乱序拼图验证的识别并还原-puzzle-captcha
一、前言
乱序拼图验证是一种较少见的验证码防御,市面上更多的是拖动滑块,被完美攻克的有不少,都在行为轨迹上下足了功夫,本文不讨论轨迹模拟范畴,就只针对拼图还原进行研究。
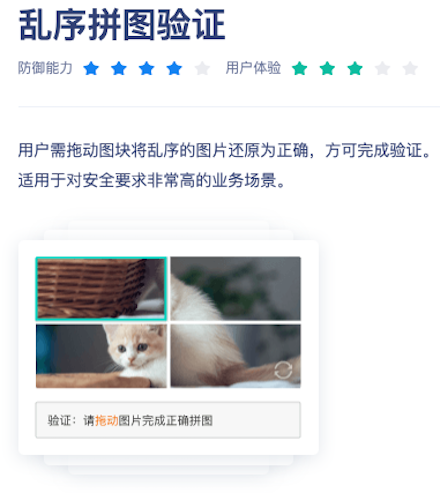
找一个市面比较普及的顶像乱序拼图进行验证,它号称的防御能力4星,用户体验3星,通过研究发现,它的还原程度相当高,思路也很简单,下面一步步的讲解还原过程。

二、环境准备
1.依赖
- 采集模拟
selenium - 特征匹配
python+opencv
2.安装环境
!pip install setuptools
!pip install selenium
!pip install numpy Matplotlib
!pip install opencv-python
3.chormedriver 下载
找到对应浏览器版本+系统平台的driver后,macOS 建议存放到 /usr/local/bin
!wget https://npm.taobao.org/mirrors/chromedriver/95.0.4638.69/chromedriver_mac64.zip
三、采集样本
引入依赖库,使用 webdriver 打开官方网站的产品演示页面

