python中的xlrd模块学习
1、xlrd模块主要用于excel表格的读取,支持xlsx和xls;xlwt主要用于excel的写,库的读取
2、常用单元格中的数据类型
0、empty(空的);1、string(text);2、number;3、date;4、boolean;5、error;6、blank(空白表格)
运用
一、 导入模块
import xlrd
二、打开excel文件读取数据(该文件是被先创建好的)
data = xlrd.open_workbook('study.xls') #文件名及路径,如果路径或者文件名有中文给前面加一个r表示原生字符;例如'r学习.xls'
三、xlrd模块操作
1、基本函数
1.1. 打开workbook获取Book对象
- xlrd.open_workbook(filename[, logfile, file_contents, ...]):打开excel文件
filename:需操作的文件名(包括文件路径和文件名称);
若filename不存在,则报错FileNotFoundError;
若filename存在,则返回值为xlrd.book.Book对象
1.2. 获取Book对象中所有sheet名称
- BookObject.sheet_names():获取所有sheet的名称,以列表方式显示
1.3. 获取Book对象中所有Sheet对象
BookObject.sheets():获取所有sheet的对象,以列表形式显示
BookObject.sheet_by_index(sheetx):通过sheet索引获取所需sheet对象
sheetx为索引值,索引从0开始计算;
若sheetx超出索引范围,则报错IndexError;
若sheetx在索引范围内,则返回值为xlrd.sheet.Sheet对象BookObject.sheet_by_name(sheet_name):通过sheet名称获取所需sheet对象
sheet_name为sheet名称;
若sheet_name不存在,则报错xlrd.biffh.XLRDError;
若sheet_name存在,则返回值为xlrd.sheet.Sheet对象
1.4. 判断Book对象中某个sheet是否导入
- BookObject.sheet_loaded(sheet_name_or_index):通过sheet名称或索引判断该sheet是否导入成功
返回值为bool类型,若返回值为True表示已导入;若返回值为False表示未导入
1.5. 对Sheet对象中的行操作
SheetObject.nrows:获取某sheet中的有效行数
SheetObject.row_values(rowx[, start_colx=0, end_colx=None]):获取sheet中第rowx+1行从start_colx列到end_colx列的数据,返回值为列表。
若rowx在索引范围内,以列表形式返回数据;
若rowx不在索引范围内,则报错IndexErrorSheetObject.row(rowx):获取sheet中第rowx+1行单元,返回值为列表;
列表每个值内容为: 单元类型:单元数据SheetObject.row_slice(rowx[, start_colx=0, end_colx=None]):以切片方式获取sheet中第rowx+1行从start_colx列到end_colx列的单元,返回值为列表;
列表每个值内容为: 单元类型:单元数据SheetObject.row_types(rowx[, start_colx=0, end_colx=None]):获取sheet中第rowx+1行从start_colx列到end_colx列的单元类型,返回值为array.array类型。
单元类型ctype:empty为0,string为1,number为2,date为3,boolean为4, error为5(左边为类型,右边为类型对应的值);SheetObject.row_len(rowx):获取sheet中第rowx+1行的长度
rowx:行标,行数从0开始计算(0表示第一行), 必填参数;
start_colx:起始列,表示从start_colx列开始取值,包括第start_colx的值;
end_colx:结束列,表示到end_colx列结束取值,不包括第end_colx的值;
start_colx默认为0,end_colx默认为None:表示取整行相关数据;
- SheetObject.get_rows():获取某一sheet所有行的生成器
1.6. 对Sheet对象中的列操作
SheetObject.ncols:获取某sheet中的有效列数
SheetObject.col_values(self, colx[, start_rowx=0, end_rowx=None]):获取sheet中第colx+1列从start_rowx行到end_rowx行的数据,返回值为列表。
SheetObject.col_slice(colx[, start_rowx=0, end_rowx=None]):以切片方式获取sheet中第colx+1列从start_rowx行到end_rowx行的数据,返回值为列表。
列表每个值内容为: 单元类型:单元数据SheetObject.col_types(colx[, start_rowx=0, end_rowx=None]):获取sheet中第colx+1列从start_rowx行到end_rowx行的单元类型,返回值为列表;
1.7. 对Sheet对象的单元格执行操作
ShellObeject.cell(rowx, colx):获取sheet对象中第rowx+1行,第colx+1列的单元对象,返回值为'xlrd.sheet.Cell'类型,返回值的格式为“单元类型:单元值”。
ShellObject.cell_value(rowx, colx):获取sheet对象中第rowx+1行,第colx+1列的单元数据,返回值为当前值的类型(如float、int、string...);
ShellObject.cell_type(rowx, colx):获取sheet对象中第rowx+1行,第colx+1列的单元数据类型值;
单元类型ctype:empty为0,string为1,number为2,date为3,boolean为4, error为5;

import xlrd
'''打开exce表格'''
wook_book = xlrd.open_workbook('study.xls')
