大数据学习day38----数据仓库01-----区域字典的生成
更多内容见文档
1. 区域字典的生成
mysql中有如下表格数据
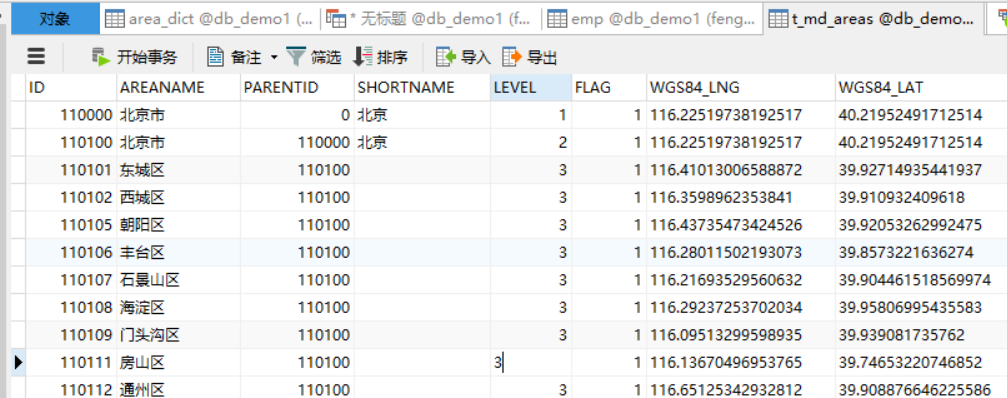
现要将这类数据转换成(GEOHASH码, 省,市,区)如下所示
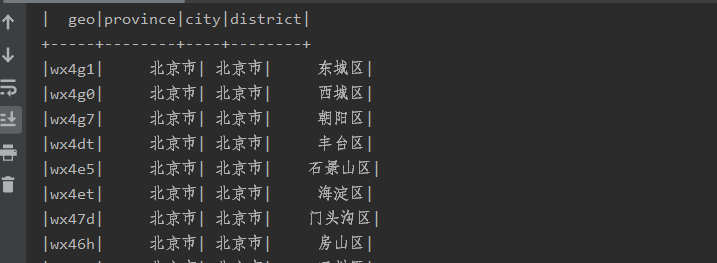
(1)第一步:在mysql中使用sql语句对表格数据进行整理(此处使用到了自关联,具体见文档大数据学习day03)
create table area_dict
as
SELECT
a.BD09_LNG as lng,
a.BD09_LAT as lat,
a.AREANAME as district,
b.AREANAME as city,
c.AREANAME as province from t_md_areas a
join t_md_areas b on a.`LEVEL`=3 and a.PARENTID=b.ID
join t_md_areas c on b.PARENTID = c.ID
得到结果如下
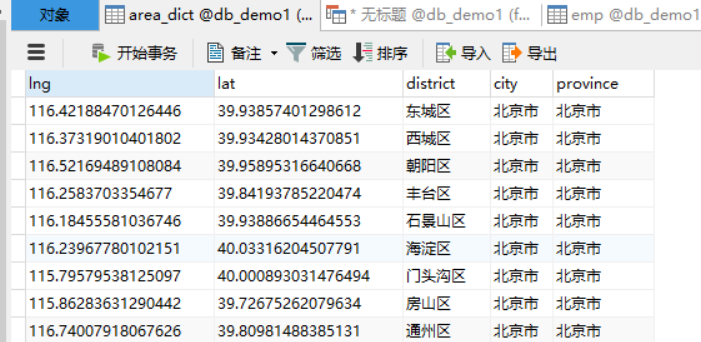
(2)第二步:使用spark sql读取这些数据,并将数据使用GeoHash编码,具体代码如下(这里涉及到parquet数据源,spark喜欢的数据格式)
AreaDictGenerator
package com._51doit import java.util.Properties import ch.hsr.geohash.GeoHash
import org.apache.spark.sql.{DataFrame, SparkSession} object AreaDictGenerator {
def main(args: Array[String]): Unit = {
// 创建SparkSession实例
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
// 创建连接数据库需要的参数
val probs: Properties = new Properties()
probs.setProperty("driver", "com.mysql.jdbc.Driver")
probs.setProperty("user","root")
probs.setProperty("password", "feng")
// 以读取mysql数据库的形式创建DataFrame
val df: DataFrame = spark.read.jdbc("jdbc:mysql://localhost:3306/db_demo1?characterEncoding=UTF-8", "area_dict", probs)
// 运算逻辑
import spark.implicits._
val res: DataFrame = df.rdd.map(row => {
val lng = row.getAs[Double]("lng")
val lat = row.getAs[Double]("lat")
val district = row.getAs[String]("district")
val city = row.getAs[String]("city")
val province = row.getAs[String]("province")
val geoCode: String = GeoHash.withCharacterPrecision(lat, lng, 5).toBase32
(geoCode, province, city, district)
}).toDF("geo", "province", "city", "district")
res.write.parquet("E:/javafile/spark/out11")
}
}
这一步即可得到上述格式的数据。
(3)验证
ParquetReader
package com._51doit
import org.apache.spark.sql.{DataFrame, SparkSession}
object ParquetReader {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
val df: DataFrame = spark.read.parquet("E:/javafile/spark/out11")
df.show()
}
}
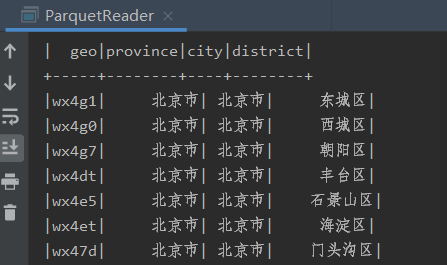