import os
import cv2
import time
import urllib.request
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
创建下载样本的代码,主要流程是打开官网的demo页后,截图并保存
# 采集代码
class CrackPuzzleCaptcha():
# 初始化webdriver
def init(self):
self.url = 'https://www.dingxiang-inc.com/business/captcha'
chrome_options = webdriver.ChromeOptions()
# chrome_options.add_argument("--start-maximized")
chrome_options.add_experimental_option("excludeSwitches", ["ignore-certificate-errors","enable-automation"]) # 设置为开发者模式
path = r'/usr/local/bin/chromedriver' #macOS
# path = r'D:\Anaconda3\chromedriver.exe' #windows
self.browser = webdriver.Chrome(executable_path=path,chrome_options=chrome_options)
#设置显示等待时间
self.wait = WebDriverWait(self.browser, 20)
self.browser.get(self.url)
# 打开验证码demo页面,并强制元素在浏览器可视区域
def openTest(self):
time.sleep(1)
self.browser.execute_script('setTimeout(function(){document.querySelector("body > div.wrapper-main > div.wrapper.wrapper-content > div > div.captcha-intro > div.captcha-intro-header > div > div > ul > li.item-8").click();},0)')
self.browser.execute_script('setTimeout(function(){document.querySelector("body > div.wrapper-main > div.wrapper.wrapper-content > div > div.captcha-intro > div.captcha-intro-body > div > div.captcha-intro-demo").scrollIntoView();},0)')
time.sleep(1)
# 找到原图,webp格式,直接下载保存
def download(self):
onebtn = self.browser.find_element_by_css_selector('#dx_captcha_oneclick_bar-logo_2 > span')
ActionChains(self.browser).move_to_element(onebtn).perform()
time.sleep(1)
#下载webp
img_url = self.browser.find_element_by_css_selector('#dx_captcha_jigsaw_fragment-top-left_3 > img').get_attribute("src")
img_address = "test.png" # 样本文件
response = urllib.request.urlopen(img_url)
img = response.read()
with open(img_address, 'wb') as f:
f.write(img)
print('已保存', img_address)
return self.browser
def crack(self):
pass
开始采集
crack = CrackPuzzleCaptcha()
crack.init()
crack.openTest()
browser2 = crack.download()
已保存 test.png
四、调研结果
- 关键1:显示的拼图的原图就是
已经乱序的状态 - 关键2:原图是一个整体,那么获取原图
切割并编号,能得到与拼图过程一致的结果 - 关键3:拼图只需要做
1次换位即可,2x2的矩阵,可以对[1,2,3,4]进行排列组合,得到所有的拼接结果
五、分析过程
1.辅助函数
定义辅助函数,方便获取参数
# 显示图形
def show_images(images: list , title = '') -> None:
if title!='':
print(title)
n: int = len(images)
f = plt.figure()
for i in range(n):
f.add_subplot(1, n, i + 1)
plt.imshow(images[i])
plt.show(block=True)
# 获取图像的基本信息
def getSize(p):
sum_rows = p.shape[0]
sum_cols = p.shape[1]
channels = p.shape[2]
return sum_rows,sum_cols,channels
2.图像切割
# 输入样本
file = 'test.png'
img = cv2.imread(file)
sum_rows,sum_cols,channels = getSize(img)
part_rows,part_cols = round(sum_rows/2),round(sum_cols/2)
print('样本图 高度、宽度、通道',sum_rows,sum_cols,channels)
print('四图切分,求原图中心位置',part_rows,part_cols)
part1 = img[0:part_rows, 0:part_cols]
part2 = img[0:part_rows, part_cols:sum_cols]
part3 = img[part_rows:sum_rows, 0:part_cols]
part4 = img[part_rows:sum_rows, part_cols:sum_cols]
print('切割为4个小块的 W/H/C 信息,并四图编号:左上=1,右上=2,左下=3,右下=4\n',getSize(part1),getSize(part2),getSize(part3),getSize(part4))
show_images([img],'原图')
show_images([part1,part2],'切割图')
show_images([part3,part4])
样本图 高度、宽度、通道 150 300 3
四图切分,求原图中心位置 75 150
切割为4个小块的 W/H/C 信息,并四图编号:左上=1,右上=2,左下=3,右下=4
(75, 150, 3) (75, 150, 3) (75, 150, 3) (75, 150, 3)
原图

切割图


完成切割后,还需要重组合并4个图像,用于匹配最佳结果
3.图像拼接
# 拼接函数
def merge(sum_rows,sum_cols,channels,p1,p2,p3,p4):
final_matrix = np.zeros((sum_rows, sum_cols,channels), np.uint8)
part_rows,part_cols = round(sum_rows/2),round(sum_cols/2)
final_matrix[0:part_rows, 0:part_cols] = p1
final_matrix[0:part_rows, part_cols:sum_cols] = p2
final_matrix[part_rows:sum_rows, 0:part_cols] = p3
final_matrix[part_rows:sum_rows, part_cols:sum_cols] = p4
return final_matrix
从编号上来看,应该将 [1,2,3,4] 还原成 [4,2,3,1] 就是正确的图,测试下还原效果
# 还原图
f = merge(sum_rows,sum_cols,channels,part4,part2,part3,part1)
show_images([f],'还原图 [4,2,3,1]')
还原图 [4,2,3,1]

