java面试系列<2>——java容器
1、概览
容器主要包括Collection和Map两种,Collection存储着对象的集合,而map存储着键值对(两个对象)的映射表
Collection
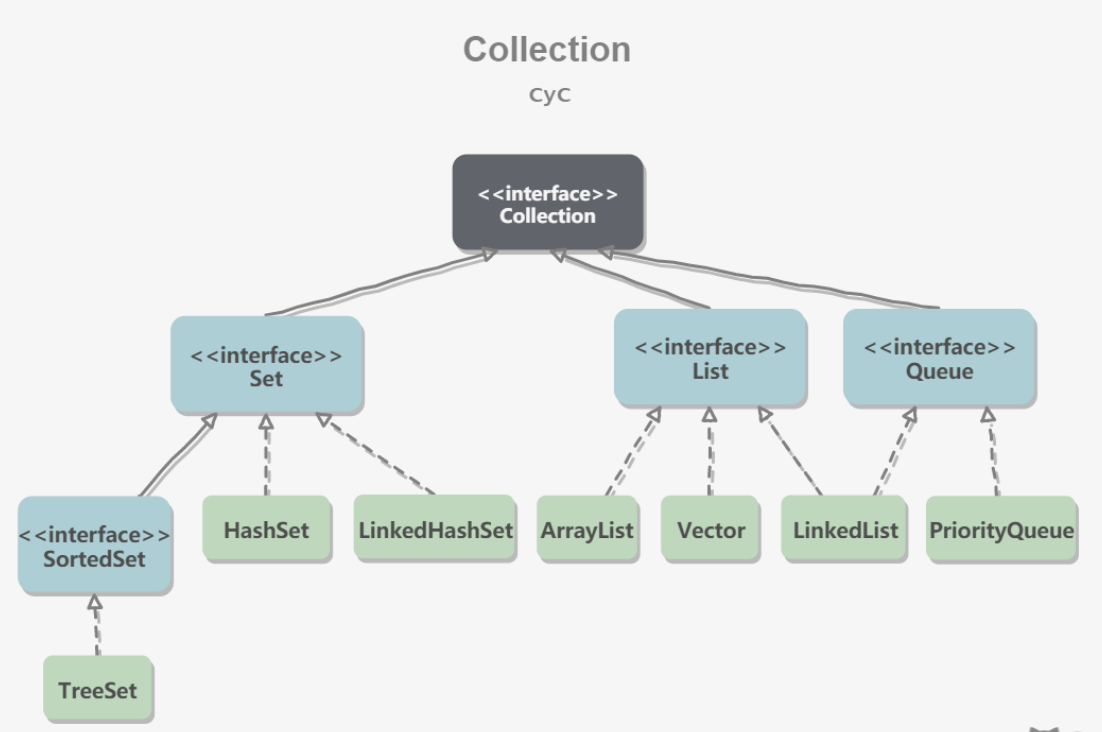
1、set
- TreeSet:基于红黑树实现,支持有序操作,。查找效率不如HashSet,HashSet查找的时间复杂度为O(1),TreeSet则为O(logN)。
- HashSet:基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去元素的插入顺序信息,即遍历HashSet时候得到的结果是不确定的。
- LinkeHashSet:具有HashSet的查找效率,并且内部使用双向链表维护元素的插入顺序。
2、List
- ArrayList:基于动态数组实现,支持随机访问
- Vector:和ArrayList类型,但它是线程安全的。
- LinkedList:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList还可以用作栈、队列和双向队列。
3、Queue
- LinkedList:可以用它来实现双向队列
- PriorityQueue:基于堆结构实现,可以用它来实现优先队列。
Map
