WebGPU性能测试分析
大家好,本文对WebGPU进行性能测试和分析,目的是为了对比WebGL和WebGPU在“渲染”和“计算”两个维度的性能差异,具体表现为CPU性能和FPS性能两个方面的性能数据差异。
我们会分别在苹果笔记本和配备RTX显卡的台式机上,对WebGL和WebGPU分别进行性能测试。
本文对于WebGPU使用了“reuse render command buffer”和“dynamic uniform buffer offset”两种优化,相关介绍可以参考WebGPU学习(十一):学习两个优化:“reuse render command buffer”和“dynamic uniform buffer offset”。
本文只使用了WebGPU的基础能力,还没有使用更高级的特性(如draw indirect、多线程渲染等),所以理论上WebGPU相比WebGL的性能优势还可以进一步地扩大。
测试的代码
测试的代码在Github上
测试结论
这里先给出最后的测试结论:
- 在“渲染”性能上,WebGPU比WebGL快3倍以上
- 在“计算”性能上,WebGPU比WebGL快50倍以上
测试环境
设备一:13“MacBook M1 Pro
操作系统:Mac OS Big Sur
设备二:配备RTX显卡的台式机(i7-4790+ RTX 2060 Super)
操作系统:Win10 64位
WebGL运行的浏览器:Chrome(版本 91.0.4472.114(正式版本))
WebGPU运行的浏览器:Chrome Canary(v93.0)
测试“渲染”的性能
场景描述
该场景的设计思路为:
在固定分辨率的屏幕当中,用WebGL和WebGPU去渲染相同个数的固定大小的三角形,三角形个数从小到大进行递增,三角形颜色都为随机的灰度颜色;
每一帧提交对应三角形个数的DrawCall进行重绘(一个三角形对应一次DrawCall)(这里的每个三角形可看为场景中的一个物体。实际场景中的物体通常由几百上千个三角形组成,但是此处为了简化和突出性能测试的重点,所以一个物体只由一个三角形组成)。
为了能更好的体现重绘的效果,我们在距离+Z轴方向(指向屏幕的方向)的最近的1000个三角形中,随机选取了100个,进行Z轴方向的移动,表现效果为三角形的闪烁。这也符合实际的渲染场景中的情况:大部分物体并不是在每一帧都进行数据改变,只有部分会发生数据变化(这个场景中体现为三角形在Z轴方向的位置移动)。
具体的场景效果如下图:
渲染场景
结果分析
1)硬件环境为13”MacBook M1:
- 影响CPU性能的因素: CPU传递DrawCall时间
