Hive相关知识点
---恢复内容开始---
转载:Hive 性能优化
介绍
首先,我们来看看Hadoop的计算框架特性,在此特性下会衍生哪些问题?
- 数据量大不是问题,数据倾斜是个问题。
- jobs数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联多次汇总,产生十几个jobs,耗时很长。原因是map reduce作业初始化的时间是比较长的。
- sum,count,max,min等UDAF,不怕数据倾斜问题,hadoop在map端的汇总合并优化,使数据倾斜不成问题。
- count(distinct ),在数据量大的情况下,效率较低,如果是多count(distinct )效率更低,因为count(distinct)是按group by 字段分组,按distinct字段排序,一般这种分布方式是很倾斜的。举个例子:比如男uv,女uv,像淘宝一天30亿的pv,如果按性别分组,分配2个reduce,每个reduce处理15亿数据。
面对这些问题,我们能有哪些有效的优化手段呢?下面列出一些在工作有效可行的优化手段:
- 好的模型设计事半功倍。
- 解决数据倾斜问题。
- 减少job数。
- 设置合理的map reduce的task数,能有效提升性能。(比如,10w+级别的计算,用160个reduce,那是相当的浪费,1个足够)。
- 了解数据分布,自己动手解决数据倾斜问题是个不错的选择。set hive.groupby.skewindata=true;这是通用的算法优化,但算法优化有时不能适应特定业务背景,开发人员了解业务,了解数据,可以通过业务逻辑精确有效的解决数据倾斜问题。
- 数据量较大的情况下,慎用count(distinct),count(distinct)容易产生倾斜问题。
- 对小文件进行合并,是行至有效的提高调度效率的方法,假如所有的作业设置合理的文件数,对云梯的整体调度效率也会产生积极的正向影响。
- 优化时把握整体,单个作业最优不如整体最优。
而接下来,我们心中应该会有一些疑问,影响性能的根源是什么?
性能低下的根源
hive性能优化时,把HiveQL当做M/R程序来读,即从M/R的运行角度来考虑优化性能,从更底层思考如何优化运算性能,而不仅仅局限于逻辑代码的替换层面。
RAC(Real Application Cluster)真正应用集群就像一辆机动灵活的小货车,响应快;Hadoop就像吞吐量巨大的轮船,启动开销大,如果每次只做小数量的输入输出,利用率将会很低。所以用好Hadoop的首要任务是增大每次任务所搭载的数据量。
Hadoop的核心能力是parition和sort,因而这也是优化的根本。
观察Hadoop处理数据的过程,有几个显著的特征:
- 数据的大规模并不是负载重点,造成运行压力过大是因为运行数据的倾斜。
- jobs数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联对此汇总,产生几十个jobs,将会需要30分钟以上的时间且大部分时间被用于作业分配,初始化和数据输出。M/R作业初始化的时间是比较耗时间资源的一个部分。
- 在使用SUM,COUNT,MAX,MIN等UDAF函数时,不怕数据倾斜问题,Hadoop在Map端的汇总合并优化过,使数据倾斜不成问题。
- COUNT(DISTINCT)在数据量大的情况下,效率较低,如果多COUNT(DISTINCT)效率更低,因为COUNT(DISTINCT)是按GROUP BY字段分组,按DISTINCT字段排序,一般这种分布式方式是很倾斜的;比如:男UV,女UV,淘宝一天30亿的PV,如果按性别分组,分配2个reduce,每个reduce处理15亿数据。
- 数据倾斜是导致效率大幅降低的主要原因,可以采用多一次 Map/Reduce 的方法, 避免倾斜。
最后得出的结论是:避实就虚,用 job 数的增加,输入量的增加,占用更多存储空间,充分利用空闲 CPU 等各种方法,分解数据倾斜造成的负担。
配置角度优化
我们知道了性能低下的根源,同样,我们也可以从Hive的配置解读去优化。Hive系统内部已针对不同的查询预设定了优化方法,用户可以通过调整配置进行控制, 以下举例介绍部分优化的策略以及优化控制选项。
列裁剪: Hive 在读数据的时候,可以只读取查询中所需要用到的列,而忽略其它列。 例如,若有以下查询:
SELECT a,b FROM q WHERE e<10;