print(wook_book) #j结果:<xlrd.book.Book object at 0x000001DC91214B50>
'''1、获取所有sheet名称'''
sheet_names = wook_book.sheet_names()
print(sheet_names) #结果:列表['people', 'animal', 'car']
'''2、获取所有或某个sheet对象'''
'''获取所有的sheet对象'''
sheet_object = wook_book.sheets()
print(sheet_object) #结果[<xlrd.sheet.Sheet object at
# 0x0000026F491C21C0>,
# <xlrd.sheet.Sheet object at 0x0000026F491C22E0>,
# <xlrd.sheet.Sheet object at 0x0000026F491C22B0>]
#通过index获取第一个sheet对象
sheet1_object =wook_book.sheet_by_index(0)
print(sheet1_object)
#通过name获取第一个sheet对象
sheet2_object = wook_book.sheet_by_name('people')
print(sheet2_object)
'''3、判断某个sheet是否已导入'''
#通过index判断sheet1是否导入
sheet1_is_load = wook_book.sheet_loaded(sheet_name_or_index=0)
print(sheet1_is_load) #结果:True
#通过sheet名称判断sheet1是否导入
sheet1_name_is_load = wook_book.sheet_loaded(sheet_name_or_index='people')
print(sheet1_name_is_load) #结果为True或False
'''4、对sheet对象中的执行操作:如有效行数、某行从n1到n2列的数据、某行的单元和类型、某行的长度。。。'''
#获取sheet1中的有效行数 nrows:行数
nrows = sheet1_object.nrows
print(nrows)
#获取sheet1中第三行的数据
all_row_values =sheet1_object.row_values(rowx=2)
print(all_row_values)
#获取某行中的第几列到第几列的值
row_values = sheet1_object.row_values(rowx=2,start_colx=1,end_colx=3)
print(row_values)
#获取sheet1中第三行的单元对象,是单元对象
row_object = sheet1_object.row(rowx=2)
print(row_object)
#获取sheet1中第3行的单元
row_slice = sheet1_object.row_slice(rowx=2)
print(row_slice)
#获取sheet1中第3行的单元类型
row_type = sheet1_object.row_types(rowx=2)
print(row_type)
#获取sheet1中第三行的长度
row_len = sheet1_object.row_len(rowx=2)
print(row_len)
#获取sheet1中所以行的生成器
row_generator = sheet1_object.get_rows()
print(row_generator)
'''5、对sheet对象中的列执行操作'''
#获取sheet1中的有效列数 ncols:列数
ncols = sheet1_object.ncols
print(ncols)
#获取sheet1中第colx+1列的数据
col_values = sheet1_object.col_values(colx=1)
print(col_values)
col_value1 = sheet1_object.col_values(1,1,3)
print(col_value1)
#获取sheet1中第二列的单元
col_silce = sheet1_object.col_slice(colx=1)
print(col_silce)
#获取sheet1中第二列的单元类型
col_types =sheet1_object.col_types(colx=1)
print(col_types)
'''5、对sheet对象中的单元执行操作'''
#获取sheet1中第row+1行,第colx+1列的单元对象
cell_info = sheet1_object.cell(rowx=1,colx=2)
print(cell_info)
print(type(cell_info)) #<class 'xlrd.sheet.Cell'>
#获取sheet1中第row+1行,第colx+1列的单元值
cell_value = sheet1_object.cell_value(rowx=1,colx=2)
print(cell_value)
#获取sheet中row+1行,第colx+1列的单元类型值
cell_type =sheet1_object.cell_type(rowx=1,colx=2)
print(cell_type)
python操作excel表格xlrd、xlwt
import xlrd,xlwt
from datetime import date,datetime
def read_excel():
workbook = xlrd.open_workbook('study.xls') #打开文件
print(workbook.sheet_names()) #获取所有sheet
sheet2_name = workbook.sheet_names()[1] #定义sheet
print(sheet2_name)
sheet2 = workbook.sheet_by_index(1) #根据sheet索引或者名称获取sheet内容,索引从0开始
# sheet2 =workbook.sheet_names('sheet2')
#sheet的名称、行数,列数
print(sheet2.name,sheet2.nrows,sheet2.ncols)