- WebGL:5000个DrawCall命令以内时,CPU在10ms以内可以将其全部发送给GPU进行绘制。可以看出CPU并没有进行等待,原因是GPU在绘制5000个DrawCall命令以内时,完成速度很高,并不需要CPU等待。但是超过5000个DrawCall命令时,CPU的耗时明显增加,而且成线性增长。原因是,在WebGL下,每一个DrawCall命令都必须由CPU传递给GPU进行绘制执行,一旦GPU绘制无法在相应时间内完成,就会要求CPU等待。GPU完成绘制所需时间越长,CPU等待时间就越长,所以造成超过5000个DrawCall命令时,CPU的耗时等待时间线性增加。
- WebGPU:在测试范围内,CPU耗时几乎保持不变。原因是WebGPU标准定义了绘制缓存机制(GPURenderBundle),只需在初始化时提交一次进行缓存,后面就不需要再由CPU发送DrawCall绘制命令给GPU,而是GPU直接在缓存中读取绘制命令并进行绘制。因此可以看出WebGPU通过绘制缓存机制,巨大地释放了CPU线程的运算负担,极大地提高了性能。
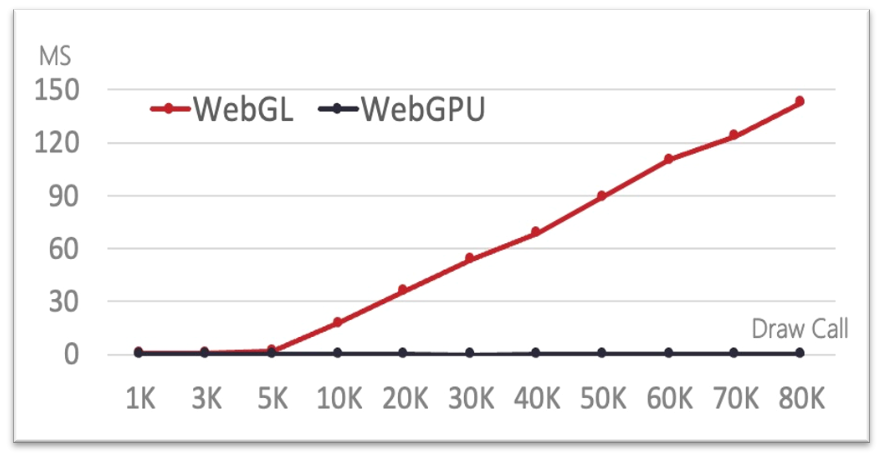
M1配置下渲染场景中CPU耗时性能对比
- 影响FPS性能的因素:CPU传递DrawCall时间+GPU时间
WebGL:5000个DrawCall命令以内,可以保持在60FPS的状态。但是当DrawCall超过5000时,性能成反比例函数曲线下降。因为当CPU发送DrawCall给GPU,时间成线性升高时,FPS的时间被此线性时间影响且成倒数关系。当超过一定的DrawCal数量时,甚至出现了测试崩溃(大于72000个DrawCall)。
WebGPU:由于缓存机制,极大的减少了影响FPS最大的权重时间,即“CPU传递DrawCall时间”。因此可以在相对大量的DrawCall发送测试下,保持在较高的60FPS状态。但是当测试达到74000个DrawCall时,也会出现FPS下降,这是因为硬件的GPU已经无法满足运算绘制的要求。
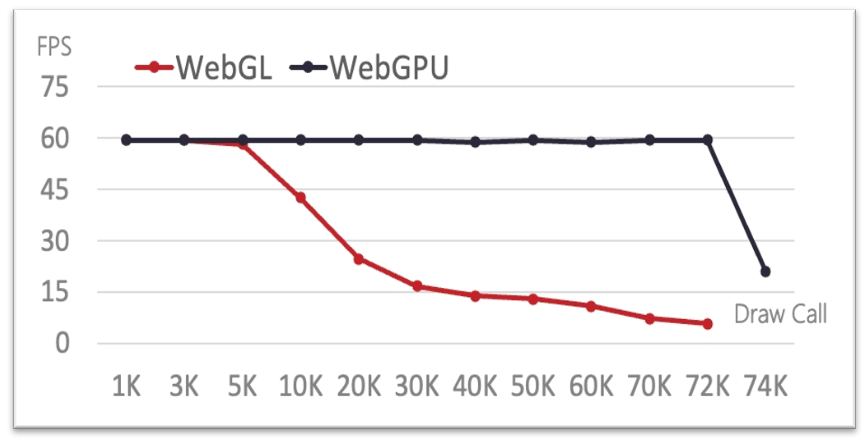
M1配置下渲染场景中FPS对比
2)硬件环境为台式机i7-4790 + RTX 2060 Super
- 影响CPU性能的因素 CPU传递DrawCall时间
- WebGL:1000个DrawCall命令以内,CPU全部发送给GPU进行绘制时,可以看出CPU并没有进行等待,耗时都控制在10ms以内。然后超过1000个以后, CPU的耗时明显增加,而且成线性增长。其整体趋势和M1环境下对比分析相同。但是由于M1环境的CPU性能更好,所以M1在5000以后才表现出CPU耗时线性增加,而台式机在1000的时候已经开始表现出CPU耗时线性增加了。
