还是关于编码——decode & encode的探究
最近被py3.4中的编码折磨的不要不要的,decode & encode的使用、功能貌似在2.7—3.0有一个巨大的变化。网上查询的一些解答很多是基于2.7中的unicode功能,给出的解答是下面:
| decode(解码)的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串转换成unicode编码。 |
| encode(编码)的作用是将unicode编码转换成其他编码的字符串,如str2.encode('gb2312'),表示将unicode编码的字符串转换成gb2312编码。 |
但自己实践起来完全不是那样,可以说错误百出。最基本的:decode & encode不在是”unicode→其他编码的解码、编码”过程,而是Str→bytes的解码、编码。在这里,还要对Str和bytes做本质性的深入探究
(以下资料都是网上查到的,问题很多,最主要的是不成体系,有些人这样理解,有些人那样理解,也许他们都能成熟使用py3.4编码,但对初学者就很不友好了,很多名词的定义和解释也不一致,我只能尽自己努力去整合)
|
<此段文字时间是2009,应该是基于py2.0>
字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码。 encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode('gb2312'),表示将unicode编码的字符串str2转换成gb2312编码。 因此,转码的时候一定要先搞明白,字符串str是什么编码,然后decode成unicode,然后再encode成其他编码 代码中字符串的默认编码与代码文件本身的编码一致。 如:s='中文' 如果是在utf8的文件中,该字符串就是utf8编码,如果是在gb2312的文件中,则其编码为gb2312。这种情况下,要进行编码转换,都需要先用decode方法将其转换成unicode编码,再使用encode方法将其转换成其他编码。通常,在没有指定特定的编码方式时,都是使用的系统默认编码创建的代码文件。 如果字符串是这样定义:s=u'中文' 则该字符串的编码就被指定为unicode了,即python的内部编码,而与代码文件本身的编码无关。因此,对于这种情况做编码转换,只需要直接使用encode方法将其转换成指定编码即可。 如果一个字符串已经是unicode了,再进行解码则将出错,因此通常要对其编码方式是否为unicode进行判断: isinstance(s, unicode) #用来判断是否为unicode 用非unicode编码形式的str来encode会报错 |
以上文字可以说已经完全被py3.0抛弃了,我是从3.0入手的,那么怎么办呢? 功夫不负有心人,终于在某论坛里找到了类似问题。
1 #python 3中只有unicode str,所以把decode方法去掉了。已经是unicode的str,不用decode。如果文件内容不是unicode编码的,要先以二进制方式打开,读入比特流,再解码码。 |
.#python语言中有两种不同的字符串,一个用于存储文本,一个用于存储原始字节。 文本字符串内部使用Unicode存储,字节字符串存储原始字节并显示ASCII。(无法显示为ASCII字符的字节,用\x##显示。) |
python3中,文本型字符串类型 被命名为 str,字节字符串类型 被命名为 bytes。 正常情况下,实例化一个字符串会得到一个str实例,如果希望得到一个bytes实例,需要在文本之前添加b字符。 |
| 全文 http://www.jianshu.com/p/4f0e65bee38b 作者:wwlovett 链接:http://www.jianshu.com/p/4f0e65bee38b 來源:简书 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 |
>>> s='hello,world'
>>> s
'hello,world'
>>> type(s)
<class 'str'>
>>> h=b'hello,world'
>>> type(h)
<class 'bytes'>
3.#文本总是unicode字符集,用str类型表示。二进制数据则由bytes表示。(通过socket在网络上传输数据时必须要用二进制格式)Python不会以任何隐式的方式混用str和bytes,所以我们不能在代码中拼接字符串和字节包当然字符串和字节,是可以被相互转换的。借用一个图来说明转换关系: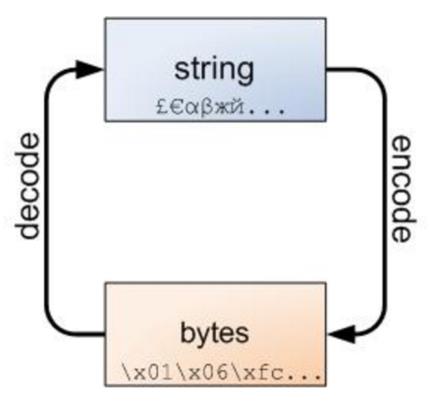 |
#encode 用来对str(文本字符串)格式的数据进行编码:
1 >>> s='你好'
>>> s.encode() #不指定目的格式,则默认'utf-8'
b'\xe4\xbd\xa0\xe5\xa5\xbd'
>>> s.encode('utf-8') #验证下,果然默认和设定为'utf-8'是一致的输出格式
b'\xe4\xbd\xa0\xe5\xa5\xbd'
decode 用来对bytes格式的数据进行解码:
>>> s=b'\xe4\xbd\xa0\xe5\xa5\xbd'
