k近邻算法(knn)的c语言实现
最近在看knn算法,顺便敲敲代码。
knn属于数据挖掘的分类算法。基本思想是在距离空间里,如果一个样本的最接近的k个邻居里,绝大多数属于某个类别,则该样本也属于这个类别。俗话叫,“随大流”。
简单来说,KNN可以看成:有那么一堆你已经知道分类的数据,然后当一个新的数据进入的时候,就开始跟训练里的每个点求距离,然后挑出离这个数据最近的K个点,看看这K个点属于什么类型,然后用少数服从多数的原则,给新数据归类。
该算法的示意图,简单明了:

下面的算法步骤取自于百度文库(文库是一个好东西),代码是参照这个思路实现的:

code:
#include<stdio.h>
#include<math.h>
#include<stdlib.h> #define K 3 //近邻数k
typedef float type; //动态创建二维数组
type **createarray(int n,int m)
{
int i;
type **array;
array=(type **)malloc(n*sizeof(type *));
array[]=(type *)malloc(n*m*sizeof(type));
for(i=;i<n;i++) array[i]=array[i-]+m;
return array;
}
//读取数据,要求首行格式为 N=数据量,D=维数
void loaddata(int *n,int *d,type ***array,type ***karray)
{
int i,j;
FILE *fp;
if((fp=fopen("data.txt","r"))==NULL) fprintf(stderr,"can not open data.txt!\n");
if(fscanf(fp,"N=%d,D=%d",n,d)!=) fprintf(stderr,"reading error!\n");
*array=createarray(*n,*d);
*karray=createarray(,K); for(i=;i<*n;i++)
for(j=;j<*d;j++)
fscanf(fp,"%f",&(*array)[i][j]); //读取数据 for(i=;i<;i++)
for(j=;j<K;j++)
(*karray)[i][j]=9999.0; //默认的最大值
if(fclose(fp)) fprintf(stderr,"can not close data.txt");
}
//计算欧氏距离
type computedistance(int n,type *avector,type *bvector)
{
int i;
type dist=0.0;
for(i=;i<n;i++)
dist+=pow(avector[i]-bvector[i],);
return sqrt(dist);
}
//冒泡排序
void bublesort(int n,type **a,int choice)
{
int i,j;
type k;
for(j=;j<n;j++)
for(i=;i<n-j-;i++){
if(==choice){
if(a[][i]>a[][i+]){
k=a[][i];
a[][i]=a[][i+];
a[][i+]=k;
k=a[][i];
a[][i]=a[][i+];
a[][i+]=k;
}
}
else if(==choice){
if(a[][i]>a[][i+]){
k=a[][i];
a[][i]=a[][i+];
a[][i+]=k;
k=a[][i];
a[][i]=a[][i+];
a[][i+]=k;
}
}
}
}
//统计有序表中的元素个数
type orderedlist(int n,type *list)
{
int i,count=,maxcount=;
type value;
for(i=;i<(n-);i++) {
if(list[i]!=list[i+]) {
//printf("count of %d is value %d\n",list[i],count);
if(count>maxcount){
maxcount=count;
value=list[i];
count=;
}
}
else
count++;
}
if(count>maxcount){
maxcount=count;
value=list[n-];
}
//printf("value %f has a Maxcount:%d\n",value,maxcount);
return value;
} int main()
{
int i,j,k;
int D,N; //维度,数据量
type **array=NULL; //数据数组
type **karray=NULL; // K近邻点的距离及其标签
type *testdata; //测试数据
type dist,maxdist; loaddata(&N,&D,&array,&karray);
testdata=(type *)malloc((D-)*sizeof(type));
printf("input test data containing %d numbers:\n",D-);