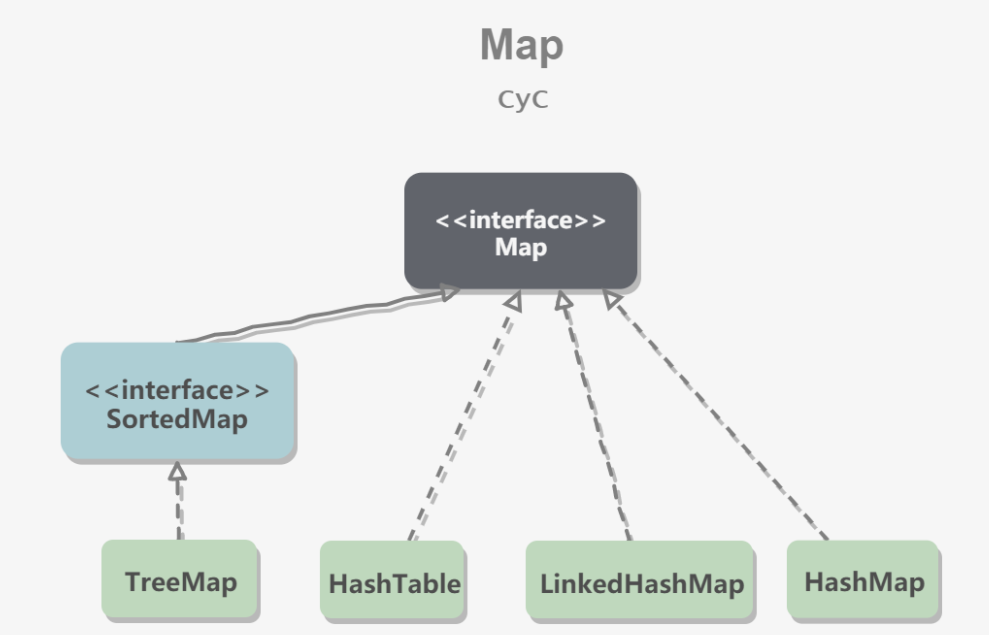
- TreeMap:基于红黑树实现。
- HashMap:基于哈希表实现。
- HashTable:和HashMap类似,但它是线程安全的,这意味着同一时刻多个县城同时写入HashTable不会导致数据不一致。遗留类,不应该使用,而是使用 ConcurrentHashMap 来支持线程安全,ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
- LinkedHashMap:使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
2、设计模式
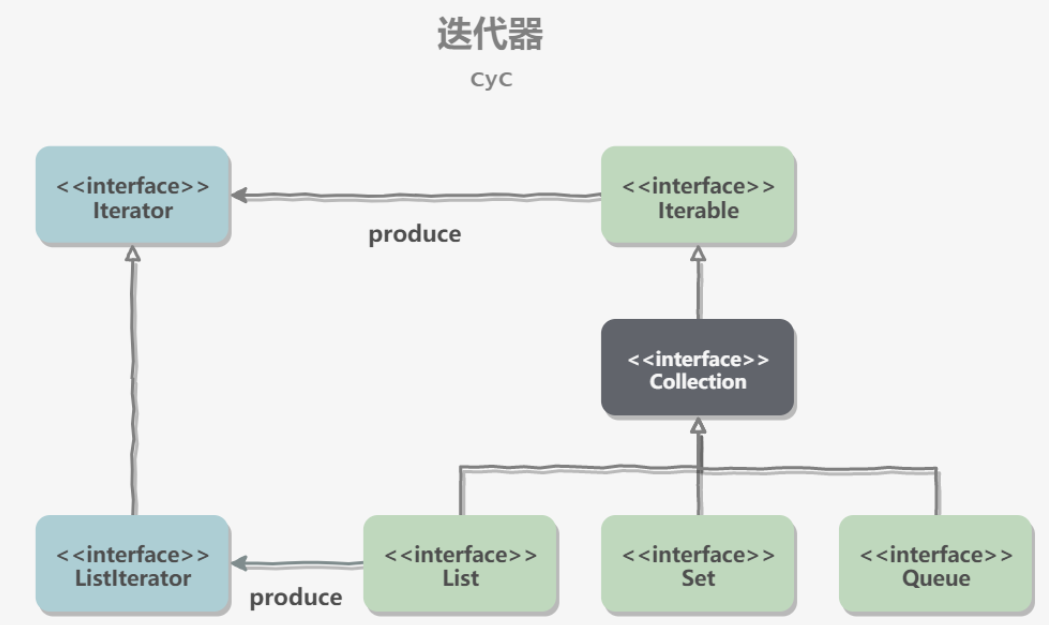
迭代器模式:
Collection继承了Iterable接口,其中的iterator()方法能够产生一个Iterator对象,通过这个对象就可以迭代遍历Collection中的元素。
适配器模式
java.Util.Arrays.asList()可以把数组类型转换为List类型。
应该注意的是 asList() 的参数为泛型的变长参数,不能使用基本类型数组作为参数,只能使用相应的包装类型数组。
3、源码分析
ArrayList
1、概述
因为ArrayList是基于数组实现的,所以支持快速随机访问。
数组的默认大小为10.
