Spark 键值对RDD操作
键值对的RDD操作与基本RDD操作一样,只是操作的元素由基本类型改为二元组。
概述
键值对RDD是Spark操作中最常用的RDD,它是很多程序的构成要素,因为他们提供了并行操作各个键或跨界点重新进行数据分组的操作接口。
创建
Spark中有许多中创建键值对RDD的方式,其中包括
- 文件读取时直接返回键值对RDD
- 通过List创建键值对RDD
在Scala中,可通过Map函数生成二元组
val listRDD = sc.parallelize(List(1,2,3,4,5))
val result = listRDD.map(x => (x,1))
result.foreach(println) //结果
(1,1)
(2,1)
(3,1)
(4,1)
(5,1)
键值对RDD的转化操作
基本RDD转化操作在此同样适用。但因为键值对RDD中包含的是一个个二元组,所以需要传递的函数会由原来的操作单个元素改为操作二元组。
下表总结了针对单个键值对RDD的转化操作,以 { (1,2) , (3,4) , (3,6) } 为例,f表示传入的函数
| 函数名 | 目的 | 示例 | 结果 |
| reduceByKey(f) | 合并具有相同key的值 | rdd.reduceByKey( ( x,y) => x+y ) | { (1,2) , (3,10) } |
| groupByKey() | 对具有相同key的值分组 | rdd.groupByKey() | { (1,2) , (3, [4,6] ) } |
| mapValues(f) | 对键值对中的每个值(value)应用一个函数,但不改变键(key) | rdd.mapValues(x => x+1) | { (1,3) , (3,5) , (3,7) } |
| combineBy Key( createCombiner, mergeValue, mergeCombiners, partitioner) | 使用不同的返回类型合并具有相同键的值 | 下面有详细讲解 | - |
| flatMapValues(f) | 对键值对RDD中每个值应用返回一个迭代器的函数,然后对每个元素生成一个对应的键值对。常用语符号化 | rdd.flatMapValues(x => ( x to 5 )) |
{ (1, 2) , (1, 3) , (1, 4) , (1, 5) , (3, 4) , (3, 5) } |
| keys() | 获取所有key | rdd.keys() | {1,3,3} |
| values() | 获取所有value | rdd.values() | {2,4,6} |
| sortByKey() | 根据key排序 | rdd.sortByKey() | { (1,2) , (3,4) , (3,6) } |
下表总结了针对两个键值对RDD的转化操作,以rdd1 = { (1,2) , (3,4) , (3,6) } rdd2 = { (3,9) } 为例,
| 函数名 | 目的 | 示例 | 结果 |
| subtractByKey | 删掉rdd1中与rdd2的key相同的元素 | rdd1.subtractByKey(rdd2) | { (1,2) } |
| join | 内连接 | rdd1.join(rdd2) |
{(3, (4, 9)), (3, (6, 9))} |
| leftOuterJoin | 左外链接 | rdd1.leftOuterJoin (rdd2) |
{(3,( Some( 4), 9)), (3,( Some( 6), 9))} |
| rightOuterJoin | 右外链接 | rdd1.rightOuterJoin(rdd2) |
{(1,( 2, None)), (3, (4, Some( 9))), (3, (6, Some( 9)))} |
| cogroup | 将两个RDD钟相同key的数据分组到一起 | rdd1.cogroup(rdd2) | {(1,([ 2],[])), (3, ([4, 6],[ 9]))} |
combineByKey
combineByKey( createCombiner, mergeValue, mergeCombiners, partitioner,mapSideCombine)
combineByKey( createCombiner, mergeValue, mergeCombiners, partitioner)
combineByKey( createCombiner, mergeValue, mergeCombiners)
函数功能:
聚合各分区的元素,而每个元素都是二元组。功能与基础RDD函数aggregate()差不多,可让用户返回与输入数据类型不同的返回值。
combineByKey函数的每个参数分别对应聚合操作的各个阶段。所以,理解此函数对Spark如何操作RDD会有很大帮助。
参数解析:
createCombiner:分区内 创建组合函数
mergeValue:分区内 合并值函数
mergeCombiners:多分区 合并组合器函数
partitioner:自定义分区数,默认为HashPartitioner
mapSideCombine:是否在map端进行Combine操作,默认为true
工作流程:
- combineByKey会遍历分区中的所有元素,因此每个元素的key要么没遇到过,要么和之前某个元素的key相同。
