MySql分析算法作品索引(马上,只是说说而已B-tree)
刚开始学习的时候,百度搜索。但我发现很难理解了很多的太复杂,各种物品的整合总结(建议可能看到的文字,我不明白也没关系,再看看操作步骤图,然后结合文,所以,一切都清楚了很多)
B-tree。B这是balance。一般用于数据库的索引。
使用B-tree结构能够显著降低定位记录时所经历的中间过程,从而加快存取速度。而B+tree是B-tree的一个变种。大名鼎鼎的MySQL就普遍使用B+tree实现其索引结构。
那数据库为什么使用这样的结构?
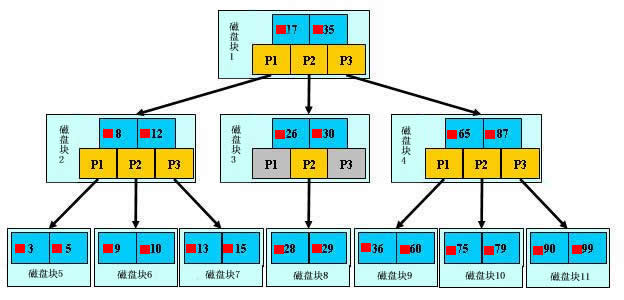
一般来说。索引本身也非常大。不可能所有存储在内存中。因此索引往往以索引文件的形式存储的磁盘上。这种话,索引查找过程中就要产生磁盘I/O消耗。相对于内存存取。I/O存取的消耗要高几个数量级。所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。
换句话说。索引的结构组织要尽量降低查找过程中磁盘I/O的存取次数。
为了达到这个目的。磁盘按需读取。要求每次都会预读的长度一般为页的整数倍。
并且数据库系统将一个节点的大小设为等于一个页,这样每一个节点仅仅须要一次I/O就能够全然加载。每次新建节点时。直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的。就实现了一个node仅仅需一次I/O。并把B-tree中的m值设的很大。就会让树的高度减少,有利于一次全然加载
m-way查找树(重点看步骤图)
首先介绍一下m-way查找树。顾名思义就是一棵树的每一个节点的度小于等于m。
故。它的性质例如以下:
- 每一个节点的键值数小于m
- 每一个节点的度小于等于m
- 键值按顺序排列
- 子树的键值要全然小于或大于或介于父节点之间的键值

B-tree
B-tree又叫平衡多路查找树。一棵m阶的B-tree (m叉树)的特性例如以下:
(当中ceil(x)是一个取上限的函数)
1) 树中每一个结点至多有m个孩子;
2) 除根结点和叶子结点外,其他每一个结点至少有有ceil(m / 2)个孩子;
个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树仅仅有一个根节点)。
4) 全部叶子结点都出如今同一层。叶子结点不包括不论什么keyword信息(能够看做是外部结点或查询失败的结点。实际上这些结点不存在。指向这些结点的指针都为null)。
