幻读:听说有人认为我是被MVCC干掉的
@

前言
我是幻读,听说有人认为我是MVCC解决的,为了让大家更全面地理解我,只能亲自来解释一下。
系列文章
1. 揭开MySQL索引神秘面纱
2. MySQL查询优化必备
3. 上来就问MySQL事务,瑟瑟发抖...
4. MVCC:听说有人好奇我的底层实现
一、我是谁?
先给大家做一个简单的自我介绍,我就是事务并发时会产生的三大问题之一。
我的其它俩兄弟脏读、不可重复读被MVCC在上一个回合无情的干掉了,至于上个回合发生了什么可以去看剧情回顾。
我的由来就是因为主人在操作一组数据时还有很多人也在对这组数据进行操作。
举一个简单的案例:
根据条件在对一组数据进行过滤返回的结果为100个,但是在主人操作的同时其他人又新增了符合条件的数据,然后主人再次进行查询时返回结果为101。第二次返回的数据跟第一次返回数据不一致。
于是我诞生了,大家还给我起了个很好听的名字幻读。
为什么会给我起这个名字呢!那是因为我给人们的现象好像出了幻觉一样。
二、为什么有人会认为我是被MVCC干掉的
为了演示方便,就直接使用之前的测试表来进行操作。
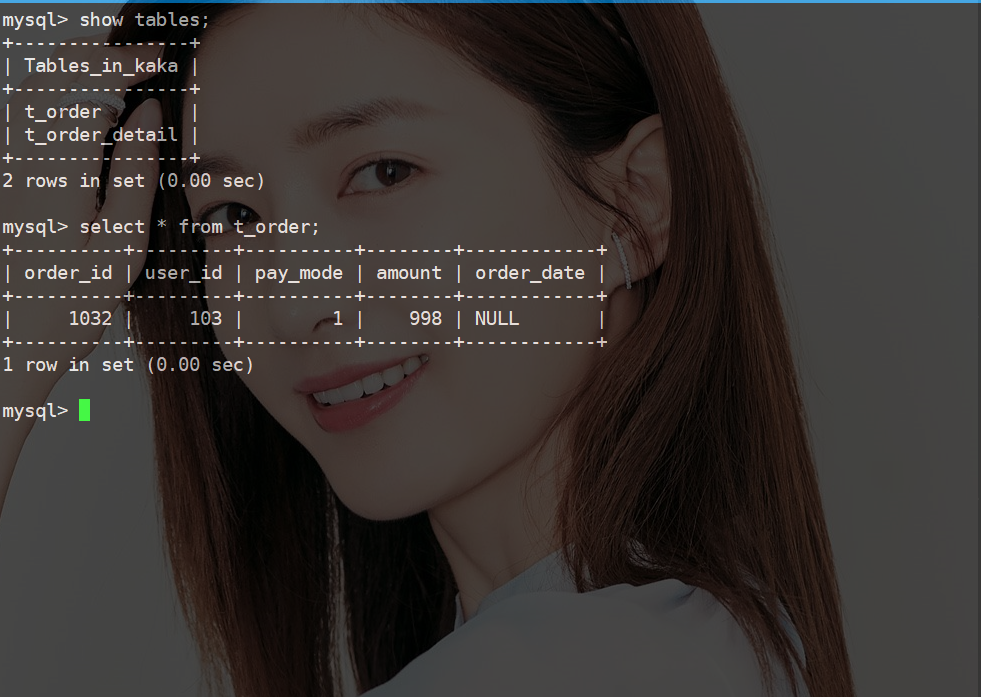
同时大家可以看到此表还有一些测试数据,一切从头开始,清空表。
清空表的命令truncate table_name
执行这个命令会使表的数据清空,并且自增ID会从1开始。
从执行过程来看,truncate table类似于drop table然后在create table,这里的环境都是测试环境,千万不要在线上进行操作,因为它绕过了DML方法,是不能回滚的。
进行了一点小插曲,进入正题。
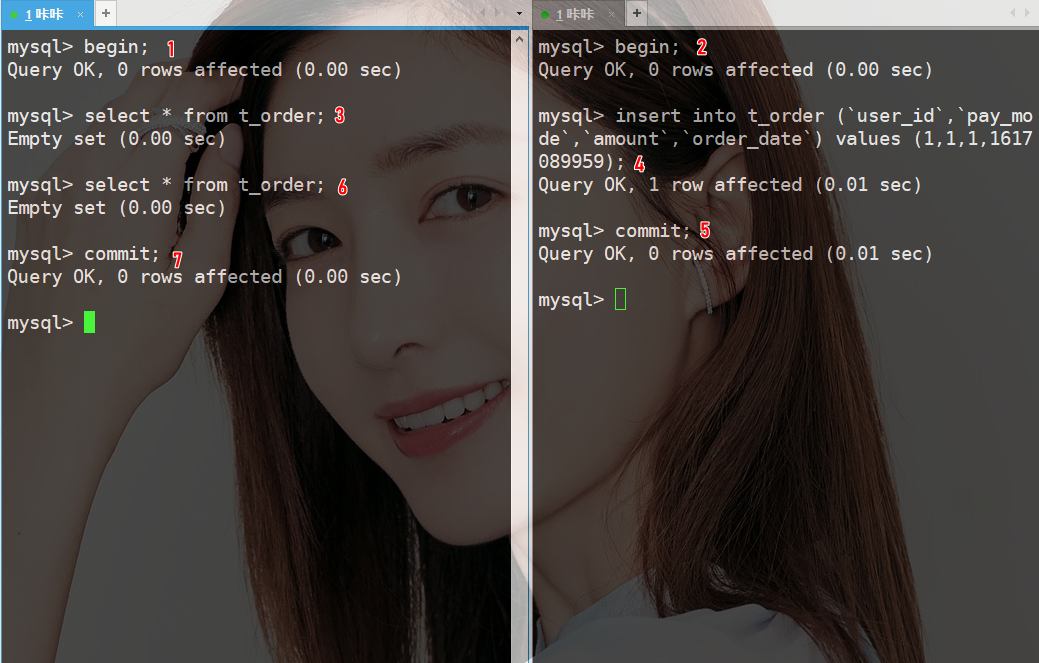
根据上图的执行步骤,预期来说左边事务的第一条select语句查询结果为空。
第二个select查询结果为1条数据,包含右边事务提交的数据。
但在实际测试的情况下,第一次执行select和第二次执行select返回结果一致。
从这个案例中,可以得出结论确实在不可重复隔离级别下会解决幻读问题(在快照读的前提下)。
三、我真的是被MVCC解决的?