结果
大数据学习day38----数据仓库01-----区域字典的生成的更多相关文章
- 大数据学习之Linux基础01
大数据学习之Linux基础 01:Linux简介 linux是一种自由和开放源代码的类UNIX操作系统.该操作系统的内核由林纳斯·托瓦兹 在1991年10月5日首次发布.,在加上用户空间的应用程序之后 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据学习系列之—HBASE
hadoop生态系统 zookeeper负责协调 hbase必须依赖zookeeper flume 日志工具 sqoop 负责 hdfs dbms 数据转换 数据到关系型数据库转换 大数据学习群119 ...
- 大数据学习路线,来qun里分享干货,
一.Linux lucene: 全文检索引擎的架构 solr: 基于lucene的全文搜索服务器,实现了可配置.可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面. 推荐一个大数据学习群 ...
- 大数据学习之 LINUX
##大数据学习 古斌6.6 01. linux系统的搭建: 选用 Contos 6.5 x64位系统 (CentOS-6.5-x86_64-minimal.iso) 我选择的为迷你版 模板机: bla ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
随机推荐
- Vue&Element开发框架中增加工作流处理,工作流的各个管理页面的界面处理
我在起前面的几篇随笔中,大概介绍了工作流的一些场景化处理,包括如何把具体业务表单组件化,并在查看和编辑界面中,动态加载组件内容,以及对于查看申请单的主页面,把审批.取消.发起会签.会签.批示分阅.阅办 ...
- Java测试开发--Spring Tools Suite (STS) 简介(一)
sts是一个定制版的Eclipse,专为Spring开发定制的,方便创建调试运行维护Spring应用. 官网下载之后,可以看到一个sts-bundle,里面有三个文件夹,一个法律信息,一个tc Ser ...
- 如何系统学习C 语言(中)之 联合体、枚举篇
在C语言中有一个和结构体非常像的数据类型,它的名字叫做联合体,也被称为共用体或公用体. 1,联合体 1,联合体的定义 定义联合体需要使用"union" 关键字,格式如下: unio ...
- newInstance方法
1.new 是java中的关键字,是创建一个新对象的关键字.用new这个关键字的话,是调用new指令创建一个对象,然后调用构造方法来初始化这个对象,如果反编译class的话,会看到一个Object o ...
- SpringCloud升级之路2020.0.x版-39. 改造 resilience4j 粘合 WebClient
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 要想实现我们上一节中提到的: 需要在重试以及断路中加一些日志,便于日后的优化 需要定义重试 ...
- [loj2393]门票安排
为了方便,不妨假设$a_{i}\le b_{i}$,并将问题转换为以下形式: $\forall 1\le i\le m$,将$[a_{i},b_{i})$或$[1,a_{i})\cup [b_{i}, ...
- [cf1515G]Phoenix and Odometers
显然这条路径只能在$v_{i}$所在的强连通分量内部,不妨仅考虑这个强连通分量 对这个强连通分量dfs,得到一棵外向树(不妨以1为根) 考虑一条边$(u,v,l)$,由于强连通,总存在一条从$v$到$ ...
- [cf1495E]Qingshan and Daniel
选择其中卡片总数较少的一类,当相同时选择$t_{1}$所对应的一类(以下记作$A$类) 如果$t_{1}$不是$A$类,就先对$t_{1}$操作一次(即令$a_{1}$减少1) 下面,问题即不断删去$ ...
- [atAGC051C]Flipper
对于这一个平面用$a_{x,y}$来表示,即$(x,y)$为黑色则$a_{x,y}=1$,否则$a_{x,y}=0$,之后定义$a$能生成$b$当且仅当$a$能够通过若干次操作后得到$b$ 令$p_{ ...
- JVM的Xms Xmx PermSize MaxPermSize区别
Eclipse崩溃,错误提示:MyEclipse has detected that less than 5% of the 64MB of Perm Gen (Non-heap memory) sp ...