- WebGPU:在测试范围内,CPU耗时几乎保持不变。原因与M1环境下的原因相同。因此无论是在M1环境还是在台式机环境,由于缓存机制,可以看出WebGPU,都可以大量的释放了CPU线程的运算负担,进而提高性能。

台式机配置下渲染场景中CPU耗时性能对比
- 影响FPS性能的因素:CPU传递DrawCall时间+GPU时间
- WebGL:30000个DrawCall命令以内,可以保持在60FPS的状态,而M1只能在5000以内,才可以维持60FPS状态,可以看出台式机的RTX显卡明显好于M1的显卡。但是当DrawCall超过30000时,性能成反比例函数曲线下降。原因与M1环境下的原因相同
- WebGPU:其整体趋势和M1环境下对比分析相同。当测试达到82000个DrawCall时,也会出现FPS下降,这是因为硬件的RTX显卡也已经无法满足运算绘制的要求。
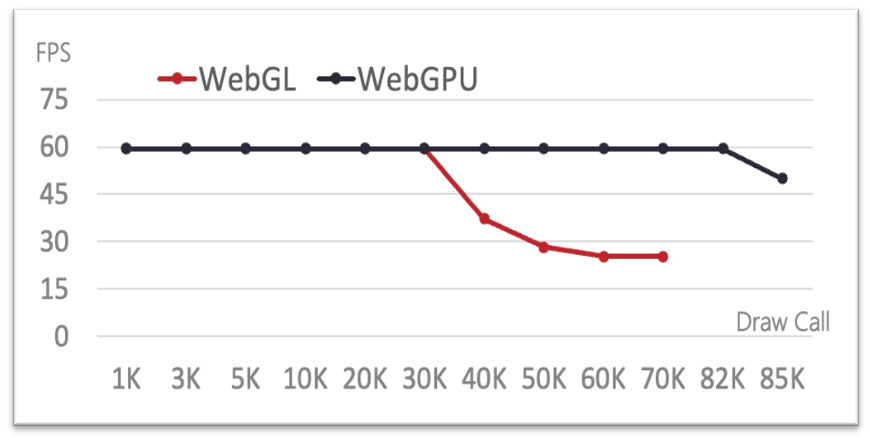
台式机配置下渲染场景中FPS对比
测试结论
在当前渲染场景的测试中得出如下结论:
- 由于WebGPU采用了缓存机制,可以避免CPU发送DrawCall指令所带来的等待时间消耗,显著提升CPU的工作效率。相比较WebGL,WebGPU在M1配置下渲染性能提升3倍,台式机i7-4790 + RTX 2060 Super配置下渲染性能提升15倍。
- 如果不使用WebGPU的缓存机制,那么WebGPU的渲染性能只比WebGL快3%左右,两者相差不大。这是为什么呢?这是因为对于WebGPU和WebGL,在GPU端都是通过光栅化管线来渲染,所以两者在GPU时间上都是一样的,不一样的点就在于CPU传递DrawCall时间。然而如果WebGPU不使用缓存机制,那么WebGPU与WebGL一样,每帧都需要在CPU端发送每个DrawCall指令,所以导致两者在CPU传递DrawCall时间上也几乎一样。
- CPU性能对比中,WebGL下,M1配置的CPU耗时参数优于台式机的CPU耗时参数,因此台式机CPU(i7-4790)性能表现不如M1芯片性能。但是在FPS性能对比中,WebGL下台式机的RTX显卡性能明显优与M1芯片。但是不论硬件配置如何,CPU性能的表现和FPS性能的表现,在WebGL下和WebGPU下,整体变化趋势一致。WebGPU性能整体明显优与WebGL性能。
分析Babylonjs关于WebGPU和WebGL的渲染性能对比的Demo
从From WebGL to WebGPU: A perspective from Babylon js by David Catuhe视频的12:51开始,演示了WebGPU和WebGL的渲染性能对比的Demo(WebGPU应该也采用了缓存机制),下面我们来详细分析下差异的原理:

如上图所示,我们看到在当前场景中,两者的FPS差不多,这是为什么呢?