通过上述测试案例来看,貌似在MySQL中通过MVCC就解决我的引来的问题,那既然都解决了我的问题,为什么还有串行化的隔离级别呢!好疑惑啊!
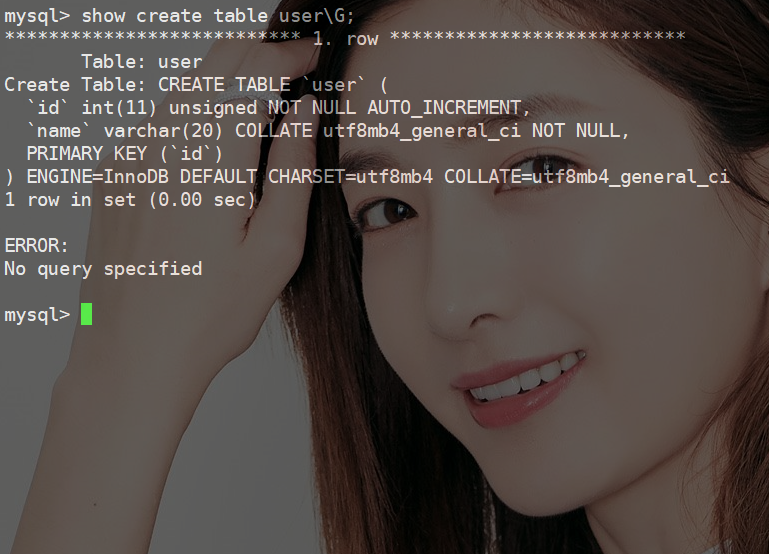
带着这个疑问继续进行实验,为了方便就不再使用上边表结构了,建立一个简单的表结构。
再进入一个小插曲你知道在MySQL终端如何清屏吗?
执行命令system clear即可
接着开始新一轮的测试
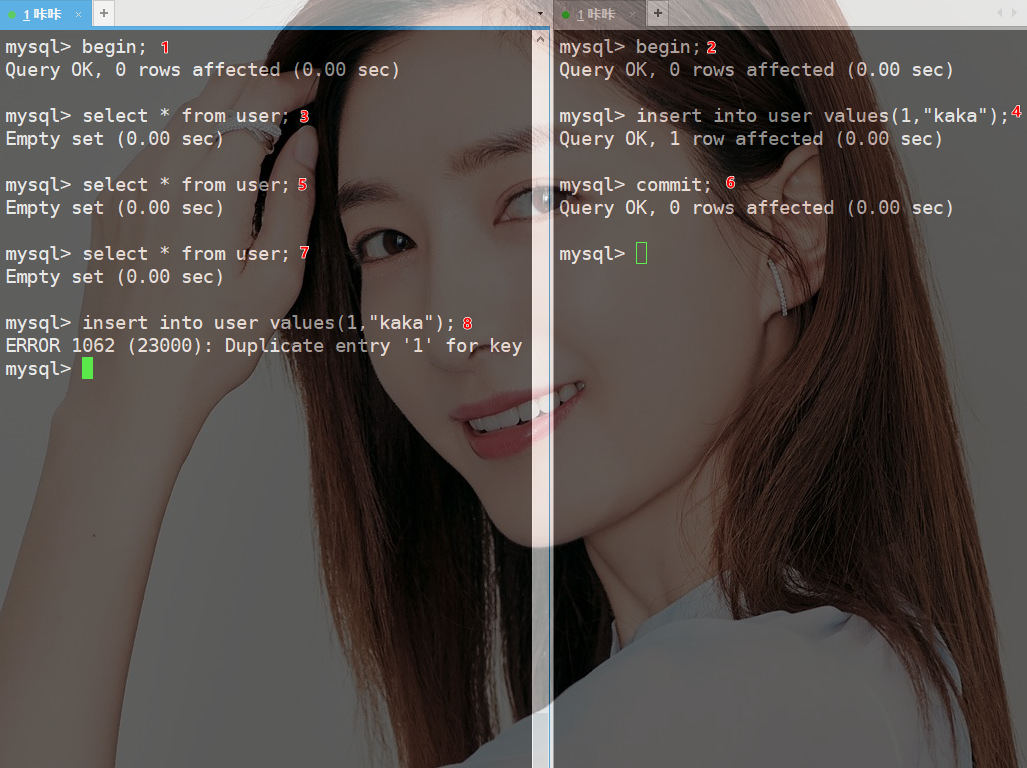
上图案例事务1几次查询数据都是空。
此时事务2已经成功将数据插入并且提交。
但当事务1几次查询数据为空之后进行数据插入时,提示主键重复。
再来看一个案例
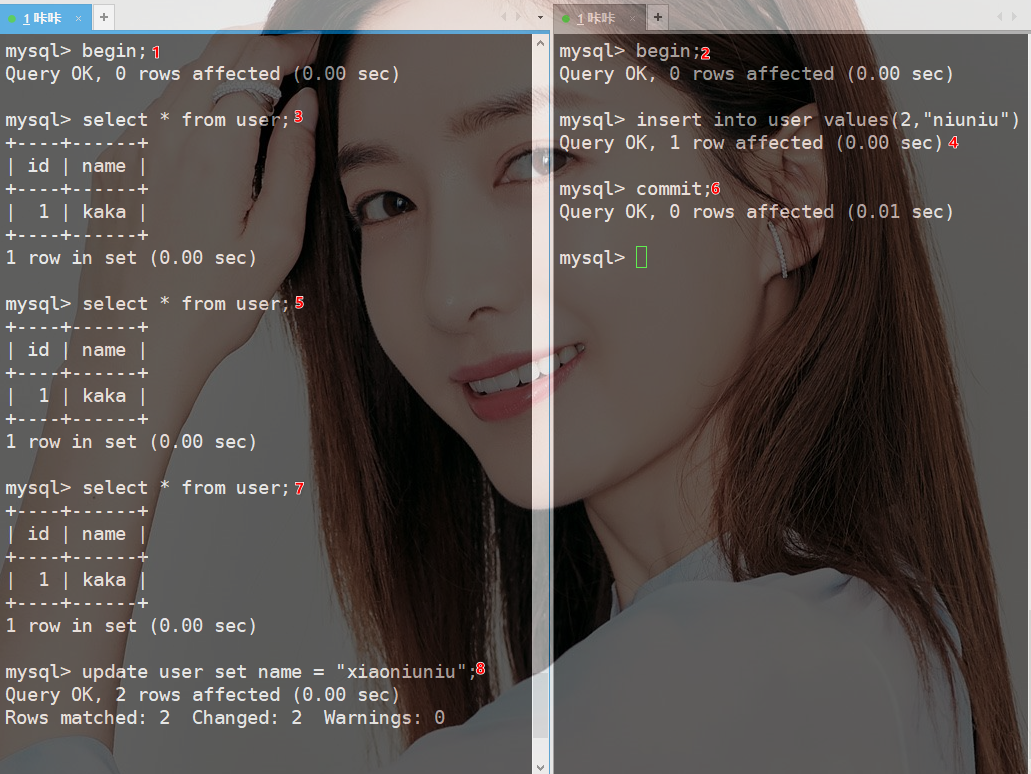
- step1:事务1开启事务
- step2:事务2开启事务
- step3:事务1查询数据只有一条数据
- step4:事务2添加一条数据
- step5:事务1查询数据为一条
- step6:事务2提交事务
- step7:事务1查询数据为一条
- step8:事务1修改name
- step9:猜想一下此时表内数据会发生什么改变
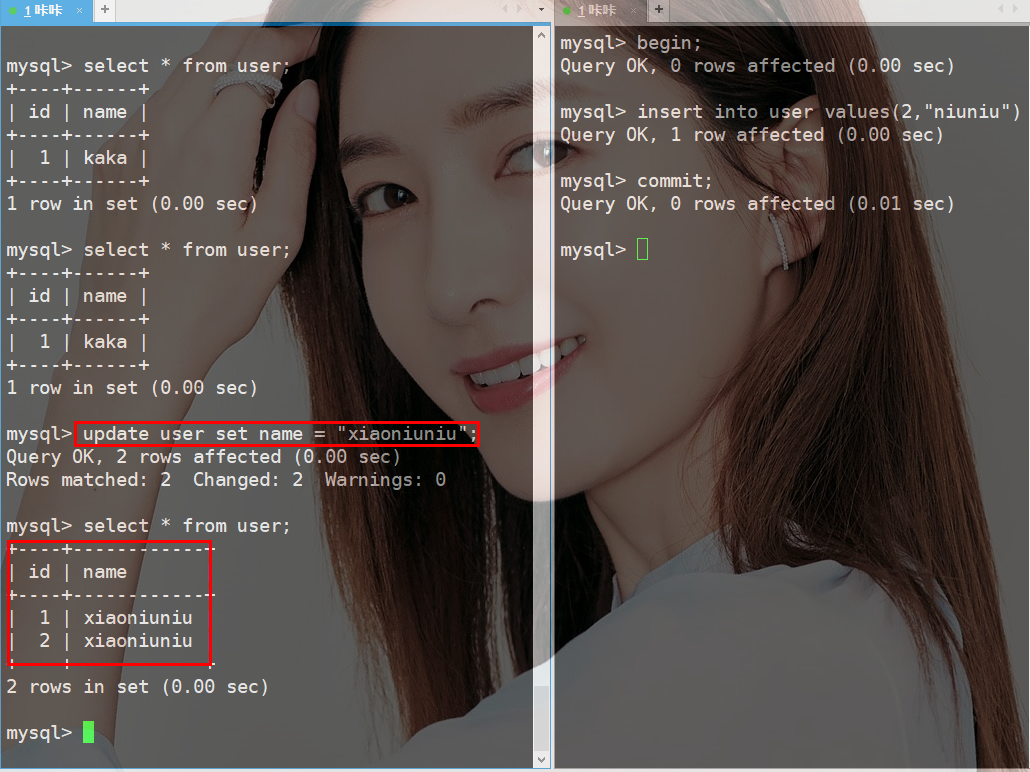
此案例中事务1始终读取数据都是一条数据,但是在修改数据时影响数据行数却是2,再次进行查看数据时竟然出现了事务2添加的数据。这也可以看作是一种幻读。
小结