private static final int DEFAULT_CAPACITY = 10;
2、扩容
添加元素时候使用ensureCapacityInternal()方法来保证容量足够,需要使用grow()方法进行扩容,新容量的大小为(oldCapacity+oldCapacity/2)。因此,新容量大约是旧容量的1.5倍左右。 (oldCapacity 为偶数就是 1.5 倍,为奇数就是 1.5 倍-0.5)。
扩容时候,需要调用操作Arrays.copyOf()把原数组整个复制到新数组中,整个操作代价高,因此最好在创建ArrayList对象时候就指定大概的容量大小,减少扩容次数。
3、删除元素
需要调用System.arraycopy()将index+1后面的元素都复制到index位置上,该操作的时间复杂度是O(N),因此ArrayList删除元素的代价是很高的。
Vector
它的实现与ArrayList类似,但是使用了synchronized进行同步。
public synchronized boolean add(E e) {modCount++;ensureCapacityHelper(elementCount + 1);elementData[elementCount++] = e;return true;}public synchronized E get(int index) {if (index >= elementCount)throw new ArrayIndexOutOfBoundsException(index);return elementData(index);}
2、扩容
Vector的可以传入 capacityIncrement 参数,可以使在扩容时使容量增长 capacityIncrement 。如果这个参数值小于或等于0,扩容时每次扩容两倍。
3、与ArrayList的比较
- Vector是同步的,因此开销就比ArrayList大,访问速度更慢。最好使用ArrayList而不是Vector,因为同步操作可以由程序员控制。
- Vector每次扩容请求其大小2倍,而ArrayList是1.5倍。
4、替代方案
可以使用Collections.synchronizedList();得到一个线程安全的ArrayList
List<String> list = new ArrayList<>();List<String> synList = Collections.synchronizedList(list);
