机器学习——集成学习(Bagging、Boosting、Stacking)
1 前言
- 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器。弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测的分类器(errorrate < 0.5)。
- 集成算法的成功在于保证弱分类器的多样性(Diversity)。而且集成不稳定的算法也能够得到一个比较明显的性能提升。
- 集成学习可以用于分类问题集成,回归问题集成,特征选取集成,异常点检测集成等等,可以说所有的机器学习领域都可以看到集成学习的身影。
2 集成学习概述
- 常见的集成学习思想有∶
- Bagging
- Boosting
- Stacking
- 为什么需要集成学习?
- 弱分类器间存在一定的差异性 ,这会导致分类的边界不同,也就是说可能存在错误。那么将多个弱分类器合并后,就可以得到更加合理的边界,减少整体的错误率,实现更好的效果;
- 对于数据集过大或者过小,可以分别进行划分和有放回的操作产生不同的数据子集,然后使用数据子集训练不同的分类器,最终再合并成为一个大的分类器;
- 如果数据的划分边界过于复杂,使用线性模型很难描述情况,那么可以训练多个模型,然后再进行模型的融合;
- 对于多个异构的特征集的时候,很难进行融合,那么可以考虑每个数据集构建一个分模型,然后将多个模型融合。
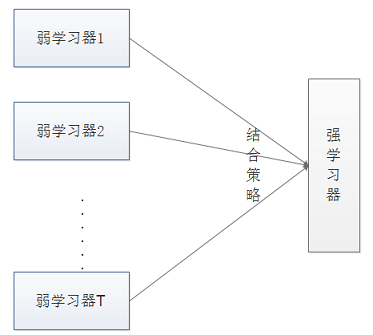
3 Bagging模型
Bagging 方法又叫做自举汇聚法(Bootstrap Aggregating),是一种并行的算法。
基本思想︰在原始数据集上通过有放回的抽样的方式,重新选择出 $T$ 个新数据集来分别训练 $T$ 个分类器的集成技术。也就是说这些模型的训练数据中允许存在重复数据。
Bagging 的特点在“随机采样”。随机采样(Bootsrap)就是从训练集里面采集固定个数的样本,但是每采集一个样本后,都将样本放回。也就是说,之前采集到的样本在放回后有可能继续被采集到。
Bagging的结合策略:对于分类问题,通常使用简单投票法,得到最多票数的类别或者类别之一为最终的模型输出。对于回归问题,通常使用简单平均法,对 $T$ 个弱学习器得到的回归结果进行算术平均得到最终的模型输出。
由于 Bagging 算法每次都进行采样来训练模型,因此泛化能力很强,对于降低模型的方差很有作用。当然对于训练集的拟合程度就会差一些,也就是模型的偏倚会大一些。
Bagging 方法的弱学习器可以是基本的算法模型,eg: Linear、Ridge、Lasso、Logistic、Softmax、ID3、C4.5、CART、SVM、KNN等。

Bagging对样本重采样,对每一轮的采样数据集都训练一个模型,最后取平均。由于样本集的相似性和使用的同种模型,因此各个模型的具有相似的 bias 和variance 。
$E({\large \frac{\sum_\limits {i=1}^{n}X_i}{n} } )=E(X_i)$
模型完全独立:
$Var({\large \frac{\sum_\limits {i=1}^{n}X_i}{n} } )={\large \frac{Var(X_i)}{n} } $
模型完全相同:
$Var({\large \frac{\sum_\limits {i=1}^{n}X_i}{n} } )=\large{Var(X_i)}$