通过以上俩个案例得知在MySQL可重复读隔离级别中并没有完全解决幻读问题,而只是解决了快照读下的幻读问题。
而对于当前读的操作依然存在幻读问题,也就是说MVCC对于幻读的解决是不彻底的。
四、再聊当前读、快照读
在上一回合中快照读、当前读已经被消化了,为了防止消化不良这里再简单说明一下。
当前读
所有操作都加了锁,并且锁之间除了共享锁都是互斥的,如果想要增、删、改、查时都需要等待锁释放才可以,所以读取的数据都是最新的记录。
简单来说,当前读就是加了锁的,增、删、改、查,不管锁是共享锁、排它锁均为当前读。
在MySQL的Innodb存储引擎下,增、删、改操作都会默认加上锁,所以增、删、改操作默认就为当前读。
快照读
快照读的出现旨在提高事务并发性,实现基于我的敌人MVCC
简单来说快照读就是不加锁的非阻塞读,即简单的select操作(select * from user)
在Innodb存储引擎下执行简单的select操作时,会记录下当前的快照读数据,之后的select会沿用第一次快照读的数据,即使有其它事务提交也不会影响当前的select结果,这就解决了不可重复读问题。
快照读读取的数据虽然是一致的,但有可能不是最新的数据而是历史数据。
五、告诉你们吧!当前读的情况下我是被next-key locks干掉的
第二小节中得知在快照读下由于我引发的问题已经被MVCC消灭了。
但是在小节三进行案例测试发现在当前读下我又满血复活了。
我要是那么容易被干掉还怎么被称为打不死的小强,这不是闹笑话呢!