#获取整行和整列的值(数组)
rows = sheet2.row_values(3) #获取第四行内容
cols = sheet2.col_values(2) #获取第三列内容
print(rows)
print(cols)
#获取单元格内容
print(sheet2.cell(1,0).value.encode('utf-8'))
print(sheet2.cell_value(1,0).encode('utf-8'))
print(sheet2.row(1)[0].value.encode('utf-8'))
#获取单元格内容的数据类型
print(sheet2.cell(1,0).ctype)
if __name__== '__main__':
read_excel()
运行结果为如图下:
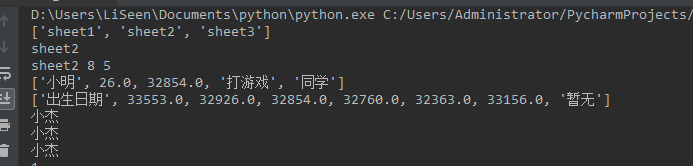
待解决问题:
1、python读取excel中单元格内容为日期的方位
python中读取excel中单元格的内容返回的有五种类型:ctype:0 empty; 1 string; 2 number; 3 date; 4 boolean ; 5 error
即date的ctype=3 ,这时需要使用xlrd的xldate_as_tuple 来处理为date的格式,先判断表格的ctype=3时xldate才能开始操作
#获取单元格内容的数据类型
print(sheet2.cell(1,0).ctype)
print(sheet2.cell(2,2).ctype) #1990/2/22,类型为3
print(sheet2.cell(2,1).ctype) # 24 2 number
print(sheet2.cell(2,0).ctype) # 小胖 1 string
print(sheet2.cell(2,4).ctype) # 空 0 empty 因为是合并单元格的原因导致的
print(sheet2.cell(2,2).value) #打印改单元格对象值
date_value = xlrd.xldate_as_tuple(sheet2.cell_value(2,2),workbook.datemode)
print(date_value)
print(date(*date_value[:3])) #时间格式转换
print(date(*date_value[:3]).strftime('%Y/%m/%d')) #时间格式转换
#以上代码可归纳为判断ctype是否为3没如果为3,则用时间格式处理
if sheet2.cell(row,col).ctype == 3:
date_value_1 = xlrd.xldate_as_tuple(sheet2.cell_value(rows,3),workbook.datemode)
date_tmp = date(*date_value_1[:3]).strftime('%Y%m/%d') #格式转换
print(date_tmp)
但是表格中又返回为空ctype的值,为合并单元格,第一个单元格有值,其他的为空
print(sheet2.col_values(4))
for i in range(sheet2.nrows):
print(sheet2.col_values(4)[i])
print(sheet2.row_values(7))
for j in range(sheet2.ncols):
print(sheet2.row_values(7)[j])
2、读取合并单元格的内容
只能获取合并单元格的第一个cell的行列索引才能读到值,读错了就是空值
即合并单元格读取行的第一个索引,合并单元格读取列的第一个索引,如上所述,读取行合并单元格“好朋友”和读取合并单元格“暂无”只能如下方式
print(sheet2.col_values(4))
for i in range(sheet2.nrows):
print(sheet2.col_values(4)[i])
print(sheet2.row_values(7))
for j in range(sheet2.ncols):
print(sheet2.row_values(7)[j])
print(sheet2.col_values(4)[1])
print(sheet2.row_values(7)[2])
print(sheet2.merged_cells)
#先知道哪些单元格是被合并的
3、获取合并的单元格
读取文件的时候需要将formatting_info 参数值设置为True,默认为False,所以上面获取合并的单元格数据为空
workbook =xlrd.open_workbook('study.xls',formatting_info=True)
sheet2 = workbook.sheet_by_name('sheet2')
print(sheet2.merged_cells)
merged_cells返回的这四个参数的含义是:(row,row_rang,col,col_range),其中[row,row_range)包括row,不包括row_range,
col也是一样,即(1,3,4,5)的含义是:从第1到第2行(不包括3)合并,(7,8,2,5)的含义是:第二到四列合并
利用这个,可以分别获取合并的三个单元格的内容
print(sheet2.cell_value(1,4)) #(1,3,4,5)
print(sheet2.cell_value(3,4)) #(3, 6, 4, 5)
print(sheet2.cell_value(7,2)) # (7, 8, 2, 5)
通过获取merge_cells返回的row和col低位的索引即可
merge = []
for (rlow,rhing,clow,chigh) in sheet2.merged_cells:
merge.append([rlow,clow])
print(merge)
for index in merge:
print(sheet2.cell_value(index[0],index[1]))
python中的xlrd模块学习的更多相关文章
- Python中re(正则表达式)模块学习
re.match re.match 尝试从字符串的开始匹配一个模式,如:下面的例子匹配第一个单词. import re text = "JGood is a handsome boy, he ...