随机森林是 Bagging 的一个特化进阶版,所谓的特化是因为随机森林的弱学习器都是决策树。所谓的进阶是随机森林在 Bagging 的样本随机采样基础上,又加上了特征的随机选择,其基本思想没有脱离 Bagging的范畴。Bagging 和随机森林算法的原理在后面的文章中会专门来讲。
4 随机森林(Random Forest)
在Bagging策略的基础上进行修改后的一种算法
- 从样本集中用Bootstrap采样选出 $n$ 个样本;
- 从所有属性中随机选择 $K$ 个属性,选择出最佳分割属性作为节点创建决策树;
- 重复以上两步 $m$ 次,即建立 $m$ 棵决策树;
- 这 $m$ 个决策树形成随机森林,通过投票表决结果决定数据属于那一类。
虽然抽样数据在一定程度上体现了全体样本数据的特性,所以可以用样本数据训练模型来预测其他的全体数据。但是数据与数据之间是存在差异性的,那么可以认为在拟合当前数据集的模型有可能出现不拟合生产环境中数据的情况,这就是过拟合。在决策树中,进行特征属性划分选择的时候,如果选择最优,表示这个划分在当前数据集上一定是最优的,但是不一定在全体数据中最优;在随机森林中,如果每个决策树都是选择最优的进行划分,就会导致所有子模型(内部的决策树)很大概率上会使用相同的特征属性进行数据的划分,不就会特别容易导致过拟合嘛,所以在随机森林中选择特征属性划分的时候一般使用随机的方式。
5 Boosting模型
在正式介绍Boosting思想之前,先介绍两个例子:
第一个例子:不知道大家有没有做过错题本,我们将每次测验的错的题目记录在错题本上,不停的翻阅,直到我们完全掌握。
第二个例子:对于一个复杂任务来说,将多个专家的判断进行适当的综合所作出的判断,要比其中任何一个专家单独判断要好。实际上这是一种“三个臭皮匠顶个诸葛亮的道理"。
这两个例子都说明Boosting的道理,也就是不错地重复学习达到最终的要求。
Boosting(提升学习)算法指将弱学习算法组合成强学习算法,它的思想起源于Valiant提出的PAC(Probably Approximately Correct)学习模型。可以用于回归和分类的问题。
Boosting: 是一种串行的算法,通过弱学习器开始加强,它每一步产生弱预测模型(如决策树),并加权累加到总模型中;如果每一步的弱预测模型的生成都是依据损失函数的梯度方式的,那么就称为梯度提升(Gradientboosting)。
基本思想:不同的训练集是通过调整每个样本对应的权重实现的,不同的权重对应不同的样本分布,而这个权重为分类器不断增加对错分样本的重视程度。
Boosting 的意义∶如果一个问题存在弱预测模型,那么可以通过提升技术的办法得到一个强预测模型;
常见的模型有:
- Adaboost
- Gradient Boosting(GBT/GBDT/GBRT)
基本步骤:
- 首先赋予每个训练样本相同的初始化权重,在此训练样本分布下训练出一个弱分类器;
- 利用该弱分类器更新每个样本的权重,分类错误的样本认为是分类困难样本,权重增加,反之权重降低,得到一个新的样本分布;
- 在新的样本分布下,在训练一个新的弱分类器,并且更新样本权重,重复以上过程T次,得到T个弱分类器。
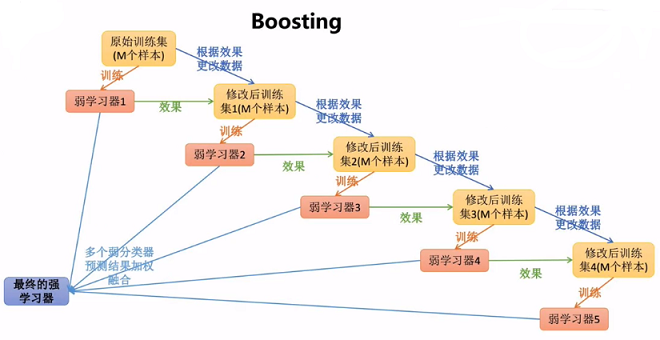
通过改变样本分布,使得分类器聚集在那些很难分的样本上,对那些容易错分的数据加强学习,增加错分数据的权重。这样错分的数据再下一轮的迭代就有更大的作用(对错分数据进行惩罚)。对于这些权重,一方面可以使用它们作为抽样分布,进行对数据的抽样;另一方面,可以使用权值学习有利于高权重样本的分类器,把一个弱分类器提升为一个强分类器。