List<String> list = new CopyOnWriteArrayList<>();
CopyOnWriteArrayList
1、读写分离
写操作在一个复制的数组上进行,读操作是在原始数组,读写分离,互不影响。
写操作需要加锁,防止并发写入时导致写入数据丢失
写操作结束后需要把原始数组指向新的复制数组
2、适用场景
CopyOnWriteArrayList 在写操作的同时允许读操作,大大提高了读操作的性能,因此很适合读多写少的应用场景。
缺陷
- 内存占用:在写操作的同时需要复制一个新的数组,内存占用为原来的两倍
- 数据不一致:读操作不能读取实时性的数据,因为部分写操作的数据还未同步到读数组中。
所以CopyOnWriteArrayList不适合内存敏感以及对实时性要求很高的场景。
LinkedList
基于双向链表实现,使用Node存储链表节点信息。
与ArrayList比较
ArrayList基于动态数组实现,LinkedList基于双向链表实现。ArrayList和LinkedList的区别可以归结为数组和链表的区别:
- 数组支持随机访问,但插入删除的代价很高,需要移动大量元素
- 链表不支持随机访问,但插入删除只需要改变指针。
HashMap
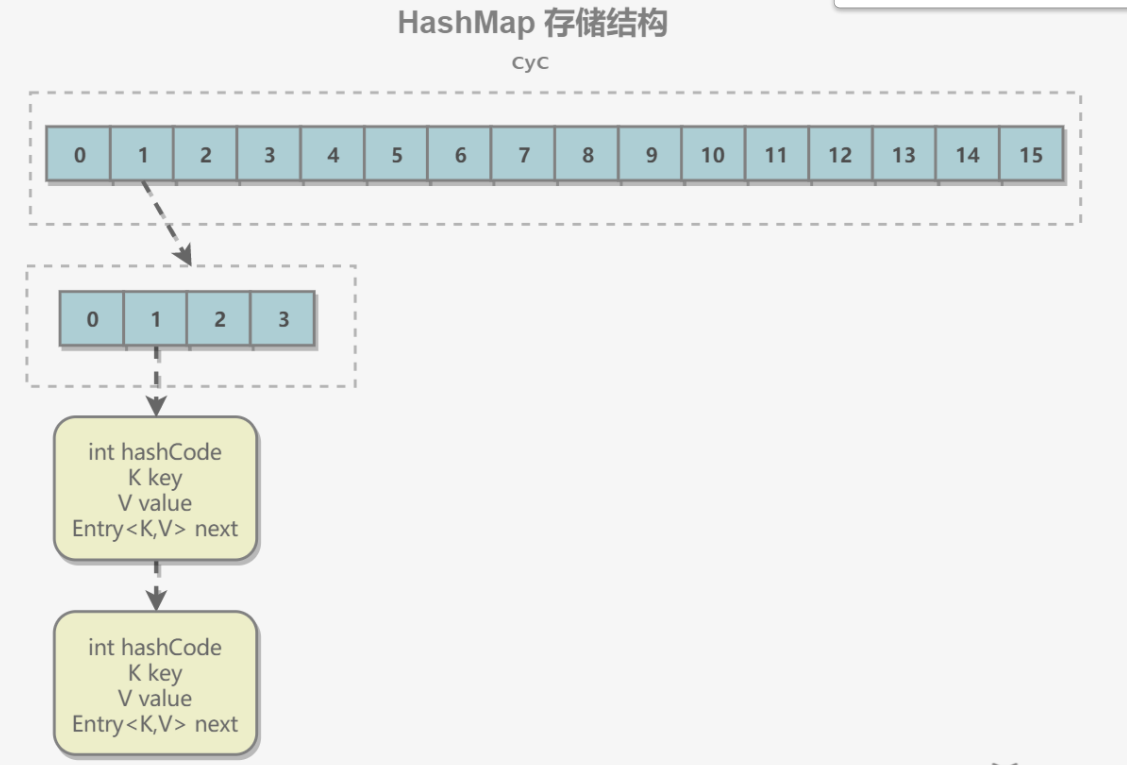
内部包含了一个 Entry 类型的数组 table。Entry 存储着键值对。它包含了四个字段,从 next 字段我们可以看出 Entry 是一个链表。即数组中的每个位置被当成一个桶,一个桶存放一个链表。HashMap 使用拉链法来解决冲突,同一个链表中存放哈希值和散列桶取模运算结果相同的 Entry。
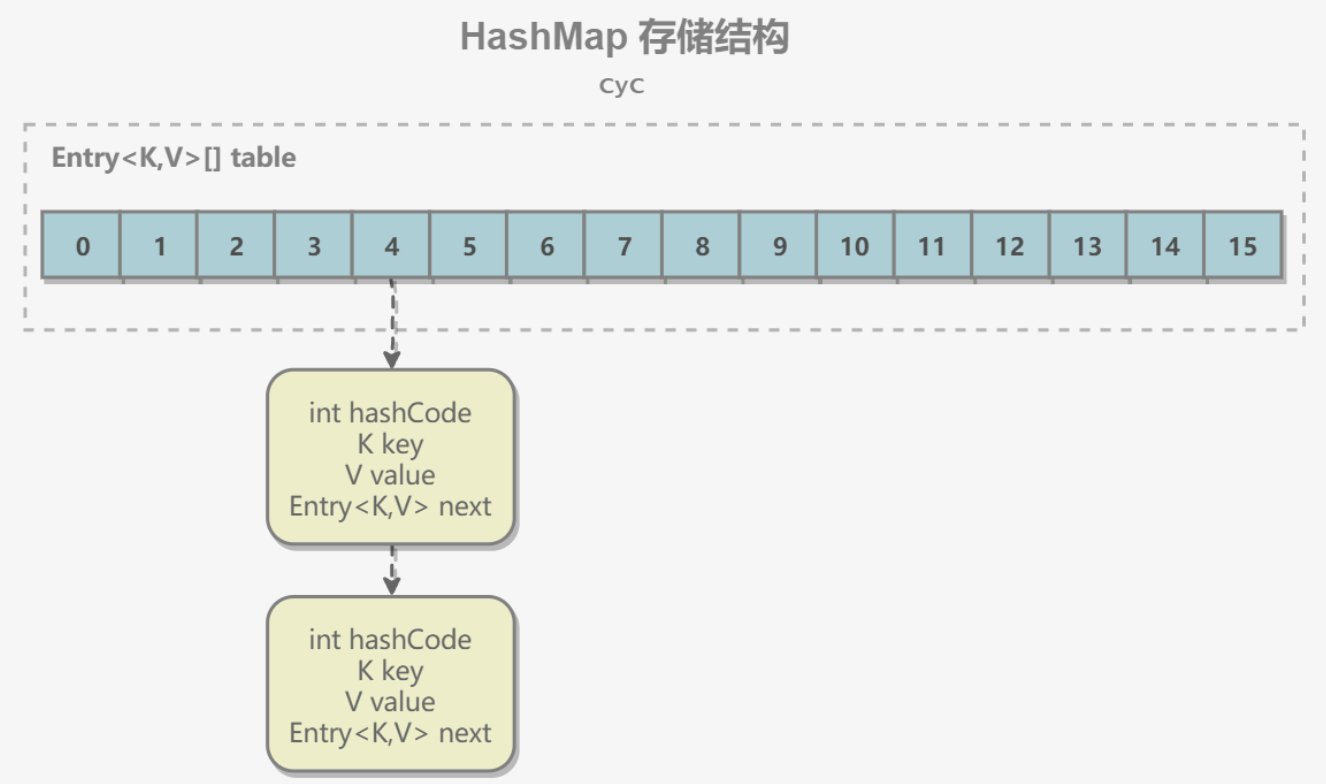
2、拉链法工作原理
- 新建一个 HashMap,默认大小为 16;
- 插入 <K1,V1> 键值对,先计算 K1 的 hashCode 为 115,使用除留余数法得到所在的桶下标 115%16=3。
- 插入 <K2,V2> 键值对,先计算 K2 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6。
- 插入 <K3,V3> 键值对,先计算 K3 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6,插在 <K2,V2> 前面。