5) 每一个非终端结点中包括有n个keyword信息: (n,P0,K1,P1,K2,P2,......。Kn,Pn)。
当中:
a) Ki (i=1...n)为keyword,且keyword按顺序排序K(i-1)< Ki。
b) Pi为指向子树根的接点。且指针P(i-1)指向子树种全部结点的keyword均小于Ki,但都大于K(i-1)。
c) keyword的个数n必须满足: ceil(m / 2)-1 <= n <= m-1。
B-tree中的每一个结点依据实际情况能够包括大量的keyword信息和分支(当然是不能超过磁盘块的大小,依据磁盘驱动(disk drives)的不同,一般块的大小在1k~4k左右);这样树的深度减少了。这就意味着查找一个元素仅仅要非常少结点从外存磁盘中读入内存,非常快訪问到要查找的数据。
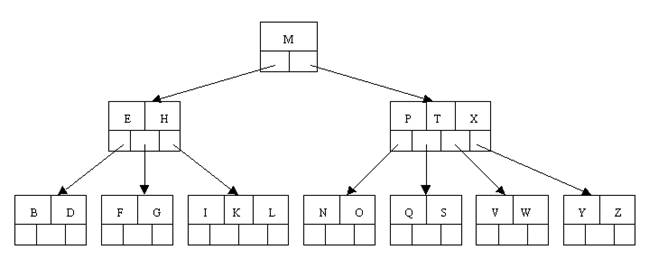
以下以一棵5阶B-tree实例进行解说(例如以下图所看到的):(重点看以下图)
其满足上述条件:个keyword)。
下图中keyword为大写字母。顺序为字母升序。
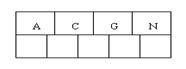
插入(insert)操作:插入一个元素时,首先在B-tree中是否存在。假设不存在,即在叶子结点处结束,然后在叶子结点中插入该新的元素。注意:假设叶子结点空间足够。这里须要向右移动该叶子结点中大于新插入keyword的元素。假设空间满了以致没有足够的空间去加入新的元素,则将该结点进行“分裂”,将一半数量的keyword元素分裂到新的其相邻右结点中,中间keyword元素上移到父结点中(当然,假设父结点空间满了,也相同须要“分裂”操作),并且当结点中关键元素向右移动了,相关的指针也须要向右移。假设在根结点插入新元素,空间满了,则进行分裂操作。这样原来的根结点中的中间keyword元素向上移动到新的根结点中,因此导致树的高度添加一层。
个字母插入同样的结点中,例如以下图:
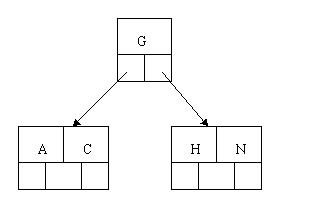
个结点,移动中间元素G上移到新的根结点中,在实现过程中,咱们把A和C留在当前结点中,而H和N放置新的其右邻居结点中。例如以下图:
当咱们插入E,K,Q时。不须要不论什么分裂操作
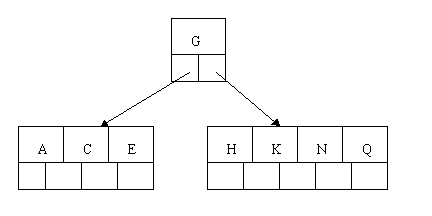
插入M须要一次分裂,注意M恰好是中间keyword元素,以致向上移到父节点中
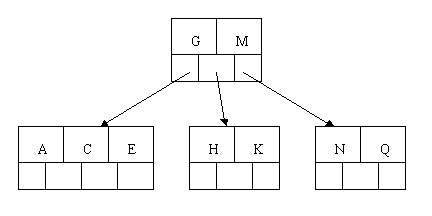
插入F,W,L,T不须要不论什么分裂操作