在实施此项查询中,Q 表有 5 列(a,b,c,d,e),Hive 只读取查询逻辑中真实需要 的 3 列 a、b、e,而忽略列 c,d;这样做节省了读取开销,中间表存储开销和数据整合开销。
裁剪所对应的参数项为:hive.optimize.cp=true(默认值为真)
分区裁剪:可以在查询的过程中减少不必要的分区。 例如,若有以下查询:
SELECT * FROM (SELECTT a1,COUNT(1) FROM T GROUP BY a1) subq WHERE subq.prtn=100; #(多余分区)
SELECT * FROM T1 JOIN (SELECT * FROM T2) subq ON (T1.a1=subq.a2) WHERE subq.prtn=100;查询语句若将“subq.prtn=100”条件放入子查询中更为高效,可以减少读入的分区 数目。 Hive 自动执行这种裁剪优化。分区参数为:hive.optimize.pruner=true(默认值为真)
JOIN操作:在编写带有 join 操作的代码语句时,应该将条目少的表/子查询放在 Join 操作符的左边。 因为在 Reduce 阶段,位于 Join 操作符左边的表的内容会被加载进内存,载入条目较少的表 可以有效减少 OOM(out of memory)即内存溢出。所以对于同一个 key 来说,对应的 value 值小的放前,大的放后,这便是“小表放前”原则。 若一条语句中有多个 Join,依据 Join 的条件相同与否,有不同的处理方法。
JOIN原则: 在使用写有 Join 操作的查询语句时有一条原则:应该将条目少的表/子查询放在 Join 操作符的左边。原因是在 Join 操作的 Reduce 阶段,位于 Join 操作符左边的表的内容会被加载进内存,将条目少的表放在左边,可以有效减少发生 OOM 错误的几率。对于一条语句中有多个 Join 的情况,如果 Join 的条件相同,比如查询:
INSERT OVERWRITE TABLE pv_users
SELECT pv.pageid, u.age FROM page_view p
JOIN user u ON (pv.userid = u.userid)
JOIN newuser x ON (u.userid = x.userid);- 如果 Join 的 key 相同,不管有多少个表,都会则会合并为一个 Map-Reduce
- 一个 Map-Reduce 任务,而不是 ‘n’ 个
- 在做 OUTER JOIN 的时候也是一样 ,如果 Join 的条件不相同,比如:
INSERT OVERWRITE TABLE pv_users
SELECT pv.pageid, u.age FROM page_view p
JOIN user u ON (pv.userid = u.userid)
JOIN newuser x on (u.age = x.age);Map-Reduce 的任务数目和 Join 操作的数目是对应的,上述查询和以下查询是等价的:
INSERT OVERWRITE TABLE tmptable
SELECT * FROM page_view p JOIN user u
ON (pv.userid = u.userid);
INSERT OVERWRITE TABLE pv_users
SELECT x.pageid, x.age FROM tmptable x
JOIN newuser y ON (x.age = y.age);
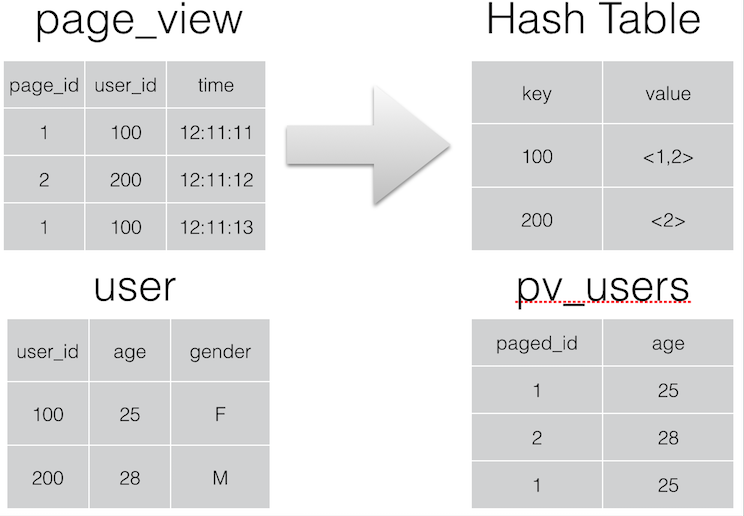
MAP JOIN操作:Join 操作在 Map 阶段完成,不再需要Reduce,前提条件是需要的数据在 Map 的过程中可以访问到。比如查询:
INSERT OVERWRITE TABLE pv_users
SELECT /*+ MAPJOIN(pv) */ pv.pageid, u.age
FROM page_view pv
JOIN user u ON (pv.userid = u.userid);可以在 Map 阶段完成 Join,如图所示:
相关的参数为:
- hive.join.emit.interval = 1000
- hive.mapjoin.size.key = 10000
- hive.mapjoin.cache.numrows = 10000
5.GROUP BY操作
进行GROUP BY操作时需要注意一下几点:
- Map端部分聚合
事实上并不是所有的聚合操作都需要在reduce部分进行,很多聚合操作都可以先在Map端进行部分聚合,然后reduce端得出最终结果。
