9.亿级流量电商系统JVM模型参数预估方案
1. 需求分析
大促在即,拥有亿级流量的电商平台开发了一个订单系统,我们应该如何来预估其并发量?如何根据并发量来合理配置JVM参数呢?
假设,现在有一个场景,一个电商平台,比如京东,需要承担每天上亿的流量。现在开发了一个订单系统,那么这个订单系统每秒的并发量是多少呢?我们应该如何分配其内存空间呢?先来分析一下

每日亿级流量,平均一个用户点击量在20-30左右,通过这个计算出日活用户数约1亿/20=500万, 看的人多,买的人少,通常下单率不超过10%,我们按照留存率10%来计算,日均订单约50万单。这是分两种情况:
- 一种是普通流量,非特殊节假日,通常早上、中午、晚上非工作时间有1个小时的时间集中购买。我们按照早上1小时,中午1小时,晚上1小时来计算,也就是3小时。这样平均到每秒就是50万/3/3600=46, 也就是及时并发,通常我们的服务都是一个集群,有好几台服务器承受着几十并发,应该不成问题。
- 另一种是大促流量,比如双十一,基本流量都集中在双十一当天的投几分钟。这时每秒的并发量大概在50万/10/60=866,平均每秒并发量不到1000。这时服务集群有3台服务器,没太服务器承受的压力是400单/s。
2. 常规方案及问题暴露
对于这每秒400但会产生多大的对象呢?
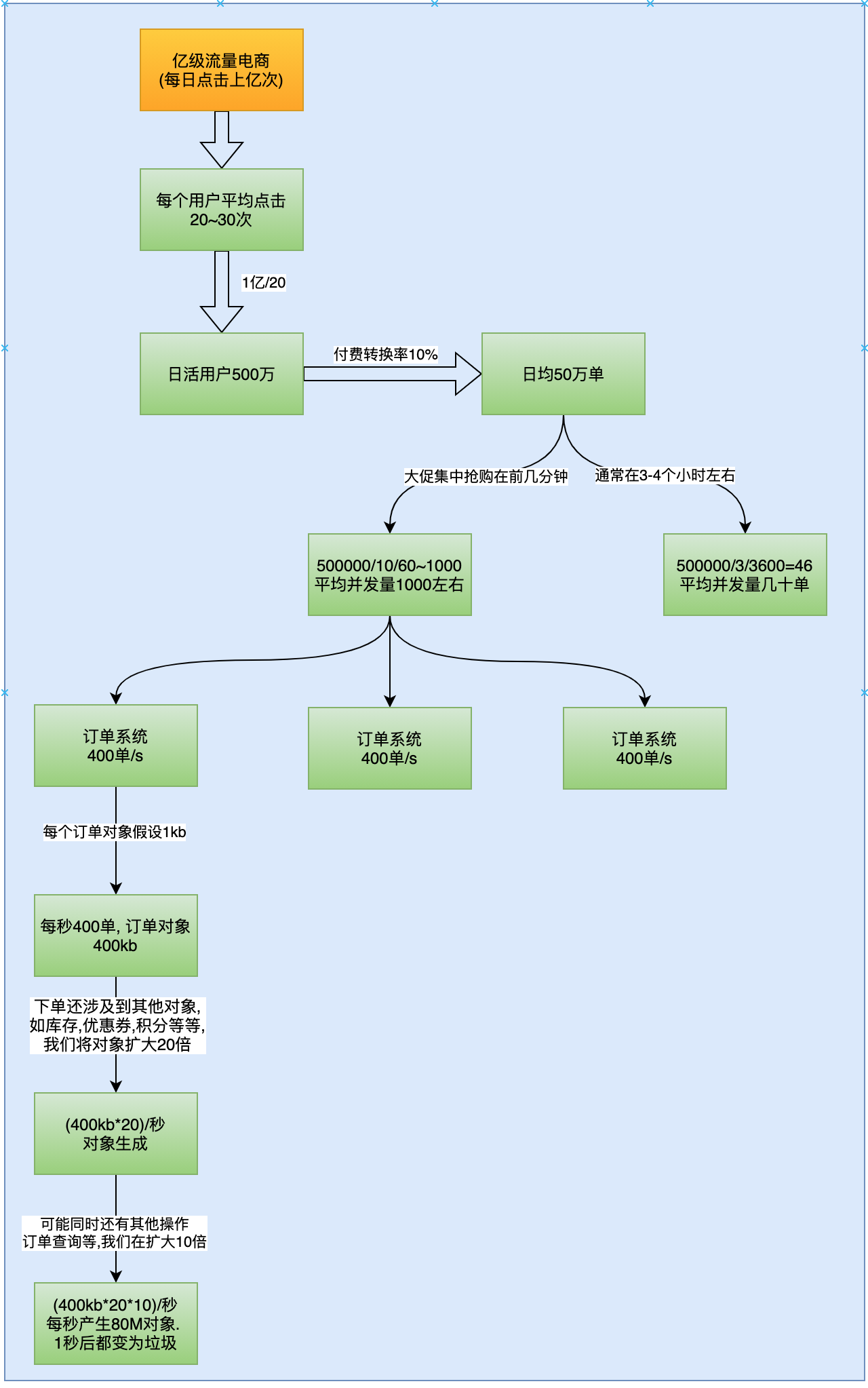
我们假设订单对象的大小是1kb,实际上订单对象的大小和订单对象中的字段有关系,我们假设是1kb。每秒400单,也就是会产生400kb的订单对象。下单还涉及到其他对象,比如库存,优惠券,积分等等,我们将对象扩大20倍, 大约是(400kb*20)/秒. 可能同时还有其他操作,比如查询订单的操作,我们再讲其扩大10倍,大约是80M,也就是每秒产生约80M的对象,这些对象在1s后都会变为垃圾。