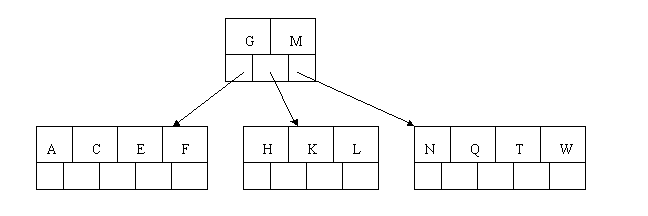
个keyword元素。
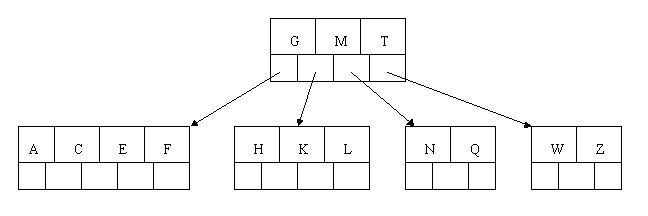
插入D时。导致最左边的叶子结点被分裂,D恰好也是中间元素,上移到父节点中,然后字母P,R,X,Y陆续插入不须要不论什么分裂操作。
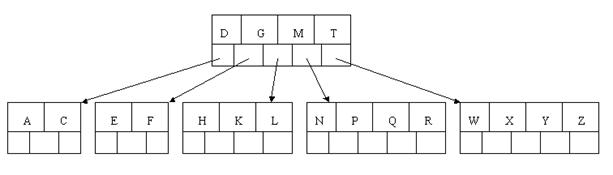
最后,当插入S时,含有N,P,Q,R的结点须要分裂,把中间元素Q上移到父节点中,可是情况来了。父节点中空间已经满了,所以也要进行分裂。将父节点中的中间元素M上移到新形成的根结点中,注意曾经在父节点中的第三个指针在改动后包含D和G节点中。
这样详细插入操作的完毕,以下介绍删除操作,删除操作相对于插入操作要考虑的情况多点。
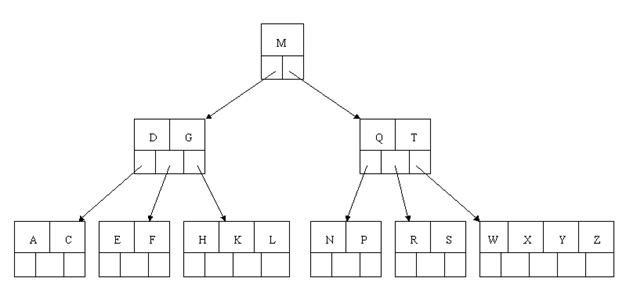
删除(delete)操作:首先查找B-tree中需删除的元素,假设该元素在B-tree中存在。则将该元素在其结点中进行删除,假设删除该元素后,首先推断该元素是否有左右孩子结点,假设有。则上移孩子结点中的某相近元素到父节点中,然后是移动之后的情况。假设没有,直接删除后。移动之后的情况.。
删除元素,移动对应元素之后,假设某结点中元素数目小于ceil(m/2)-1,则须要看其某相邻兄弟结点是否丰满(结点中元素个数大于ceil(m/2)-1),假设丰满,则向父节点借一个元素来满足条件;假设其相邻兄弟都刚脱贫。即借了之后其结点数目小于ceil(m/2)-1,则该结点与其相邻的某一兄弟结点进行“合并”成一个结点。以此来满足条件。那咱们通过以下实例来具体了解吧。
以上述插入操作构造的一棵5阶B-tree为例。依次删除H,T,R,E。
大于最小元素数目ceil(m/2)-1=2,则操作非常easy。咱们仅仅须要移动K至原来H的位置,移动L至K的位置(也就是结点中删除元素后面的元素向前移动)

,无需进行合并操作。
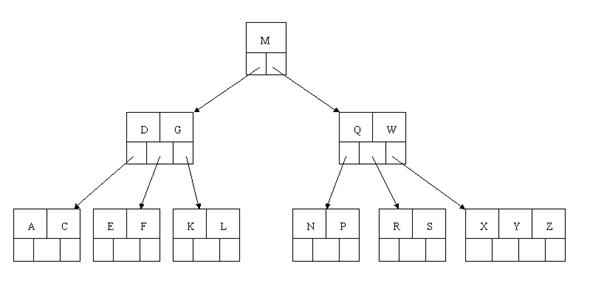
)。所以先向父节点借一个元素W下移到该叶子结点中。取代原来S的位置,S前移;然后X在相邻右兄弟结点中上移到父结点中,最后在相邻右兄弟结点中删除X,后面元素前移。
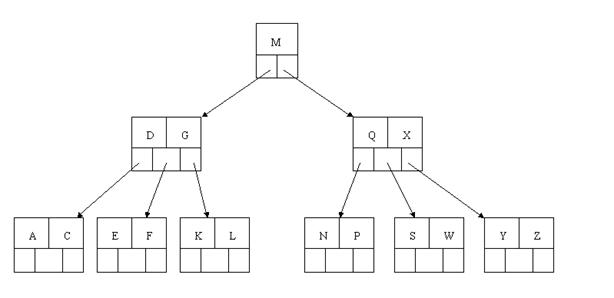
最后一步删除E。删除后会导致非常多问题。由于E所在的结点数目刚好达标。刚好满足最小元素个数(ceil(5/2)-1=2),而相邻的兄弟结点也是相同的情况。删除一个元素都不能满足条件,所以须要该节点与某相邻兄弟结点进行合并操作;首先移动父结点中的元素(该元素在两个须要合并的两个结点元素之间)下移到其子结点中。然后将这两个结点进行合并成一个结点。