说归说,闹归闹如果MVCC把它的小弟next-key locks带上那我就完了,就不再像灰太狼说经典语录“我一定会回来的”
此时就要思考一个问题,在Innodb存储引擎下,是默认给快照读加next-key locks,还是说需要手动加锁。
通过官方文档对于next-key locks的解释。
To prevent phantoms, InnoDB uses an algorithm called next-key locking that combines index-row locking with gap locking. InnoDB performs row-level locking in such a way that when it searches or scans a table index, it sets shared or exclusive locks on the index records it encounters. Thus, the row-level locks are actually index-record locks. In addition, a next-key lock on an index record also affects the “gap” before that index record. That is, a next-key lock is an index-record lock plus a gap lock on the gap preceding the index record. If one session has a shared or exclusive lock on record R in an index, another session cannot insert a new index record in the gap immediately before R in the index order.
大致意思,为了防止幻读,Innodb使用next-key lock算法,将行锁(record lock)和间隙锁(gap lock)结合在一起。Innodb行锁在搜索或者扫描表索引时,会在遇到的索引记录上设置共享锁或者排它锁,因此行锁实际是索引记录锁。另外, 在索引记录上设置的锁同样会影响索引记录之前的“间隙(gap)”。即next-key lock是索引记录行加上索引记录之前的“gap”上的间隙锁定。
并且还给了一个案例SELECT * FROM child WHERE id > 100 FOR UPDATE;
当Innodb扫描索引时,会将id大于100地上锁,阻止任何大于100的数据添加。
到这里就回答了上边问题,在Innodb下解决当前读产生的幻读问题需要手动加锁来解决。
再来看一个案例
下图为此时的数据情况
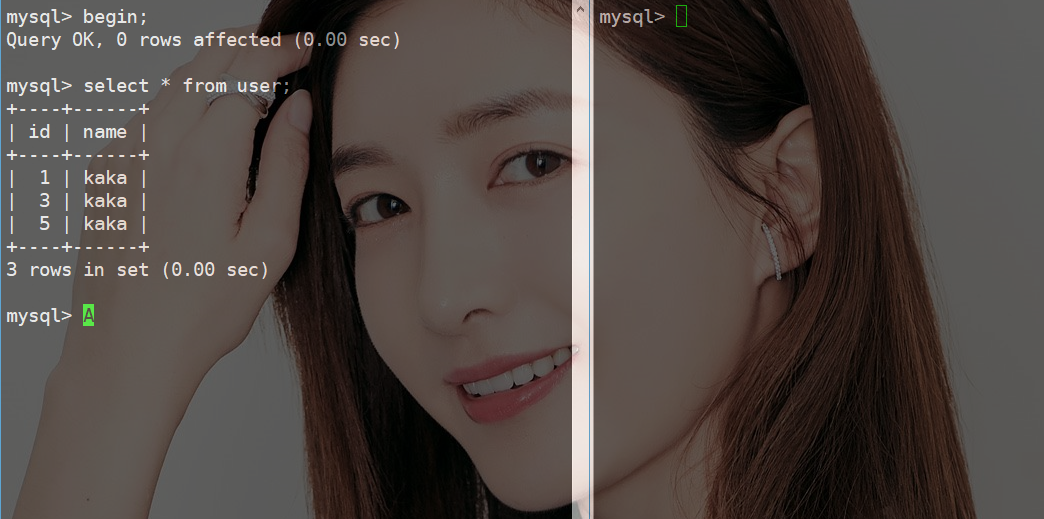
下图的这个案例就解决了在第三节中第一个案例的幻读问题。