我们已经知道,影响FPS性能的因素为:CPU传递DrawCall时间+GPU时间
目前在屏幕上绘制的物体较少,所以DrawCall次数很少,所以CPU传递DrawCall时间很少;
所以一帧的时间主要花费在GPU时间上。然而对于WebGPU和WebGL,在GPU端都是通过光栅化管线来渲染,所以两者在GPU时间上都是一样的。
所以综上所述,两者的FPS应该是差不多的。
下面看另外的一个场景:
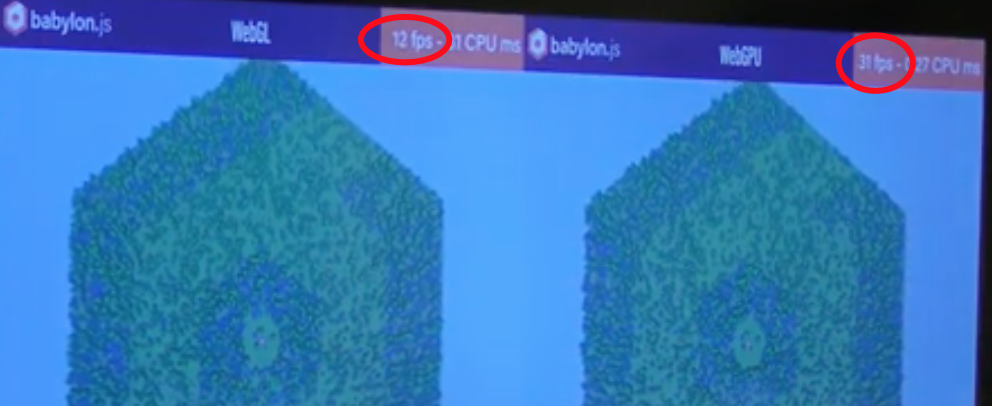
现在因为相机拉的非常远,所以在屏幕上绘制的物体非常多,所以DrawCall次数很多,所以CPU传递DrawCall时间很大,所以使用缓存机制的WebGPU的性能优势就体现出来了。
WebGPU比WebGL快了3倍左右,这与我们的测试结果差不多。
测试“计算”的性能
场景描述
该场景的设计思路为:
在固定分辨率的屏幕当中,用WebGL和WebGPU计算和渲染相同个数的固定大小三角形,三角形个数从小到大进行递增;
所有的三角形首先通过计算算法计算出每个三角形在场景中的位置,然后通过一次DrawCall(Instancing)渲染到屏幕中。
此算法的思路是:每一个三角形的位置的获得都需要遍历场景中其他所有三角形的位置,最终算法会收敛成为三角形群聚现象,模拟类似于鸟群的飞行状态。这里需要特殊说明,算法本身只是为了体现测试场景的计算量,不同的算法并不会对测试结果的整体趋势产生任何影响。
具体的场景效果如下图:
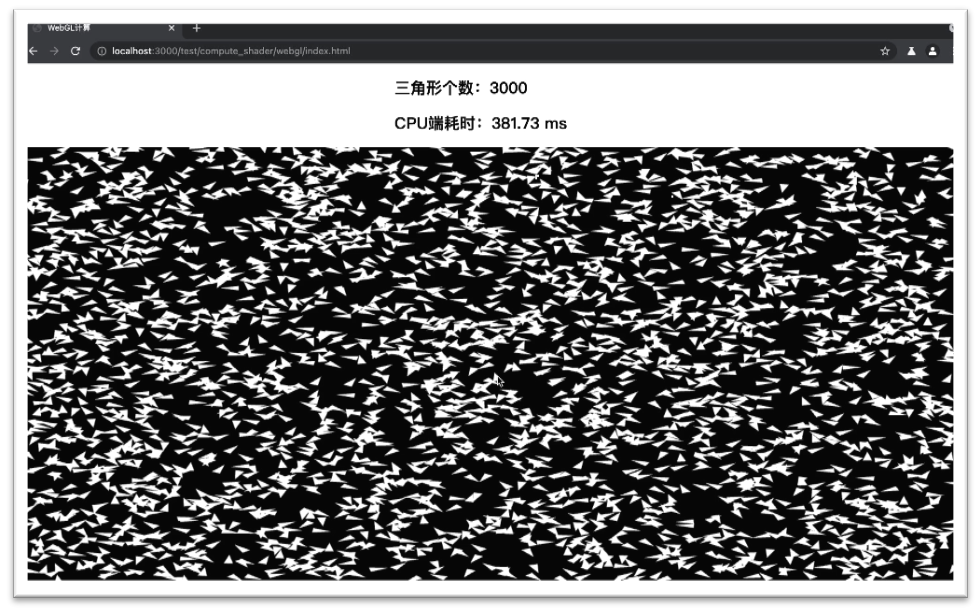
渲染场景收敛前
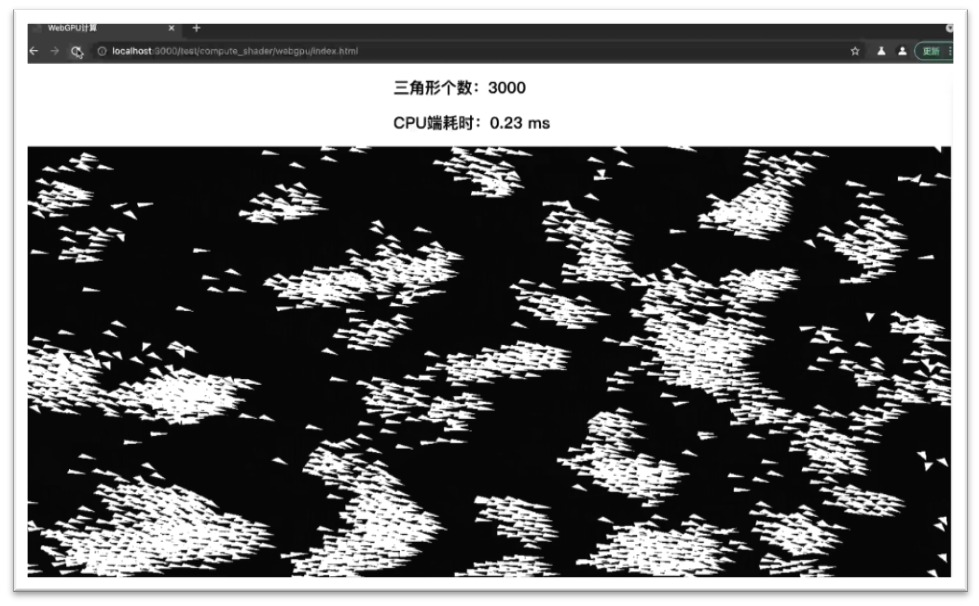
渲染场景收敛后
结果分析
1)硬件环境为13”MacBook M1:
- 影响CPU性能的因素:CPU计算时间(因为只有一次DrawCall,所以“CPU传递DrawCall时间”几乎为0,故该项忽略不计)
- WebGL:物体数量低于500时,在计算每一个物体的位置和运动轨迹时,虽然需要遍历其他所有三角形的状态(测试算法的效果),但是由于物体数量较少,CPU的计算任务仍然可以在16ms以内完成。但是超过500个物体后,CPU的耗时明显增加。原因是,CPU的主要运算时间都在计算物体在下一时刻的位置,随着物体数量的增加,需要遍历的次数也随之线性增加。