- 如果这是一个新的元素,函数会调用createCombiner创建那个key对应的累加器初始值。
- 如果这是一个在处理当前分区之前已经遇到的key,会调用mergeCombiners把该key累加器对应的当前value与这个新的value合并。
代码例子:
//统计男女个数
val conf = new SparkConf ().setMaster ("local").setAppName ("app_1")
val sc = new SparkContext (conf)
val people = List(("男", "李四"), ("男", "张三"), ("女", "韩梅梅"), ("女", "李思思"), ("男", "马云"))
val rdd = sc.parallelize(people,2)
val result = rdd.combineByKey(
(x: String) => (List(x), 1), //createCombiner
(peo: (List[String], Int), x : String) => (x :: peo._1, peo._2 + 1), //mergeValue
(sex1: (List[String], Int), sex2: (List[String], Int)) => (sex1._1 ::: sex2._1, sex1._2 + sex2._2)) //mergeCombiners
result.foreach(println)
结果
(男, ( List( 张三, 李四, 马云),3 ) )
(女, ( List( 李思思, 韩梅梅),2 ) )
流程分解:
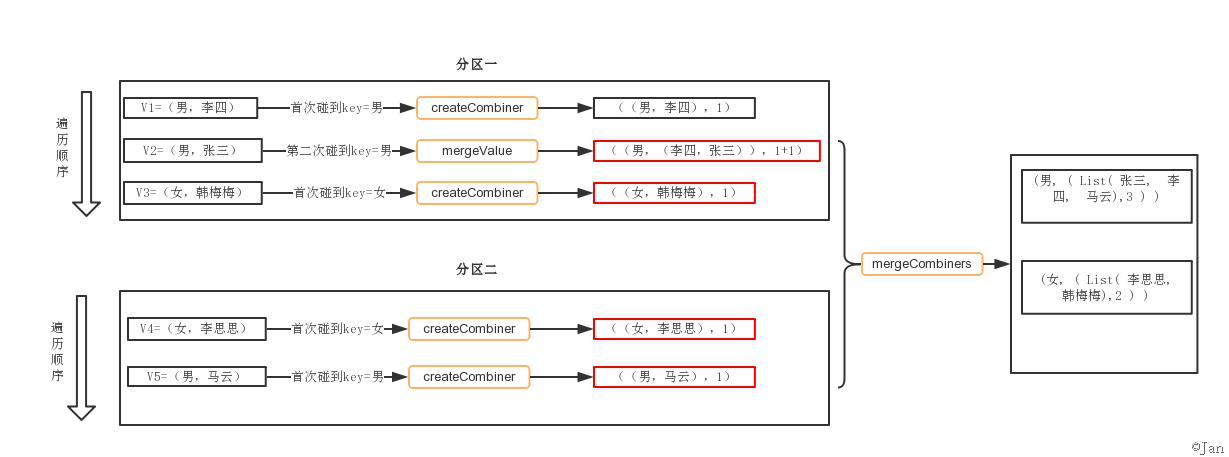
解析:两个分区,分区一按顺序V1、V2、V3遍历
- V1,发现第一个key=男时,调用createCombiner,即
(x: String) => (List(x), 1)
- V2,第二次碰到key=男的元素,调用mergeValue,即
(peo: (List[String], Int), x : String) => (x :: peo._1, peo._2 + 1)
- V3,发现第一个key=女,继续调用createCombiner,即
(x: String) => (List(x), 1)
- … …
- 待各V1、V2分区都计算完后,数据进行混洗,调用mergeCombiners,即
(sex1: (List[String], Int), sex2: (List[String], Int)) => (sex1._1 ::: sex2._1, sex1._2 + sex2._2))
add by jan 2017-02-27 18:34:39
以下例子都基于此RDD
(Hadoop,1)
(Spark,1)
(Hive,1)
(Spark,1)
reduceByKey(func)
reduceByKey(func)的功能是,使用func函数合并具有相同键的值。
比如,reduceByKey((a,b) => a+b),有四个键值对("spark",1)、("spark",2)、("hadoop",3)和("hadoop",5),对具有相同key的键值对进行合并后的结果就是:("spark",3)、("hadoop",8)。可以看出,(a,b) => a+b这个Lamda表达式中,a和b都是指value,比如,对于两个具有相同key的键值对("spark",1)、("spark",2),a就是1,b就是2。
scala> pairRDD.reduceByKey((a,b)=>a+b).foreach(println)
(Spark,2)
(Hive,1)
(Hadoop,1)
groupByKey()
roupByKey()的功能是,对具有相同键的值进行分组。比如,对四个键值对("spark",1)、("spark",2)、("hadoop",3)和("hadoop",5),采用groupByKey()后得到的结果是:("spark",(1,2))和("hadoop",(3,5))。
scala> pairRDD.groupByKey()
res15: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[15] at groupByKey at <console>:34
//从上面执行结果信息中可以看出,分组后,value被保存到Iterable[Int]中
scala> pairRDD.groupByKey().foreach(println)
(Spark,CompactBuffer(1, 1))
(Hive,CompactBuffer(1))
(Hadoop,CompactBuffer(1))
keys
keys只会把键值对RDD中的key返回形成一个新的RDD。比如,对四个键值对("spark",1)、("spark",2)、("hadoop",3)和("hadoop",5)构成的RDD,采用keys后得到的结果是一个RDD[Int],内容是{"spark","spark","hadoop","hadoop"}。
scala> pairRDD.keys
res17: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[17] at keys at <console>:34
