常用正则表达式RE(慕课网_Meshare_huang)

import re str1 = 'imooc python'
# str1.find('l1') 输出: -1
# str1.find('imooc') 0 # str1.startswith('imooc') True pa = re.compile(r'imooc') #加个r 代表是个原字符串
# pa = re.compile('imooc\n') \n会转译成一个换行符 # type: _sre.SRE_Pattern pa.match(str1)
ma = pa.match(str1)
# ma.span() (0, 5)
# ma.group() 'imooc' # ma.string 'imooc python'
# ma.re re.compile(r'imooc', re.UNICODE) pa1 = re.compile(r'_')
ma1 = pa1.match('_value')
# ma1.group <function SRE_Match.group> # pa re.compile(r'imooc', re.UNICODE) ma = pa.match('imooc python')
# ma.group() 'imooc' # pa = pa.match('imoOc python', re.I)
# type(pa) NoneType pa = re.compile(r'(imooc)', re.I) #组 大写的i
ma = pa.match(str1)
# ma.group() 'imooc'
# ma.groups() ('imooc',) # ma = re.match(r'imooc', str1)
# ma <_sre.SRE_Match object; span=(0, 5), match='imooc'>
# ma.group() 'imooc'
语法
# . 匹配任意字符 除了\n
# ma = re.match(r'a', 'a')
# ma.group() 'a' # ma = re.match(r'.', 'b')
# ma.group() 'b' # ma = re.match(r'.', '0')
# ma.group() '0' # ma = re.match(r'{.}', '{a}')
# ma.group() '{a}' # ma = re.match(r'{..}', '{a0}')
# ma.group() '{a0}' # [...] 匹配字符集
# ma = re.match(r'{[abc]}', '{a}')
# ma.group() '{a}' # ma = re.match(r'{[abc]}', '{d}')
# ma.group() AttributeError: 'NoneType' object has no attribute 'group' # ma = re.match(r'{[a-z]}', '{d}')
# ma.group() '{d}' # ma = re.match(r'{[a-zA-Z]}', '{D}')
# ma.group() '{D}' # ma = re.match(r'{[a-zA-Z0-9]}', '{9}')
# ma.group() '{9}' # ma = re.match(r'{[\w]}', '{0}')
# ma.group() '{0}' # ma = re.match(r'{[\w]}', '{ }')
# ma.group() AttributeError: 'NoneType' object has no attribute 'group' # ma = re.match(r'{[\W]}', '{ }')
# ma.group() '{ }' # ma = re.match(r'{[[\w]]}', '[0]')
# ma.group() AttributeError: # ma = re.match(r'\[[\w]\]', '[0]') 要加转译字符
# ma.group() '[0]'
import re # ma = re.match(r'[A-Z][a-z]', 'Aa')
# ma.group() 'Aa' # ma = re.match(r'[A-Z][a-z]*', 'A')
# ma.group() 'A' # ma = re.match(r'[A-Z][a-z]*', 'AdsfafeadcxAe') 如果出现数字是匹配不上的
# ma.group() 'Adsfafeadcx' # _ = 10
# _ 10 # ma = re.match(r'[0-9]?[0-9]', '90')
# ma.group() '90' # ma = re.match(r'[0-9]?[0-9]', '9')
# ma.group() '9' # ma = re.match(r'[0-9]?[0-9]', '09')
# ma.group() '09' # ma = re.match(r'[a-zA-Z0-9]{6}', 'abc123')
# ma.group() 'abc123' # ma = re.match(r'[a-zA-Z0-9]', 'abc123')
# ma.group() 'a' # ma = re.match(r'[a-zA-Z0-9]{6}', 'abc123__')
# ma.group() 'abc123' # ma = re.match(r'[a-zA-Z0-9]{6}@163.com', 'abc123@163.com')
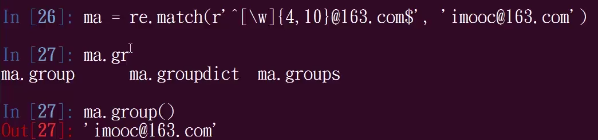