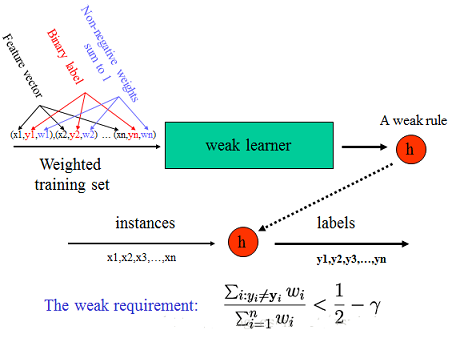
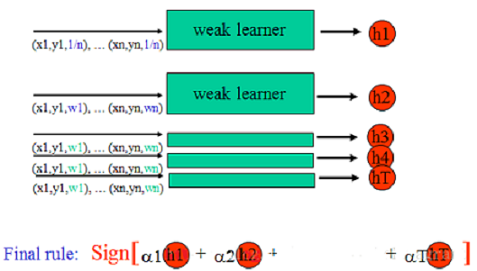
Boosting算法通过权重投票的方式将T个弱分类器组合成一个强分类器。只要弱分类器的分类精度高于50%,将其组合到强分类器里,会逐渐降低强分类器的分类误差。
由于Boosting将注意力集中在难分的样本上,使得它对训练样本的噪声非常敏感,主要任务集中在噪声样本上,从而影响最终的分类性能。
对于Boosting来说,有两个问题需要回答:一是在每一轮如何如何改变训练数据的概率分布;二是如何将多个弱分类器组合成一个强分类器。而且存在一个重大的缺陷:该分类算法要求预先知道弱分类器识别准确率的下限。
Boosting系列算法里最著名算法主要有AdaBoost算法和提升树(boosting tree)系列算法。提升树系列算法里面应用最广泛的是梯度提升树(Gradient Boosting Tree)。AdaBoost和提升树算法的原理在后面的文章中会专门来讲。
6 Bagging和Boosting的区别
1 样本选择︰Bagging算法是有放回的随机采样;Boosting算法是每一轮训练集不变,只是训练集中的每个样例在分类器中的权重发生变化,而权重根据上一轮的分类结果进行调整;
2 样例权重︰Bagging使用随机抽样,样例的权重;Boosting根据错误率不断的调整样例的权重值,错误率越大则权重越大;
3 预测函数︰Bagging所有预测模型的权重相等;Boosting算法对于误差小的分类器具有更大的权重;
4 并行计算︰Bagging算法可以并行生成各个基模型;Boosting理论上只能顺序生产,因为后一个模型需要前一个模型的结果;
5 Bagging是减少模型的variance(方差);Boosting是减少模型的Bias(偏度);
6 Bagging里每个分类模型都是强分类器,因为降低的是方差,方差过高需要降低是过拟合;Boosting里每个分类模型都是弱分类器,因为降低的是偏度,偏度过高是欠拟合。
7 Stacking模型
7.1 模型解释
Stacking是指训练一个模型用于组合(combine)其它模型(基模型/基学习器)的技术。即首先训练出多个不同的模型,然后再以之前训练的各个模型的输出作为输入来新训练一个新的模型,从而得到一个最终的模型。一般情况下使用单层的Logistic回归作为组合模型。
Stacking的过程图,如下:
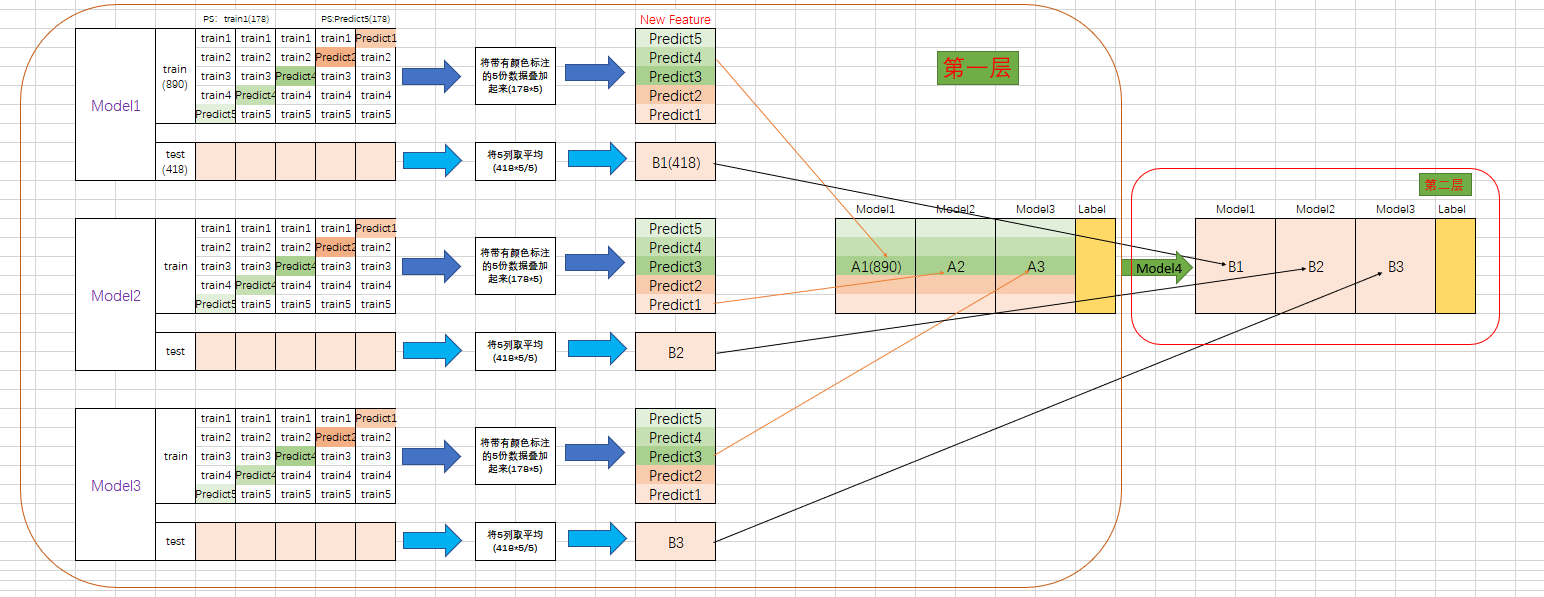
第一层
1、首先得到两组数据:训练集 train 和测试集 test。将训练集 train 分成5份:train1,train2,train3,train4,train5。
2、选定基模型。这里假定选择了 Model1 作为基模型。
在 Model1 模型部分:依次用 train1,train2,train3,train4,train5 作为验证集,其余4份作为训练集,进行5折交叉验证进行模型训练;
假定 tain 有890行数据,test 有 418 行数据。每个小 train(即train1,train2...)则有 890/5=178行数据。
对于每一轮的 5-fold,Model1 都要做满 5 次的训练和预测。用 Model1来训练 713 (=178*4) 行的小 train,然后预测 178 行 小test(Predict部分),预测的结果是长度为 178 的预测值。