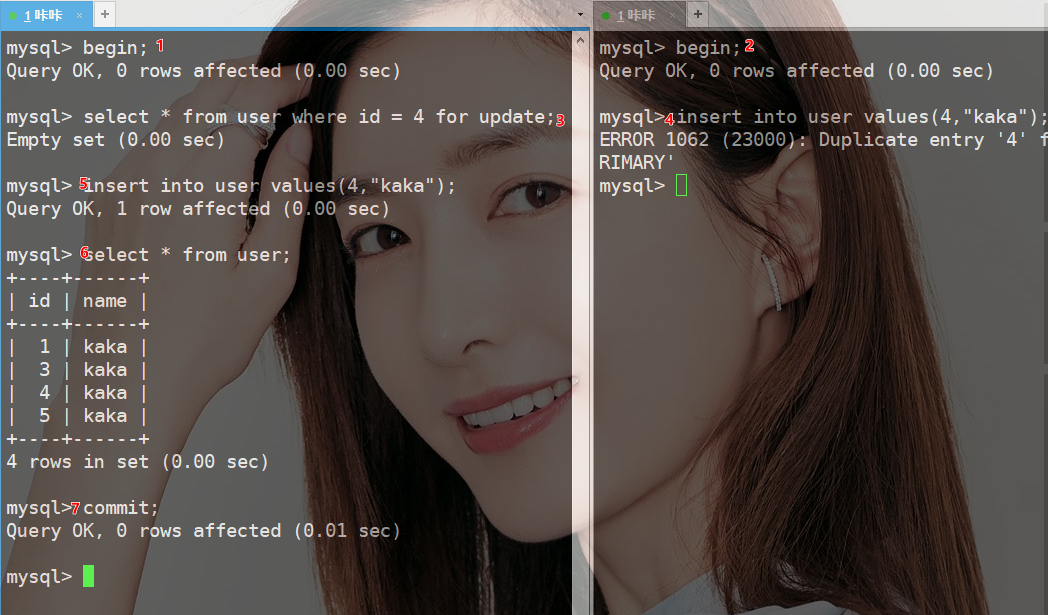
- step事务1:开启事务
- step事务2:开启事务
- step事务1:查询ID为4的这条数据并且加上排它锁
- step事务2:添加ID为4的数据,并且等待事务1释放锁
- step事务1:添加ID为4的数据,添加成功
- step事务1:查询当前数据
- step事务1:提交事务
- step事务2:报错,返回主键重复问题。
这个案例查询的索引列是主键并且是唯一的,此时Innodb引擎会对next-key lock做降级处理,也就是只锁定当前查询的索引记录行,而不是范围锁定。
案例二
还是使用上边的数据,但是这次我们进行一次范围查找。
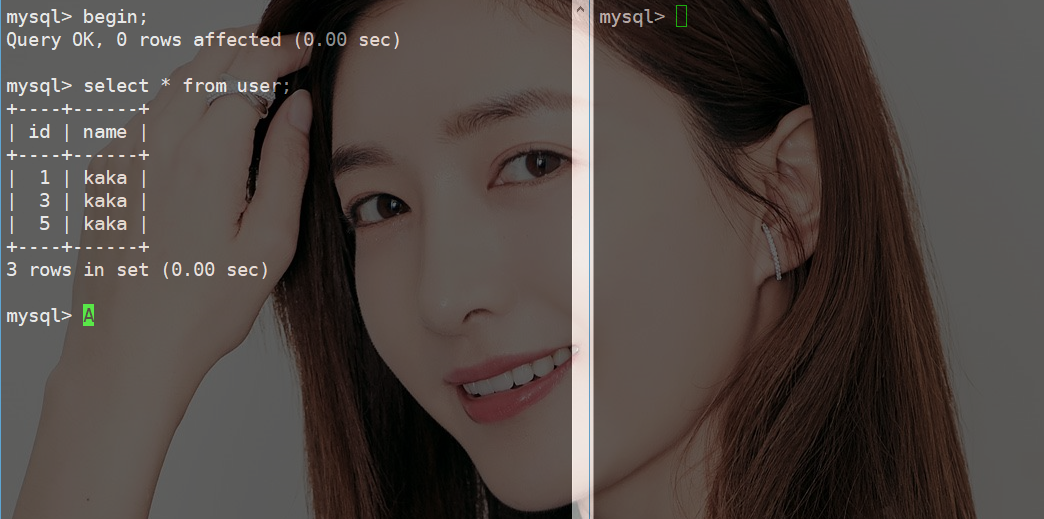
此时的数据为1,3,5,查找的范围为大于3。
从下图可以看出当事务2执行添加ID为2的是可以添加成功的。
但是当添加 ID 6时需要等待。
此时若事务1不提交事务,事务2添加ID为6的这条数据就执行不成功。
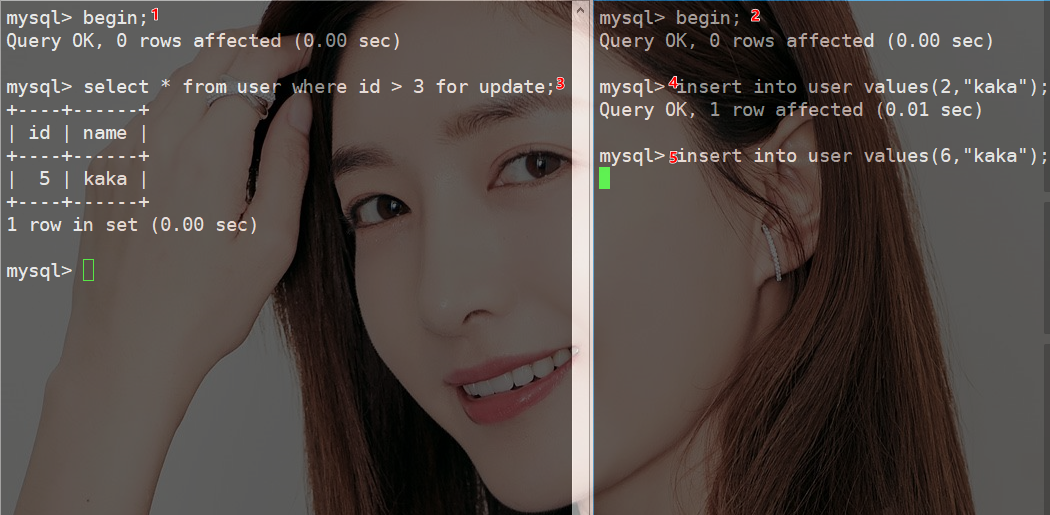
对于上述的SQL语句select * from user where id > 3 for update;执行返回的只有5这一行数据。
此时锁定的范围为(3,5],(5,∞),所以说id为2的可以插入,ID为4或者大于5的都是插入不了的。
以上就是在Innodb中解决幻读问题最终方案。
六、幻读解决方案
为了方便大家直观了解幻读的解决方案,这里咔咔进行简单的总结。
通过MVCC解决了快照读下的幻读问题,为什么能解决?在第一次执行简单的select语句就生成了一个快照,并且在后边的select查询都是沿用第一次快照读的结果。所以说快照读查询到的数据有可能是历史数据。
通过next-key lock解决当前读的幻读问题,next-key lock是record lock和gap lock的结合,锁定的是一个范围,如果查询数据为索引记录行,则只会锁定当前行,也就是说降级为record lock。若为范围查找时就会锁定一个范围,例如上例中ID为1,3,5查询大于3的数据,则会把(3,5],(5,∞)进行范围锁定,其它事务在锁未释放之前是无法插入的。
从官方文档还可得知如果需要验证数据唯一性只需要给查询加上共享锁即可,也就是给select 语句加上 in lock share mode,如果返回结果为空,则可以进行插入,并且插入的这个值肯定是唯一的。同样也可以添加next key lock防止其他人同时插入相同数据,小节5的所有案例就是使用的next-key lock,从这一点可以得知next-key lock是可以锁定表内不存在的索引。
根据上述结论来看,如果想要检测数据唯一性使用共享锁,那么多个事务同时开启共享锁,又同时添加相同的数据怎么办,会不会出现问题呢?明确地说明是不会的,如果多个事务同时插入相同数据只会有一个事务添加成功,其它事务会抛出错误,这个就是一个新的概念“死锁”。
七、扩展
事务ID是在何时分配的?