# ma.group() 'abc123@163.com' # ma = re.match(r'[a-zA-Z0-9]{6, 10}@163.com', 'imoocedu@163.com')
# ma.group() AttributeError: 'NoneType' object has no attribute 'group' # ma = re.match(r'[0-9][a-z]*?', '1bc')
# ma.group() '1' # ma = re.match(r'[a-zA-Z0-9]+?', '1bc')
# ma.group() '1'

# ma = re.match(r'\Aimooc[\w]', 'imoocpython') 边界匹配 # ma.group() 'imoocp'

# ma = re.match(r'abc|d', 'abc')
# ma.group() 'abc' # ma = re.match(r'[1-9]?\d$', '9')
# ma.group() '9' # ma = re.match(r'[1-9]?\d|100$', '100')
# ma.group() '10' # ma = re.match(r'[1-9]?\d|100$', '99')
# ma.group() '99' # ma = re.match(r'[1-9]?\d|100$', '9')
# ma.group() '9' # ma = re.match(r'[\w]{4, 6}@(163|126).com', 'imooc@163.com')
# ma.group() AttributeError: 'NoneType' object has no attribute 'group' # ma = re.match(r'[\w]{4, 6}@(163|126).com', 'imooc@126.com')
# ma.group() AttributeError: 'NoneType' object has no attribute 'group' # ma = re.match(r'<[\w]+>', '<book>')
# ma.group() '<book>' # ma = re.match(r'<([\w]+>)', '<book>')
# ma.group() '<book>' # ma = re.match(r'<([\w]+>)\1', '<book>')
# ma.group() AttributeError: 'NoneType' object has no attribute 'group' # ma = re.match(r'<([\w]+>)\1', '<book>book>')
# ma.group() '<book>book>' # ma = re.match(r'<([\w]>)[\w]+</\1', '<book>python</book>')
# ma.group() AttributeError: 'NoneType' object has no attribute 'group' # ma = re.match(r'<(?P<mark>[\w]>)[\w]+</(?P=mark)', '<book>python</book>')
# ma.group() AttributeError: 'NoneType' object has no attribute 'group'



import re
str1 = 'imooc videonum = 100'
# str1.find('100') # 17
info = re.search(r'\d+', str1)
# info # <_sre.SRE_Match object; span=(17, 20), match='100'>
str1 = 'imooc videonum = 10000'
# info.group() # '100'
str2 = 'c++=100, java=90, python=80'
info = re.findall(r'\d+', str2)
# info ['100', '90', '80']
# sum([int(x) for x in info]) 270
str3 = 'imooc videonum = 10000'
info = re.sub(r'\d+', '1001', str3)
# info 'imooc videonum = 1001'
def add1(match):
val = match.group()
num = int(val) + 1
return str(num)
# re.sub(r'\d+', add1, str3) 'imooc videonum = 10001'
str4 = 'imooc:c c++ java python'
#不能仅仅使用空格分割
re.split(r':| ', str4) #['imooc', 'c', 'c++', 'java', 'python']
# str4 = 'imooc:c c++ java python,c#'
# re.split(r':| |,', str4) ['imooc', 'c', 'c++', 'java', 'python', 'c#']
常用正则表达式RE(慕课网_Meshare_huang)的更多相关文章
- 慕课网:剑指Java面试-Offer直通车视频课程
慕课网:剑指Java面试-Offer直通车视频课程,一共有10个章节. 目录结构如下: 目录:/2020036-慕课网:剑指Java面试-Offer直通车 [6G] ┣━━第10章 Java常用类库与 ...
- JavaScript入门--慕课网学习笔记
JAVASCRIPT—(慕课网)入门篇 我们来看看如何写入JS代码?你只需一步操作,使用<script>标签在HTML网页中插入JavaScript代码.注意, <script&g ...
- java网络爬虫----------简单抓取慕课网首页数据
© 版权声明:本文为博主原创文章,转载请注明出处 一.分析 1.目标:抓取慕课网首页推荐课程的名称和描述信息 2.分析:浏览器F12分析得到,推荐课程的名称都放在class="course- ...