4.排列组合
已知 python 实现排列组合非常方便,测试代码如下
import itertools
# 对应拼图的4个块的编号
puzzle_list = [
"1:左上","2:右下",
"3:左下","4:右下"
]
result = itertools.permutations(puzzle_list,4)
cnt=0
for x in result:
cnt+=1
print(x)
print('共',cnt,'种组合')
('1:左上', '2:右下', '3:左下', '4:右下')
('1:左上', '2:右下', '4:右下', '3:左下')
('1:左上', '3:左下', '2:右下', '4:右下')
('1:左上', '3:左下', '4:右下', '2:右下')
('1:左上', '4:右下', '2:右下', '3:左下')
('1:左上', '4:右下', '3:左下', '2:右下')
('2:右下', '1:左上', '3:左下', '4:右下')
('2:右下', '1:左上', '4:右下', '3:左下')
('2:右下', '3:左下', '1:左上', '4:右下')
('2:右下', '3:左下', '4:右下', '1:左上')
('2:右下', '4:右下', '1:左上', '3:左下')
('2:右下', '4:右下', '3:左下', '1:左上')
('3:左下', '1:左上', '2:右下', '4:右下')
('3:左下', '1:左上', '4:右下', '2:右下')
('3:左下', '2:右下', '1:左上', '4:右下')
('3:左下', '2:右下', '4:右下', '1:左上')
('3:左下', '4:右下', '1:左上', '2:右下')
('3:左下', '4:右下', '2:右下', '1:左上')
('4:右下', '1:左上', '2:右下', '3:左下')
('4:右下', '1:左上', '3:左下', '2:右下')
('4:右下', '2:右下', '1:左上', '3:左下')
('4:右下', '2:右下', '3:左下', '1:左上')
('4:右下', '3:左下', '1:左上', '2:右下')
('4:右下', '3:左下', '2:右下', '1:左上')
共 24 种组合
5.特征提取
采用 merge 函数,对切割的小图进行组合还原后,转换为灰度图并提取轮廓。
# 还原图
f = merge(sum_rows,sum_cols,channels,part1,part2,part3,part4)
show_images([f],'还原图[1,2,3,4]')
# 灰度
gray = cv2.cvtColor(f, cv2.COLOR_BGRA2GRAY)
show_images([gray],'灰度')
# 提取轮廓
edges = cv2.Canny(gray, 35, 80, apertureSize=3)
show_images([edges],'提取轮廓')
还原图[1,2,3,4]

灰度
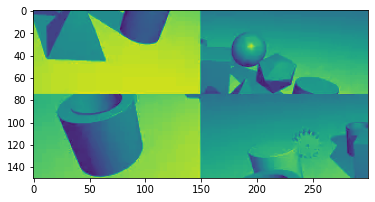
提取轮廓

再测试一种新的组合,看看轮廓特征[1,3,2,4]和原始的轮廓特征[4,2,3,1]
f = merge(sum_rows,sum_cols,channels,part1,part3,part2,part4)
gray = cv2.cvtColor(f, cv2.COLOR_BGRA2GRAY)
edges = cv2.Canny(gray, 35, 80, apertureSize=3)
show_images([edges],'提取轮廓')
f = merge(sum_rows,sum_cols,channels,part1,part2,part3,part4)
gray = cv2.cvtColor(f, cv2.COLOR_BGRA2GRAY)
edges = cv2.Canny(gray, 35, 80, apertureSize=3)
show_images([edges],'提取轮廓')
# 正确的
f = merge(sum_rows,sum_cols,channels,part4,part2,part3,part1)
gray = cv2.cvtColor(f, cv2.COLOR_BGRA2GRAY)
edges = cv2.Canny(gray, 35, 80, apertureSize=3)
show_images([edges],'正确的-提取轮廓')
提取轮廓

提取轮廓

正确的-提取轮廓

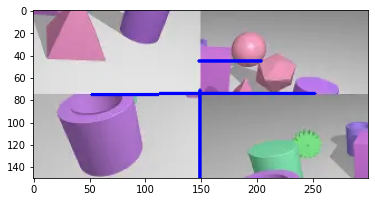
通过提取轮廓,可以看到拼接结果的明显的线条,错误的图至少存在一条x轴或y轴的线,而拼接成功的基本没有(线段位置或长度及线条数量可以决定正确率,需要多调整参数并筛选)。
这是因为原图有明显的过渡色,它是为了用户体验而设计,方便人们使用它的时候,能够‘容易’的区分,并找出正确的拼图位置。
f = merge(sum_rows,sum_cols,channels,part1,part2,part3,part4)
show_images([f],'背景渐变色')
show_images([part3,part2,part1,part4],'切割后')
f = merge(sum_rows,sum_cols,channels,part1,part2,part3,part4)
lf = f.copy()
cv2.line(lf, (0, 75), (300, 75), (0, 0, 255), 2)
cv2.line(lf, (150, 0), (150, 150), (0, 0, 255), 2)
show_images([lf],'乱序,渐变色成为了‘十字’特征线')
背景渐变色