对于一台4核8G的服务器来说,通常我们不设置JVM参数,也可能会根据物理机的8G内存来设置JVM参数。如果根据JVM参数来设置参数如何设置呢?
之前说过开启逃逸分析会将对象分配到栈上,我们这里计算分析的时候暂且忽略逃逸分析分配到栈上的对象,因为这部分对象相对来说比较少。下面我们来验证上面的预估算法是否准确,会有什么样的问题呢?
物理机有8G,分给os操作系统3G,分给JVM5G,然后JVM中给堆分配3G,元数据空间分配512M,线程栈分配1M等等。这是估算,不够精细,到底分配这么多空间够不够呢,会不会浪费呢?会产生什么样的问题呢?
设置jvm参数大致如下:
-Xms3072M -Xmx3072M -Xss1M -XX:MetaspaceSize=512M -XX:MaxMetaspaceSize=512M
这样设置到底行不行呢?有没有问题呢?我们来看看运行时数据区:

根据计算
- 整个堆空间3G
- Eden区800M
- s1/s2各100M
- 方法区512M
- 一个线程1M
按照这个模型来分析,得到如下结果:
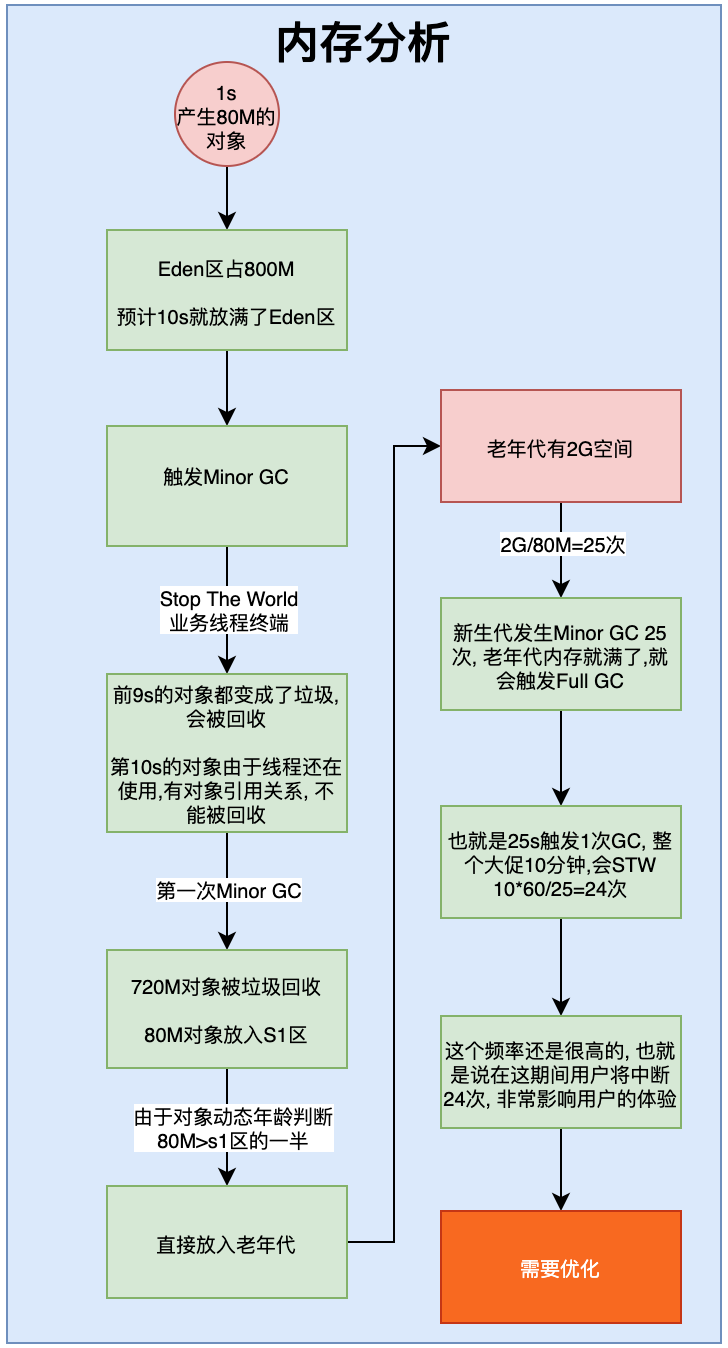
- 大促期间1s产生80M的对象数据。我们知道对象数据都是放在Eden园区,Eden园区一共800M,那么大约10s就放满了,放满了就会触发Minor GC
- 触发Minor GC的期间,会Stop The World暂停业务线程。在第10s触发MinorGC的时候,前9s的720M数据都已经变成垃圾了,会被回收掉,最后1s的80M数据由于还有对象引用,只是暂停了业务线程,因此不是垃圾,不能被回收。会被放入S1区。