scala> pairRDD.keys.foreach(println)
Hadoop
Spark
Hive
Spark
values
values只会把键值对RDD中的value返回形成一个新的RDD。比如,对四个键值对("spark",1)、("spark",2)、("hadoop",3)和("hadoop",5)构成的RDD,采用keys后得到的结果是一个RDD[Int],内容是{1,2,3,5}。
scala> pairRDD.values
res0: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[2] at values at <console>:34 scala> pairRDD.values.foreach(println)
1
1
1
1
sortByKey()
sortByKey()的功能是返回一个根据键排序的RDD。
scala> pairRDD.sortByKey()
res0: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[2] at sortByKey at <console>:34
scala> pairRDD.sortByKey().foreach(println)
(Hadoop,1)
(Hive,1)
(Spark,1)
(Spark,1)
mapValues(func)
我们经常会遇到一种情形,我们只想对键值对RDD的value部分进行处理,而不是同时对key和value进行处理。对于这种情形,Spark提供了mapValues(func),它的功能是,对键值对RDD中的每个value都应用一个函数,但是,key不会发生变化。比如,对四个键值对("spark",1)、("spark",2)、("hadoop",3)和("hadoop",5)构成的pairRDD,如果执行pairRDD.mapValues(x => x+1),就会得到一个新的键值对RDD,它包含下面四个键值对("spark",2)、("spark",3)、("hadoop",4)和("hadoop",6)。
scala> pairRDD.mapValues(x => x+1)
res2: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[4] at mapValues at <console>:34
scala> pairRDD.mapValues(x => x+1).foreach(println)
(Hadoop,2)
(Spark,2)
(Hive,2)
(Spark,2)
join
join(连接)操作是键值对常用的操作。“连接”(join)这个概念来自于关系数据库领域,因此,join的类型也和关系数据库中的join一样,包括内连接(join)、左外连接(leftOuterJoin)、右外连接(rightOuterJoin)等。最常用的情形是内连接,所以,join就表示内连接。
对于内连接,对于给定的两个输入数据集(K,V1)和(K,V2),只有在两个数据集中都存在的key才会被输出,最终得到一个(K,(V1,V2))类型的数据集。
比如,pairRDD1是一个键值对集合{("spark",1)、("spark",2)、("hadoop",3)和("hadoop",5)},pairRDD2是一个键值对集合{("spark","fast")},那么,pairRDD1.join(pairRDD2)的结果就是一个新的RDD,这个新的RDD是键值对集合{("spark",1,"fast"),("spark",2,"fast")}。对于这个实例,我们下面在spark-shell中运行一下:
scala> val pairRDD1 = sc.parallelize(Array(("spark",1),("spark",2),("hadoop",3),("hadoop",5)))
pairRDD1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[24] at parallelize at <console>:27
scala> val pairRDD2 = sc.parallelize(Array(("spark","fast")))
pairRDD2: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[25] at parallelize at <console>:27
scala> pairRDD1.join(pairRDD2)
res9: org.apache.spark.rdd.RDD[(String, (Int, String))] = MapPartitionsRDD[28] at join at <console>:32
scala> pairRDD1.join(pairRDD2).foreach(println)
(spark,(1,fast))
(spark,(2,fast))
详细请参考《Spark快速大数据分析》
Spark 键值对RDD操作的更多相关文章
- Spark基础:(三)Spark 键值对操作
1.pair RDD的简介 Spark为包含键值对类型的RDD提供了一些专有的操作,这些RDD就被称为pair RDD 那么如何创建pair RDD呢? 在不同的语言中有着不同的创建方式 在pytho ...