>>> s.decode('utf-8') #表示把二进制字节字符串解释成 什么格式的数据(默认UTF-8)
'你好'
数据处于 网络传输 或 磁盘存储状态下,必须以'二进制字节字符串'(即'字节流')形式存在,即b'\x_ _\x_ _\x_ _\x_ _'
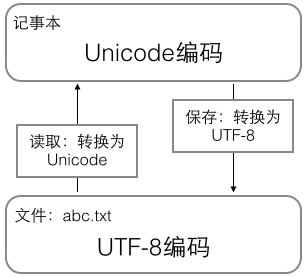
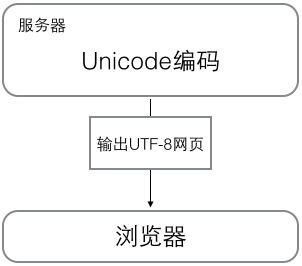
A.在计算机内存中,统一使用Unicode编码(str),当需要保存到硬盘或者 B. 浏览网页的时候,服务器会把动态生成的Unicode内容(str)转
需要传输(bytes)的时候,就转换为UTF-8编码。 换为UTF-8(bytes)再传输到浏览器:
4#读取文件 python3:文件总是存储字节,因此,为了使用文件中读取的文本数据,必须首先将其解码为一个文本字符串。 python3中,文本正常情况下会自动为你解码,所以打开或读取文件会得到一个文本字符串。 使用的解码方式取决系统,在mac os 或者 大多数linux系统中,首选编码是utf-8,但windows不一定。 可以使用locale.getpreferredencoding()方法得到系统的默认解码方式。 |
#Python3 把系统默认编码设置为 UTF-8
>>> import sys
>>> sys.getdefaultencoding()
'utf-8'
自己找个例子验证下是否已经掌握
>>> '深蓝'
'深蓝'
>>> type('深蓝')
<class 'str'> #随意输入的数据在python内部已经被默认为 ‘文本字符串’=str,此时的str为 unicode类无编码数据 >>> '深蓝'.decode('utf-8') #傻傻的试下,果然str是无法被解码的(人家已经是unicode了,还解什么?解码的目的就是变成unicode嘛),程序报错了<str无法使用decode函数功能>
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'str' object has no attribute 'decode' >>> '深蓝'.encode('utf-8') #看看能编码否
b'\xe6\xb7\xb1\xe8\x93\x9d' #OK,str被顺利用utf-8规则编码为 字节字符串了(此时的数据可以被网络传输或存入硬盘了,它已处于从python出口待output状态了)
>>> type('深蓝'.encode('utf-8'))
<class 'bytes'> #不放心验证下,数据确是bytes了 >>> print('深蓝'.encode('utf-8').decode('utf-8')) #想要再次的得到数据的'文本字符串'形式,必须再次解码(decode)
深蓝
python如何判断对象是否为字符串或者其他类型?
>>> a=10
>>> b='中华'
>>> print(isinstance(a,int))
True
>>> print(isinstance(b,str))
True
>>> print(isinstance(a,str))
False
>>> print(isinstance(b,float))
False
>>> print(isinstance('中华',str))
True
避免乱码,坚持几点:
1、坚持使用UTF-8编码对str和bytes进行转换。
2、源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。
3、当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3 < 告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略 >
# -*- coding: utf-8 -*- < 告诉Python解释器,按照UTF-8编码读取源代码 >
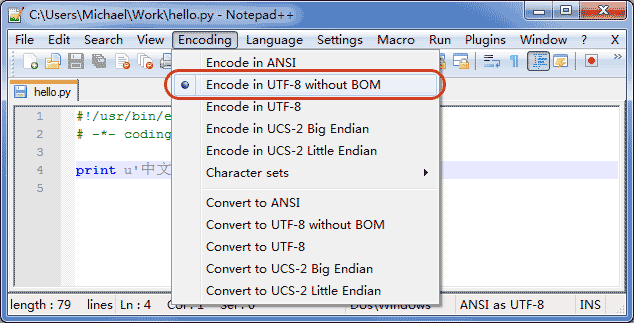
4、确保文本编辑器正在使用<UTF-8 without BOM>编码
由于一直在看廖雪峰老师的教程学习py,但他讲的稍显简略,属于提纲挈领的体会型教程。而我个人学东西特喜欢刨根问底,而且喜欢发散思维,喜欢以点带面,但缺点也很明显——对于暂时搞不懂的难点,很难跨过去继续学习后面内容,导致遇到问题就卡壳。
例如遇到了py编码问题,我就想深入的把编码类问题一次性全部弄通,虽然有朋友告诫我,初学应该抓大放小 、注重体验,有些难点可以后补或者学完再思考,这次编码问题我困惑了足足2天,起码10个小时。后来我知道了是由于py2.0-3.0阶段的版本大更新问题导致语法结构的巨变,使得我浪费了太多时间。以后不会了,决定采用朋友的告诫,先弄通一个流程,建立起基本框架再补全各类问题。
PS:编码问题太痛苦了,好了好了,赶紧翻篇~~
还是关于编码——decode & encode的探究的更多相关文章
- 编码 decode & encode
import sys # python3 中字符编码默认为 utf-8 s = '你好' print(s) # utf-8 转为 gbk (s 默认为 unicode 所以可以直接 encode 成 ...