- 在Survivor区有一个对象动态年龄判断机制。什么是对象动态年龄判断机制呢?
当前放对象的Survivor区域里(其中一块区域,放对象的那块s区),一批对象的总大小大于这块Survivor区域内存大小的50%(-XX:TargetSurvivorRatio可以指定),那么此时大于等于这批对象年龄最大值的对象,就可以直接进入老年代了,
例如:Survivor区域里现在有一批对象,年龄1+年龄2+年龄n的多个年龄对象总和超过了Survivor区域的50%,此时就会把年龄n(含)以上的对象都放入老年代。这个规则其实是希望那些可能是长期存活的对象,尽早进入老年代。
对象动态年龄判断机制一般是在minor gc之后触发的。
也就是说当在Survivor区经过几代的回收以后,如果对象总和大于Survivor区域的一半,则会直接放入到老年代。Survivor是100M,第10s的对象是80M,大于100M,会直接将这个对象放入到老年代。

- 老年代一共有2G空间,2G空间执行多少次会满呢?2G/80M=25次,也就是发生25次(25秒)Minor GC就会触发一次Full GC。这个频率就太高了,通常应该要很少触发Full GC,起码也得1个小时触发一次。而触发的原因是因为垃圾对象(这些对象1s后都变成垃圾了),这样肯定是不行的。我们需要优化JVM参数。
3. JVM优化
有问题有就解决问题。问题的根本原因是老年代发生了Full GC,为什么会发生Full GC呢?
之所以80M对象会放到了老年代是因为每秒产生的数据 大于 Survivor区空间的一半。所以,我们可以调整Survivor区大小。通常我们不会修改默认的Eden:S1:S2的比例,所以,我们可以考虑从整体扩大新生代的内存空间。假设我们扩大到2G,让老年代是1G。

这时会怎么样呢?