在本文或者其它资料中都能得到一个信息就是当执行一条简单的select语句同时也会生成read-view。
虽然快照读、read-view都是基于事务启动的前提下,但是read-veiw是通过未提交事务ID组成的。
那么到底是在何时分配事务ID的呢?
事务的启动方式有两种,分别为显示启动、另一种是设置autocommit=0后执行select就会启动事务。
在显示启动中最简单的就是以begin语句开始,也可以使用start transaction开启事务。
若使用start trancaction开启事务也可以选择开始只读事务还是读写事务。
看了很多资料都说当开启一个事务时会分配一个事务ID,那么来验证一下是这个样子的吗?
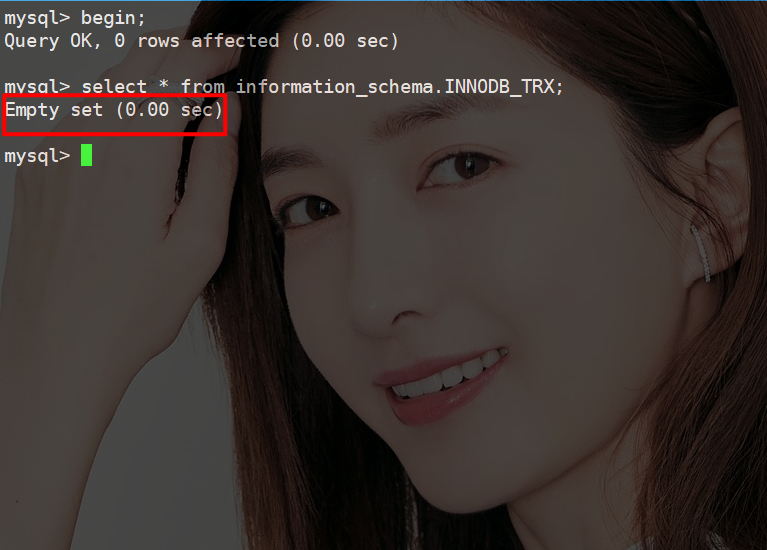
通过上图可以看到当执行一个begin语句之后查询事务ID是空的,也就说当执行begin后并没有分配trx_id。
那么当执行begin后在支持DML语句呢!
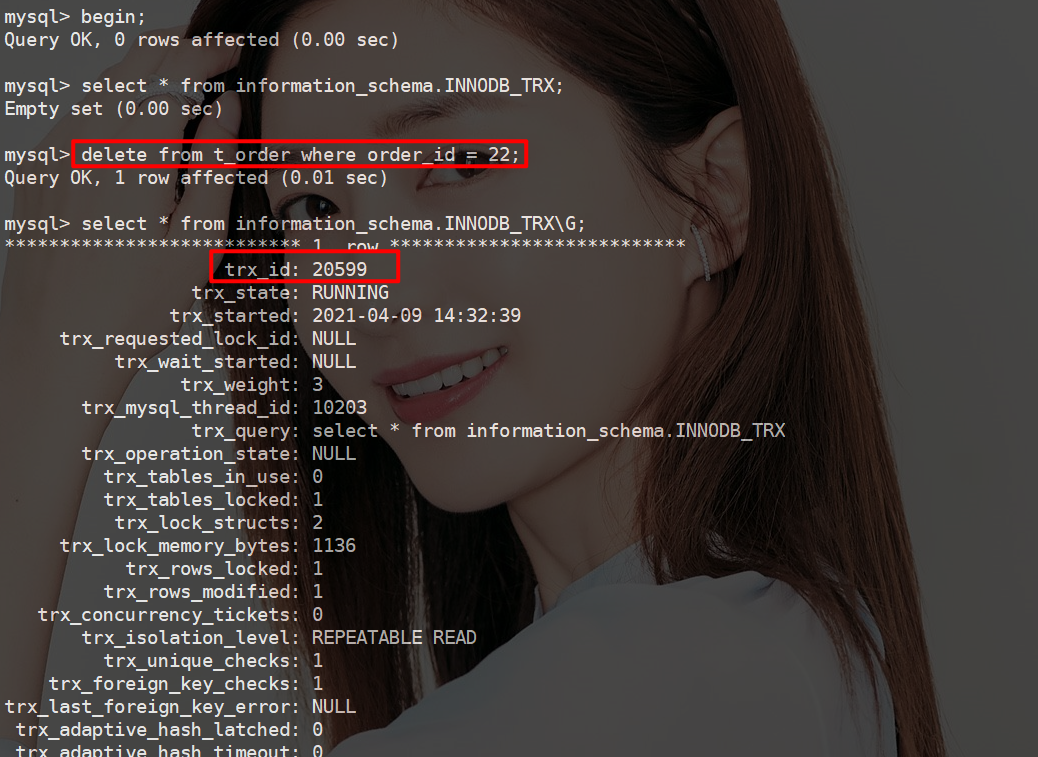
根据文档得知
执行begin命令并不是真正开启一个事务,仅仅是为当前线程设定标记,表示为显式开启的事务。
所以要明白对数据进行了增、删、改、查等操作后才算真正开启了一个事务,此时会去引擎层开启事务。
为什么事务ID差异特别大?

上图中查询了当前活跃的事务ID,但是两个事务ID的差异特别大。
相信很多小伙伴都遇到过这个问题,有问题不害怕,害怕的是没有问题。
事实上在这两条数据中只有20841是真正的事务ID,那么第二条数据中的ID是什么呢!