应该注意到链表的插入是以头插法方式进行的,例如上面的 <K3,V3> 不是插在 <K2,V2> 后面,而是插入在链表头部。
查找需要分成两步进行:
- 计算键值对所在的桶;
- 在链表上顺序查找,时间复杂度显然和链表的长度成正比。
HashMap 允许插入键为 null 的键值对。但是因为无法调用 null 的 hashCode() 方法,也就无法确定该键值对的桶下标,只能通过强制指定一个桶下标来存放。HashMap 使用第 0 个桶存放键为 null 的键值对。
3、扩容
设 HashMap 的 table 长度为 M,需要存储的键值对数量为 N,如果哈希函数满足均匀性的要求,那么每条链表的长度大约为 N/M,因此查找的复杂度为 O(N/M)。
为了让查找的成本降低,应该使 N/M 尽可能小,因此需要保证 M 尽可能大,也就是说 table 要尽可能大。HashMap 采用动态扩容来根据当前的 N 值来调整 M 值,使得空间效率和时间效率都能得到保证。
4、扩容-重新计算桶下标
在进行扩容时,需要把键值对重新计算桶下标,从而放到对应的桶上。在前面提到,HashMap 使用 hash%capacity 来确定桶下标。HashMap capacity 为 2 的 n 次方这一特点能够极大降低重新计算桶下标操作的复杂度。
假设原数组长度 capacity 为 16,扩容之后 new capacity 为 32:
对于一个 Key,它的哈希值 hash 在第 5 位:
- 为 0,那么 hash%00010000 = hash%00100000,桶位置和原来一致;
- 为 1,hash%00010000 = hash%00100000 + 16,桶位置是原位置 + 16。
5、链表转红黑树
从JDK1.8开始,一个桶存储的链表长度大于等于8时会将链表转为红黑树。
6、与Hashtable的比较
- Hashtable使用synchronized来进行同步
- HashMap可以插入键为null的Entry
- HashMap是无序的
ConcurrentHashMap
ConcurrentHashMap 和 HashMap 实现上类似,最主要的差别是 ConcurrentHashMap 采用了分段锁(Segment),每个分段锁维护着几个桶(HashEntry),多个线程可以同时访问不同分段锁上的桶,从而使其并发度更高(并发度就是 Segment 的个数)。