- Young区占2G,Eden区有1.6G, S1、S2各有200M。
这时在分析:
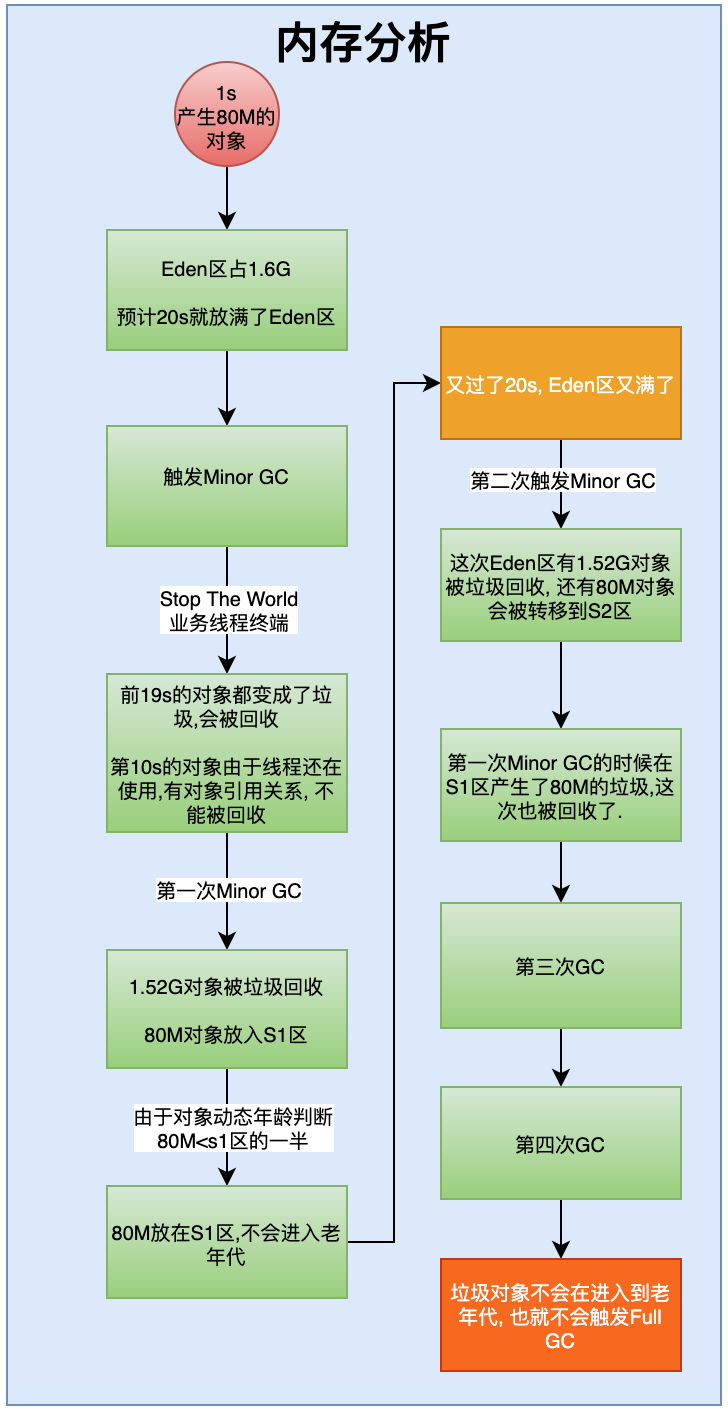
- Eden区有1.6G,每秒产生80M的对象放到Eden区,大约1.6G/80=20s放满。
- 放满以后触发Minor GC, 此时前19s的对象都已经成为垃圾被回收,第20s的对象被转移到S1区。
- 此时,S1区有200M,80<S1区空间的一半,所以不会转移到老年代。这样第一次GC结束
- 又过了20s,进行第二次Minor GC,这次Eden区又产生了1.52G的垃圾被回收,之前在S1区的80M对象也已经变成垃圾被回收。新的80M对象被放入到S2区。没有进入到老年代。
- 以此类推,第三次,第四次,垃圾对象不会再进入老年代,因此也不会在发生Full GC.
由此分析,大大降低了Full GC发生的频率。
最终参数设置:
-Xms3072M -Xmx3072M -Xmn2048M -Xss1M -XX:MetaspaceSize=512M -XX:MaxMetaspaceSize=512M
为了更清晰的看到效果,可以打印GC详细日志
-XX:+PrintGCDetails
4. 总结
通过上面的数据分析,我们要养成一个习惯,做任何事情都是要有理有据,不能是拍脑袋就说出来的。一定要能够经得起验证的。
9.亿级流量电商系统JVM模型参数预估方案的更多相关文章
- 12. 亿级流量电商系统JVM模型参数二次优化
亿级流量电商系统JVM模型参数预估方案,在原来的基础上采用ParNew+CMS垃圾收集器 一.亿级流量分析及jvm参数设置 1. 需求分析 大促在即,拥有亿级流量的电商平台开发了一个订单系统,我们应该 ...
- java亿级流量电商详情页系统的大型高并发与高可用缓存架构实战视频教程
亿级流量电商详情页系统的大型高并发与高可用缓存架构实战 完整高清含源码,需要课程的联系QQ:2608609000 1[免费观看]课程介绍以及高并发高可用复杂系统中的缓存架构有哪些东西2[免费观看]基于 ...