想知道这个数字是什么的前提是知道是怎么来的。
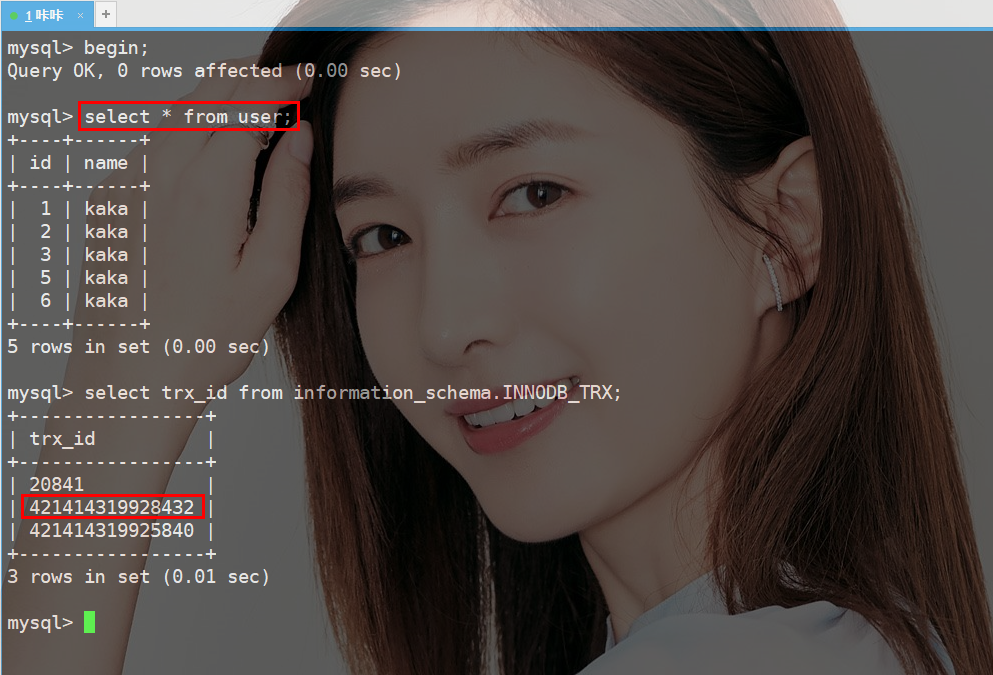
从上图可以看出,当执行select语句后会产生一个非常大的事务ID,那能不能理解为这种差异非常大的事务ID是通过快照读的方式才会生成的。
接着再这个事务下面在执行一个insert语句,然后再查看一下事务ID的状态
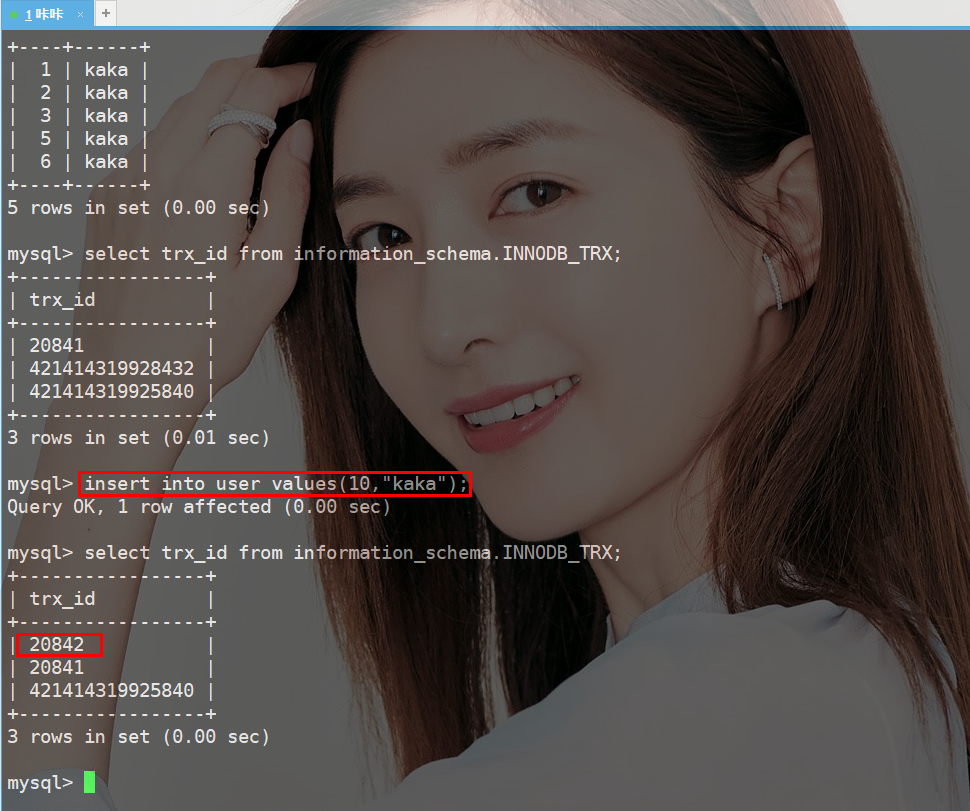
不可思议的是在事务中先执行select语句,然后执行insert语句,事务ID发生了变化,这是什么原因呢?
经过资料查询得知当执行一个简单的select语句时,被称之为只读事务,为了避免给只读事务分配trx_id带来不必要的开销就没有对其分配事务ID。只读事务没有分配undo segment也不会分配LOCK锁结构,本质上只读事务的trx_id的值就是0,但是为了执行select * from information_schema.INNODB_TRX或者show engine innodb status时就会通过reinterpret_cast(trx) | (max_trx_id + 1)将指针转换为一个64字节非负整数然后位或(max_trx_id + 1) 就是这么个值。
关于这个值的生成过程就不用再去深究了,只需要知道在只读事务下是不会分配事务ID,而查询出来的这个值只是为了显示而存在的没有实际意义。
但是当你执行select * from information_schema.INNODB_TRX查询出来的事务ID,再通过show engine innodb status查询是查不到的。在Innodb下如果事务为只读事务则不会在Innodb数据结构中显示,因此你是看不到的。
坚持学习、坚持写作、坚持分享是咔咔从业以来一直所秉持的信念。希望在偌大互联网中咔咔的文章能带给你一丝丝帮助。我是咔咔,下期见。
幻读:听说有人认为我是被MVCC干掉的的更多相关文章
- 关于MySQL幻读的实验
该实验基于 CentOS 7 + MySQL 5.7 进行 打开两个窗口连接到MySQL 第一个连接的事务我们命名为 T1 第二个连接的事务我们命名为 T2 T2 发生在 T1 的 O1 操作结束以 ...
