windows下使用LTP分词,安装pyltp
1.LTP介绍
ltp是哈工大出品的自然语言处理工具箱, 提供包括中文分词、词性标注、命名实体识别、依存句法分析、语义角色标注等丰富、 高效、精准的自然语言处理技术。pyltp是python下对ltp(c++)的封装. 在linux下我们很容易的安装pyltp, 因为各种编译工具比较方便. 但是在windows下需要安装vs并且还得做一些配置,但是经过本人查阅资料总结了一种不需要安装c++的方法。
2.windows下安装pyltp
想使用LTP进行nlp的任务,第一步就是要需要安装一个pyltp的包,如果直接pip insatll pyltp的话,很大概率时会报错的,所以本人使用另一种方法安装,那就是安装轮子文件(whl文件):
第一步:创建python3.6或者3.5
检查自己的电脑上是否有python3.6或(3.5)环境(python3.8不支持这种安装),如果没有python3.6(3.5)环境的话,需要先安装python3.6(3.6),最简便快捷的方法就是使用anaconda来安装,在你的电脑安装了anaconda的前提下,打开win+r输入cmd进入命令窗,输入
conda create --name python36 python=3.6 #这样你就创建了一个新的python3.6环境
注意,在创建的时候会出现创建失败的问题,具体问题有一堆如下的解释:
UnavailableInvalidChannel: The channel is not accessible or is invalid.
channel name: anaconda/pkgs/free
channel url: https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
error code: 404
这是因为清华园关闭了anaconda的服务,此时你需要输入以下指令恢复设置:
conda config --remove-key channels
回复完毕以后,继续上面的创建指令,就可以完成python环境的创建了。
在创建的时候会出现一个选择,直接输入 y 就好了。这样你的python环境就创建完毕了,你可以进入你的anaconda安装目录下,进入scripts文件就可以看到你的新环境了。
第二步:下载whl文件
python3.5:pyltp-0.2.1-cp35-cp35m-win_amd64.whl
python3.6:pyltp-0.2.1-cp36-cp36m-win_amd64.whl
根据上一步创建的python环境选择相应的whl文件,最好是单独创建一个文件夹来存放这些whl文件。
第三步:安装whl文件
这一步需要先进入到你创建的环境中去:
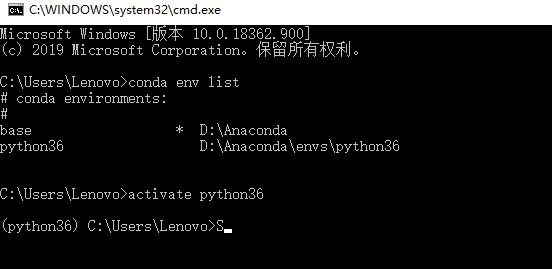
输入
conda env list
检查你的环境列表,然后输入
activate XXX(你的环境名字)
进行激活,在进入到你的环境之后需要转到你上一步存放whl文件的目录,进行安装:
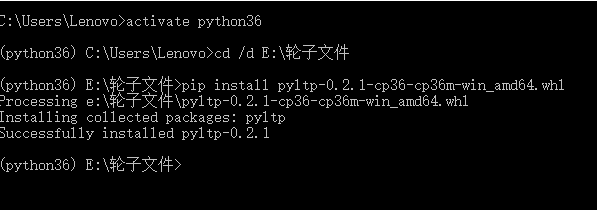
使用:
cd /d E:\轮子文件
直接进入到你存放whl的文件夹,然后使用pip install 进行安装。注意!!安装的时候,一定要加whl后缀,不然会报错
pip install pyltp-0.2.1-cp36-cp36m-win_amd64.whl
至此,whl安装完毕
第四步:下载模型
模型地址:哈工大语言云,我下载的是3.4版本的模型,下载好的模型解压到自己创建的一个文件夹里面。
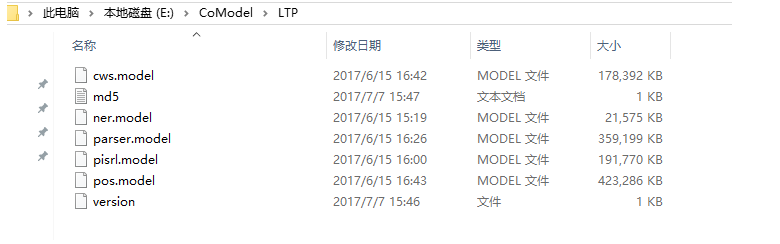
这里我为了方便使用,单独建了一个专门用于存放网上下载的模型的文件夹CoModel,然后将下载下来的ltp模型ltp_data_v3.4.0解压后拿出来,然后放到新建的一个叫做LTP的文件夹里面,可以看到里面有多个模型:
| 文件名 | 模型 |
|---|---|
| cws.model | 分句模型 |
| ner.model | 命名实体识别模型 |
| parser.model | 依存句法分析模型 |
| pisrl.model | 语义角色标注模型 |
| pos.model | 词性标注模型 |
接下来,你就可以在你的程序里面调用这个模型了~~
注意!