切割后

乱序,渐变色成为了‘十字’特征线

6.特征匹配
特征已知后,现在剩下的就是对特征进行检测,可以计算 x/2,y/2 十字架的色差,也可以用 opencv 的直线提取,测试代码如下:
f = merge(sum_rows,sum_cols,channels,part1,part2,part3,part4)
gray = cv2.cvtColor(f, cv2.COLOR_BGRA2GRAY)
edges = cv2.Canny(gray, 35, 80, apertureSize=3)
show_images([edges],'提取轮廓')
lines = cv2.HoughLinesP(edges,0.01,np.pi/360,60,minLineLength=50,maxLineGap=10)
if lines is None:
print('没找到线条')
else:
lf = f.copy()
for line in lines:
x1, y1, x2, y2 = line[0]
cv2.line(lf, (x1, y1), (x2, y2), (0, 0, 255), 2)
show_images([lf])
提取轮廓

尝试正确的组合 [4,2,3,1]
f = merge(sum_rows,sum_cols,channels,part4,part2,part3,part1)
gray = cv2.cvtColor(f, cv2.COLOR_BGRA2GRAY)
edges = cv2.Canny(gray, 35, 80, apertureSize=3)
show_images([edges],'提取轮廓')
lines = cv2.HoughLinesP(edges,0.01,np.pi/360,60,minLineLength=50,maxLineGap=10)
if lines is None:
print('没找到线条')
else:
lf = f.copy()
for line in lines:
x1, y1, x2, y2 = line[0]
cv2.line(lf, (x1, y1), (x2, y2), (0, 0, 255), 2)
show_images([lf])
提取轮廓

没找到线条
7.匹配过程
import itertools
print('原图顺序')
print(1,2)
print(3,4)
show_images([img])
# 按编号,将切割的图放入list做排列组合
list1 = [
[1,part1],
[2,part2],
[3,part3],
[4,part4]
]
result = itertools.permutations(list1,4)
idx =1
finded = False
finalResult = []
for x in result:
# 排列组合合并图像
f = merge(sum_rows,sum_cols,channels,x[0][1],x[1][1],x[2][1],x[3][1])
# 图像特征提取
gray = cv2.cvtColor(f, cv2.COLOR_BGRA2GRAY)
edges = cv2.Canny(gray, 35, 80, apertureSize=3)
# 直线匹配
lines = cv2.HoughLinesP(edges,0.01,np.pi/360,60,minLineLength=50,maxLineGap=10)
if lines is None:
print('还原图像')
show_images([f])
show_images([gray])
show_images([edges])
print('正确顺序')
print(x[0][0],x[1][0])
print(x[2][0],x[3][0])
print('完成!!')
finded = True
finalResult =[x[0][0],x[1][0],x[2][0],x[3][0]] #获取最终排列正确的结果
break
else:
print(idx, '排列:' , x[0][0],x[1][0],x[2][0],x[3][0] , '线:', len(lines))
lf = f.copy()
for line in lines:
x1, y1, x2, y2 = line[0]
cv2.line(lf, (x1, y1), (x2, y2), (0, 0, 255), 2)
# show_images([lf])
pass
idx+=1
print('测试次数',idx,'最终状态',finded,finalResult)
原图顺序
1 2
3 4

