Snowflake算法 ID生成
Snowflake算法 ID生成
http://blog.csdn.net/w200221626/article/details/52064976
使用UUID或者GUID产生的ID没有规则
Snowflake算法是Twitter的工程师为实现递增而不重复的ID实现的
从图上看除了第一位不可用之外其它三组均可浮动站位,据说前41位就可以支撑到2088年,10位的可支持1023台机器,最后12位序列号可以在1毫秒内产生4095个自增的ID。
数据中主键有多种方式:数据库自增、程序生成。程序生成一般采用的是snowflake 算法。这个算法在网上有很多解释,这里就不做过多的解释。
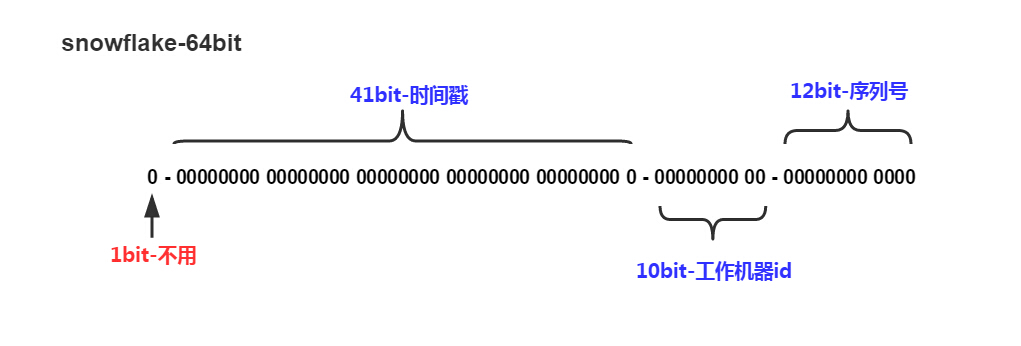
生成的id大致有以下组成:
Snowflake算法一般生成的每一个ID都是64位的整型数,它的核心算法也比较简单高效,结构如下:
41位的时间序列,精确到毫秒级,41位的长度可以使用69年。时间位还有一个很重要的作用是可以根据时间进行排序。
5位的数据中心标识,5位的长度最多支持部署32个节点。
5位的机器标识,8位的长度最多支持部署255个节点。
12位的计数序列号,序列号即一系列的自增id,可以支持同一节点同一毫秒生成多个ID序号,12位的计数序列号支持每个节点每毫秒产生4095个ID序号。
最高位是符号位,始终为0,不可用。
根据生成规则和实际代码:
(有关算法详解:https://segmentfault.com/a/1190000011282426#articleHeader2)
在多线程中使用要加锁。
C# 实现 Snowflake算法

/// <summary>
/// 动态生产有规律的ID Snowflake算法是Twitter的工程师为实现递增而不重复的ID实现的
/// http://blog.csdn.net/w200221626/article/details/52064976
/// C# 实现 Snowflake算法
/// </summary>
public class Snowflake
{
private static long machineId;//机器ID
private static long datacenterId = 0L;//数据ID
private static long sequence = 0L;//计数从零开始
private static long twepoch = 687888001020L; //唯一时间随机量
private static long machineIdBits = 5L; //机器码字节数
private static long datacenterIdBits = 5L;//数据字节数
public static long maxMachineId = -1L ^ -1L << (int)machineIdBits; //最大机器ID
private static long maxDatacenterId = -1L ^ (-1L << (int)datacenterIdBits);//最大数据ID
private static long sequenceBits = 12L; //计数器字节数,12个字节用来保存计数码
private static long machineIdShift = sequenceBits; //机器码数据左移位数,就是后面计数器占用的位数
private static long datacenterIdShift = sequenceBits + machineIdBits;
private static long timestampLeftShift = sequenceBits + machineIdBits + datacenterIdBits; //时间戳左移动位数就是机器码+计数器总字节数+数据字节数
public static long sequenceMask = -1L ^ -1L << (int)sequenceBits; //一微秒内可以产生计数,如果达到该值则等到下一微妙在进行生成
private static long lastTimestamp = -1L;//最后时间戳
private static object syncRoot = new object();//加锁对象
static Snowflake snowflake;
public static Snowflake Instance()
{
if (snowflake == null)
snowflake = new Snowflake();
return snowflake;
}
public Snowflake()
{
Snowflakes(0L, -1);
}
public Snowflake(long machineId)
{
Snowflakes(machineId, -1);
}
public Snowflake(long machineId, long datacenterId)
{