所以在该实例中,咱们首先将父节点中的元素D下移到已经删除E而仅仅有F的结点中。然后将含有D和F的结点和含有A,C的相邻兄弟结点进行合并成一个结点。
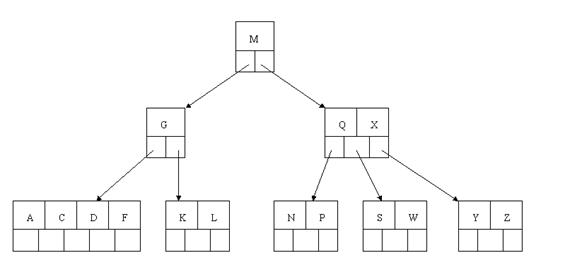
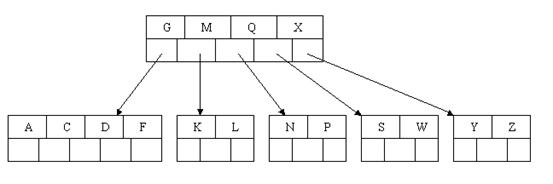
或许你觉得这样删除操作已经结束了。事实上不然。在看看上图,对于这样的特殊情况,你马上会发现父节点仅仅包括一个元素G,没达标,这是不可以接受的。
如果这个问题结点的相邻兄弟比較丰满,则可以向父结点借一个元素。如果这时右兄弟结点(含有Q,X)有一个以上的元素(Q右边还有元素),然后咱们将M下移到元素非常少的子结点中,将Q上移到M的位置,这时,Q的左子树将变成M的右子树,也就是含有N,P结点被依附在M的右指针上。所以在这个实例中,咱们没有办法去借一个元素,仅仅能与兄弟结点进行合并成一个结点。而根结点中的唯一元素M下移到子结点,这样。树的高度降低一层。
为了进一步具体讨论删除的情况。再举另外一个实例:
这里是一棵不同的5阶B-tree,那咱们试着删除C
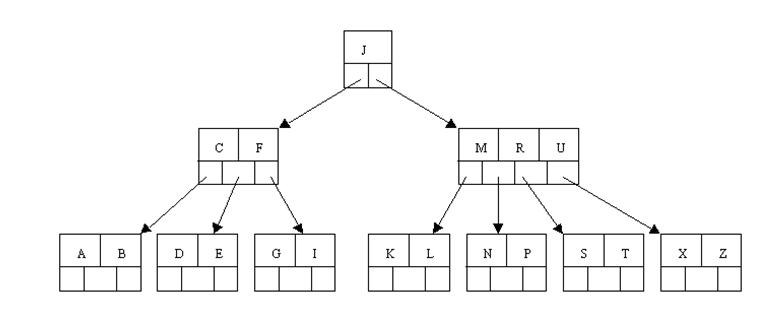
于是将删除元素C的右子结点中的D元素上移到C的位置,可是出现上移元素后,仅仅有一个元素的结点的情况。
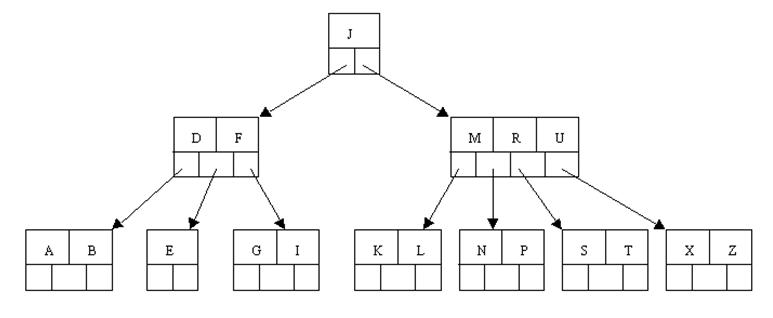
),不可能向父节点借元素。所以仅仅能进行合并操作。于是这里将含有A,B的左兄弟结点和含有E的结点进行合并成一个结点。
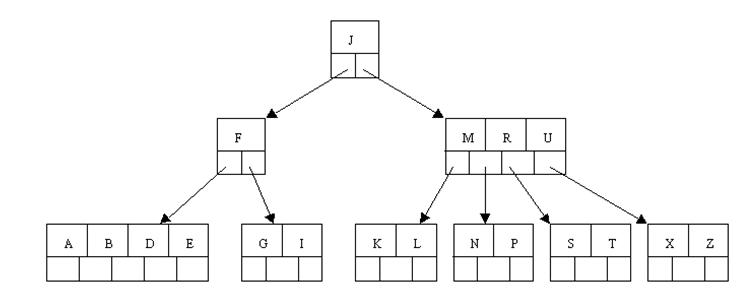
),这样就能够想父结点借元素了。把父结点中的J下移到该结点中,对应的假设结点中J后有元素则前移。然后相邻兄弟结点中的第一个元素(或者最后一个元素)上移到父节点中。后面的元素(或者前面的元素)前移(或者后移);注意含有K。L的结点曾经依附在M的左边。如今变为依附在J的右边。这样每一个结点都满足B-tree结构性质。
版权声明:本文博客原创文章。博客,未经同意,不得转载。
MySql分析算法作品索引(马上,只是说说而已B-tree)的更多相关文章
- MySQL(二)索引背后的数据结构及算法原理
本文转载自CodingLabs,原文链接 MySQL索引背后的数据结构及算法原理 目录 摘要 一.数据结构及算法基础 1. 索引的本质 2. B-Tree和B+Tree 3. 为什么使用B-Tree( ...
