ES读写数据的工作原理
es写入数据的工作原理是什么啊?es查询数据的工作原理是什么?底层的lucence介绍一下呗?倒排索引了解吗?
一、es写数据过程
1、客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点)
2、coordinating node 对document进行路由,将请求转发给对应的node(有primary shard)
3、实际的node上的primary shard 处理请求,然后将数据同步到replica node。
4、coordinating node如果发现 primary node和所有replica node都搞定之后,就返回响应结果给客户端。
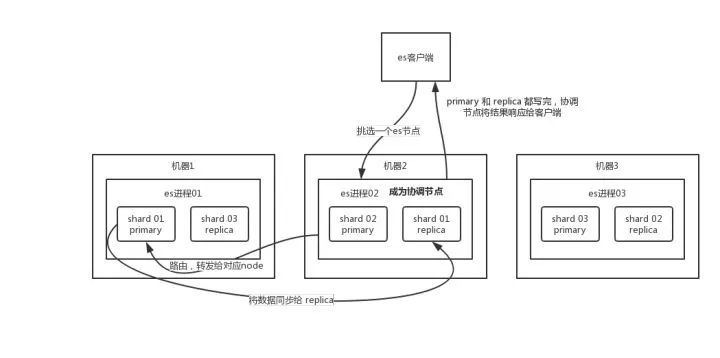
二、es读数据过程
可以通过doc id 来查询,会根据doc id进行hash,判断出来当时把doc id分配到了哪个shard上面去,从那个shard去查询。
1、客户端发送请求到任意一个node,成为coordinate node
2、coordinate node 对doc id进行哈希路由,将请求转发到对应node,此时会使用round-robin随机轮询算法,在primary shard 以及其所有replica中随机选择一个,让读请求负载均衡。
3、接收请求的node返回document给coordinate node。
4、coordinate node返回document给客户端。
三、es搜索数据过程
es最强大的是做全文检索
1、客户端发送请求到一个coordinate node。
2、协调节点将搜索请求转发到所有的shard对应的primary shard 或 replica shard ,都可以。
3、query phase:每个shard将自己的搜索结果(其实就是一些doc id)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。
4、fetch phase:接着由协调节点根据doc id去各个节点上拉取实际的document数据,最终返回给客户端。
写请求是写入primary shard,然后同步给所有的replica shard
读请求可以从primary shard 或者 replica shard 读取,采用的是随机轮询算法。

四、写数据底层原理
1、先写入内存buffer,在buffer里的时候数据是搜索不到的;同时将数据写入translog日志文件。
如果buffer快满了,或者到一定时间,就会将内存buffer数据refresh 到一个新的segment file中,但是此时数据不是直接进入segment file磁盘文件,而是先进入
os cache。这个过程就是 refresh。
每隔1秒钟,es将buffer中的数据写入一个新的segment file,每秒钟会写入一个新的segment file,这个segment file中就存储最近1秒内 buffer中写入的数据。
2、但是如果buffer里面此时没有数据,那当然不会执行refresh操作,如果buffer里面有数据,默认1秒钟执行一次refresh操作,刷入一个新的segment file中。
操作系统里面,磁盘文件其实都有一个东西,叫做os cache,即操作系统缓存,就是说数据写入磁盘文件之前,会先进入os cache,先进入操作系统级别的
一个内存缓存中去。只要buffer中的数据被refresh 操作刷入os cache中,这个数据就可以被搜索到了。
3、为什么叫es是准实时的?NRT,全称 near real-time。默认是每隔1秒refresh一次的,所以es是准实时的,因为写入的数据1s之后才能被看到。
可以通过es的restful api或者 java api,手动执行一次 refresh操作,就是手动将buffer中的数据刷入os cache中,让数据立马就可以被搜索到。只要
数据被输入os cache中,buffer 就会被清空了,因为不需要保留buffer了,数据在translog里面已经持久化到磁盘去一份了。
4、重复上面的步骤,新的数据不断进入buffer和translog,不断将buffer数据写入一个又一个新的segment file中去,每次refresh完buffer清空,translog保留。
随着这个过程的推进,translog会变得越来越大。当translog达到一定长度的时候,就会触发commit操作。
5、commit操作发生的第一步,就是将buffer中现有的数据refresh到os cache中去,清空buffer。然后将一个commit point写入磁盘文件,里面标识者这个commit
point 对应的所有segment file,同时强行将os cache中目前所有的数据都fsync到磁盘文件中去。最后清空现有 translog日志文件,重启一个translog,此时commit操作完成。
6、这个commit操作叫做flush。默认30分钟自动执行一次flush,但如果translog过大,也会触发flush。flush操作就对应着commit的全过程,我们可以通过es api,手动执行
flush操作,手动将os cache中数据fsync强刷到磁盘上去。
7、translog日志文件的作用是什么?