Snowflakes(machineId, datacenterId);
}
private void Snowflakes(long machineId, long datacenterId)
{
if (machineId >= 0)
{
if (machineId > maxMachineId)
{
throw new Exception("机器码ID非法");
}
Snowflake.machineId = machineId;
}
if (datacenterId >= 0)
{
if (datacenterId > maxDatacenterId)
{
throw new Exception("数据中心ID非法");
}
Snowflake.datacenterId = datacenterId;
}
}
/// <summary>
/// 生成当前时间戳
/// </summary>
/// <returns>毫秒</returns>
private static long GetTimestamp()
{
//让他2000年开始
return (long)(DateTime.UtcNow - new DateTime(2000, 1, 1, 0, 0, 0, DateTimeKind.Utc)).TotalMilliseconds;
}
/// <summary>
/// 获取下一微秒时间戳
/// </summary>
/// <param name="lastTimestamp"></param>
/// <returns></returns>
private static long GetNextTimestamp(long lastTimestamp)
{
long timestamp = GetTimestamp();
int count = 0;
while (timestamp <= lastTimestamp)//这里获取新的时间,可能会有错,这算法与comb一样对机器时间的要求很严格
{
count++;
if (count > 10)
throw new Exception("机器的时间可能不对");
Thread.Sleep(1);
timestamp = GetTimestamp();
}
return timestamp;
}
/// <summary>
/// 获取长整形的ID
/// </summary>
/// <returns></returns>
public long GetId()
{
lock (syncRoot)
{
long timestamp = GetTimestamp();
if (Snowflake.lastTimestamp == timestamp)
{ //同一微妙中生成ID
sequence = (sequence + 1) & sequenceMask; //用&运算计算该微秒内产生的计数是否已经到达上限
if (sequence == 0)
{
//一微妙内产生的ID计数已达上限,等待下一微妙
timestamp = GetNextTimestamp(Snowflake.lastTimestamp);
}
}
else
{
//不同微秒生成ID
sequence = 0L;
}
if (timestamp < lastTimestamp)
{
throw new Exception("时间戳比上一次生成ID时时间戳还小,故异常");
}
Snowflake.lastTimestamp = timestamp; //把当前时间戳保存为最后生成ID的时间戳
long Id = ((timestamp - twepoch) << (int)timestampLeftShift)
| (datacenterId << (int)datacenterIdShift)
| (machineId << (int)machineIdShift)
| sequence;
return Id;
}
}
}
复制代码
复制代码
[TestClass]
public class SnowflakeUnitTest1
{
/// <summary>
/// 动态生产有规律的ID Snowflake算法是Twitter的工程师为实现递增而不重复的ID实现的
/// </summary>
[TestMethod]
public void SnowflakeTestMethod1()
{
var ids = new List<long>();
for (int i = 0; i < 1000000; i++)//测试同时100W有序ID
{
ids.Add(Snowflake.Instance().GetId());
}
for (int i = 0; i < ids.Count - 1; i++)
{
Assert.IsTrue(ids[i] < ids[i+1]);
}
}
}
namespace ConsoleApplicationTester
{
class Program
{
static void Main(string[] args)
{