for(i=;i<(D-);i++) scanf("%f",&testdata[i]); while(){
for(i=;i<K;i++){
if(K>N) exit(-);
karray[][i]=computedistance(D-,testdata,array[i]);
karray[][i]=array[i][D-];
//printf("first karray:%6.2f %6.0f\n",karray[0][i],karray[1][i]);
} bublesort(K,karray,);
//for(i=0;i<K;i++) printf("after bublesort in first karray:%6.2f %6.0f\n",karray[0][i],karray[1][i]);
maxdist=karray[][K-]; //初始化k近邻数组的距离最大值 for(i=K;i<N;i++){
dist=computedistance(D-,testdata,array[i]);
if(dist<maxdist)
for(j=;j<K;j++){
if(dist<karray[][j]){
for(k=K-;k>j;k--){ //j后元素复制到后一位,为插入做准备
karray[][k]=karray[][k-];
karray[][k]=karray[][k-];
}
karray[][j]=dist; //插入到j位置
karray[][j]=array[i][D-];
//printf("i:%d karray:%6.2f %6.0f\n",i,karray[0][j],karray[1][j]);
break; //不比较karray后续元素
}
}
maxdist=karray[][K-];
//printf("i:%d maxdist:%6.2f\n",i,maxdist);
}
//for(i=0;i<K;i++) printf("karray:%6.2f %6.0f\n",karray[0][i],karray[1][i]);
bublesort(K,karray,);
//for(i=0;i<K;i++) printf("after bublesort in karray:%6.2f %6.0f\n",karray[0][i],karray[1][i]);
printf("\nThe data has a tag: %.0f\n\n",orderedlist(K,karray[])); printf("input test data containing %d numbers:\n",D-);
for(i=;i<(D-);i++) scanf("%f",&testdata[i]);
}
return ;
}
实验:
训练数据data.txt:
N=6,D=9
1.0 1.1 1.2 2.1 0.3 2.3 1.4 0.5 1
1.7 1.2 1.4 2.0 0.2 2.5 1.2 0.8 1
1.2 1.8 1.6 2.5 0.1 2.2 1.8 0.2 1
1.9 2.1 6.2 1.1 0.9 3.3 2.4 5.5 0
1.0 0.8 1.6 2.1 0.2 2.3 1.6 0.5 1
1.6 2.1 5.2 1.1 0.8 3.6 2.4 4.5 0
预测数据:
1.0 1.1 1.2 2.1 0.3 2.3 1.4 0.5
1.7 1.2 1.4 2.0 0.2 2.5 1.2 0.8
1.2 1.8 1.6 2.5 0.1 2.2 1.8 0.2
1.9 2.1 6.2 1.1 0.9 3.3 2.4 5.5
1.0 0.8 1.6 2.1 0.2 2.3 1.6 0.5
1.6 2.1 5.2 1.1 0.8 3.6 2.4 4.5
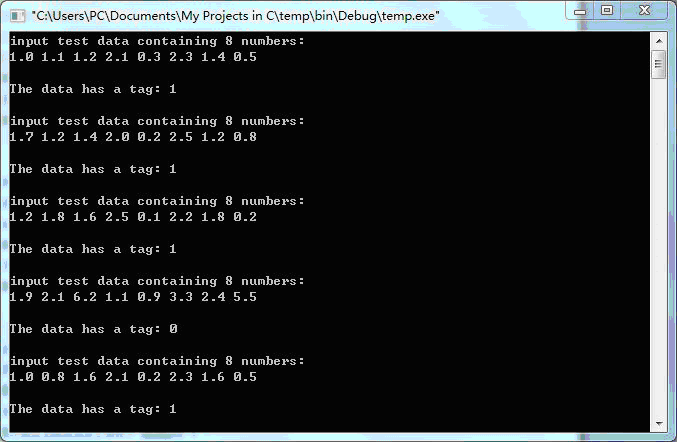
程序测试的结果:
1.0 1.1 1.2 2.1 0.3 2.3 1.4 0.5 类别为: 1
1.7 1.2 1.4 2.0 0.2 2.5 1.2 0.8 类别为: 1
1.2 1.8 1.6 2.5 0.1 2.2 1.8 0.2 类别为: 1
1.9 2.1 6.2 1.1 0.9 3.3 2.4 5.5 类别为: 0
1.0 0.8 1.6 2.1 0.2 2.3 1.6 0.5 类别为: 1
1.6 2.1 5.2 1.1 0.8 3.6 2.4 4.5 类别为: 0
实验截图:
k近邻算法(knn)的c语言实现的更多相关文章
- k近邻算法(KNN)
k近邻算法(KNN) 定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. from sklearn.model_selection ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- 一看就懂的K近邻算法(KNN),K-D树,并实现手写数字识别!
1. 什么是KNN 1.1 KNN的通俗解释 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1 ...