- python中的logging模块学习
Python的logging模块 Logging的基本信息: l 默认的情况下python的logging模块打印到控制台,只显示大于等于warning级别的日志 l 日志级别:critical ...
- python中的argparse模块学习
该模块是python用于解析命令行和参数的标准模块 好文推荐:http://blog.ixxoo.me/argparse.html,不仅域名个性,文章翻译的也很好.推荐
- python里面的xlrd模块详解(一)
那我就一下面积个问题对xlrd模块进行学习一下: 1.什么是xlrd模块? 2.为什么使用xlrd模块? 3.怎样使用xlrd模块? 1.什么是xlrd模块? python操作excel主要用到xlr ...
- python里面的xlrd模块详解
那我就一下面积个问题对xlrd模块进行学习一下: 1.什么是xlrd模块? 2.为什么使用xlrd模块? 3.怎样使用xlrd模块? 1.什么是xlrd模块? ♦python操作excel主要用到xl ...
- Python中的random模块,来自于Capricorn的实验室
Python中的random模块用于生成随机数.下面介绍一下random模块中最常用的几个函数. random.random random.random()用于生成一个0到1的随机符点数: 0 < ...
- Python中的random模块
Python中的random模块用于生成随机数.下面介绍一下random模块中最常用的几个函数. random.random random.random()用于生成一个0到1的随机符点数: 0 < ...
- 浅析Python中的struct模块
最近在学习python网络编程这一块,在写简单的socket通信代码时,遇到了struct这个模块的使用,当时不太清楚这到底有和作用,后来查阅了相关资料大概了解了,在这里做一下简单的总结. 了解c语言 ...
- 【转】浅析Python中的struct模块
[转]浅析Python中的struct模块 最近在学习python网络编程这一块,在写简单的socket通信代码时,遇到了struct这个模块的使用,当时不太清楚这到底有和作用,后来查阅了相关资料大概 ...
随机推荐
- maven 常用命名
maven项目,在命令行中操作,非常简洁.高效,现将maven项目常用命令行总结如下: maven命令行命令总结 序号 整理 统计 命令 作用 1 基本 5 mvn -v 查看maven版本 2 mv ...
- Bug调试专项训练四笔记
Ajax案例一 导入项目直接运行出现联想无反应 错误原因: 错误1: 55行找不到方法: 错误1解决方案: 解决错误1点击仍无反应 错误2:通过浏览器得出错误2:58行找不到方法 错误2解决方案: 解 ...
- Fork/Join 框架
本文部分摘自<Java 并发编程的艺术> Fork/Join 框架概述 Fork/Join 框架是 Java7 提供的一个用于并行执行任务的框架,是把一个大任务分割成若干个小任务,最终汇总 ...
- 开源框架TLog核心原理架构解析
前言 最近在做TLog 1.2.5版本的迭代,许多小伙伴之前也表示说很想参与开源项目的贡献.为了让项目更好更快速的迭代新特性以及本着发扬开源精神互相学习交流,很有幸招募到了很多小伙伴与我一起前行. 为 ...
- 「HTML+CSS」--自定义按钮样式【004】
前言 Hello!小伙伴! 首先非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出- 哈哈 自我介绍一下 昵称:海轰 标签:程序猿一只|C++选手|学生 简介:因C语言结识编程,随后转入计算机 ...
- servlet学习(一)
Tomcat 注:以下资料摘自孙鑫的<sevlet/JSP深入详解>,仅用于个人学习使用. 一.web技术的发展 早期web是静态页面的浏览,使用HTML编写,放入服务器. 1.1浏览器请 ...
- Java中的equals()和hashCode() - 超详细篇
前言 大家好啊,我是汤圆,今天给大家带来的是<Java中的equals()和hashCode() - 详细篇>,希望对大家有帮助,谢谢 文章纯属原创,个人总结难免有差错,如果有,麻烦在评论 ...
- Dapper, Ef core, Freesql 插入大量数据性能比较(一)
需求:导入9999行数据时Dapper, Ef core, Freesql 谁的性能更优,是如何执行的,级联增加谁性能更佳. 确认方法:sql server 的 sys.dm_exec_query_s ...
- QT程序发布
1.新建一个脚本文件,后缀为.bat 2.查看自己qt的windeployqt.exe路径,一般在QT安装的bin目录,而且脚本程序中需要去掉其后缀, 前面部分是windeployqt.exe的路径以 ...
- HashMap、ConcurrentHashMap 1.7和1.8对比
本篇内容是学习的记录,可能会有所不足. 一:JDK1.7中的HashMap JDK1.7的hashMap是由数组 + 链表组成 /** 1 << 4,表示1,左移4位,变成10000,即1 ...