for (int i = 0; i < 1000; i++)
{
Console.WriteLine("开始执行 " + DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss:ffffff") + " " + Snowflake.Instance().GetId());
Console.WriteLine("Snowflake.maxMachineId:" + Snowflake.maxMachineId);
}
}
}
}
“雪花”项目:Microsoft探索在.NET中实现手工内存管理
http://www.infoq.com/cn/news/2017/09/snowflake
来自Microsoft研究院、剑桥大学和普林斯顿大学的一些研究人员构建了一个.NET的分支,实现了在运行时中添加支持手工内存管理的API。研究方法的细节及所获得的性能提升发表在名为“Project Snowflake: Non-blocking Safe Manual Memory Management in .NET”(“雪花”项目:非阻塞的、安全的.NET手工内存管理)的论文中。
“雪花“项目意在实现.NET中的手工内存管理,这一改进被认为对一些应用是非常有用。C#、.NET等现代编程语言都采用了垃圾回收机制,使编程人员得以从管理对象的任务中解放出来,这一机制的优点广为人知,涉及提高生产力、改进程序稳定性、内存安全及防止恶意操作等方面。但是垃圾回收机制需要付出一些性能上的代价,尽管这在很多情况下不易被察觉,但是在一些情况下还是存在问题的。“雪花”项目的研究人员就指出,对于在具有上百GB堆内存的系统上运行数据分析和流处理任务,就可受益于手工内存管理。
“雪花”项目所引入的手工内存管理是与垃圾回收机制并行工作的,开发人员一般情况下使用的是垃圾回收机制,但在环境需要时也可以选择手工内存管理。该引入到运行时中的改进并不会对已有应用产生影响,并且会改进多线程应用的性能。“雪花”项目实现了“在程序任一位置分配和释放独立对象,并确保手工管理对象同样享有完全的类型安全和时序安全,即使存在并发访问时。”
“雪花”中提出了两个新概念,即对象“所有者”(Owner)和“护盾”(Shield),它们实现为CoreCLR和CoreFX层级的API。“所有者”表示了栈或堆中的一个位置,保存了对手工堆中分配对象的唯一引用。“所有者”获取自“护盾”,而引入“护盾”是为了避免手工对象在被多个线程访问时重分配(deallocate)。“护盾”确保了当最后使用一个对象的线程重分配该对象后,才从堆中移除该对象。论文中是如下详细阐述该机制的:
我们的解决方案……受到了无锁数据结构研究中的“风险指针”(Hazard Pointer)这一概念的启发。我们引入了一种机制,当线程想要通过其中一个“所有者”位置访问手工对象时,这一意图将会发布在线程本地状态(TLS,Thread-Local State)中。此注册过程可看成是创建了一个“护盾”,该“护盾”将保护对象不会被重分配,并授权发布注册的线程可直接访问对象,例如调用对象的方法,或是转换(mutate)对象的字段。同时,不允许任何线程(同一线程或另一个线程)重分配对象及回收(reclaim)对象的内存。一旦客户代码不再需要访问该对象,就可以释放(dispose)“护盾”,即从对象的TLS中移除了指向该对象的引用。直接访问从“护盾”获取的对象是不安全的操作,因为在释放“护盾”后,实际的重分配操作依然允许继续。
论文中提供了一系列给定场景下的测试结果,表明使用“雪花”项目的性能相比于垃圾回收机制取得了改进。其中,“在峰值工作集上获得了高达三倍的性能提高,在运行时上取得了两倍的性能提高”。测试结果给出了很好的性能改进。这是因为当对象池非常大时,垃圾回收为释放内存需要花费很多时间遍历对象图。
Microsoft并未详述是否有规划在.NET中加入“雪花”项目。但考虑到这是一种非侵入式的和安全的机制,我们希望在.NET的未来版本中能集成类似的功能。
查看英文原文: Microsoft Explores Manual Memory Management in .NET with Snowflake
Snowflake算法 ID生成的更多相关文章
- C# 实现 Snowflake算法 ID生成
http://blog.csdn.net/w200221626/article/details/52064976 C# 实现 Snowflake算法 /// <summary> /// 动 ...
- Twitter的SnowFlake分布式id生成算法
二进制相关知识回顾 1.所有的数据都是以二进制的形式存储在硬盘上.对于一个字节的8位到底是什么类型 计算机是如何分辨的呢? 其实计算机并不负责判断数据类型,数据类型是程序告诉计算机该如何解释内存块. ...
- SnowFlake --- 分布式id生成算法
转载自:https://segmentfault.com/a/1190000011282426 概述 SnowFlake算法生成id的结果是一个64bit大小的整数,它的结构如下图: 1位,不用.二进 ...