- WebGPU:在测试范围内,CPU耗时几乎为0。原因是WebGPU标准定义了计算着色器(Compute Shader),使得WebGPU可以将所有的计算任务全部交给GPU的Compute Shader来完成,而不需要CPU参与计算任务。因此可以看出WebGPU,在计算场景中,同样释放了CPU的运算负担,极大得提高了性能。

M1配置下计算场景中CPU耗时性能对比
- 影响FPS性能的因素:CPU计算时间 + GPU时间
- WebGL:物体数量低于500时,几乎可以保持在60FPS的状态。但是当物体数量超过500时,FPS表现迅速下降。因为CPU大量的时间都消耗在了计算每个物体的位置上,随着物体数量的增加,需要遍历的物体越多,因此计算耗时越多,帧率下降明显。而且当超过一定物体数量时,由于计算量过大,出现了测试崩溃(大于3000个物体)。
- WebGPU:由于有了计算着色器(Compute Shader),所以所有的计算都交给了GPU去完成。由于GPU的Compute Shader具有并行计算的特征,可以非常快地完成这种复杂的计算任务,因此FPS可以大部分时间都保持在60FPS的状态。但是当测试达到15000个物体时,也达到了M1的GPU运算能力上限,因此也会出现FPS下降。
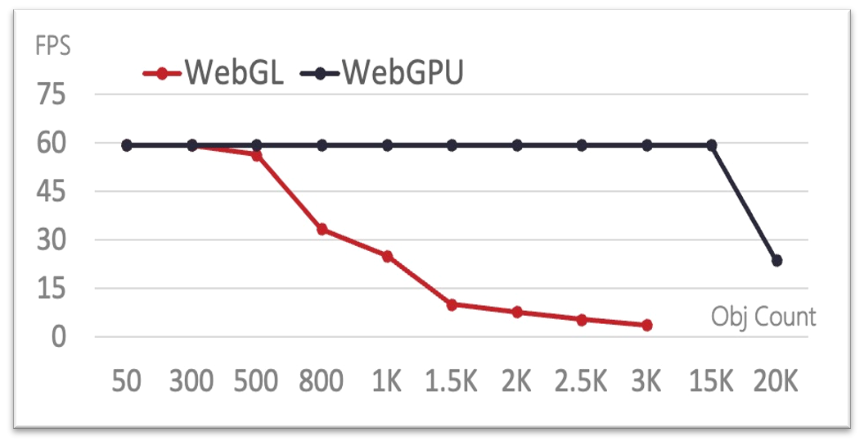
M1配置下计算场景中FPS对比
2)硬件环境为台式机i7-4790 + RTX 2060 Super:
- 影响CPU性能的因素:CPU计算时间(因为只有一次DrawCall,所以CPU传递DrawCall时间的几乎为0,故该项忽略不计)
- WebGL:物体数量低于500时,由于物体数量较少,台式机CPU的计算任务和M1配置一样,也可以在16ms以内完成。但是超过500个物体后,CPU的耗时明显增加。原因与M1环境下的原因相同。
- WebGPU:其整体趋势和M1环境下对比分析相同

台式机配置下计算场景中CPU耗时性能对比
- 影响FPS性能的因素:CPU时间 + GPU时间