1 排列: 1 2 3 4 线: 4
2 排列: 1 2 4 3 线: 5
3 排列: 1 3 2 4 线: 4
4 排列: 1 3 4 2 线: 2
5 排列: 1 4 2 3 线: 3
6 排列: 1 4 3 2 线: 4
7 排列: 2 1 3 4 线: 3
8 排列: 2 1 4 3 线: 5
9 排列: 2 3 1 4 线: 3
10 排列: 2 3 4 1 线: 3
11 排列: 2 4 1 3 线: 1
12 排列: 2 4 3 1 线: 1
13 排列: 3 1 2 4 线: 2
14 排列: 3 1 4 2 线: 2
15 排列: 3 2 1 4 线: 3
16 排列: 3 2 4 1 线: 3
17 排列: 3 4 1 2 线: 5
18 排列: 3 4 2 1 线: 3
19 排列: 4 1 2 3 线: 4
20 排列: 4 1 3 2 线: 3
21 排列: 4 2 1 3 线: 2
还原图像



正确顺序
4 2
3 1
完成!
测试次数 22 最终状态 True [4, 2, 3, 1]
8.提取结果
再看看如何这种拼图,如果要交换位置的组合有12种
list1 = [1,2,3,4]
result = itertools.permutations(list1,2)
idx=0
for x in result:
idx+=1
print(idx,x)
1 (1, 2)
2 (1, 3)
3 (1, 4)
4 (2, 1)
5 (2, 3)
6 (2, 4)
7 (3, 1)
8 (3, 2)
9 (3, 4)
10 (4, 1)
11 (4, 2)
12 (4, 3)
#交换函数
def change_check(a,b):
diffs = []
if len(a)!=len(b):
return diffs
for i in range(len(a)):
if a[i]!=b[i]:
diffs.append(b[i])
return diffs
ab = change_check([1,2,3,4],finalResult)
print('原始',[1,2,3,4])
print('最终',finalResult)
print('要交换的位置',ab)
原始 [1, 2, 3, 4]
最终 [4, 2, 3, 1]
要交换的位置 [4, 1]
将‘交换的位置’换算成小图中心的偏移坐标,采用查表法
#大图尺寸
pwidth = 150
pheight = 75
#小图xy中心点 = 大图wh 1/4
px = round(pwidth/2)
py = round(pheight/2)
#创建坐标表
offset_points = [
[px,py],[px+pwidth,py],
[px,py+pheight],[px+pwidth,py+pheight]
]
print(offset_points)
print(ab)
#通过结果作为索引,拿到坐标表索引的坐标
drag_start = offset_points[ ab[0] -1 ]
drag_end = offset_points[ ab[1] -1 ]
print('起点偏移坐标',drag_start,'终点偏移坐标',drag_end)
[[75, 38], [225, 38], [75, 113], [225, 113]]
[4, 1]
起点偏移坐标 [225, 113] 终点偏移坐标 [75, 38]
9.模拟操作
至此,已经完成了拼图还原的分析所有过程,下面采用另一种简单的方法,move_to_element 方法,内置的拖动 dom-a 到 dom-b 位置,测试下结果
# 模拟聚焦按钮,让拼图显示出来
onebtn = browser2.find_element_by_css_selector('#dx_captcha_oneclick_bar-logo_2 > span')
ActionChains(browser2).move_to_element(onebtn).perform()
time.sleep(1)
获取最终结果
ab = change_check([1,2,3,4],finalResult)
print(ab)
[4, 1]
找到网页拼图的dom元素,存储下来用于操作并交换拼图
d1 = browser2.find_element_by_css_selector('#dx_captcha_jigsaw_fragment-top-left_3 > div')
d2 = browser2.find_element_by_css_selector('#dx_captcha_jigsaw_fragment-top-right_3 > div')
d3 = browser2.find_element_by_css_selector('#dx_captcha_jigsaw_fragment-bottom-left_3 > div')