本人使用的是pycharm,在pycharm中选择解释器的时候一定要选择你第一步的环境(也就是你所安装pyltp的环境),我没用创建虚环境而是直接使用的python36环境,如果你想使用虚环境,在第一步的时候就要创建为虚环境:
conda create -n venvname python=3.6
最后附上自己分词和词频统计的程序
# -*- coding: utf-8 -*-
from pyltp import Segmentor
import json
import re
def clean(path): # 定义数据清理函数
with open(path, encoding='UTF-8') as f:
strs = ''
for line in f.readlines(): # 读取每一行,并将所有行存到一个strs里
dict = json.loads(line)
str = json.dumps(dict, ensure_ascii=False)
strs += str
strs_clean1 = strs.replace(' ', '') # 去掉文本中的空格
pattern = re.compile("[A-Z0-9元年月日\"\"{}::;,,、。.%%¥()《》—]")
# pattern = re.compile("^\d{1,9}$")
strs_clean2 = re.sub(pattern, '', strs_clean1) # 去掉文本中的数字和字母、符号等
return strs_clean2
def stopwordslist(filepath): # 定义函数创建停用词列表
stopword = [line.strip() for line in open(filepath, 'r',encoding='utf-8').readlines()] # 以行的形式读取停用词表,同时转换为列表
return stopword
def word_splitter(sentence): # 分词
segmentor = Segmentor() # 初始化实例
segmentor.load('./LTP/cws.model') # 加载模型
words = segmentor.segment(sentence) # 分词
words_list = list(words)
segmentor.release() # 释放模型
return words_list
def get_TF(wordslist):
TF_dic={}
for word in wordslist:
TF_dic[word] =TF_dic.get(word,0)+1
# 在字典中查找word的值,该list中的值都为none,找到了就加1,第二次找到就为2...最终返还的是一堆键的值
# print(TF_dic) # 打印键值
return sorted(TF_dic.items(),key=lambda x:x[1],reverse=True) # True:降序
#将字典定义为迭代器,[('word1',value1),('word2',value2)....]然后按照元组的[1]的值(value)来排序
data = clean('DataSet/testsp.json')
print('清洗后的数据:')
print(data)
words_list = word_splitter(data) # 分词后的结果
stopwords = stopwordslist('./DataSet/中文停用词表.txt')
words_clean =[word for word in words_list if word not in stopwords] # 去除停用词
print('去除停用词后的分词:')
print(words_clean)
result = str(get_TF(words_clean))
print(result)
运行结果:

windows下使用LTP分词,安装pyltp的更多相关文章
- 2分钟 windows下sublime text 3安装git插件:
12:35 2015/11/182分钟 windows下sublime text 3安装git插件:推荐博客:http://blog.csdn.net/naola2001/article/detail ...
- 纯windows下制作变色龙引导安装U盘教程
原创教程:纯windows下制作变色龙引导安装U盘教程 支持Mavericks和Yosemite 支持白苹果 目标:windows下制作带 Chamelon变色龙引导的黑苹果安装U盘,支持PC机引导安 ...
- Windows下Oracle 11g的安装
Windows下Oracle 11g的安装 Windows下Oracle 11g的安装: Windows:64位, Oracle 11g版本:win64_11gR2_database_1of2(安装包 ...