执行commit 操作之前,数据要么是停留在buffer中,要么是停留在os cache中,无论是buffer 还是os cache都是内存,一旦这台机器死了,内存中的数据就全丢了。
所以需要将数据对应的操作写入一个专门的日志文件translog中,一旦此时机器宕机了,再次重启的时候,es会自动读取translog日志文件中的数据,恢复到内存buffer
和os cache中去。
8、translog其实也是先写入os cache的,默认每隔5秒刷一次到磁盘中去,所以默认情况下,可能有5s的数据会仅仅停留在buffer或者translog文件的os cache中,如果
此时机器挂了,会丢失5秒钟的数据。但是这样性能比较好,最多丢5秒的数据。
也可以将translog设置成每次写操作必须是直接fsync到磁盘,但是性能会差很多。
9、es第一是准实时的,数据写入1秒后就可以搜索到:可能会丢失数据的。有5秒的数据,停留在buffer、translog os cache 、segment file os cache中,而不在磁盘上,
此时如果宕机,会导致5秒的数据丢失。
10、总结::数据先写入内存buffer,然后每隔1s,将数据refresh到 os cache,到了 os cache数据就能被搜索到(所以我们才说es从写入到能被搜索到,中间有1s的延迟)。
每隔5s,将数据写入到translog文件(这样如果机器宕机,内存数据全没,最多会有5s的数据丢失),translog达到一定程度,或者默认每隔30min,会触发commit操作,将缓冲区的
数据都flush到segment file磁盘文件中。
数据写入 segment file之后,同时就建立好了倒排索引。
五、删除/更新数据底层原理
如果是删除操作,commit的时候会生成一个 .del文件,里面将某个doc标识为 deleted状态,那么搜索的时候根据 .del文件就知道这个doc是否被删除了。
如果是更新操作,就是将原来的doc标识为deleted状态,然后重新写入一条数据。
buffer 每refresh一次,就会产生一个segment file,所以默认情况下是1秒钟一个segment file,这样下来segment file会越来越多,此时会定期执行merge。
每次merge的时候,会将多个segment file合并成一个,同时这里会将标识为 deleted的doc给物理删除掉,然后将新的segment file写入磁盘,这里会写一个
commit point,标识所有新的 segment file,然后打开segment file供搜索使用,同时删除旧的segment file。
六、底层lucence
简单来说,lucence就是一个jar包,里面包含了封装好的各种建立倒排索引的算法代码。我们用java 开发的时候,引入 lucene jar,然后基于lucene的api去开发
就可以了。
通过lucene,我们可以将已有的数据建立索引,lucene会在本地磁盘上面,给我们组织索引的数据结果。
ES读写数据的工作原理的更多相关文章
- ES读写数据过程及原理
ES读写数据过程及原理 倒排索引 首先来了解一下什么是倒排索引 倒排索引,就是建立词语与文档的对应关系(词语在什么文档出现,出现了多少次,在什么位置出现) 搜索的时候,根据搜索关键词,直接在索引中找到 ...
- 面试系列八 es写入数据的工作原理
(1)es写数据过程 1)客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点) 2)coordinating node,对document进行路由,将请求 ...
- ElasticSearch写入数据的工作原理是什么?
面试题 es 写入数据的工作原理是什么啊?es 查询数据的工作原理是什么啊?底层的 lucene 介绍一下呗?倒排索引了解吗? 面试官心理分析 问这个,其实面试官就是要看看你了解不了解 es 的一些基 ...