- WebGL:物体数量低于500时,几乎可以保持在60FPS的状态。但是当物体数量超过500时,FPS表现迅速下降。原因同M1场景分析一致。计算量过大时,测试场景出现崩溃(大于3000个物体)。
- WebGPU:其整体趋势和M1环境下对比分析相同。当测试达到35000个物体时, FPS开始下降,因为达到了RTX显卡的运算能力上限。
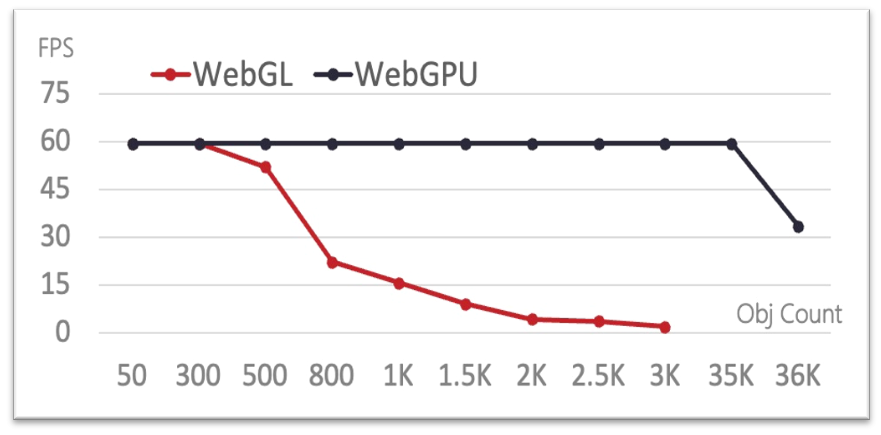
台式机配置下计算场景中FPS对比
测试结论
在当前计算场景的测试中得出如下结论:
- WebGPU采用了计算着色器,可以直接调用GPU能力,通过并行计算完成复杂的计算场景。而WebGL只能把计算任务交给CPU来处理,效率较低。相比较WebGL,WebGPU在M1配置下计算性能提升50倍,台式机i7-4790 + RTX 2060 Super配置下,计算性能提升100倍。
- CPU性能对比中,WebGL下,M1配置的CPU耗时参数优与台式机的CPU耗时参数,因此台式机CPU(i7-4790)性能表现不如M1芯片性能。同样在FPS性能对比中,WebGL下,台式机的计算还是体现在CPU方面,即使拥有RTX显卡也无法利用其计算能力。但是不论硬件配置如何,CPU性能的表现和FPS性能的表现,在WebGL下和WebGPU下,整体变化趋势一致。WebGPU性能整体明显优与WebGL性能。
WebGPU性能测试分析的更多相关文章
- 测试计划&性能测试分析报告模板(仅供参考)
一.测试计划 1. 引言 1.1 编写目的 2. 参考文档 3. 测试目的 4. 测试范围 4.1 测试对象 4.2 需要测试的特性 4.3 无需测试的特性 5. 测试启动与结束准则 5.1 ...
- LR性能测试分析流程
LR性能测试分析流程 一. 判断测试结果的有效性 (1)在整个测试场景的执行过程中,测试环境是否正常. (2)测试场景的设置是否正确.合理. (3)测试结果是否直接暴露出系统的一些问题. (4 ...
- 软件性能测试分析与调优实践之路-Web中间件的性能分析与调优总结
本文主要阐述软件性能测试中的一些调优思想和技术,节选自作者新书<软件性能测试分析与调优实践之路>部分章节归纳. 在国内互联网公司中,Web中间件用的最多的就是Apache和Nginx这两款 ...