- 机器学习(四) 机器学习(四) 分类算法--K近邻算法 KNN (下)
六.网格搜索与 K 邻近算法中更多的超参数 七.数据归一化 Feature Scaling 解决方案:将所有的数据映射到同一尺度 八.scikit-learn 中的 Scaler preprocess ...
- 《机器学习实战》---第二章 k近邻算法 kNN
下面的代码是在python3中运行, # -*- coding: utf-8 -*- """ Created on Tue Jul 3 17:29:27 2018 @au ...
- 最基础的分类算法-k近邻算法 kNN简介及Jupyter基础实现及Python实现
k-Nearest Neighbors简介 对于该图来说,x轴对应的是肿瘤的大小,y轴对应的是时间,蓝色样本表示恶性肿瘤,红色样本表示良性肿瘤,我们先假设k=3,这个k先不考虑怎么得到,先假设这个k是 ...
- 07.k近邻算法kNN
1.将数据分为测试数据和预测数据 2.数据分为data和target,data是矩阵,target是向量 3.将每条data(向量)绘制在坐标系中,就得到了一系列的点 4.根据每条data的targe ...
- 机器学习随笔01 - k近邻算法
算法名称: k近邻算法 (kNN: k-Nearest Neighbor) 问题提出: 根据已有对象的归类数据,给新对象(事物)归类. 核心思想: 将对象分解为特征,因为对象的特征决定了事对象的分类. ...
- 机器学习(1)——K近邻算法
KNN的函数写法 import numpy as np from math import sqrt from collections import Counter def KNN_classify(k ...
随机推荐
- css实现文本溢出显示...
在网页中显示文字内容时,经常会碰到文字内容特别长的情况,那么这个时候为了使网页看起来比较美观和简洁,会对内容进行处理.下面我们就来看一看,如何使用css来对文字溢出部分增加.... 首先来看第一种情况 ...
- Php基础知识测试题
一:选择题 1. LAMP具体结构不包含下面哪种(A ) A:Windows系统 如果是这个就是WMP B:Apache服务器 C:MySQL数据库 D:PHP语 ...
- 给ListView设置emptyView
给ListView设置emptyView 版权声明:本文为博主原创文章,未经博主允许不得转载. 使用ListView和GridView时,当列表为空时,默认是不显示任何内容的,这样对用户非常不友好,这 ...
- 如何修复VUM在客户端启用之后报数据库连接失败的问题
在上一篇随笔中介绍了关于重新注册VMware Update Manager(VUM)至vCenter Server中的方法,最近有朋友反应,原本切换过去好好的更新服务为什么某次使用一下就不灵了? 当时 ...
- 完美解决,浏览器下拉显示网址问题 | 完美解决,使用原生 scroll 写下拉刷新
在 web 开发过程中我们经常遇到,不想让用户下拉看到我的地址,也有时候在 div 中没有惯性滚动,就此也出了 iScroll 这种关于滚动条的框架,但是就为了一个体验去使用一个框架好像又不值得,今天 ...
- 深入理解JavaScript——闭包
跟很多新手一样我也是初入前端,对闭包的理解花费的时间和精力相当的多.效果也还行,今天我就来根据自己的理解细致的讲一讲闭包,由于是初入学习的时候不免有一些弯路和困惑,我想信这也是很多跟我一样的人会同样遇 ...
- C#开发微信门户及应用(21)-微信企业号的消息和事件的接收处理及解密
在上篇随笔<C#开发微信门户及应用(19)-微信企业号的消息发送(文本.图片.文件.语音.视频.图文消息等)>介绍了有关企业号的消息发送,官方特别声明消息是不用加密发送的.但是在回调的服务 ...
- 解析ListView联动的实现--仿饿了么点餐界面
一.博客的由来 大神王丰蛋哥 之前一篇博客仿饿了点餐界面2个ListView联动(http://www.cnblogs.com/wangfengdange/p/5886064.html) 主要实现了2 ...
- ActiveMQ(li)
一.ActiveMQ 首先,ActiveMQ不是一个框架,它不是struct,webx,netty这种框架,它更像是tomcat服务器,因为你使用它之前必须启动它,activeMQ和JMS的关系有点类 ...
- python征程3.1(列表,迭代,函数,dic,set,的简单应用)
1.列表的切片. 1.对list进行切片.'''name=["wangshuai","wangchuan","wangjingliang", ...