执行5次,使用每次长度为 178 的预测值组合形成长度为 178 X 5 = 890 预测值,刚好和 train 长度吻合。这一步产生的预测值转成 890 X 1 (890 行,1列)的 New Feature,记作 A1。
3、再在测试集 test 上进行预测。
每一次的 fold,713 行的 小train 组合训练出来的 局部最优 Model1 要去预测全部的 test (418行数据)(因为 test 没有加入 5-fold,所以每次都是全部)。此时,Model1 的预测结果是长度为 418 的预测值。 执行 5 次,可以得到一个 5 X 418 的预测值。然后根据行来就平均值,最后得到一个 418 X 1 的平均预测值,记作 B1。
4、走到这里,第一层的 Model1完成了它的使命。
第一层还会有其他Model的,比如Model2,同样的走一遍, 可以得到 890 X 1 New Feature (A2) 和 418 X 1 ( B1 ) 列预测值。
这样吧,假设第一层有3个模型,这样你就会得到:
来自 5-fold 的预测值矩阵 890 X 3,(A1,A2,A3) 和 来自 test 预测值矩阵 418 X 3(B1, B2, B3)。
第二层
来自5-fold的 预测值矩阵 890 X 3 (A1,A2,A3)作为新的train Data,训练第二层的模型(Model4)。
来自 test Data 预测值矩阵 418 X 3 (B1, B2, B3) 就是新的test Data,用训练好的模型来预测。
7.2 Stacking注意事项
做Stacking模型融合时需要注意以下个点,我们拿2层stacking模型融合来举例子:
- 第一层的基模型最好是强模型,而第二层的基模型可以放一个简单的分类器,防止过拟合。
- 第一层基模型的个数不能太小,因为一层模型个数等于第二层分类器的特征维度。大家可以把勉强将其想象成神经网络的第一层神经元的个数,当然这个值也不是越多越好。
- 第一层的基模型必须准而不同",如果有一个性能很差的模型出现在第一层,将会严重影响整个模型融合的效果(笔者在实验过程中就遇到这样的坑)。
通过上述的描述,大家没有发现其实2层的stacking 其实和两层的神经网络有些相像,只不过stacking将神经网络第一层的神经元换成了强大的机器学习模型。
7.3 Stacking实验
数据准备


from sklearn.datasets import make_classification
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier as GBDT
from sklearn.ensemble import ExtraTreesClassifier as ET
from sklearn.ensemble import RandomForestClassifier as RF
from sklearn.ensemble import AdaBoostClassifier as ADA
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
import numpy as np
x,y = make_classification(n_samples=6000)
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.5)
定义第一层模型