- MySQL到底有没有解决幻读问题?这篇文章彻底给你解答
MySQL InnoDB引擎在Repeatable Read(可重复读)隔离级别下,到底有没有解决幻读的问题? 网上众说纷纭,有的说解决了,有的说没解决,甚至有些大v的意见都无法达成统一. 今天就深入 ...
- MVCC 能解决幻读吗?
MySQL通过MVCC(解决读写并发问题)和间隙锁(解决写写并发问题)来解决幻读 MySQL InnoDB事务的隔离级别有四级,默认是“可重复读”(REPEATABLE READ). 未提交读(REA ...
- mysql幻读、MVCC、间隙锁、意向锁(IX\IS)
IO即性能 顺序主键写性能很高,由于B+树的结构,主键如果是顺序的,则磁盘页的数据会按顺序填充,减少数据移动,随机主键则可能由于记录移动产生很多io 查询二级索引时,会再根据主键id获取数据页,产生一 ...
- InnoDB解决幻读的方案——LBCC&MVCC
最近要在公司内做一次技术分享,思来想去不知道该分享些什么,最后在朋友的提示下,准备分享一下MySQL的InnoDB引擎下的事务幻读问题与解决方案--LBCC&MVCC.经过好几天的熬夜通宵,终 ...
- MySQL之MVCC与幻读
转自 https://blog.csdn.net/qq_31930499/article/details/110393988 如果是快照度,直接采用MVCC,如果是当前读,才会走next-key lo ...
- 面试官:MySQL的幻读是怎么被解决的?
大家好,我是小林. 我之前写过一篇数据库事务的文章「 事务.事务隔离级别和MVCC」,这篇我说过什么是幻读. 在这里插入图片描述 然后前几天有位读者跟我说,我这个幻读例子不是已经被「可重复读」隔离级别 ...
- 【面试普通人VS高手系列】innoDB如何解决幻读
前天有个去快手面试的小伙伴私信我,他遇到了这样一个问题: "InnoDB如何解决幻读"? 这个问题确实不是很好回答,在实际应用中,很多同学几乎都不关注数据库的事务隔离性. 所有问题 ...
- 【Java面试】这应该是面试官最想听到的回答,Mysql如何解决幻读问题?
"Mysql如何解决幻读问题" 一个工作了4年小伙伴,去一个美团面试,遇到了这样一个问题. 大家好,我是Mic,一个工作了14年的Java程序员 关于这个问题,面试官想考察什么?我 ...
随机推荐
- List转String数组 collection.toArray(new String[0])中new String[0]的语法解释
Collection的公有方法中,toArray()是比较重要的一个. 但是使用无参数的toArray()有一个缺点,就是转换后的数组类型是Object[]. 虽然Object数组也不是不能用,但当你 ...
- eclipse快速定位当前类所在位置
如何快速的找到一个类并且定位它所在的位置呢?这里以搜索Menu类为例说明. 可以通过CTRL + SHIFT +R的组合键,输入Menu 双击Menu.java即可跳转到对应的类上,但此时还不知道此类 ...
- Python3.x 基础练习题100例(51-60)
练习51: 题目: 学习使用 按位与(&) . 分析: 0&0=0; 0&1=0; 1&0=0; 1&1=1. 程序: if __name__ == '__ma ...
- 公钥基础设施PKI利用SRAM物理不可克隆函数PUF实现芯片标识唯一性
下面给出PKI利用SRAM PUF实现芯片标识唯一性的方法思路: PKI利用SRAM PUF实现芯片标识唯一性的方式 (1)使用PUF原因 物理上不可克隆函数利用硅制造的自然变化来产生每个芯片统计上唯 ...
- CCF(管道清洁):最小费用最大流
管道清洁 201812-5 需要清洁的管道下界为1, 不需要清洁的管道下界为0, 可重复经过的管道上界为正无穷, 不可重复经过的管道上界为1. 这属于无源无汇的有容量下界的最小费用可行流.解决的方法就 ...
- bouncycastle中添加HMAC-SM3支持
一. 最近看完了PKCS#5中的内容,总结一下自己添加HMAC-SM3中遇到的问题和解决方法. 大概通读BC java源码以后,开始上手修改. 在SM3.java中添加如下代码: /** * SM3 ...
- 手把手教你Spring Boot2.x整合Elasticsearch(ES)
文末会附上完整的代码包供大家下载参考,码字不易,如果对你有帮助请给个点赞和关注,谢谢! 如果只是想看java对于Elasticsearch的操作可以直接看第四大点 一.docker部署Elastics ...
- python 操作符** (两个乘号就是乘方)
一个乘号*,如果操作数是两个数字,就是这两个数字相乘,如2*4,结果为8**两个乘号就是乘方.比如3**4,结果就是3的4次方,结果是81 *如果是字符串.列表.元组与一个整数N相乘,返回一个其所有元 ...
- kubernetes生产实践之redis-cluster
方案一 自定义yaml文件安装redis cluster 背景 在Kubernetes中部署Redis集群面临挑战,因为每个Redis实例都依赖于一个配置文件,该文件可以跟踪其他集群实例及其角色.为此 ...
- Python开发环境从零搭建-02-代码编辑器Sublime
想要从零开始搭建一个Python的开发环境说容易也容易 说难也能难倒一片开发人员,在接下来的一系列视频中,会详细的讲解如何一步步搭建python的开发环境 本文章是搭建环境的第2篇 讲解的内容是:安装 ...