InfluxDB总结
一、简介
InfluxDB(时序数据库)influxdb是一个开源分布式时序、时间和指标数据库,使用 Go 语言编写,无需外部依赖。其设计目标是实现分布式和水平伸缩扩展,是 InfluxData 的核心产品。常用的一种使用场景:监控数据统计,物联网传感器数据和实
时分析等的后端存储。每毫秒记录一下电脑内存的使用情况,然后就可以根据统计的数据,利用图形化界面(InfluxDB V1一般配合Grafana)制作内存使用情况的折线图;可以理解为按时间记录一些数据(常用的监控数据、埋点统计数据等),然
后制作图表做统计。
- 时间序列数据:从定义上来说,就是一串按时间维度索引的数据。
- 时序数据库(TSDB)特点:
持续高并发写入、无更新;
数据压缩存储;
低查询延时。 - 常见 TSDB:influxdb、opentsdb、timeScaladb、Druid 等。
- influxdb 完整的上下游产业还包括:Chronograf、Telegraf、Kapacitor,其具体作用及关系如下:
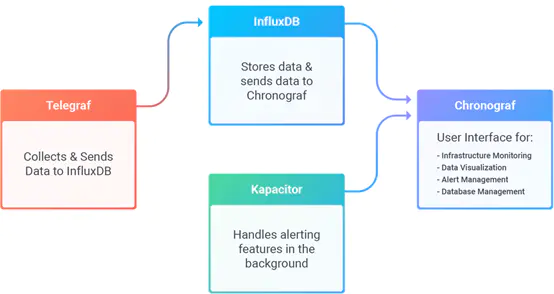
influxdb和其他时序数据库比较

二、同常见关系型数据库(MySQL)的基础概念对比
| 概念 | MySQL | InfluxDB |
|---|---|---|
| 数据库(同) | database | database |
| 表(不同) | table | measurement |
| 列(不同) | column | tag(带索引的,非必须)、field(不带索引)、timestemp(唯一主键) |
tag set:不同的每组tag key和tag value的集合;
field set:每组field key和field value的集合;
retention policy:数据存储策略(默认策略为autogen)InfluxDB没有删除数据操作,规定数据的保留时间达到清除数据的目的;
series:共同retention policy,measurement和tag set的集合;
示例数据如下: 其中census是measurement,butterflies和honeybees是field key,location和scientist是tag key
name: census
————————————
time butterflies honeybees location scientist
2015-08-18T00:00:00Z 12 23 1 langstroth
2015-08-18T00:00:00Z 1 30 1 perpetua
2015-08-18T00:06:00Z 11 28 1 langstroth
2015-08-18T00:06:00Z 11 28 2 langstroth
- point的数据结构由时间戳(time)、标签(tags)、数据(fields)三部分组成,具体含义如下:
| point 属性 | 含义 |
|---|---|
| time | 数据记录的时间,是主索引(自动生成) |
| tags | 各种有索引的属性 |
| fields | 各种value值(没有索引的属性) |
- 此外,influxdb还有个特有的概念:series(一般由:retention policy, measurement, tagset就共同组成),其含义如下:
所有在数据库中的数据,都需要通过图表来展示,而这个series表示这个表里面的数据,可以在图表上画成几条线:通过tags排列组合算出来。 - 需要注意的是,influxdb不需要像传统数据库一样创建各种表,其表的创建主要是通过第一次数据插入时自动创建,如下:
insert mytest, server=serverA count=1,name=5 //自动创建表
“mytest”,“server” 是 tags,“count”、“name” 是 fields - fields 中的 value 基本不用于索引
- tag 只能为字符串类型
- field 类型无限制
- 不支持join
- 支持连续查询操作(汇总统计数据):CONTINUOUS QUERY
- 配合Telegraf服务(Telegraf可以监控系统CPU、内存、网络等数据)
- 配合Grafana服务(数据展现的图像界面,将influxdb中的数据可视化)
三、常见sql
-- 查看所有的数据库
show databases;
-- 使用特定的数据库
use database_name;
-- 查看所有的measurement
show measurements;
-- 查询10条数据
select * from measurement_name limit 10;
-- 数据中的时间字段默认显示的是一个纳秒时间戳,改成可读格式
precision rfc3339; -- 之后再查询,时间就是rfc3339标准格式
-- 或可以在连接数据库的时候,直接带该参数
influx -precision rfc3339
-- 查看一个measurement中所有的tag key