由于Stacking的第一层最后选择比较强的模型,所以这里笔者选了四个本身就是集成模型的强模型,GBDT,RandomForest,ExtraTrees,和 Adaboost。
### 第一层模型
clfs = [ GBDT(n_estimators=100),
RF(n_estimators=100),
ET(n_estimators=100),
ADA(n_estimators=100)
]
X_train_stack = np.zeros((X_train.shape[0], len(clfs)))
X_test_stack = np.zeros((X_test.shape[0], len(clfs)))
数据输入第一层模型,输出即将喂给第二层模型特征
6折交叉验证,同时通过第一层的强模型训练预测生成喂给第二层的特征数据。
### 6折stacking
n_folds = 6
skf = StratifiedKFold(n_splits=n_folds, shuffle=True, random_state=1)
for i,clf in enumerate(clfs):
# print("分类器:{}".format(clf))
X_stack_test_n = np.zeros((X_test.shape[0], n_folds))
for j,(train_index,test_index) in enumerate(skf.split(X_train,y_train)):
tr_x = X_train[train_index]
tr_y = y_train[train_index]
clf.fit(tr_x, tr_y)
#生成stacking训练数据集
X_train_stack [test_index, i] = clf.predict_proba(X_train[test_index])[:,1]
X_stack_test_n[:,j] = clf.predict_proba(X_test)[:,1]
#生成stacking测试数据集
X_test_stack[:,i] = X_stack_test_n.mean(axis=1)
用第一层模型的输出特征,训练第二层模型
为了防止过拟合,第二层选择了一个简单的Logistics回归模型。输出Stacking模型的auc得分。
###第二层模型LR
clf_second = LogisticRegression(solver="lbfgs")
clf_second.fit(X_train_stack,y_train)
pred = clf_second.predict_proba(X_test_stack)[:,1]
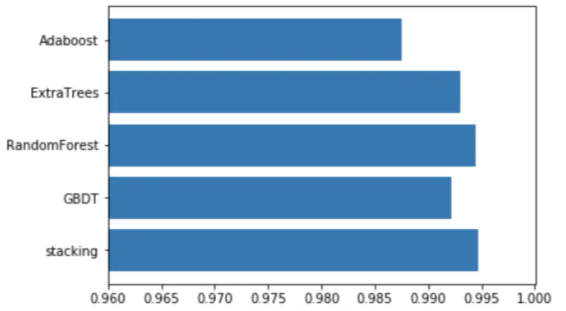
roc_auc_score(y_test,pred)#0.9946
同时笔者对比了第一层四个基模型的得分情况。
GBDT分类器性能
###GBDT分类器
clf_1 = clfs[0]
clf_1.fit(X_train,y_train)
pred_1 = clf_1.predict_proba(X_test)[:,1]
roc_auc_score(y_test,pred_1)#0.9922
随机森林分类器性能
###随机森林分类器
clf_2 = clfs[1]
clf_2.fit(X_train,y_train)
pred_2 = clf_2.predict_proba(X_test)[:,1]
roc_auc_score(y_test,pred_2)#0.9944