- MySQL高级第二章——索引优化分析
一.SQL性能下降原因 1.等待时间长?执行时间长? 可能原因: 查询语句写的不行 索引失效(单值索引.复合索引) CREATE INDEX index_user_name ON user(name) ...
- 「MySQL高级篇」explain分析SQL,索引失效&&常见优化场景
大家好,我是melo,一名大三后台练习生 专栏回顾 索引的原理&&设计原则 欢迎关注本专栏:MySQL高级篇 本篇速览 在我们上一篇文章中,讲到了索引的原理&&设计原则 ...
- mysql性能优化-慢查询分析、优化索引和配置
一.优化概述 二.查询与索引优化分析 1性能瓶颈定位 Show命令 慢查询日志 explain分析查询 profiling分析查询 2索引及查询优化 三.配置优化 1) max_connec ...
- mysql性能优化-慢查询分析、优化索引和配置 (慢查询日志,explain,profile)
mysql性能优化-慢查询分析.优化索引和配置 (慢查询日志,explain,profile) 一.优化概述 二.查询与索引优化分析 1性能瓶颈定位 Show命令 慢查询日志 explain分析查询 ...
- mysql性能优化-慢查询分析、优化索引和配置【转】
一.优化概述 二.查询与索引优化分析 1性能瓶颈定位 Show命令 慢查询日志 explain分析查询 profiling分析查询 2索引及查询优化 三.配置优化 1) max_connec ...
- mysql性能优化-慢查询分析、优化索引和配置 MySQL索引介绍
MySQL索引介绍 聚集索引(Clustered Index)----叶子节点存放整行记录辅助索引(Secondary Index)----叶子节点存放row identifier-------Inn ...
- 优化、分析Mysql表读写、索引等操作的sql语句效率优化问题
为什么要优化: 随着实际项目的启动,数据库经过一段时间的运行,最初的数据库设置,会与实际数据库运行性能会有一些差异,这时我们 就需要做一个优化调整. 数据库优化这个课题较大,可分为四大类: >主 ...
- 9.mysql性能优化-慢查询分析、优化索引和配置
目录 一.优化概述 二.查询与索引优化分析 1性能瓶颈定位 Show命令 慢查询日志 explain分析查询 profiling分析查询 2索引及查询优化 三.配置优化 max_connections ...
随机推荐
- 【android】在Eclipse在联想引jar包源代码
(前提是你有jar包源代码!!) .确保Referenced LIbraies下已经有该jar包,否则的话,右击该jar包选build path->add to build path. 二.右键 ...
- wscript:329: error: Could not autodetect OpenSSL support. Make sure OpenSSL development packages are
安装node错: wscript:329: error: Could not autodetect OpenSSL support. Make sure OpenSSL development pac ...
- mmc生产任务分配问题
mmc生产任务分配问题,本题目简单.
- 强大的PropertyGrid
PropertyGrid, 做工具一定要用这东西..... 把要编辑的对象看成类的话, 全部要编辑的属性就是成员 嗯嗯, 近期看了几眼Ogitor, 它对于PropertyGrid的使用就非常不错 全 ...
- zoj 3822 Domination(2014牡丹江区域赛D称号)
Domination Time Limit: 8 Seconds Memory Limit: 131072 KB Special Judge Edward is the headm ...
- 设备Oracle当误差:环境不符合要求》》解决方法
一旦安装Oracle当我常常会遇到这样的问题.也没太在意,改了一下client\stage\cvu文件夹cvu_prereq.xml档(添加支持目前的操作系统信息)为了克服,我没有做笔记,但后来有同学 ...
- Android学习笔记(四十):Preference使用
Preference从字面上看偏好,译为首选项. 一些配置数据,一些我们上次点击选择的内容.我们希望在下次应用调起的时候依旧有效,无须用户再一次进行配置或选择.Android提供preference这 ...
- REDGATE SQLPROMPT 6.0新功能
原文:REDGATE SQLPROMPT 6.0新功能 REDGATE SQLPROMPT 6.0新功能 下载地址:http://files.cnblogs.com/lyhabc/SQLPrompt6 ...
- Spring之AOP术语
AOP是Aspect Oriented Programing的简称.被译为"面向切面编程". AOP独辟蹊径通过横向抽取机制为这类无法通过纵向继承体系进行抽象的反复性代码提供了解决 ...
- ASP.Net 重写IHttpModule 来拦截 HttpApplication 实现HTML资源压缩和空白过滤
务实直接上代码: 1. 重写FilterModule.cs using System; using System.Collections.Generic; using System.Linq; usi ...