show tag keys
-- 查看一个measurement中所有的field key
show field keys
-- 查看一个measurement中所有的保存策略(可以有多个,一个标识为default)
show retention policies;
- 1) 基于时间序列,支持与时间有关的相关函数(如最大,最小,求和等);
- 2) 可度量性:你可以实时对大量数据进行计算;
- 3) 基于事件:它支持任意的事件数据;
- 4) 无结构(无模式):可以是任意数量的列;
- 5)支持min, max, sum, count, mean, median 等一系列函数;
- 6)内置http支持,使用http读写;
- 7)强大的类SQL语法;
- 8)自带管理界面,方便使用(新版本需要通过Chronograf)
四、 存储引擎
采用TSM存储引擎,TSM是在LSM的基础上优化改善的,引入了serieskey的概念,对数据实现了很好的分类组织。
TSM主要由四个部分组成: cache、wal、tsm file、compactor:
- cache:插入数据时,先往 cache 中写入再写入wal中,可以认为 cache 是 wal 文件中的数据在内存中的缓存,cache 中的数据并不是无限增长的,有一个 maxSize 参数用于控制当 cache 中的数据占用多少内存后就会将数据写入 tsm 文件。如果不配置的话,默认上限为 25MB
- wal:预写日志,对比MySQL的 binlog,其内容与内存中的 cache 相同,作用就是为了持久化数据,当系统崩溃后可以通过 wal 文件恢复还没有写入到 tsm 文件中的数据,当 InfluxDB 启动时,会遍历所有的 wal 文件,重新构造 cache。
- tsm file:每个 tsm 文件的大小上限是 2GB。当达到 cache-snapshot-memory-size,cache-max-memory-size 的限制时会触发将 cache 写入 tsm 文件。
- compactor:主要进行两种操作,一种是 cache 数据达到阀值后,进行快照,生成一个新的 tsm 文件。另外一种就是合并当前的 tsm 文件,将多个小的 tsm 文件合并成一个,减少文件的数量,并且进行一些数据删除操作。 这些操作都在后台自动完成,一般每隔 1 秒会检查一次是否有需要压缩合并的数据。
InfluxDB数据保留策略:
- 每个数据库刚开始会自动创建一个默认的存储策略 autogen,数据保留时间为永久,在集群中的副本个数为1,之后用户可以自己设置(查看、新建、修改、删除),例如保留最近2小时的数据。插入和查询数据时如果不指定存储策略,则使用默认存储策略,且默认存储策略可以修改。InfluxDB 会定期清除过期的数据。
- 每个数据库可以有多个过期策略:
show retention policies on "db_name" - Shard 在 influxdb中是一个比较重要的概念,它和 retention policy 相关联。每一个存储策略下会存在许多 shard,每一个 shard 存储一个指定时间段内的数据,并且不重复,例如 7点-8点 的数据落入 shard0 中,8点-9点的数据则落入 shard1 中。每一个 shard 都对应一个底层的 tsm 存储引擎,有独立的 cache、wal、tsm file。
这样做的目的就是为了可以通过时间来快速定位到要查询数据的相关资源,加速查询的过程,并且也让之后的批量删除数据的操作变得非常简单且高效。 - 建议在数据库建立的时候设置存储策略,不建议设置过多且随意切换
create database testdb2 with duration 30d
influxdb的数据存储有三个目录,分别是meta、wal、data:
- meta 用于存储数据库的一些元数据,meta 目录下有一个 meta.db 文件;
- wal 目录存放预写日志文件,以 .wal 结尾;
- data 目录存放实际存储的数据文件,以 .tsm 结尾。
五、 性能优化与go开发
- 控制 series 的数量;
- 使用批量写;
- 使用恰当的时间粒度;
- 存储的时候尽量对 Tag 进行排序;
- 根据数据情况,调整 shard 的 duration;
- 无关的数据写不同的database;
- 控制 Tag Key, 与 Tag Value 值的大小;
- 存储分离 ,将 wal 目录与 data 目录分别映射到不同的磁盘上,以减少读写操作的相互影响。
- go语言开发只需要一个依赖包:github.com/influxdata/influxdb/client/v2,需要注意是v1.8版本,直接clone会失败,
可先到:github.com/influxdata/influxdb中选择版本号V1.8,然后clone下载 - 对influxdb的操作主要有连接、插入、查询、关闭等几个步骤,其中查询的时候需要注意时间,要设置相应的时区,不然可能显示的时间结果不同
import (
"github.com/influxdata/influxdb/client/v2"
...