ExtraTrees分类器性能
ExtraTrees分类器性能
###ExtraTrees分类器
clf_3 = clfs[2]
clf_3.fit(X_train,y_train)
pred_3 = clf_3.predict_proba(X_test)[:,1]
roc_auc_score(y_test,pred_3)#0.9930
AdaBoost分类器性能
###AdaBoost分类器
clf_4 = clfs[3]
clf_4.fit(X_train,y_train)
pred_4 = clf_4.predict_proba(X_test)[:,1]
roc_auc_score(y_test,pred_4)#0.9875
8 集成学习之结合策略
本节就对集成学习之结合策略做一个总结。假定得到的 $T$ 个弱学习器是$\{h_1,h_2,...h_T\}$。
8.1 平均法
对于数值类的回归预测问题,通常使用的结合策略是平均法,即对于若干个弱学习器的输出进行平均得到最终的预测输出。
最简单的平均是算术平均,也就是说最终预测是
$H(x) = \frac{1}{T}\sum\limits_{1}^{T}h_i(x)$
如果每个弱学习器有一个权重$w$,则最终预测是
$H(x) = \sum\limits_{i=1}^{T}w_ih_i(x)$
其中 $w_i$ 是个体学习器 $h_i$ 的权重,通常有
$w_i \geq 0 ,\;\;\; \sum\limits_{i=1}^{T}w_i = 1$
8.2 投票法
对于分类问题的预测,通常使用的是投票法。假设预测类别是 $\{c_1,c_2,...c_K\}$ ,对于任意一个预测样本 $x$, $T$ 个弱学习器的预测结果分别是 $(h_1(x), h_2(x)...h_T(x))$。
稍微复杂的投票法是绝对多数投票法,也就是常说的要票过半数。在相对多数投票法的基础上,不光要求获得最高票,还要求票过半数。否则会拒绝预测。
更加复杂的是加权投票法,和加权平均法一样,每个弱学习器的分类票数要乘以一个权重,最终将各个类别的加权票数求和,最大的值对应的类别为最终类别。
8.3 学习法
投票法和平均法相对比较简单,但是可能学习误差较大,于是就有了学习法。对于学习法,代表方法是 Stacking,当使用 Stacking 的结合策略时, 不是对弱学习器的结果做简单的逻辑处理,而是再加上一层学习器,也就是说,将训练集弱学习器的学习结果作为输入,将训练集的输出作为输出,重新训练一个学习器来得到最终结果。
在这种情况下,将弱学习器称为初级学习器,将用于结合的学习器称为次级学习器。对于测试集,首先用初级学习器预测一次,得到次级学习器的输入样本,再用次级学习器预测一次,得到最终的预测结果。
机器学习——集成学习(Bagging、Boosting、Stacking)的更多相关文章
- [机器学习]集成学习--bagging、boosting、stacking
集成学习简介 集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务. 如何产生"好而不同"的个体学习器,是集成学习研究的核心. 集成学习的思路是通过 ...
- 机器学习入门-集成算法(bagging, boosting, stacking)
目的:为了让训练效果更好 bagging:是一种并行的算法,训练多个分类器,取最终结果的平均值 f(x) = 1/M∑fm(x) boosting: 是一种串行的算法,根据前一次的结果,进行加权来提高 ...