d4 = browser2.find_element_by_css_selector('#dx_captcha_jigsaw_fragment-bottom-right_3 > div')
drag_elements = [d1,d2,d3,d4]
<ipython-input-22-61fb3f895e04>:1: DeprecationWarning: find_element_by_* commands are deprecated. Please use find_element() instead
d1 = browser2.find_element_by_css_selector('#dx_captcha_jigsaw_fragment-top-left_3 > div')
<ipython-input-22-61fb3f895e04>:2: DeprecationWarning: find_element_by_* commands are deprecated. Please use find_element() instead
d2 = browser2.find_element_by_css_selector('#dx_captcha_jigsaw_fragment-top-right_3 > div')
<ipython-input-22-61fb3f895e04>:3: DeprecationWarning: find_element_by_* commands are deprecated. Please use find_element() instead
d3 = browser2.find_element_by_css_selector('#dx_captcha_jigsaw_fragment-bottom-left_3 > div')
<ipython-input-22-61fb3f895e04>:4: DeprecationWarning: find_element_by_* commands are deprecated. Please use find_element() instead
d4 = browser2.find_element_by_css_selector('#dx_captcha_jigsaw_fragment-bottom-right_3 > div')
找出要拖动的2个dom,并交付给 webdriver
drag_start = drag_elements[ ab[0] -1 ]
drag_end = drag_elements[ ab[1] -1 ]
print('drag_start',drag_start, 'drag_end',drag_end)
drag_start <selenium.webdriver.remote.webelement.WebElement (session="1d7d691bd509cd03cd8b1483da2056ea", element="8439005e-eb70-4b02-856e-eebbe2526d6d")> drag_end <selenium.webdriver.remote.webelement.WebElement (session="1d7d691bd509cd03cd8b1483da2056ea", element="f9239df5-9aa3-43ae-a6af-afacf81eb670")>
ActionChains(browser2).drag_and_drop(drag_start,drag_end).perform()
# browser2.close()
简单拖一下,目标网站认可了,但它判定是有问题的,又弹出一种新的验证码出来,看来仅仅能够识别还原正确拼图还只是开端,如何伪造一个让其认可的运行环境,又是一个新的技术研究领域,值得与各位共同学习与分享交流。
六、终
边学边做,如有错误之处敬请指出,谢谢!
项目地址:https://github.com/suifei/puzzle-captcha
乱序拼图验证的识别并还原-puzzle-captcha的更多相关文章
- 疯狂位图之——位图生成12GB无重复随机乱序大整数集
上一篇讲述了用位图实现无重复数据的排序,排序算法一下就写好了,想弄个大点数据测试一下,因为小数据在内存中快排已经很快. 一.生成的数据集要求 1.数据为0--2147483647(2^31-1)范围内 ...
- 主键乱序插入对Innodb性能的影响
主键乱序插入对Innodb性能的影响 在平时的mysql文档学习中我们经常会看到这么一句话: MySQL tries to leave space so that future inserts do ...
- 关于乱序(shuffle)与随机采样(sample)的一点探究