)
//连接influxdb
func ConnectInflux()(client.Client, error){
conn, err := client.NewHTTPClient(client.HTTPConfig{
Addr:"http://localhost:8086",
Username:username,
Password:password,
})
if nil != err{
fmt.Println(err)
return nil, err
}
return conn, nil
}
//写入point
func WritePoints(con client.Client)error{
batchpoint ,err := client.NewBatchPoints(client.BatchPointsConfig{
Precision:"s",
Database:MyDB,
})
if nil != err{
fmt.Println(err)
return err
}
record := Record{AssertId:"assert_aaaaa", ModelId:"model0", PoinntId:"point1",
ModelPath:"model0/model1/point1", Attr:"", ModelTime:"123456789"}
tags := map[string]string{Tag1:record.AssertId, Tag2:record.ModelId}
fields := map[string]interface{}{Field1:record.PoinntId, Field2:record.ModelPath,
Field3:record.Attr, Field4:record.ModelTime}
point, err := client.NewPoint(Measurement, tags, fields, time.Now())
if nil != err{
fmt.Println(err)
return err
}
batchpoint.AddPoint(point)
if err := con.Write(batchpoint); err != nil{
fmt.Println(err)
return err
}
}
//查询时要注意时区,东八区设置为:tz('Asia/Shanghai'),命令行需要:precision rfc3339
query := fmt.Sprintf("select * from %s limit %d tz('Asia/Shanghai')", Measurement, 5)
res, err := querydb(conn, query)
InfluxDB总结的更多相关文章
- 【容器云】十分钟快速构建 Influxdb+cadvisor+grafana 监控
本文作者:七牛云布道师@陈爱珍,DBAPlus社群联合发起人.前新炬技术专家.多年企业级系统的应用运维及分布式系统实战经验.现专注于容器.微服务及DevOps落地的研究与实践. 安装过程 三个都直接下 ...
- InfluxDB学习之InfluxDB数据保留策略(Retention Policies)
InfluxDB每秒可以处理成千上万条数据,要将这些数据全部保存下来会占用大量的存储空间,有时我们可能并不需要将所有历史数据进行存储,因此,InfluxDB推出了数据保留策略(Retention Po ...
- InfluxDB学习之InfluxDB的HTTP API查询操作
在 InfluxDB学习 的上一篇文章:InfluxDB学习之InfluxDB的HTTP API写入操作 中,我们介绍了使用InfluxDB的HTTP API进行数据写入操作的过程,本文我们再来介绍下 ...
- grafana + influxdb + telegraf , 构建性能监控平台
1.安装平台 1).grafana , 访问各类数据源 , 自定义报表.显示图表等等 , 用于提供界面监控 , 默认端口为3000 , 默认登陆信息admin wget https://grafana ...
- logstash输出到influxdb
用了这个logstash扩展 https://github.com/PeterPaulH/logstash-influxdb/blob/master/src/influxdb.rb 把这个文件放到 l ...
- Jmeter + Grafana + InfluxDB 性能测试监控
阅读目录 1. 安装InfluxDB 2. 安装Grafana 3. 配置Jmeter 序章 前几天在群里看到大神们在讨论Jmeter + InfluxDB + Grafana监控.说起来Jmeter ...