LinkedHashMap
存储结构
继承自HashMap,因此具有和HashMap一样的快速查找特性。
内部维护了一个双向链表,用来维护插入顺序或者 LRU 顺序。
LinkedHashMap 最重要的是以下用于维护顺序的函数,它们会在 put、get 等方法中调用。
void afterNodeAccess(Node<K,V> p) { }void afterNodeInsertion(boolean evict) { }
afterNodeAccess()
当一个节点被访问时,如果 accessOrder 为 true,则会将该节点移到链表尾部。也就是说指定为 LRU 顺序之后,在每次访问一个节点时,会将这个节点移到链表尾部,保证链表尾部是最近访问的节点,那么链表首部就是最近最久未使用的节点。
afterNodeInsertion()
在 put 等操作之后执行,当 removeEldestEntry() 方法返回 true 时会移除最晚的节点,也就是链表首部节点 first。
evict 只有在构建 Map 的时候才为 false,在这里为 true。
java面试系列<2>——java容器的更多相关文章
- 程序员面试系列之Java单例模式的攻击与防御
我写的程序员面试系列 Java面试系列-webapp文件夹和WebContent文件夹的区别? 程序员面试系列:Spring MVC能响应HTTP请求的原因? Java程序员面试系列-什么是Java ...
- 【阿里面试系列】Java线程的应用及挑战
文章简介 上一篇文章[「阿里面试系列」搞懂并发编程,轻松应对80%的面试场景]我们了解了进程和线程的发展历史.线程的生命周期.线程的优势和使用场景,这一篇,我们从Java层面更进一步了解线程的使用.关 ...
- 面试系列<3>——java并发
面试系列--java并发 一.使用线程 有三种使用线程的方法: 实现Runnable接口 实现Callable接口 继承Thread类 实现 Runnable 和 Callable 接口的类只能当做一 ...
- java面试系列<4>——IO
面试系列--javaIO 一.概述 java的IO主要分为以下几类: 磁盘操作:File 字节操作:InputStream 和 OutputStream 字符操作:Reader 和 Writer 对象 ...