- P9架构师讲解从单机至亿级流量大型网站系统架构的演进过程
阶段一.单机构建网站 网站的初期,我们经常会在单机上跑我们所有的程序和软件.此时我们使用一个容器,如tomcat.jetty.jboos,然后直接使用JSP/servlet技术,或者使用一些开源的框架 ...
- 阿里P9架构师讲解从单机至亿级流量大型网站系统架构的演进过程
阶段一.单机构建网站 网站的初期,我们经常会在单机上跑我们所有的程序和软件.此时我们使用一个容器,如tomcat.jetty.jboos,然后直接使用JSP/servlet技术,或者使用一些开源的框架 ...
- 电商系统中的商品模型的分析与设计—续
前言 在<电商系统中的商品模型的分析与设计>中,对电商系统商品模型有一个粗浅的描述,后来有博友对货品和商品的区别以及属性有一些疑问.我也对此做一些研究,再次简单的对商品模型做一个介 ...
- 案例实战:每日上亿请求量的电商系统,JVM年轻代垃圾回收参数如何优化?
出自:http://1t.click/7TJ 目录: 案例背景引入 特殊的电商大促场景 抗住大促的瞬时压力需要几台机器? 大促高峰期订单系统的内存使用模型估算 内存到底该如何分配? 新生代垃圾回收优化 ...
- 每日上亿请求量的电商系统,JVM年轻代垃圾回收参数如何优化? ----实战教会你如何配置
目录: 案例背景引入 特殊的电商大促场景 抗住大促的瞬时压力需要几台机器? 大促高峰期订单系统的内存使用模型估算 内存到底该如何分配? 新生代垃圾回收优化之一:Survivor空间够不够 新生代对象躲 ...
- 亿级流量场景下,大型缓存架构设计实现【1】---redis篇
*****************开篇介绍**************** -------------------------------------------------------------- ...
- SpringCloud 亿级流量 架构演进
疯狂创客圈 Java 高并发[ 亿级流量聊天室实战]实战系列 [博客园总入口 ] 架构师成长+面试必备之 高并发基础书籍 [Netty Zookeeper Redis 高并发实战 ] 前言 Crazy ...
随机推荐
- 分治算法:Tromino谜题,L型覆盖
1 public class Tromino { 2 3 static int num = 2; 4 //x 对应 第二维 5 //y 对应 第一维 6 static int[][] panel = ...
- nacos配置
server: port: 3377 spring: application: name: nacos-config-client cloud: nacos: discovery: #nacos 服务 ...
- MySQL修改配置文件 避免中文乱码
MySQL修改配置文件 避免中文乱码 MySQL安装后默认的服务器字符集是拉丁文,也就是说默认 character_set_server = latin1 ,这是造成 MySQL 中文乱码的主要原因之 ...
- Nginx+Tomcat+Memcached实现session共享
实验环境: server1:nginx tomcat memcached server2:tomcat memcached Session是指一个终端用户与交互系统进行通信的时间间隔,通常指从注册进入 ...
- Redis详解(一)——
Redis详解1 https://www.cnblogs.com/MoYu-zc/p/14985250.html https://www.cnblogs.com/xiaoxiaotank/p/1498 ...
- windows 安装pip 及更换pip国内源
一.官网下载压缩包并解压. 官网:https://pypi.org/project/pip/#files 文件:选择.tar.gz版本 image 解压后,进入解压文件目录,在当前路径下打开cmd窗口 ...
- Spring中使用@within与@target的一些区别
目录 背景 模拟项目例子 看看使用@within和@target的区别 @within @target @target 看起来跟合理一点 通知方法中注解参数的值为什么是不一样的 想用@within,但 ...
- python库--tensorflow--scope命名方式
方法 参数 说明 .name_scope() with...: name 在其下使用Variable, 变量名(V_n)前会被加上'name/...'且相同V_n会自动添加后缀加以区分, 使用ge ...
- 支持Cron表达式、间隔时间的工具(TaskScheduler)
后台任务如何支持间隔时间.Cron表达式两种方式? 分享一个项目TaskScheduler,这是我从Furion项目中拷出来的 源码:https://gitee.com/dot-net-core/ta ...
- 详解Java中==和equals()的区别
众所周知,在 Java 编程中,程序员通常会使用==或equals()来简单的比较地址,内容是否相等.而这两者之间的使用区别,对于初学 Java 的同学来说可能会比较迷糊.我将根据下面的几段示例程序, ...