Kafka从入门到放弃(三)—— 详说消费者
之前介绍了Kafka以及生产者,包括它的一些特性和参数,这回写一下消费者。
之前没看得可以点击链接阅读。
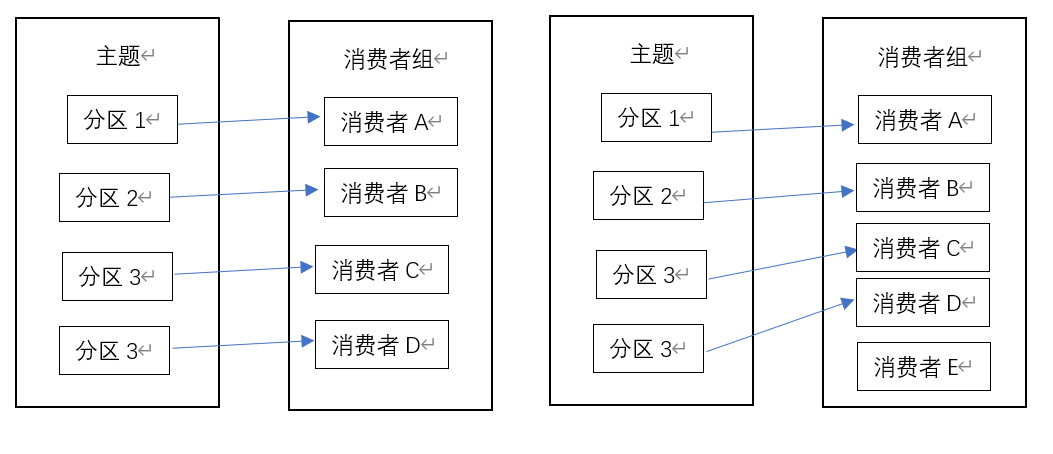
消费者与消费者组
在Kafka中消费者是消费消息的对象。假设目前有一个消费者正在消费消息,但生产数据的速度突然上升,这时候消费者会有点力不从心,跟不上消息生产的速度,这时候咋办呢?
我们对消费者进行横向扩展,加几个消费者,达到负载均衡的作用。但是要做点限制吧,不然几个消费者消费同一个分区的消息,不仅没办法提高消费能力,还会造成重复消费。因此让他们分别消费不同的分区。
在Kafka中的消费者组就是如此,一个消费者组内的消费者订阅同一个Topic的数据,但消费不同分区的数据,提高了消费能力。
但是消费者组里的消费者数量建议不要超过分区数量,不然就浪费资源。

LEO & HW
Kafka中的分区是可以有多个副本的,我们把每个副本中待写入的那个offset称为LEO(Log End Offset),把最少消息的那个副本的LEO称为HW(High Watermark)
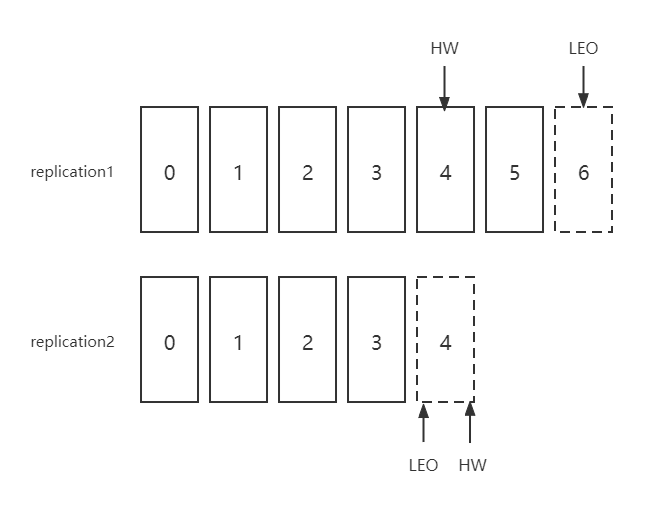
对于消费者而言,消费者所能消费的区间就是小于HW那部分,即图中 0-3 部分。这样消费者不管是哪个副本,订阅到的消息都是一致的,即使换了leader也能接着消费。
提交偏移量
假如一个消费者退出,另一个消费者接替它的任务,这时候就需要知道上一个消费者消费到了哪条数据,因此消费者需要追踪偏移量。
在Kafka中,有一个名为_consumer_offset的主题,消费者会往里面发送消息,提交偏移量,这个时候消费者也是生产者。
当消费者挂了或者有新的消费者假如消费者组,就会触发在均衡操作,即为消费者重新分配分区。
为了能够继续之前的操作,消费者需要获取每个分区最后一次提交的偏移量。
如果提交的偏移量小于处理的最后一个消息的偏移量,会造成重复消费。比如消费者提交了 6 的offset,此时又拉取了2条数据,还没等提交,消费者就挂掉了,然后就发生了再均衡。新的消费者获取到 6 的偏移量,接着处理,这就造成了重复消费。
如果提交的偏移量大于处理的最后一个消息的偏移量,会造成数据丢失。比如消费者一次性拉取了 88 条数据,并且提交了偏移量,还没处理完就宕机了,新的消费者获取 88 的偏移量,继续消费,就造成了数据丢失。
因此,如何提交偏移量对客户端影响很大,稍有不慎就会造成不好的影响。
在Kafka中,有几种提交偏移量的方式。
自动提交
这种提交方式有两个很重要的参数:
enable.auto.commit=true(是否开启自动提交,true or false)
auto.commit.interval.ms=5000(提交偏移量的时间间隔,默认5000ms)
这种方式最容易造成数据丢失以及重复消费。
通过CommitSync()方法手动提交当前偏移量
在处理完所有消息后提交,前提要把enable.auto.commit设置为false。
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for(ConsumerRecords<String, String> record: records){
System.out.println("topic=%s, offset=%s,partition=%s",
record.topic(), record.offset(),record.partition());
}
try{
consumer.commitSync();
} catch(Exception e){
log.error(e);
}
}
消费者通过poll方法轮询获取消息,poll里的参数是一个超时时间,用于控制阻塞的时间,如果没有数据则会阻塞这么久,如果设置为0则会立即放回。