- [python] 常用正则表达式爬取网页信息及分析HTML标签总结【转】
[python] 常用正则表达式爬取网页信息及分析HTML标签总结 转http://blog.csdn.net/Eastmount/article/details/51082253 标签: pytho ...
- 常用正则表达式-copy
匹配中文:[\u4e00-\u9fa5] 英文字母:[a-zA-Z] 数字:[0-9] 匹配中文,英文字母和数字及_: ^[\u4e00-\u9fa5_a-zA-Z0-9]+$ 同时判断输入长度:[\ ...
- PHP常用正则表达式汇总 [复制链接]
PHP常用正则表达式汇总 [复制链接] 上一主题下一主题 离线我是小猪头 法师 发帖 539 加关注 发消息 只看楼主 倒序阅读 使用道具楼主 发表于: 2011-06-22 更多 ...
- 慕课网-安卓工程师初养成-4-7 Java循环语句之 while
来源: http://www.imooc.com/code/1420 生活中,有些时候为了完成任务,需要重复的进行某些动作.如参加 10000 米长跑,需要绕 400 米的赛道反复的跑 25 圈.在 ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- RegExp正则表达式规则以及常用正则表达式
html,body { font-family: "SF UI Display", ".PingFang SC", "PingFang SC" ...
随机推荐
- HttpContext访问的正确姿势
本文章转发自:https://www.cnblogs.com/tianqing/p/12570801.html 使用HttpContext的具体场景: 1. 在Controller层访问HttpCon ...
- jmeter响应时间与postman响应时间为什么不一样?
postman响应时间 是一个线程或者一个用户再者说是发送一次请求的响应时间,一般都是200ms一下: 而jmeter属于并行,就是多个用户去访问这个功能点或者接口,多个用户同时访问,就会造成压力,自 ...
- PE文件格式偏移参考
在进行PE文件格式病毒分析的时候,经常要使用到PE文件格式的解析,尤其是对LoadPE形式的病毒的分析,经常要查看PE文件格式的偏移,特地从博客<PE文件格式的偏移参考>中转载收录一份,之 ...
- Linux中使用gdb dump内存
在应急响应中,我们往往会有dump出某一块内存下来进行分析的必要.今天要讲的是利用gdb命令dump出sshd进程的内存. 按照 Linux 系统的设计哲学,内核只提供dump内存的机制,用户想要du ...
- WIN64内核编程-的基础知识
WIN64内核编程基础班(作者:胡文亮) https://www.dbgpro.com/x64driver 我们先从一份"简历"说起: 姓名:X86或80x86 性别:? 出生 ...
- visual studio 将他人的 vtk 程序在本机生成
在网上下载了一些关于vtk的资源,在本机使用visual studio 打开后,生成时出现类似与以下的错误 无法打开包括文件:"vtkStructuredPointsToPolyDataFi ...
- 接口测试的N中玩法
在我看来接口测试相对其他类型的测试是比较简单的.对于最常见的HTTP接口,只需要知道接口的 URL.方法.参数类型.返回值 ... 就可以对接口进行测试了. apifox 如果你是入门级选手,那么ap ...
- 【python】Leetcode每日一题-位1的个数
[python]Leetcode每日一题-位1的个数 [题目描述] 编写一个函数,输入是一个无符号整数(以二进制串的形式),返回其二进制表达式中数字位数为 '1' 的个数(也被称为汉明重量). 示例1 ...
- 谷歌浏览器安装Vue.js devtools
第一步:访问谷歌商店 在之前的博客中已经谈到了这一点的实现方式 https://www.cnblogs.com/10134dz/p/13552777.html 第二步:下载Vue.js devtool ...
- Nacos使用 MySQL 8.0 提示Public Key Retrieval is not allowed
原因如下(参考官网给出的连接选项): 如果用户使用了 sha256_password 认证,密码在传输过程中必须使用 TLS 协议保护,但是如果 RSA 公钥不可用,可以使用服务器提供的公钥:可以在连 ...