最近一个月的时间,基本上都在加班加点的写业务,在写代码的时候,也遇到了一个有趣的问题,值得记录一下. 简单来说,需求是从一个字典(python dict)中随机选出K个满足条件的key.代码如下(py ...
- Wireshark理解TCP乱序重组和HTTP解析渲染
TCP数据传输过程 TCP乱序重组原理 HTTP解析渲染 TCP乱序重组 TCP具有乱序重组的功能.(1)TCP具有缓冲区(2)TCP报文具有序列号所以,对于你说的问题,一种常见的处理方式是:TCP会 ...
- tf.train.batch的偶尔乱序问题
tf.train.batch的偶尔乱序问题 觉得有用的话,欢迎一起讨论相互学习~Follow Me tf.train.batch的偶尔乱序问题 我们在通过tf.Reader读取文件后,都需要用batc ...
- 乱序优化与GCC的bug
以下内容来自搜狗实验室技术交流文档,搜狐公司研发中心版权所有,仅供技术交流 摘要 --------- 乱序优化是现代编译器非常重要的特性,本文介绍了什么是乱序优化,以及由此引发的一个bug,希 ...
- mysql select 无order by 默认排序 出现乱序的问题
原文:mysql select 无order by 默认排序 出现乱序的问题 版权声明:感谢您的阅读,转载请联系博主QQ3410146603. https://blog.csdn.net/newMan ...
- wireshark和tcpdump抓包TCP乱序和重传怎么办?PCAP TCP排序工具分享
点击上方↑↑↑蓝字[协议分析与还原]关注我们 " 介绍TCP排序方法,分享一个Windows版的TCP排序工具." 在分析协议的过程中,不可避免地需要抓包. 无论抓包条件如何优越, ...
- memory barrier 内存屏障 编译器导致的乱序
小结: 1. 很多时候,编译器和 CPU 引起内存乱序访问不会带来什么问题,但一些特殊情况下,程序逻辑的正确性依赖于内存访问顺序,这时候内存乱序访问会带来逻辑上的错误, 2. https://gith ...
随机推荐
- hdu 1502 Regular Words(DP)
题意: 一个单词X由{A,B,C}三种字母构成. A(X):单词X中A的个数.B(X),C(X)同理. 一个单词X如果是regular word必须满足A(X)=B(X)=C(X)且对于X的任意前缀有 ...
- SSH 提示密码过期,如何通过 ansible 批量更新线上服务器密码
起因 线上环境是在内网,登陆线上环境需要使用 VPN + 堡垒机 登陆,但是我日常登陆线上环境都是 VPN + 堡垒机 + Socks5常驻代理,在shell端只需要保存会话,会话使用socks5代理 ...
- 2021 ICPC 江西省赛总结
比赛链接:https://ac.nowcoder.com/acm/contest/21592 大三的第一场正式赛,之前的几次网络赛和选拔赛都有雄哥坐镇,所以并没有觉得很慌毕竟校排只取每个学校成 ...
- Java的基本数据类型和数据类型转换
首先java属于强类型语言,要求变量的使用要严格遵守规范,所有变量都必须先定义后才能使用. Java的数据类型分为以下两种: 1 基础数据类型(primtive type) 和 2 引用数据类型(re ...
- 运行级别和找回root密码
运行级别说明 0 :关机 1 :单用户 [类似安全模式,这个模式可以帮助找回root密码 2:多用户状态没有网络服务 3:多用户状态有网络服务 [使用] 4:系统未使用保留给用户 5:图形界面 6:系 ...
- 在Express 中获取表单请求体数据
在Express 中获取表单请求体数据 获取 GET 请求参数 获取 POST 请求体数据 安装 配置 获取 GET 请求参数 Express 内置了一个 API , 可以直接通过 req.query ...
- airflow 并发上不去
airflow.cfg parallelism配置是否合适 任务池slot是否足够
- c++学习笔记(十)
返回应用类型 返回引用 1.不要返回局部变量的引用 为了验证为什么不能返回局部变量的引用,我按照所学的例题自己做了一点小测试. #include<iostream> using names ...
- Mysql5.7和8.0版本的文件夹版安装教程(整合版,超详细)
安装Mysql(5.7版本) 下载地址在这里可以自选版本,找到合适的版本进行下载 解压安装包 配置环境变量 win+r 输入 sysdm.cpl 点击高级 点击环境变量 新建一个系统变量 变量名为MY ...
- Mybatis动态传入tableName--非预编译(STATEMENT)
在使用Mybatis过程中,你可以体会到它的强大与灵活之处,由衷的为Mybatis之父点上999个赞!在使用过程中经常会遇到这样一种情况,我查询数据的时候,表名称是动态的从程序中传入的,比如我们通过m ...