使用这种方法一定要在处理完所有记录后调用CommitSync()方法,避免数据丢失。如果发生错误,会进行重试。
异步提交
CommitSync() 提交偏移量的方式会造成阻塞,即需要等客户端处理完所有消息后才提交偏移量,限制了吞吐量。因此可以使用异步提交的方式,通过调用commitAsync()方法实现。
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for(ConsumerRecords<String, String> record: records){
System.out.println("topic=%s, offset=%s,partition=%s",
record.topic(), record.offset(),record.partition());
}
consumer.commitAsync();
}
提交偏移量后就可以去做其他事了。CommitSync()方式发生错误会重试,但CommitAsync()不会。
之所以不重试,是因为有可能在收到broker响应前有其它偏移量提交了。
试想一下,如果会重试的话,当提交 66 的偏移量时发生网络问题,与此同时提交了 88 的偏移量,这时候刚好网络又通了,然后 88 的偏移量就提交成功了,然后 66 就重试,成功后又变成 66 了,就有可能造成重复消费。
之所以说这个问题,是因为异步提交支持在broker响应时回调,常被用于记录错误或生成度量指标。如果用他重试的话一定要注意提交的顺序。
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for(ConsumerRecords<String, String> record: records){
System.out.println("topic=%s, offset=%s,partition=%s",
record.topic(), record.offset(),record.partition());
}
consumer.commitAsync(new OffsetCommitCallback() {
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception e){
if(e != null){
log.error("Error");
}
}
});
}
异步与同步组合提交
如果发生在关闭消费者或者再均衡前的最后一次提交,就需要确保其成功。
因此在消费者关闭前一般会通过组合使用的方式确保其提交成功。
try{
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for(ConsumerRecords<String, String> record: records){
System.out.println("topic=%s, offset=%s,partition=%s",
record.topic(),record.offset(),record.partition());
}
consumer.commitAsync();
}
}catch(Exception e){
log.error(e);
}finally {
try {
consumer.commitSync();
}
finally{
consumer.close();
}
}
提交特定偏移量
commitSync() 和 commitAsync() 方法一般是在处理完一个批次后提交偏移量。如果需要更频繁的提交偏移量,需要在处理的过程中间提交的话,消费者 API 允许在调用 commitSync()和 commitAsync () 方法时传进去希望提交的分区和偏移量的 map
Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<TopicPartition, OffsetAndMetadata>();
int count = 0;
try {
while(true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
if (records.isEmpty()){
continue;
}
for (ConsumerRecord<String, String> record : records){
System.out.println("topic=%s, offset=%s,partition=%s",
record.topic(),record.offset(),record.partition());
currentOffsets.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset(), "no metadata"));
// 每处理完1000条消息后就提交偏移量
if (count%1000==0) {
consumer.commitAsync(currentOffsets, null);
}
count++;
}
}
} finally {
try{
consumer.commitSync();
} finally{
consumer.close();
}
}
消费者分区分配策略
分区会被分配给消费者组里的消费者进行消费,在Kafka种可以通过配置参数partition.assignment.strategy选择分区分配策略。
Range 范围分区
假设现在有10个分区,消费者组里有3个消费者。
分区数量 10 除以消费者数量 3 取整(10/3)得 3,设为 x;分区数量 10 模 消费者数量 3(10%3)得 1,设为 y
则前 y 个消费者分得 x+1 个分区;其余消费者分得 x 个分区。
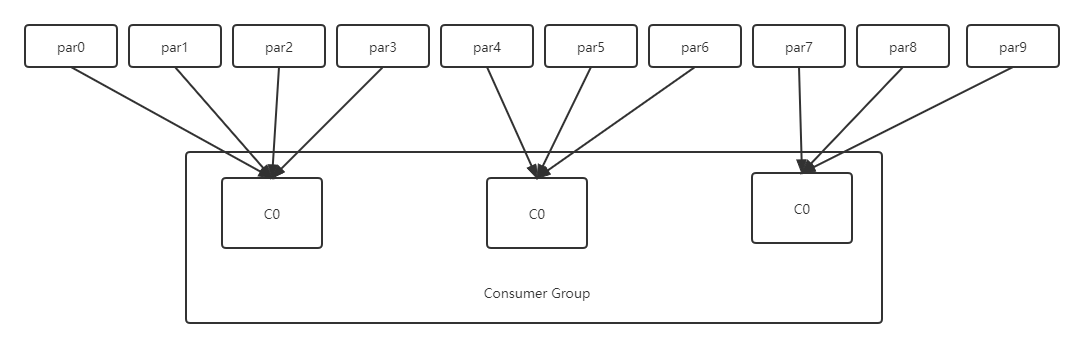
RoundRobin 轮询分区
假设有10个分区,3个消费者,第一个分区给第一个消费者,第二个给第二个消费者,第三个分区给第三个消费者,第四个给第一个消费者... 以此类推

到这,消费者的点就讲得差不多了,可能有些细节没写或者没讲明白。后面如果发现了,我另写一篇补上。如果觉得写得还行得的话,麻烦点个小赞,谢谢!
转载请注明出处:工众号“大数据的奇妙冒险”
Kafka从入门到放弃(三)—— 详说消费者的更多相关文章
- Kafka从入门到放弃(三) —— 详说生产者
上一篇对Kafka做了简单介绍,还没看的朋友可以点击下方链接. Kafka从入门到放弃(一) -- 初识别Kafka 消息中间件必须与生产者和消费者一起存在才有意义,这次先来聊聊Kafka的生产者. ...
- hive从入门到放弃(三)——DML数据操作
上一篇给大家介绍了 hive 的 DDL 数据定义语言,这篇来介绍一下 DML 数据操作语言. 没看过的可以点击跳转阅读: hive从入门到放弃(一)--初识hive hive从入门到放弃(二)--D ...
- storm从入门到放弃(三),放弃使用《StreamId》特性。
序:StreamId是storm中实现DAG有向无环图的重要一个特性,但是从实际生产环境来看,这个功能其实蛮影响生产环境的稳定性的,我们系统在迭代时会带来整体服务的不可用. StreamId是stor ...
- storm从入门到放弃(三),放弃使用 StreamId 特性
序:StreamId是storm中实现DAG有向无环图的重要一个特性,但是从实际生产环境来看,这个功能其实蛮影响生产环境的稳定性的,我们系统在迭代时会带来整体服务的不可用. StreamId是stor ...