这里需要修改的参数为:
hive.map.aggr=true(用于设定是否在 map 端进行聚合,默认值为真) hive.groupby.mapaggr.checkinterval=100000(用于设定 map 端进行聚合操作的条目数)
- 有数据倾斜时进行负载均衡
此处需要设定 hive.groupby.skewindata,当选项设定为 true 是,生成的查询计划有两 个 MapReduce 任务。在第一个 MapReduce 中,map 的输出结果集合会随机分布到 reduce 中, 每个 reduce 做部分聚合操作,并输出结果。这样处理的结果是,相同的 Group By Key 有可 能分发到不同的 reduce 中,从而达到负载均衡的目的;第二个 MapReduce 任务再根据预处 理的数据结果按照 Group By Key 分布到 reduce 中(这个过程可以保证相同的 Group By Key 分布到同一个 reduce 中),最后完成最终的聚合操作。
6.合并小文件
我们知道文件数目小,容易在文件存储端造成瓶颈,给 HDFS 带来压力,影响处理效率。对此,可以通过合并Map和Reduce的结果文件来消除这样的影响。
用于设置合并属性的参数有:
- 是否合并Map输出文件:hive.merge.mapfiles=true(默认值为真)
- 是否合并Reduce 端输出文件:hive.merge.mapredfiles=false(默认值为假)
- 合并文件的大小:hive.merge.size.per.task=256*1000*1000(默认值为 256000000)
程序角度优化
熟练使用SQL提高查询
场景:有一张 user 表,为卖家每天收到表,user_id,ds(日期)为 key,属性有主营类目,指标有交易金额,交易笔数。每天要取前10天的总收入,总笔数,和最近一天的主营类目。 :
解决方法1:如下所示:常用方法
INSERT OVERWRITE TABLE t1
SELECT user_id,substr(MAX(CONCAT(ds,cat),9) AS main_cat) FROM users
WHERE ds=20120329 // 20120329 为日期列的值,实际代码中可以用函数表示出当天日期 GROUP BY user_id; INSERT OVERWRITE TABLE t2
SELECT user_id,sum(qty) AS qty,SUM(amt) AS amt FROM users
WHERE ds BETWEEN 20120301 AND 20120329
GROUP BY user_id SELECT t1.user_id,t1.main_cat,t2.qty,t2.amt FROM t1
JOIN t2 ON t1.user_id=t2.user_id下面给出方法1的思路,实现步骤如下:
第一步:利用分析函数,取每个 user_id 最近一天的主营类目,存入临时表 t1。
第二步:汇总 10 天的总交易金额,交易笔数,存入临时表 t2。
第三步:关联 t1,t2,得到最终的结果。
解决方法2
- 如下所示:优化方法
SELECT user_id,substr(MAX(CONCAT(ds,cat)),9) AS main_cat,SUM(qty),SUM(amt) FROM users
WHERE ds BETWEEN 20120301 AND 20120329
GROUP BY user_id
- 如下所示:优化方法
在工作中我们总结出:方案 2 的开销等于方案 1 的第二步的开销,性能提升,由原有的 25 分钟完成,缩短为 10 分钟以内完成。节省了两个临时表的读写是一个关键原因,这种方式也适用于 Oracle 中的数据查找工作。
SQL 具有普适性,很多 SQL 通用的优化方案在 Hadoop 分布式计算方式中也可以达到效果。
2.无效ID在关联时的数据倾斜问题
问题:日志中常会出现信息丢失,比如每日约为 20 亿的全网日志,其中的 user_id 为主 键,在日志收集过程中会丢失,出现主键为 null 的情况,如果取其中的 user_id 和 bmw_users 关联,就会碰到数据倾斜的问题。原因是 Hive 中,主键为 null 值的项会被当做相同的 Key 而分配进同一个计算 Map。
- 解决方法 1:user_id 为空的不参与关联,子查询过滤 null
SELECT
*
FROM log a
JOIN
bmw_users b