- 机器学习——集成学习之Boosting
整理自: https://blog.csdn.net/woaidapaopao/article/details/77806273?locationnum=9&fps=1 AdaBoost GB ...
- 集成学习---bagging and boosting
作为集成学习的二个方法,其实bagging和boosting的实现比较容易理解,但是理论证明比较费力.下面首先介绍这两种方法. 所谓的集成学习,就是用多重或多个弱分类器结合为一个强分类器,从而达到提升 ...
- 机器学习:集成学习:随机森林.GBDT
集成学习(Ensemble Learning) 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测 ...
- 集成学习之Boosting —— Gradient Boosting原理
集成学习之Boosting -- AdaBoost原理 集成学习之Boosting -- AdaBoost实现 集成学习之Boosting -- Gradient Boosting原理 集成学习之Bo ...
- 集成学习二: Boosting
目录 集成学习二: Boosting 引言 Adaboost Adaboost 算法 前向分步算法 前向分步算法 Boosting Tree 回归树 提升回归树 Gradient Boosting 参 ...
- 集成学习之Boosting —— XGBoost
集成学习之Boosting -- AdaBoost 集成学习之Boosting -- Gradient Boosting 集成学习之Boosting -- XGBoost Gradient Boost ...
- 集成学习之Boosting —— AdaBoost实现
集成学习之Boosting -- AdaBoost原理 集成学习之Boosting -- AdaBoost实现 AdaBoost的一般算法流程 输入: 训练数据集 \(T = \left \{(x_1 ...
随机推荐
- 高楼扔鸡蛋问题(鹰蛋问题) POJ-3783
这是一道经典的DP模板题. https://vjudge.net/problem/POJ-3783#author=Herlo 一开始也是不知道咋写,尝试找了很多博客,感觉有点领悟之后写下自己的理解. ...
- linux 高并发socket通信模型
------select 1 一个误区很多人认为它最大可以监听1024个,实际上却是文件描述符的值不能大于等于1024,所以除掉标准输入.输出.错误输出,一定少于1024个,如果在之前还打开了其他文件 ...
- 树莓派远程连接工具SSH使用教程
树莓派远程连接工具SSH使用教程 树莓派 背景故事 树莓派作为一款迷你小主机,大部分的使用场景都会用到远程调试,远程调试用到最多的方式一般就是VNC和SSH,SSH就是命令行型的远程方式,简单来说就是 ...
- Pikachu-暴力破解模块
一.概述 "暴力破解"是一攻击具手段,在web攻击中,一般会使用这种手段对应用系统的认证信息进行获取. 其过程就是使用大量的认证信息在认证接口进行尝试登录,直到得到正确的结果. 为 ...
- 详解C#中 Thread,Task,Async/Await,IAsyncResult的那些事儿
说起异步,Thread,Task,async/await,IAsyncResult 这些东西肯定是绕不开的,今天就来依次聊聊他们 1.线程(Thread) 多线程的意义在于一个应用程序中,有多个执行部 ...
- C# 正则表达式的重点知识 1
- sql 中的with 语句使用
一直以来都很少使用sql中的with语句,但是看到了一篇文章中关于with的使用,它的确蛮好用,希望以后记得使用这个语句.一.with 的用法With alias_name as (select1)[ ...
- Spring整合Quartz轻松完成定时任务
一.背景 上次我们介绍了如何使用Spring Task进行完成定时任务的编写,这次我们使用Spring整合Quartz的方式来再一次实现定时任务的开发,以下奉上开发步骤及注意事项等. 二.开发环境及必 ...
- ubuntu18.04 开机启动/停止服务
ubuntu18.04 开机启动/停止服务 一.删除一个服务 如果要删除一个服务,使用uodate-rc.d(参数-f是强制删除符号链接) update-rc.d -f apache2 remove ...
- 了解Flask
了解Flask 什么是Flask Flask 是一个微框架(Micro framework),所谓微框架,它就是很轻量级的,作者划分出了Flask应该负责什么(请求路由.处理请求.返回响应).不应该负 ...