- Kafka从入门到放弃(一) —— 初识Kafka
消息中间件的使用已经越来越广泛,基本上具有一定规模的系统都会用到它,在大数据领域也是个必需品,但为什么使用它呢?一个技术的广泛使用必然有它的道理. 背景与问题 以前一些传统的系统,基本上都是" ...
- robotium从入门到放弃 三 基于apk的自动化测试
1.apk重签名 在做基于APK的自动化测试的过程中,需要确保的一点是,被测试的APK必须跟测试项目具有相同的签名,那怎么做才能确保两者拥有相同的签名呢?下面将给出具体的实现方法. 首先将被测 ...
- Go语言从入门到放弃(三) 布尔/数字/格式化输出
本章主要介绍Go语言的数据类型 布尔(bool) 布尔指对或者错,也就是说bool只有两个值, True 或 False 两个类型相同的值可以使用比较运算符来得出一个布尔值 当两个值是完全相同的情况下 ...
- MyBatis从入门到放弃三:一对一关联查询
前言 简单来说在mybatis.xml中实现关联查询实在是有些麻烦,正是因为起框架本质是实现orm的半自动化. 那么mybatis实现一对一的关联查询则是使用association属性和resultM ...
- hive从入门到放弃(一)——初识hive
之前更完了<Kafka从入门到放弃>系列文章,本人决定开新坑--hive从入门到放弃,今天先认识一下hive. 没看过 Kafka 系列的朋友可以点此传送阅读: <Kafka从入门到 ...
随机推荐
- 保姆级神器 Maven,再也不用担心项目构建搞崩了
今天来给大家介绍一款项目构建神器--Maven,不仅能帮我们自动化构建,还能够抽象构建过程,提供构建任务实现:它跨平台,对外提供了一致的操作接口,这一切足以使它成为优秀的.流行的构建工具,从此以后,再 ...
- Vue: 一个简单的Vue2.0 v-model双向数据绑定的实现,含源代码,小白也能看懂
首先说一下原理吧 View层(dom元素)的变动如何响应到Model层(Js变量)呢? 通过监听元素的input事件来动态的改变js变量的值,实际上不是改变的js变量的值,而是改变的js变量的gett ...
- 测试平台系列(81) 编写在线执行Redis功能
大家好~我是米洛! 我正在从0到1打造一个开源的接口测试平台, 也在编写一套与之对应的完整教程,希望大家多多支持. 欢迎关注我的公众号测试开发坑货,获取最新文章教程! 回顾 上一节我们牛刀小试,编写了 ...
- IDEA:Git stash 暂存分支修改的代码
IDEA:Git stash 暂存分支修改的代码 场景:当我们正在master分支开发新功能的时候,突然接到一个任务发现线上出现了一个紧急的BUG需要修复,由于没有打新分支做这部分新需求,这时正做到半 ...
- Timer定时器的使用
import java.util.Timer; import java.util.TimerTask; public class Demo2 { //执行时间,时间单位为毫秒,读者可自行设定,不得小于 ...
- pycahrm下载
下载地址: https://www.jetbrains.com/pycharm/download/#section=windows 下载社区版本,不用破解,可以直接使用
- sigma网格中水平压力梯度误差及其修正
1.水平梯度误差产生 sigma坐标系下,笛卡尔坐标内水平梯度项对应形式为 \[\begin{equation} \left. \frac{\partial }{\partial x} \right| ...
- 【豆科基因组】绿豆Mungbean, Vigna radiata苏绿基因组预印
目录 一.来源 二.结果 测序组装 组装评价 编码基因预测 基因功能注释 非编码RNA注释 假基因预测 重复序列注释 进化分析和分歧时间估计 全基因组复制 LTR插入时间估计 正选择基因 一.来源 H ...
- fluidity详解
fluidity详解 1.fluidity编译过程 1.1.femtools库调用方法 编译fluidity/femtools目录下所有文件,打包为libfemtools.a静态库文件: 通过-lfe ...
- 【百奥云GS专栏】全基因组选择之工具篇
目录 1. 免费开源包/库 1.1 R包 1.2 Python库 2. 成熟软件 3. WEB/GUI工具 前面我们已经介绍了基因组选择的各类模型,今天主要来了解一下做GS有哪些可用的软件和工具.基因 ...