- Python编码介绍——encode和decode
在 python 源代码文件中,如果你有用到非ASCII字符,则需要在文件头部进行字符编码的声明,声明如下: # code: UTF-8 因为python 只检查 #.coding 和编码字符串,所以 ...
- Python编码decode和encode
常见编码介绍: GB2312编码:适用于汉字处理.汉字通信等系统之间的信息交换;GBK编码:是汉字编码标准之一,是在 GB2312-80 标准基础上的内码扩展规范,使用了双字节编码ASCII编码:是对 ...
- unicode可以通过编码(encode)成为特定编码的str
1.原始字符串python中的原始字符串以r开头,使用原始字符串可以避免字符串中转义字符带来的问题,例如写路径时 path = 'c:\noway',此时用 print path,其结果为:c:owa ...
- x264源代码简单分析:宏块编码(Encode)部分
===================================================== H.264源代码分析文章列表: [编码 - x264] x264源代码简单分析:概述 x26 ...
- python 小数据池,is and "==",decode ,encode
一:小数据池 1.python运行中的缓存: 2.目的:缓存我们字符串,整数,布尔值.在使用的时候不需要创建过多的对象 3.python 缓存数据:缓存:int, str, bool. ...
- mysql decode encode 乱码问题
帮网友解决了一个问题,感觉还是挺好的. 问题是这样的: 问个问题:为什么我mysql中加密和解密出来的字段值不一样?AES_ENCRYPT和 AES_DECRYPT 但是解密出来就不对了 有时候 ...
- x264代码剖析(三):主函数main()、解析函数parse()与编码函数encode()
x264代码剖析(三):主函数main().解析函数parse()与编码函数encode() x264的入口函数为main().main()函数首先调用parse()解析输入的參数,然后调用encod ...
- Python3 关于UnicodeDecodeError/UnicodeEncodeError: ‘gbk’ codec can’t decode/encode bytes类似的文本编码问题
以下是小白的爬虫学习历程中遇到并解决的一些困难,希望写出来给后来人,如有疏漏恳请大牛指正,不胜感谢! 首先,我的代码是这样的 import requests url = 'http://www.acf ...
随机推荐
- Gulp安装及使用
測试环境 Mac:10.10.4 Gulp:3.9.0 时间:2015年08月15日18:07:08 安装Gulp sudo npm install --global gulp npm install ...
- spring test---restful与文件上传
spring提供了大量经常使用的功能測试,如文件上传.restful风格url訪问.以下介绍主要介绍下test中经常使用功能的使用方法: 首先能够静态导入类.方便在測试类中使用,导入的类有 impor ...
- ASP.NET MVC不可或缺的部分——DI(IOC)容器及控制器重构的剖析
ASP.NET MVC不可或缺的部分——DI(IOC)容器及控制器重构的剖析 IoC框架最本质的东西:反射或者EMIT来实例化对象.然后我们可以加上缓存,或者一些策略来控制对象的生命周期,比如是否 ...
- 剑指offer面试题18-树的子结构
题目: 输入两颗二叉树A和B,推断B是不是A的子结构. 树的结构例如以下: package com.aii.algorithm; public class TreeNode { int value; ...
- Spark技术内幕:Master基于ZooKeeper的High Availability(HA)源代码实现
假设Spark的部署方式选择Standalone,一个採用Master/Slaves的典型架构,那么Master是有SPOF(单点故障,Single Point of Failure).Spark能够 ...
- 万一的Delphi消息教程
http://www.cnblogs.com/del/category/134064.html
- 脱离开发软件启动Tomcat访问项目
作为开发人员平时用的最多的就是通过开发软件启动Tomcat服务,从而访问项目.这样便于开发的bug调试 此处讲的是脱离开发软件启动Tomcat访问项目 链接参考: http://jingyan.bai ...
- Ubuntu 14.04 台式机锐捷使用:
1.解压文件:RG_Supplicant_For_Linux_V1.31.zip2.sudo chmod -R 777 rjsupplicant3.进入文件夹(./rjsupplicant.sh -a ...
- C#面向过程之编译原理、变量、运算符
.net基础:.net与C# .net是一个平台 c#是一门语言 .net的用途a.桌面应用程序 b.网站应用程序 c.专业游戏开发(XBOX360) d.嵌入式设备软件开发 e.智能手机APP开发 ...
- Maven之项目搭建与第一个helloworld(多图)
这次记录第一个搭建一个maven的helloworld的过程. 转载 1.搭建web工程肯定得new 一个 maven工程,假如project中没有直接看到maven工程,那么选择Other,然后在W ...