- HADOOP1.X中HDFS工作原理
转载自:http://www.daniubiji.cn/archives/596 HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据googl ...
- 【ElasticSearch】ES 读数据,写数据与搜索数据的过程
ES读数据的过程: 1.ES客户端选择一个node发送请求,该请求作为协调节点(coordinating node): 2.corrdinating node 对 doc id 对哈希,找出该文档对应 ...
- 大数据 --> 分布式文件系统HDFS的工作原理
分布式文件系统HDFS的工作原理 Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数 ...
- HBase 架构与工作原理3 - HBase 读写与删除原理
本文系转载,如有侵权,请联系我:likui0913@gmail.com 一.前言 在 HBase 中,Region 是有效性和分布的基本单位,这通常也是我们在维护时能直接操作的最小单位.比如当一个集群 ...
- 《浏览器工作原理与实践》 <12>栈空间和堆空间:数据是如何存储的?
对于前端开发者来说,JavaScript 的内存机制是一个不被经常提及的概念 ,因此很容易被忽视.特别是一些非计算机专业的同学,对内存机制可能没有非常清晰的认识,甚至有些同学根本就不知道 JavaSc ...
- 【夯实Nginx基础】Nginx工作原理和优化、漏洞
本文地址 原文地址 本文提纲: 1. Nginx的模块与工作原理 2. Nginx的进程模型 3 . NginxFastCGI运行原理 3.1 什么是 FastCGI ...
随机推荐
- Java 获取Word中指定图片的坐标位置
本文介绍通过Java程序获取Word文档中指定图片的坐标位置. 程序运行环境: Word测试文档:.docx 2013 Free Spire.doc.jar 3.9.0 IntelliJ IDEA J ...
- Java 将Word转为XML,XML转为Word的方法
本文介绍将Word和XML文档进行双向互转的方法.转换时,Word支持.docx/.doc等格式. 代码环境如下: Word测试文档:.docx或.doc 编译环境:IntelliJ IDEA JDK ...
- SetupDi系列函数
SetupDiClassGuidsFromName WINSETUPAPI BOOL SetupDiClassGuidsFromNameA( PCSTR ClassName, LPGUID Class ...
- xmind8-update9 安装破解激活教程
xmind8是一款原型图设计流行的软件,相比于xmind2020功能更为丰富,比如画甘特图等.本教程来教大家如何对xmind8 update9进行安装激活,使用全部功能,无限期使用! 只看本文一篇即可 ...
- Spring Cloud专题之五:config
书接上回: SpringCloud专题之一:Eureka Spring Cloud专题之二:OpenFeign Spring Cloud专题之三:Hystrix Spring Cloud 专题之四:Z ...
- WIN XP SP2系统经常性死机问题解决历程
如题: 1.初始时,XP还能进入系统,等系统3分钟左右,鼠标熄灭,键盘无反应,查看资源管理器CPU 100%,内存占用不高. 2.现象初步分析: a.怀疑是病毒占用CPU 100%,于是下载360安全 ...
- linux下利用JMX监控Tomcat
利用JMX监控Tomcat,就是相当于部署在tomcat上的应用作为服务端,也就是被管理资源的对象.然后通过程序或者jconsole远程连接到该应用上来.远程连接需要服务器端提供ip和port.如果需 ...
- Java 中节省 90% 时间的常用的工具类
前言 你们有木有喜欢看代码的领导啊,我的领导就喜欢看我写的代码,有事没事就喜欢跟我探讨怎么写才最好,哈哈哈...挺好. 今天我们就一起来看看可以节省 90% 的加班时间的第三方开源库吧,第一个介绍的必 ...
- VSCode远程免密登录
VSCode远程免密登录 本地生成密钥 生成命令如下: ssh-keygen -t rsa 会生成id_rsa, id_rsa.pub两个文件 公钥拷贝到服务器 将公钥id_rsa.pub拷贝到服务器 ...
- BUUCTF-[HCTF 2018]admin(Unicode欺骗&伪造session)
目录 方法一:Unicode欺骗 方法二:伪造session 参考文章 记一道flask下session伪造的题. 方法一:Unicode欺骗 拿到题目f12提示you are not admin,显 ...