- InfluxDB学习系列教程,InfluxDB入门必备教程
nfluxDB是一个当下比较流行的时序数据库,InfluxDB使用 Go 语言编写,无需外部依赖,安装配置非常方便,适合构建大型分布式系统的监控系统. 本文是一系列InfluxDB学习教程的目录,现主 ...
- InfluxDB学习之InfluxDB连续查询(Continuous Queries)
在上一篇:InfluxDB学习之InfluxDB数据保留策略(Retention Policies) 中,我们介绍了 InfluxDB的数据保留策略,数据超过保存策略里指定的时间之后,就会被删除. 但 ...
- InfluxDB学习之InfluxDB的HTTP API写入操作
HTTP API也有两种操作:写入和查询,本文就先给大家介绍一下 InfluxDB的HTTP API的写入操作方式. 在InfluxDB学习的上一篇文章:InfluxDB学习之InfluxDB ...
- InfluxDB学习之InfluxDB的基本操作
InfluxDB提供类SQL语法,如果熟悉SQL的话会非常容易上手.本文就为大家介绍一下InfluxDB的基本操作. InfluxDB提供类SQL语法,如果熟悉SQL的话会非常容易上手. 本文 ...
随机推荐
- Win64 驱动内核编程-19.HOOK-SSDT
HOOK SSDT 在 WIN64 上 HOOK SSDT 和 UNHOOK SSDT 在原理上跟 WIN32 没什么不同,甚至说 HOOK 和 UNHOOK 在本质上也没有不同,都是在指定的地址上填 ...
- 【js】Leetcode每日一题-二叉树的堂兄弟节点
[js]Leetcode每日一题-二叉树的堂兄弟节点 [题目描述] 在二叉树中,根节点位于深度 0 处,每个深度为 k 的节点的子节点位于深度 k+1 处. 如果二叉树的两个节点深度相同,但 父节点不 ...
- (四)Jira Api对接:缺陷分析和任务分析
迭代进行期间或者结束后,在我们的测试日报或者测试报告中需要体现缺陷详细情况,甚至大家工作效率情况.本文就讨论下如何通过jira api获取缺陷信息并进行分析,同时获取需求子任务情况来了解测试和开发的工 ...
- C++ primer plus读书笔记——第11章 使用类
第11章 使用类 1. 运算符重载是一种形式的C++多态. 2. 不要返回指向局部变量或临时对象的引用.函数执行完毕后,局部变量和临时对象将消失,引用将指向不存在的数据. 3. 运算符重载的格式如下: ...
- 消息队列RabbitMQ(五):死信队列与延迟队列
死信队列 引言 死信队列,英文缩写:DLX .Dead Letter Exchange(死信交换机),其实应该叫做死信交换机才更恰当. 当消息成为Dead message后,可以被重新发送到另一个交换 ...
- [刷题] PTA 03-树3 Tree Traversals Again
用栈实现树遍历 1 #include<stdio.h> 2 #include<string.h> 3 #define MAXSIZE 30 4 5 int Pre[MAXSIZ ...
- [c++] 细节
\r退格:printf("asdflkj\r111")输出111flkj(https://blog.csdn.net/tyshtang/article/details/436770 ...
- vipivp常用linux命令
基础安装 # CentOS sudo yum install epel-release 命令行Tips 进程及端口 # 查看端口占用情况 netstat -ap | grep 端口号 # 查看某一 ...
- jmeter从安装到使用
最近,项目需要做接口测试,在python和jmeter之前选择,最终还是选择jmeter,虽然脚本管理及持续集成方面有所不便,但胜在使用简单,调试方便,方便后续做并发压力测试,而且最后的报告统计图表也 ...
- linux中级之防火墙的数据传输过程
网络数据传输过程 netfilter在数据包必须经过且可以读取规则的位置,共设有5个控制关卡.这5个关卡处的检查规则分别放在5个规则链中(有的叫钩子函数(hook functions).也就是说5条链 ...