ON a.user_id IS NOT NULL AND a.user_id=b.user_id
UNION All
SELECT
*
FROM log a
WHERE a.user_id IS NULL - 解决方法2 如下所示:函数过滤 null
SELECT
*
FROM log a
LEFT OUTER JOIN
bmw_users b
ON
CASE WHEN a.user_id IS NULL THEN CONCAT('dp_hive',RAND()) ELSE a.user_id END =b.user_id; // 这句话写的好骚气啊,还有这种操作,我没有试过调优结果:原先由于数据倾斜导致运行时长超过 1 小时,解决方法 1 运行每日平均时长 25 分钟,解决方法 2 运行的每日平均时长在 20 分钟左右。优化效果很明显。
我们在工作中总结出:解决方法2比解决方法1效果更好,不但IO少了,而且作业数也少了。解决方法1中log读取两次,job 数为2。解决方法2中 job 数是1。这个优化适合无效 id(比如-99、 ‘’,null 等)产生的倾斜问题。把空值的 key 变成一个字符串加上随机数,就能把倾斜的 数据分到不同的Reduce上,从而解决数据倾斜问题。因为空值不参与关联,即使分到不同 的 Reduce 上,也不会影响最终的结果。附上 Hadoop 通用关联的实现方法是:关联通过二次排序实现的,关联的列为 partion key,关联的列和表的 tag 组成排序的 group key,根据 pariton key分配Reduce。同一Reduce内根据group key排序。
3.不同数据类型关联产生的倾斜问题
问题:不同数据类型 id 的关联会产生数据倾斜问题。
一张表 s8 的日志,每个商品一条记录,要和商品表关联。但关联却碰到倾斜的问题。 s8 的日志中有 32 为字符串商品 id,也有数值商品 id,日志中类型是 string 的,但商品中的 数值 id 是 bigint 的。猜想问题的原因是把 s8 的商品 id 转成数值 id 做 hash 来分配 Reduce, 所以字符串 id 的 s8 日志,都到一个 Reduce 上了,解决的方法验证了这个猜测。
- 解决方法:把数据类型转换成字符串类型
SELECT * FROM s8_log a LEFT OUTER
JOIN r_auction_auctions b ON a.auction_id=CASE(b.auction_id AS STRING)
调优结果显示:数据表处理由 1 小时 30 分钟经代码调整后可以在 20 分钟内完成。
4.利用Hive对UNION ALL优化的特性
多表 union all 会优化成一个 job。
问题:比如推广效果表要和商品表关联,效果表中的 auction_id 列既有 32 为字符串商 品 id,也有数字 id,和商品表关联得到商品的信息。
- 解决方法:Hive SQL 性能会比较好
ELECT * FROM effect a
JOIN
(SELECT auction_id AS auction_id FROM auctions
UNION All
SELECT auction_string_id AS auction_id FROM auctions) b
ON a.auction_id=b.auction_id比分别过滤数字 id,字符串 id 然后分别和商品表关联性能要好。
这样写的好处:1 个 MapReduce 作业,商品表只读一次,推广效果表只读取一次。把 这个 SQL 换成 Map/Reduce 代码的话,Map 的时候,把 a 表的记录打上标签 a,商品表记录 每读取一条,打上标签 b,变成两个<key,value>对,<(b,数字 id),value>,<(b,字符串 id),value>。
所以商品表的 HDFS 读取只会是一次。
- 解决方法:Hive SQL 性能会比较好
5.解决Hive对UNION ALL优化的短板
Hive 对 union all 的优化的特性:对 union all 优化只局限于非嵌套查询。
- 消灭子查询内的 group by 示例 1:子查询内有 group by
SELECT * FROM
(SELECT * FROM t1 GROUP BY c1,c2,c3 UNION ALL SELECT * FROM t2 GROUP BY c1,c2,c3)t3
