第一个get请求的爬虫程序
一:urllib库:
- urllib是Python自带的一个用于爬虫的库,器主要作用就是可以通过代码模拟浏览器发送请求.其被用到子模块在Python3中的urllib.request和urllib.parse,在Python2中是urllib和urllib2.
二,有易到难的爬虫程序:
- 爬取到百度页面所有的数据值
import urllib.request
import urllib.parse
if __name__ == '__main__':
# 指定爬取的网页url
url = "http://www.baidu.com"
# 通过urlopen含少数向指定的url发送请求,返回响应对象
response = urllib.request.urlopen(url=url)
# 通过调用响应对象中的read函数,返回响应客户端的数据值(爬取到的数据)
# data = response.read() # 返回的是byte类型,并非字符串
print(response) # <http.client.HTTPResponse object at 0x0000015ACAC57E80>
print(response.headers)
print(response.getcode()) # 200
print(response.geturl()) # http://www.baidu.com
# 补充说明
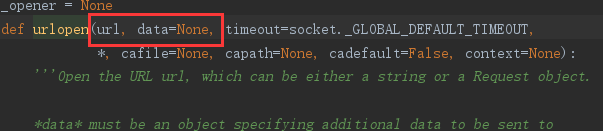
urlopen函数的原型:urllib.request.urlopen(),具体参数见下图
url参数:指定向那个url发起请求
data参数:可以将post请求中携带的参数封装成字典的形式传递给该参数
urlopen函数的响应对象,相关函数的调用介绍
response.headers: 获取响应头信息
response.getcode(): 获取响应状态码
response.geturl(): 获取请求的url
response.read(): 获取响应的数据(字节类型)
- 将爬取到的百度新闻首页的数据值写入文件进行存储
# -*- coding:utf-8 -*-
from urllib import request
import urllib.parse
if __name__ == '__main__':
url = "https://news.baidu.com/"
response = request.urlopen(url=url)
# decode()作用是是将响应中的字节(byte)类型的数据值转化成字符串类型
data = response.read().decode()
# 使用IO操作将data表示的数据值以"w"权限的方式写入到news.html
with open("./news.html","w") as fp:
fp.write(data)
print("写入完毕!!!") # 写出的文字不识别,是乱码!!!,编码有问题, 在文件开头申明的编码也不好使
- 爬取网络上某张图片数据u,存储到本地
#爬取网络上的图片
from urllib import request
# 下边这两行代码表示忽略https证书,因为下面请求的url为https协议的请求,如果请求不是https则该两行代码可不用 .
import ssl
ssl._create_default_https_context = ssl._create_unverified_context if __name__ == '__main__':
# url 是存放https协议的
url = "https://image.baidu.com/search/detail?ct=503316480&z=0&ipn=false&word=%E5%AE%8B%E6%85%A7%E4%B9%94&step_word=&hs=2&pn=20&spn=0&di=195362068990&pi=0&rn=1&tn=baiduimagedetail&is=0%2C0&istype=0&ie=utf-8&oe=utf-8&in=&cl=2&lm=-1&st=undefined&cs=2995972207%2C2611875489&os=366366976%2C3885463767&simid=3393796370%2C191512008&adpicid=0&lpn=0&ln=3750&fr=&fmq=1548471365943_R&fm=&ic=undefined&s=undefined&hd=undefined&latest=undefined©right=undefined&se=&sme=&tab=0&width=undefined&height=undefined&face=undefined&ist=&jit=&cg=star&bdtype=0&oriquery=&objurl=http%3A%2F%2Fpic.makepolo.net%2Fnews%2Fallimg%2F20161225%2F1482604638984064.jpg&fromurl=ippr_z2C%24qAzdH3FAzdH3Fgjof_z%26e3B4whjr5s5_z%26e3Bv54AzdH3Fmlcblld_z%26e3Bip4s&gsm=0&rpstart=0&rpnum=0&islist=&querylist=&force=undefined"
response = request.urlopen(url=url)
data = response.read() # 因为图片的数据值(二进制数据),则无需使用decode进行类型转换
# 存储到本地
with open("./xf.jpg", "wb") as fp:
fp.write(data)
print("写入完毕!!!")