- SnowFlake分布式ID生成及反解析
概述 分布式id生成算法的有很多种,Twitter的SnowFlake就是其中经典的一种,SnowFlake算法生成id的结果是一个64bit大小的整数,它的结构如下图: 1位,不用.二进制中最高位为 ...
- twitter的ID生成器的snowFlake算法的自造版
snowFlake算法在生成ID时特别高效,可参考:https://segmentfault.com/a/1190000011282426 SnowFlake算法生成id的结果是一个64bit大小的整 ...
- ID生成算法(一)——雪花算法
JavaScript生成有序GUID或者UUID,这时就想到了雪花算法. 原理介绍: snowFlake算法最终生成ID的结果为一个64bit大小的整数,结构如下图: 解释: 1bit.二进制中最高位 ...
- 架构设计 | 分布式业务系统中,全局ID生成策略
本文源码:GitHub·点这里 || GitEE·点这里 一.全局ID简介 在实际的开发中,几乎所有的业务场景产生的数据,都需要一个唯一ID作为核心标识,用来流程化管理.比如常见的: 订单:order ...
- PHP使用SnowFlake算法生成唯一ID
前言:最近需要做一套CMS系统,由于功能比较单一,而且要求灵活,所以放弃了WP这样的成熟系统,自己做一套相对简单一点的.文章的详情页URL想要做成url伪静态的格式即xxx.html 其中xxx考虑过 ...
- 分布式ID生成系统 UUID与雪花(snowflake)算法
Leaf——美团点评分布式ID生成系统 -https://tech.meituan.com/MT_Leaf.html 网游服务器中的GUID(唯一标识码)实现-基于snowflake算法-云栖社区-阿 ...
随机推荐
- the import org.springframewok.test cannot be resolved
在写Spring的单元测试时遇见了问题,注解@ContextConfiguration和SpringJUnit4ClassRunner.class无法导包.手动导包后错误为“the import or ...
- Maven自动部署(SCM-SVN/Git)(maven-scm-plugin/maven-release-plugin插件的使用)
以下内容引用自https://ayayui.gitbooks.io/tutorialspoint-maven/content/book/maven_deployment_automation.html ...
- android Activity生命周期的例子
package com.example.yanlei.yl2; import android.app.AlertDialog; import android.content.DialogInterfa ...
- 【HDOJ 5399】Too Simple
pid=5399">[HDOJ 5399]Too Simple 函数映射问题 给出m函数 里面有0~m个函数未知(-1) 问要求最后1~n分别相应仍映射1~n 有几种函数写法(已给定的 ...
- EasyDarwin开源手机直播方案:EasyPusher手机直播推送,EasyDarwin流媒体server,EasyPlayer手机播放器
在不断进行EasyDarwin开源流媒体server的功能和性能完好的同一时候,我们也配套实现了眼下在安防和移动互联网行业比較火热的移动端手机直播方案,主要就是我们的 EasyPusher直播推送项目 ...
- Leetcode41: Remove Duplicates from Sorted List
Given a sorted linked list, delete all duplicates such that each element appear only once. For examp ...
- POJ - 1062 昂贵的聘礼(最短路Dijkstra)
昂贵的聘礼 Time Limit: 1000MS Memory Limit: 10000KB 64bit IO Format: %I64d & %I64u SubmitStatus Descr ...
- CPU Stepping
http://baike.baidu.com/view/16839.htm?fr=ala0_1_1 步进 编辑 步进(Stepping)是CPU的一个重要参数,也叫分级鉴别产品数据转换规范,“步进 ...
- webRequest模块的解读
Chrome Extension 的 webRequest模块的解读 文档在此:http://developer.chrome.com/trunk/extensions/webRequest.ht ...
- OpenStack源码系列---起始篇
近一年来我负责公司云点的自动化部署工作,包括公司自有云平台方案.XenServer.vSphere.Ovirt和OpenStack的自动化安装部署,目前已经到了OpenStack这一部分.自动化部署首 ...