GROUP BY c1,c2,c3从业务逻辑上说,子查询内的 GROUP BY 怎么都看显得多余(功能上的多余,除非有 COUNT(DISTINCT)),如果不是因为 Hive Bug 或者性能上的考量(曾经出现如果不执行子查询 GROUP BY,数据得不到正确的结果的 Hive Bug)。所以这个 Hive 按经验转换成如下所示:
SELECT * FROM (SELECT * FROM t1 UNION ALL SELECT * FROM t2)t3 GROUP BY c1,c2,c3
调优结果:经过测试,并未出现 union all 的 Hive Bug,数据是一致的。MapReduce 的 作业数由 3 减少到 1。
t1 相当于一个目录,t2 相当于一个目录,对 Map/Reduce 程序来说,t1,t2 可以作为 Map/Reduce 作业的 mutli inputs。这可以通过一个 Map/Reduce 来解决这个问题。Hadoop 的 计算框架,不怕数据多,就怕作业数多。
但如果换成是其他计算平台如 Oracle,那就不一定了,因为把大的输入拆成两个输入, 分别排序汇总后 merge(假如两个子排序是并行的话),是有可能性能更优的(比如希尔排 序比冒泡排序的性能更优)。
- 消灭子查询内的 COUNT(DISTINCT),MAX,MIN。
SELECT * FROM
(SELECT * FROM t1
UNION ALL SELECT c1,c2,c3 COUNT(DISTINCT c4) FROM t2 GROUP BY c1,c2,c3) t3
GROUP BY c1,c2,c3;由于子查询里头有 COUNT(DISTINCT)操作,直接去 GROUP BY 将达不到业务目标。这时采用 临时表消灭 COUNT(DISTINCT)作业不但能解决倾斜问题,还能有效减少 jobs。
INSERT t4 SELECT c1,c2,c3,c4 FROM t2 GROUP BY c1,c2,c3;
SELECT c1,c2,c3,SUM(income),SUM(uv) FROM
(SELECT c1,c2,c3,income,0 AS uv FROM t1
UNION ALL
SELECT c1,c2,c3,0 AS income,1 AS uv FROM t2) t3
GROUP BY c1,c2,c3;job 数是 2,减少一半,而且两次 Map/Reduce 比 COUNT(DISTINCT)效率更高。
调优结果:千万级别的类目表,member 表,与 10 亿级得商品表关联。原先 1963s 的任务经过调整,1152s 即完成。
- 消灭子查询内的 JOIN
SELECT * FROM
(SELECT * FROM t1 UNION ALL SELECT * FROM t4 UNION ALL SELECT * FROM t2 JOIN t3 ON t2.id=t3.id) x
GROUP BY c1,c2上面代码运行会有 5 个 jobs。加入先 JOIN 生存临时表的话 t5,然后 UNION ALL,会变成 2 个 jobs。
INSERT OVERWRITE TABLE t5
SELECT * FROM t2 JOIN t3 ON t2.id=t3.id;
SELECT * FROM (t1 UNION ALL t4 UNION ALL t5);调优结果显示:针对千万级别的广告位表,由原先 5 个 Job 共 15 分钟,分解为 2 个 job 一个 8-10 分钟,一个3分钟。
- 消灭子查询内的 group by 示例 1:子查询内有 group by
6.GROUP BY替代COUNT(DISTINCT)达到优化效果
计算 uv 的时候,经常会用到 COUNT(DISTINCT),但在数据比较倾斜的时候 COUNT(DISTINCT) 会比较慢。这时可以尝试用 GROUP BY 改写代码计算 uv。
- 原有代码
INSERT OVERWRITE TABLE s_dw_tanx_adzone_uv PARTITION (ds=20120329)
SELECT 20120329 AS thedate,adzoneid,COUNT(DISTINCT acookie) AS uv FROM s_ods_log_tanx_pv t WHERE t.ds=20120329 GROUP BY adzoneid关于COUNT(DISTINCT)的数据倾斜问题不能一概而论,要依情况而定,下面是我测试的一组数据:
测试数据:169857条
#统计每日IP
CREATE TABLE ip_2014_12_29 AS SELECT COUNT(DISTINCT ip) AS IP FROM logdfs WHERE logdate='2014_12_29';