三,url的特性:url必须为ASCII编码的数据值.所以我们在爬虫代码中编写url的时候,如果url中存在ASCII编码的数据值,则必须对其进行ASCII编码后,该url方可被使用
from urllib import request
from urllib import parse
if __name__ == '__main__':
# 原始url中存在ASCII编码的值,则该url无法被使用
# url = "http://www.baidu.com/s?ie=utf-8&kw=周杰伦"
# 处理url中存在的非ASCII数据值
url = "https://www.baidu.com/s?"
# 将带有非ASCII的数据封装到字典中,url中非ASCII的数据往往都是"?"后面键值参数的请求
param = {
"ie": "utf-8",
"wd": "周杰伦",
}
# 使用parse子模块中的urlencode函数将封装好的字典中存在的非ASCII的数值进行ASCII编码
param = parse.urlencode(param)
# 将编码后的数据和url进行整合拼接成一个完整可用的url
url = url + param
print(url)
# https://www.baidu.com/s?ie=utf-8&wd=%E5%91%A8%E6%9D%B0%E4%BC%A6
response = request.urlopen(url=url)
data = response.read()
with open("./周杰伦.html", "wb") as fp:
fp.write(data)
print("写入完毕!!!")
五,通过自定义请求对象,用于伪装爬虫程序请求的身份
在请求头信息中有User-Agent参数,简称UA,该参数的作用是用于表名本次请求载体的身份表示.乳沟我们通过浏览器发起请求,则该请求的载体wi当前浏览器,则UA参数的值表名是当前浏览器的一种标识表示宜春数据,如果我们用爬虫程序发起一个请求,则该请求的载体为爬虫程序,那么该请求的UA爬虫程序的身份标识表示一串数据.有些网站会通过辨别请求的UA来判断请求载体是否为爬虫程序,如果为爬虫程序,则不会给该请求返回响应值,那么我们的爬虫程序无法通过发起请求爬取到该网站的数据,这也是反爬虫的一种初级手段.那么为了防止该问题的出现.则我们可以给爬虫程序的UA进行伪装,伪装成某款浏览器的身份标识
import urllib.request
import urllib.parse import ssl
ssl._create_default_https_context = ssl._create_unverified_context if __name__ == "__main__":
#原始url中存在非ASCII编码的值,则该url无法被使用。
#url = 'http://www.baidu.com/s?ie=utf-8&kw=周杰伦'
#处理url中存在的非ASCII数据值
url = 'http://www.baidu.com/s?'
#将带有非ASCII的数据封装到字典中,url中非ASCII的数据往往都是'?'后面键值形式的请求参数
param = {
'ie':'utf-8',
'wd':'周杰伦'
}
#使用parse子模块中的urlencode函数将封装好的字典中存在的非ASCII的数值进行ASCII编码
param = urllib.parse.urlencode(param)
#将编码后的数据和url进行整合拼接成一个完整可用的url
url = url + param
#将浏览器的UA数据获取,封装到一个字典中。该UA值可以通过抓包工具或者浏览器自带的开发者工具中获取某请求,从中获取UA的值
headers={
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
#自定义一个请求对象
#参数:url为请求的url。headers为UA的值。data为post请求的请求参数(后面讲)
request = urllib.request.Request(url=url,headers=headers) #发送我们自定义的请求(该请求的UA已经进行了伪装)
response = urllib.request.urlopen(request) data=response.read() with open('./周杰伦.html','wb') as fp:
fp.write(data)
print('写入数据完毕')
第一个get请求的爬虫程序的更多相关文章
- 一个简单的python爬虫程序
python|网络爬虫 概述 这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识. 什么是网络爬虫 简单的讲,网络爬虫就是模拟人访问web ...
- 一个简单的C#爬虫程序
这篇这篇文章主要是展示了一个C#语言如何抓取网站中的图片.实现原理就是基于http请求.C#给我们提供了HttpWebRequest和WebClient两个对象,方便发送请求获取数据,下面看如何实 1 ...
- Android网络爬虫程序(基于Jsoup)
摘要:基于 Jsoup 实现一个 Android 的网络爬虫程序,抓取网页的内容并显示出来.写这个程序的主要目的是抓取海投网的宣讲会信息(公司.时间.地点)并在移动端显示,这样就可以随时随地的浏览在学 ...