- Java面试系列
如果你的面试简历是如下这样写的,请务必准备回答下面的所有问题. 面试职位:Java高级工程师 专业技能: (1)牢固掌握Java基础知识,如集合.并发.I/O等,并对Java源码有一定的研究. (2) ...
- 大宇java面试系列(二):jvm组成部分
1. 说一下 JVM 的主要组成部分?及其作用? 类加载器(ClassLoader) 运行时数据区(Runtime Data Area) 执行引擎(Execution Engine) 本地库接口(Na ...
- java 面试题目(java高级架构)
题目信息 java基础: 1. Java 基础 JDK 和 JRE 有什么区别? Java中JDK和JRE的区别是什么?它们的作用分别是什么? == 和 equals 的区别是什么? 两个对象的 ...
- JAVA面试精选【Java基础第一部分】
这个系列面试题主要目的是帮助你拿轻松到offer,同时还能开个好价钱.只要能够搞明白这个系列的绝大多数题目,在面试过程中,你就能轻轻松松的把面试官给忽悠了.对于那些正打算找工作JAVA软件开发工作的童 ...
- 【java虚拟机系列】java虚拟机系列之JVM总述
我们知道java之所以能够快速崛起一个重要的原因就是其跨平台性,而跨平台就是通过java虚拟机来完成的,java虚拟机属于java底层的知识范畴,即使你不了解也不会影响绝大部分人从事的java应用层的 ...
随机推荐
- 瞧一瞧React Fiber
啥是React Fiber? React Fiber,简单来说就是一个从React v16开始引入的新协调引擎,用来实现Virtual DOM的增量渲染. 说人话:就是一种能让React视图更新过程变 ...
- 26_ mysql数据操作语言:DELETE语句
-- DELETE语句 -- 删除10部门中,工龄超过20年的员工记录 DELETE FROM t_emp WHERE deptno=10 AND DATEDIFF(NOW(),hiredate)/3 ...
- 从零开始搞后台管理系统(1)——shin-admin
shin 的读音是[ʃɪn],谐音就是行,寓意可行的后台管理系统,shin-admin 的特点是: 站在巨人的肩膀上,依托Umi 2.Dva 2.Ant Design 3和React 16.8搭建 ...
- Docker-compose封装mysql并初始化数据以及redis
一.概述 现有一台服务器,需要部署mysql和redis.其中mysql容器,需要在第一次启动时,执行sql文件. redis保持空数据即可. 关于Docker-compose的安装,请参考连接: h ...
- Django登录使用的技术和组件
登录 ''' 获取用户所有的数据 每条数据请求的验证 成功之后获取所有正确的信息 失败则显示错误信息 ''' #登陆页面管理 def login(request): if request.method ...
- 死磕Spring之IoC篇 - 开启 Bean 的加载
该系列文章是本人在学习 Spring 的过程中总结下来的,里面涉及到相关源码,可能对读者不太友好,请结合我的源码注释 Spring 源码分析 GitHub 地址 进行阅读 Spring 版本:5.1. ...
- uni-app创建项目
下载 HBuilderX 下载地址(https://www.dcloud.io/hbuilderx.html) HBuilderX是通用的前端开发工具,但为uni-app做了特别强化. 创建uni ...
- Amazon Connect 配置ccp端的soft phone配置(客服坐席工作站配置)
本文参考: Amazon Connect 配置ccp端的soft phone配置(客服坐席工作站配置) [官网]:https://aws.amazon.com/cn/connect/ 应用场景 在应 ...
- JavaEE---JDBC技术
JDBC:java连接数据库(任意数据库)的技术JDBC是java为我们预先写好的操作数据库的一系列接口和类 主流的关系型数据库 中小型数据库(mysql sqlserver) 大型数据库(oracl ...
- 掌握HTTP原理
URI和URL URI的全程为Uniform Resource identifier,即统一资源标志符,URL的全称 Universal Resource Locator 即统一资源定位符 在目前的互 ...