耗时:24.805 seconds
#统计每日IP(改造)
CREATE TABLE ip_2014_12_29 AS SELECT COUNT(1) AS IP FROM (SELECT DISTINCT ip from logdfs WHERE logdate='2014_12_29') tmp;
耗时:46.833 seconds测试结果表名:明显改造后的语句比之前耗时,这是因为改造后的语句有2个SELECT,多了一个job,这样在数据量小的时候,数据不会存在倾斜问题。
- 原有代码
优化总结
优化时,把hive sql当做mapreduce程序来读,会有意想不到的惊喜。理解hadoop的核心能力,是hive优化的根本。这是这一年来,项目组所有成员宝贵的经验总结。
- 长期观察hadoop处理数据的过程,有几个显著的特征:
- 不怕数据多,就怕数据倾斜。
- 对jobs数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联多次汇总,产生十几个jobs,没半小时是跑不完的。map reduce作业初始化的时间是比较长的。
- 对sum,count来说,不存在数据倾斜问题。
- 对count(distinct ),效率较低,数据量一多,准出问题,如果是多count(distinct )效率更低。
- 优化可以从几个方面着手:
- 好的模型设计事半功倍。
- 解决数据倾斜问题。
- 减少job数。
- 设置合理的map reduce的task数,能有效提升性能。(比如,10w+级别的计算,用160个reduce,那是相当的浪费,1个足够)。
- 自己动手写sql解决数据倾斜问题是个不错的选择。set hive.groupby.skewindata=true;这是通用的算法优化,但算法优化总是漠视业务,习惯性提供通用的解决方法。 Etl开发人员更了解业务,更了解数据,所以通过业务逻辑解决倾斜的方法往往更精确,更有效。
- 对count(distinct)采取漠视的方法,尤其数据大的时候很容易产生倾斜问题,不抱侥幸心理。自己动手,丰衣足食。
- 对小文件进行合并,是行至有效的提高调度效率的方法,假如我们的作业设置合理的文件数,对云梯的整体调度效率也会产生积极的影响。
优化时把握整体,单个作业最优不如整体最优。
优化的常用手段
主要由三个属性来决定:
- hive.exec.reducers.bytes.per.reducer #这个参数控制一个job会有多少个reducer来处理,依据的是输入文件的总大小。默认1GB。
- hive.exec.reducers.max #这个参数控制最大的reducer的数量, 如果 input / bytes per reduce > max 则会启动这个参数所指定的reduce个数。 这个并不会影响mapre.reduce.tasks参数的设置。默认的max是999。
- mapred.reduce.tasks #这个参数如果指定了,hive就不会用它的estimation函数来自动计算reduce的个数,而是用这个参数来启动reducer。默认是-1。
参数设置的影响
如果reduce太少:如果数据量很大,会导致这个reduce异常的慢,从而导致这个任务不能结束,也有可能会OOM 2、如果reduce太多: 产生的小文件太多,合并起来代价太高,namenode的内存占用也会增大。如果我们不指定mapred.reduce.tasks, hive会自动计算需要多少个reducer。
---恢复内容结束---
Yarn的介绍
Hive相关知识点的更多相关文章
- 3. Hive相关知识点
以下是阅读<Hive编程指南>后整理的一些零散知识点: 1. 有时候用户需要频繁执行一些命令,例如设置系统属性,或增加对于Hadoop的分布式内存,加入自定的Hive扩展的Jave包(JA ...
- UITableView相关知识点
//*****UITableView相关知识点*****// 1 #import "ViewController.h" // step1 要实现UITableViewDataSou ...
- Android开发涉及有点概念&相关知识点(待写)
前言,承接之前的 IOS开发涉及有点概念&相关知识点,这次归纳的是Android开发相关,好废话不说了.. 先声明下,Android开发涉及概念比IOS杂很多,可能有很多都题不到的.. 首先由 ...