- 5.2 RDD编程---键值对RDD
一.键值对RDD的创建 1.从文件中加载 2.通过并行集合(数组)创建RDD 二.常用的键值对RDD转换操作 1.reduceByKey(func) 功能:使用func函数合并具有相同键的值 2.gr ...
- 3. 键值对RDD
键值对RDD是Spark中许多操作所需要的常见数据类型.除了在基础RDD类中定义的操作之外,Spark为包含键值对类型的RDD提供了一些专有的操作在PairRDDFunctions专门进行了定义.这些 ...
- mybatis 08: 返回主键值的insert操作 + 利用UUID获取字符串(了解)
返回主键值的insert操作 应用背景 图示说明 在上述业务背景下,涉及两张数据表的关联操作:用户表 + 用户积分表 传统操作:在对用户表执行完插入语句后,再次查询该用户的uid,将该uid作为外键, ...
- Spark编程模型及RDD操作
转载自:http://blog.csdn.net/liuwenbo0920/article/details/45243775 1. Spark中的基本概念 在Spark中,有下面的基本概念.Appli ...
- Redis 使用 Eval 多个键值自增操作示例
在PHP上使用Redis 给多个键值进行自增,示例如下: $set['money'] = $this->redis->hIncrByFloat($key, $hour .'_money', ...
- python 对redis 键值对的操作
我们可以将Redis中的Hashes类型看成具有String Key和String Value的键值对容器.类似python中的dict,javascript的jaon,java 的map,每一个Ha ...
- Spark中的键值对操作-scala
1.PairRDD介绍 Spark为包含键值对类型的RDD提供了一些专有的操作.这些RDD被称为PairRDD.PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口.例如,Pa ...
- Spark中的键值对操作
1.PairRDD介绍 Spark为包含键值对类型的RDD提供了一些专有的操作.这些RDD被称为PairRDD.PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口.例如,Pa ...
随机推荐
- 《Web接口开发与自动化测试 -- 基于Python语言》 ---前言
前 言 本书的原型是我整理一份Django学习文档,从事软件测试工作的这六.七年来,一直有整理学习资料的习惯,这种学习理解再输出的方式对我非常受用,博客和文档是我主要的输出形式,这些输出同时也帮 ...
- 计时器chronometer补充
项目中要实现关于安卓控件chronometer这部分的功能需求: 1.计时器的功能对用户答题时间进行时间统计,用户答完该题,进入下一题,计时器接续上一题的结束时间继续计时: 2.用户可以跳出答题界面, ...
- IOS 动画的两种方式
方式一: [UIView animateWithDuration:1 animations:^{ //动画的内容 CGRect frame = CGRectMake([UIParam widthScr ...
- mysql 和excel相互转换
原文地址:http://blog.sina.com.cn/s/blog_43eb83b90100h0mc.html 今天是全国数学建模比赛,同学选的一个题目需要对一个large的Excel表格进行统计 ...
- 在DFS和BFS中一般情况可以不用vis[][]数组标记
开始学dfs 与bfs 时一直喜欢用vis[][]来标记有没有访问过, 现在我觉得没有必要用vis[][]标记了 看代码 用'#'表示墙,'.'表示道路 if(所有情况都满足){ map[i][j]= ...
- 阿里云服务器windows系统C盘一键清理脚本
@ECHO OFF @echo @echo @echo 清理几个比较多垃圾文件的地方 DEL /F /S /Q "C:\WINDOWS\PCHealth\ERRORREP\QSIGNOFF\ ...
- 百度人脸识别api及face++人脸识别api测试(python)
一.百度人脸识别服务 1.官方网址:http://apistore.baidu.com/apiworks/servicedetail/464.html 2.提供的接口包括: 2.1 多人脸比对:请求多 ...
- python bottle 简介
bottle是一个轻量级的python web框架, 可以适配各种web服务器,包括python自带的wsgiref(默认),gevent, cherrypy,gunicorn等等.bottle是单文 ...
- 照片提取GPS 转成百度地图坐标
感谢: 小慧only http://www.cnblogs.com/zhaohuionly/p/3142623.html GPS转化坐标方法 大胡子青松 http://www.cnblogs.com ...
- office如何去除多页签
写文档会遇到同时打开多个文档,偶尔可能需要对比,而有时office会出现跟浏览器类似的多页签界面.如何去除多页签,office本身没有此加载项,一般都是作为插件或组件形式另外安装,导致我们不知道从哪里 ...