个小的总结. 首先,和聚类算法一样,关联规则挖掘属于无监督学习方 ...
- 数据挖掘系列(2)--关联规则FpGrowth算法
上一篇介绍了关联规则挖掘的一些基本概念和经典的Apriori算法,Aprori算法利用频繁集的两个特性,过滤了很多无关的集合,效率提高不少,但是我们发现Apriori算法是一个候选消除算法,每一次消除 ...
- 数据挖掘进阶之关联规则挖掘FP-Growth算法
数据挖掘进阶之关联规则挖掘FP-Growth算法 绪 近期在写论文方面涉及到了数据挖掘,需要通过数据挖掘方法实现软件与用户间交互模式的获取.分析与分类研究.主要涉及到关联规则与序列模式挖掘两块.关联规 ...
随机推荐
- SIEBEL应用概述
Siebel CRM是围绕客户关系管理这个主题建立起来的一系列应用的总和,和一些国内公司的CRM/CALL CENTER产品不一样,Siebel应用远远不是只是接一些电话然后记录下来并进行处理这么简单 ...
- Hadoop从伪分布式到真正的分布式
对这两天学习hadoop的一个总结,概念就不提了.直接说部署的事,关于如何部署hadoop网上的资料很多, 比较经典的还是Tim在IBM developworks上的系列文章 http://www.i ...
- 在SQL2008R2查询分析器出错(在执行批处理时出现错误。错误消息为: 目录名称无效。)
在用SQL2008R2查询分析器时 SELECT * FROM 表名; 出错: 在执行批处理时出现错误.错误消息为: 目录名称无效. 原因: 在打开查询分析器时,用360软件清空了临时文件(只是偶尔1 ...
- Solr5.0源码分析-SolrDispatchFilter
年初,公司开发法律行业的搜索引擎.当时,我作为整个系统的核心成员,选择solr,并在solr根据我们的要求做了相应的二次开发.但是,对solr的还没有进行认真仔细的研究.最近,事情比较清闲,翻翻sol ...
- centos7 新手基本命令
1. yum update 安装系统后,更新yum到最新版本 提示错误 :cannot find a valid baseurl for repo: base/7/x86_64 解决:修改/etc/s ...
- 最完整PHP.INI中文版
;;;;;;;;;;;;;;;;;;; 关于php.ini ;;;;;;;;;;;;;;;;;;;; 这个文件必须命名为'php.ini'并放置在httpd.conf中PHPINIDir指令指定的目录 ...
- 烂泥:KVM中安装Windows Server 2008 R2系统
本文由秀依林枫提供友情赞助,首发于烂泥行天下. 在前一篇文章中,我介绍了有关在KVM中的安装Centos系统.接下来,就来介绍如何在KVM中安装Windows系统. 注意:在此我安装的是windows ...
- Azure 自动化里添加ResourceManager模块
最近想尝试通过Azure里的自动化功能来控制VM的定时开关机,找到网上的一篇文章, 按照文章操作到"Import Azure Resource manager module"的第 ...
- Hadoop Resource
http://www.aiopass4sure.com/cloudera-exams/ccd-410-exam-questions/which-process-describes-the-lifecy ...
- A + B Problem II
之前总是在查阅别人的文档,看着其他人的博客,自己心里总有一份冲动,想记录一下自己学习的经历.学习算法有一段时间了,于是想从算法开始自己的博客生涯O(∩_∩)O~~ 今天在网上看了一道大数相加(高精度) ...