- IOS开发涉及有点概念&相关知识点
前言,IOS是基于UNIX的,用C/C+/OC直通系统底层,不想android有个jvm. 首先还是系统架构的分层架构 1.核心操作系统层 Core OS,就是内存管理.文件系统.电源管理等 2.核心 ...
- IOS之UI--小实例项目--添加商品和商品名(使用xib文件终结版) + xib相关知识点总结
添加商品和商品名小项目(使用xib文件终结版) 小贴士:博文末尾有项目源码在百度云备份的下载链接. xib相关知识点总结 01-基本使用 一开始使用xib的时候,如果要使用自定义view的代码,就需要 ...
- 学习记录013-NFS相关知识点
一.NFS相关知识点 1.NFS常用的路径/etc/exports NFS服务主配置文件,配置NFS具体共享服务的地点/usr/sbin/exportfs NFS服务的管理命令,exportfs -a ...
- TCP/IP 相关知识点与面试题集
第一部分:TCP/IP相关知识点 对TCP/IP的整体认 链路层知识点 IP层知识点 运输层知识点 应用层知识点 (这些知识点都可以参考:http://www.cnblogs.com/newwy/p/ ...
- Python开发一个csv比较功能相关知识点汇总及demo
Python 2.7 csv.reader(csvfile, dialect='excel', **fmtparams)的一个坑:csvfile被csv.reader生成的iterator,在遍历每二 ...
- Caffe学习系列(二)Caffe代码结构梳理,及相关知识点归纳
前言: 通过检索论文.书籍.博客,继续学习Caffe,千里之行始于足下,继续努力.将自己学到的一些东西记录下来,方便日后的整理. 正文: 1.代码结构梳理 在终端下运行如下命令,可以查看caffe代码 ...
随机推荐
- udev 使用方法
原文地址 http://blog.163.com/againinput4@yeah/blog/static/122764271200962305339483/ 最近有在研究SD卡设备节点自动创建及挂载 ...
- 二,zabbix与php的一些问题
zabbix 检查先决条件 一.php-bcmath 不支持 php 安装 bcmath 扩展(编译安装) PHP的linux版本需要手动安装BCMath扩展,在PHP的源码包中默认包含BCMath的 ...
- dart系列之:dart语言中的变量
目录 简介 dart中的变量 定义变量 变量的默认值 Late变量 常量 总结 简介 flutter是google在2015年dart开发者峰会上推出的一种开源的移动UI构建框架,使用flutter可 ...
- 多线程 | 03 | CAS机制
Compare and swap(CAS) 当前的处理器基本都支持CAS,只不过每个厂家所实现的算法并不一样罢了,每一个CAS操作过程都包含三个参数:一个内存地址V,一个期望的值A和一个新值B,操作的 ...
- mybatis之参数传递的方式 | mybatis
1.单个参数(基本类/包装类+String) 这种情况MyBatis可直接使用这个参数,不需要经过任何处理. 一个参数情况下#{}中内容随便写 public Employee getEmployeeB ...
- Vue.js教程 2.体验Vue
Vue.js教程 2.体验Vue <!DOCTYPE html> <html lang="en"> <head> <meta charse ...
- Java学习(十二)
今天安装讲师推荐下载了一个叫Hbuiler X的IDE,并且学习了选择器的知识. 作为练习,写了一下的代码 <!DOCTYPE html> <html> <head> ...
- 常用的Dos(Win+R)命令
打开CMD的方式 开始 + 系统 + 命令提示符 win + R --> 输入CMD 管理员方式运行:开始-->windows系统-->右击命令提示符-->管理员身份运行(最高 ...
- 虚拟化中虚拟机处理器核数与物理主机cpu的关系
vCPU,顾名思义,是虚拟CPU. 创建虚拟机时,需要配置vCPU资源. 因此vCPU是虚拟机的部件. 因此脱离VM,谈论vCPU是没有意义的.虚拟化管理系统如何调度vCPU,取决于系统内的虚拟机数目 ...
- Mastering-VSCode
中英文等宽 14寸1920x1080, Win10, 设置如下(前两个字体就够了), 字号14,16都可以. 需要下载UbuntuMono字体. 如果分表率低如14寸1366x768,可尝试 Inco ...