- C语言Linix服务器网络爬虫项目(二)项目设计和通过一个http请求抓取网页的简单实现
我们通过上一篇了解了爬虫具体要实现的工作之后,我们分析得出的网络爬虫的基本工作流程如下: 1.首先选取一部分精心挑选的种子URL: 2.将这些URL放入待抓取URL队列: 3.从待抓取URL队列中取出 ...
- 爬虫浅谈一:一个简单c#爬虫程序
这篇文章只是简单展示一个基于HTTP请求如何抓取数据的文章,如觉得简单的朋友,后续我们再慢慢深入研究探讨. 图1: 如图1,我们工作过程中,无论平台网站还是企业官网,总少不了新闻展示.如某天产品经理跟 ...
- 【云开发】10分钟零基础学会做一个快递查询微信小程序,快速掌握微信小程序开发技能(轮播图、API请求)
大家好,我叫小秃僧 这次分享的是10分钟零基础学会做一个快递查询微信小程序,快速掌握开发微信小程序技能. 这篇文章偏基础,特别适合还没有开发过微信小程序的童鞋,一些概念和逻辑我会讲细一点,尽可能用图说 ...
- 第一个python爬虫程序
1.安装Python环境 官网https://www.python.org/下载与操作系统匹配的安装程序,安装并配置环境变量 2.IntelliJ Idea安装Python插件 我用的idea,在工具 ...
- 开发记录_自学Python写爬虫程序爬取csdn个人博客信息
每天刷开csdn的博客,看到一整个页面,其实对我而言,我只想看看访问量有没有上涨而已... 于是萌生了一个想法: 想写一个爬虫程序把csdn博客上边的访问量和评论数都爬下来. 打算通过网络各种搜集资料 ...
- Scrapy框架-爬虫程序相关属性和方法汇总
一.爬虫项目类相关属性 name:爬虫任务的名称 allowed_domains:允许访问的网站 start_urls: 如果没有指定url,就从该列表中读取url来生成第一个请求 custom_se ...
随机推荐
- Linux组和提权
目 录 第1章 组命名管理** 1 1.1 group组信息和密码信息 1 1.1.1 /etc/group 组账户信息 1 1.1.2 /etc/gshadow 组密码信息 ...
- htmlpurifier的使用
什么是htmlpurifier?? HTML Purifier是一个可以用来移除所有恶意代码(XSS),而且还能确保你的页面遵循W3C的标准规范的PHP类库. 在php里解决XSS最简单的方法是使用h ...
- django的基本操作流程
pip install django cd Desktop/课上代码02/ #进入到创建项目的目录 django-admin startproject 项目的名称 #创建项目 __ini ...
- PCB线宽与电流计算器--在线计算
http://eda365.com/article-12-1.html 计算线宽与载流量的关系,方便设计:单个人建议在有限的空间尽量将大电流线路加宽.
- Oracle获取最近执行的SQL语句
注意:不是每次执行的语句都会记录(如果执行的语句是能在该表找到的则ORACLE不会再次记录,就是说本次执行的语句和上次或者说以前的语句一模一样则下面语句就查不出来的): select last_loa ...
- Spring核心技术(九)——Spring管理的组件和Classpath扫描
Spring管理的组件和Classpath的扫描 在前文描述中使用到的Spring中的Bean的定义,都是通过指定的XML来配置的.而前文中描述的注解的解析则是在源代码级别来提供配置元数据的.在那些例 ...
- xtu summer individual 2 E - Double Profiles
Double Profiles Time Limit: 3000ms Memory Limit: 262144KB This problem will be judged on CodeForces. ...
- hdu 1564水题Play a game
#include<stdio.h> int main() { int n; while(scanf("%d",&n),n) { n=n*n-1; i ...
- 亚瑟王(bzoj 4008)
Description 小 K 不慎被 LL 邪教洗脑了,洗脑程度深到他甚至想要从亚瑟王邪教中脱坑. 他决定,在脱坑之前,最后再来打一盘亚瑟王.既然是最后一战,就一定要打得漂 亮.众所周知,亚瑟王是一 ...
- 《effective C++》:条款36——绝不重新定义继承而来的非虚函数
(1)当派生类中重写了基类的非虚函数时,这个时候这个函数发生的是静态绑定 下面中的代码中: 定义一个基类B,基类定义了函数fcm,fcm是非虚的函数. 定义一个派生类D,派生类重新定义了fcm. 当用 ...