- windows下,下载pip安装
windows下,下载pip安装 https://pypi.python.org/pypi/pip#downloads 找到source那个压缩文件,下载下来解压. 参考: windows下面安装Py ...
- Lua在Windows下的配置、安装、运行
Windows下安装.运行Lua! 本文提供全流程,中文翻译.Chinar坚持将简单的生活方式,带给世人!(拥有更好的阅读体验 -- 高分辨率用户请根据需求调整网页缩放比例) 1↓ 进入Lua官网:h ...
- Windows下openssl的下载安装和使用
Windows下openssl的下载安装和使用 安装openssl有两种方式,第一种直接下载安装包,装上就可运行:第二种可以自己下载源码,自己编译.下面对两种方式均进行详细描述. 一.下载和安装ope ...
- Windows下Apache2.2+PHP5安装步骤
Windows下Apache2.2+PHP5安装 初学者在学习PHP的时候可能都会遇到安装Apache和PHP不成功的问题,于是很多开发者便选择了集成包,一键安装好Apache+PHP+MySQL.但 ...
- python学习:Windows 下 Python easy_install 的安装
Windows 下 Python easy_install 的安装 下载安装python安装工具下载地址:http://pypi.python.org/pypi/setuptools 可以找到 ...
- Windows下的Linux子系统安装,WSL 2下配置docker
Windows下的Linux子系统安装,WSL 2下配置docker 前提条件: 安装WSL 2需要Windows 10版本是Build 18917或更高,首先先确认系统版本已升级. 在“启用或关闭W ...
随机推荐
- 【LeetCode】329. Longest Increasing Path in a Matrix 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 题目地址: https://leetcode.com/problems/longest- ...
- 计算机视觉1->opencv4学习指南1 | 环境配置与例程
opencv虽然很有名,但是自己一直没怎么玩过,暑假的时候使用深度相机做项目,但负责的不是代码模块,也只是配好了环境,没有继续了解图像处理.最近电子实习老师有教这个东西,但是身边不少同学遇到了麻烦,所 ...
- 「算法笔记」树形 DP
一.树形 DP 基础 又是一篇鸽了好久的文章--以下面这道题为例,介绍一下树形 DP 的一般过程. POJ 2342 Anniversary party 题目大意:有一家公司要举行一个聚会,一共有 \ ...
- A Primer on Domain Adaptation Theory and Applications
目录 概 主要内容 符号说明 Prior shift Covariate shift KMM Concept shift Subspace mapping Wasserstein distance 应 ...
- 【入门到精通】❤️「Java工程师全栈知识路线」
持续更新中- Vue前端开发 章节 内容 实践练习 Vue.js高效前端开发 • (实践练习) 第1章 Vue.js高效前端开发 • [ 一.初识Vue.js ] 第2章 Vue.js高效前端开发 • ...
- PIC18 bootloader之CAN bootloader
了解更多关于bootloader 的C语言实现,请加我Q扣: 1273623966 (验证信息请填 bootloader),欢迎咨询或定制bootloader(在线升级程序). PIC18 ...
- iNeuOS工业互联网操作系统,增加设备驱动的自定义参数模板,适配行业个性化设备的应用场景
目 录 1. 概述... 2 2. 平台演示... 2 3. 应用过程... 2 1. 概述 增加设备驱动的自定义参数模板,适配行业个性化设备的应用场景. ...
- nano 编辑器快速入门
# 打开或新建一个文件 $ nano tmp.txt # 常用组合按键 ^G:获取帮助 ^X:退出,如果文件有改定会提示是否保存 ^O:保存文件内容 ^R:读取其他文件的内容,放入到当前文件中 ^W: ...
- java运算符2
续: 位运算符(<<,>>,>>>) 1.<<: 3<<2,二进制左移2位,右边用0补齐 3的二进制:00000000 0 ...
- angularJS中$digest already in progress报错解决方法
看到一个前端群里有人问,就查了下解决"$digest already in progress"最好的方式,就是不要使用$scope.$apply()或者$scope.$digest ...