- Jmeter- 笔记12 - 性能测试分析 & 性能测试流程
性能测试分析 场景设计.监视图表: 设计场景:阶梯式.波浪式 监视器: 收集用于性能分析的数据:TPS图表.聚合报告\汇总报告.察看结果树.响应时间.吞吐量 服务器资源监控:cpu.内存.磁盘io 分 ...
- 软件性能测试分析与调优实践之路-Java应用程序的性能分析与调优-手稿节选
Java编程语言自从诞生起,就成为了一门非常流行的编程语言,覆盖了互联网.安卓应用.后端应用.大数据等很多技术领域,因此Java应用程序的性能分析和调优也是一门非常重要的课题.Java应用程序的性能直 ...
- 软件性能测试分析与调优实践之路-JMeter对RPC服务的性能压测分析与调优-手稿节选
一.JMeter 如何通过自定义Sample来压测RPC服务 RPC(Remote Procedure Call)俗称远程过程调用,是常用的一种高效的服务调用方式,也是性能压测时经常遇到的一种服务调用 ...
- MySQL数据库的性能分析 ---图书《软件性能测试分析与调优实践之路》-手稿节选
1 .MySQL数据库的性能监控 1.1.如何查看MySQL数据库的连接数 连接数是指用户已经创建多少个连接,也就是MySQL中通过执行 SHOW PROCESSLIST命令输出结果中运行着的线程 ...
- 转:Web网站性能测试分析及调优实例
1.背景 前段时间,性能测试团队经历了一个规模较大的门户网站的性能优化工作,该网站的开发和合作涉及多个组织和部门,而且网站的重要性不言而喻,同时上线时间非常紧迫,关注度也很高,所以对于整个团队的压力也 ...
- 性能测试培训:sql server性能测试分析局部变量的性能影响
poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.在poptest的loadrunner的培训中,为了提高学员性能优化的经验,加入了 ...
随机推荐
- select 语句的基础语法
授权语法sql 一.用户的创建与使用 在管理员登录后可创建用户 --创建qfplan用户-create user qfplan identified by qfplan; --用户基本权限授权gran ...
- Win7通过cmd进入d盘的方法
Win7通过cmd进入d盘的方法 时间:2016-05-13 15:06:03 作者:yunchun 来源:系统之家 手机查看 评论 我们在使用Win7系统过程中,对于经常使用DOS程序的朋友们来说 ...
- jolokia配置Java监控
wget http://search.maven.org/remotecontent?filepath=org/jolokia/jolokia-jvm/1.3.6/jolokia-jvm-1.3.6- ...
- Linux占用swap分区过高,物理内存还有剩余
Linux占用swap分区过高,物理内存还有剩余 问题分析 Swap配置对性能的影响 分配太多的Swap空间会浪费磁盘空间,而Swap空间太少,则系统会发生错误.如果系统的物理内存用光了,系统就会跑得 ...
- VUE如何关闭代码规范extra semiclon/VUE新手必看-(转载)
VUE如何关闭代码规范 最近在学VUE,作为一个设计转前端的小白鼠. 总是能碰到各种各样奇葩的问题. 比如我碰到了 extra semicolon 百度了下说是这个原因造成的: 但是!!!!!关键点来 ...
- 安全漏洞扫描工具 burpsuite V1.7.32 资料
安装包下载地址:http://www.downxia.com/downinfo/229728.html 实战教程:https://t0data.gitbooks.io/burpsuite/conten ...
- python3 摆放家具练习
摆放家具 需求: 1)房子有户型,总面积和家具名称列表 新房子没有任何家具 2)家具有名字和占地面积.其中: 床:占4平米 衣柜:占2平米 餐桌:占1.5平米 3)将以上三件家具添加到房子中 4)打印 ...
- windows下nginx配合nodejs进行反向代理
本文原创,转载请附上原作者链接!https://www.cnblogs.com/LSWu/articles/14848324.html 1.安装node.js 从node.js官网上下载node.js ...
- gin框架路由拆分与注册
gin框架路由拆分与注册 本文总结了我平时在项目中积累的关于gin框架路由拆分与注册的若干方法. gin框架路由拆分与注册 基本的路由注册 下面最基础的gin路由注册方式,适用于路由条目比较少的简单项 ...
- 元素定位工具ChroPath - Chrome浏览器插件
一 ChroPath的作用 可以自动识别元素定位表达式,对于系统需要定位元素多时,可使用这种方法减轻定位工作量,但需要验证 二 ChroPath的安装 下载ChroPath -> 在谷歌浏览器访 ...