以小25倍参数量媲美GPT-3的检索增强自回归语言模型:RETRO
NLP论文解读 原创•作者 | 吴雪梦Shinemon
研究方向 | 计算机视觉
导读说明:
一个具有良好性能的语言模型,一定量的数据样本必不可少。现有的各种语言模型中,例如GPT3具有1750亿的参数量,前不久发布的源1.0单体模型参数量达2457亿,DeepMind团队一起新发布的语言模型Gopher[1]也具有2800亿参数量,更有巨无霸模型MT-NLP参数量高达5300亿(如图2所示)!
为了获得更高的性能,同时增加了如此庞大的数据量,从最初的万级,到达现在的千亿级,这种方式虽有效,但是难免会有如数据集难理解、增加模型偏差等一系列问题。
为了解决如此庞大数据量带来的困扰,DeepMind团队研发一种带有互联网规模检索的高效预训练模型,RETRO(Retrieval-Enhanced Transformer )模型,打破了模型越大准确度越高的假设。
论文解读:
Improving language models by retrieving from trillions of tokens
论文地址:
https://arxiv.org/pdf/2112.04426.pdf
研发团队:

图1. RETRO模型研发团队
Fig1. Research Team of RETRO
01 研究背景
近年来,通过增加Transformer模型中的参数数量,自回归语言建模的性能得到了显著提高。
这也导致了训练成本的增加,并产生了具有千亿个参数的密集大型语言模型;同时,为了方便这些模型的训练,收集了大量的数据集,其中包含了数万亿的单词,详情如图2所示。
为减少计算量,论文作者探索了改进语言模型的另一种途径:通过检索包括网页、书籍、新闻和代码在内的文本段落数据库来增强检索,生成了一种新的语言模型RETRO。
RETRO模型利用从大型语料库中检索到的文档块,基于与前面标记的局部相似性来增强自回归语言模型。该模型可以从零开始训练,也可以快速改装带检索的预训练Transformer,仍然取得良好的性能。
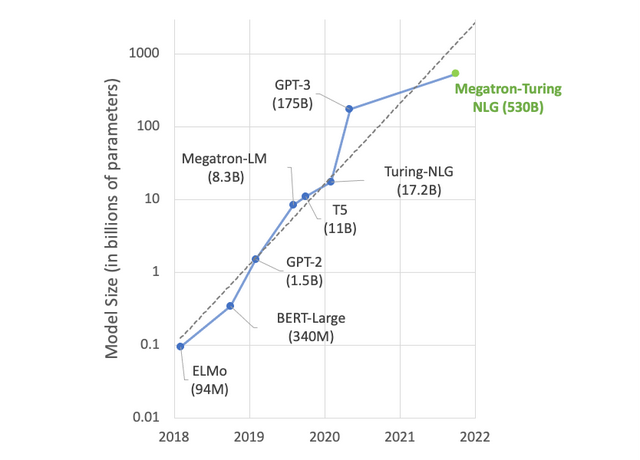
图2. 语言模型参数量[2]
Fig2. Size of Language Model
02 RETRO模型
RETRO模型使用一个基于 MassiveText 多语言数据集的2万亿token数据库,数据库由一个键值内存(key-value memory)组成,每个值由两个连续的标记块( neighbour chunk:用于计算 key;its continuation:原文件文本的延续)组成,长度为64 token。
在数据库进行查找时,模型利用嵌入算子BERT句子嵌入来预先计算所有近似最近邻,并将结果保存为数据(RETRO 输入)的一部分。
RETRO模型架构由一个编码器堆栈(处理近邻)和一个解码器堆栈(处理输入)组成,如下图3所示。
编码器堆栈由标准的 Transformer 编码器块组成;解码器堆栈包含了Transformer解码器块和RETRO 解码器块(ATTN + Chunked cross attention (CCA) + FFNN)。

图3. RETRO架构编码器与解码器[3]
Fig3. Encoder and Decoder of RETRO
编码器堆栈会处理检索到的近邻,并生成键值矩阵;Transformer解码器块处理输入文本,它对提示token应用自注意力,然后通过FFNN层;到达RETRO解码器时,进行合并检索到的信息。
在RETRO解码器中应用分块交叉注意力机制(Chunked cross-attention)[4],这样模型就可以同时利用输入的提示信息和记忆信息来完成布置的各种NLP任务,结构如图4所示。

图4. 高层次的RETRO架构
Fig4. A high-level overview of RETRO
这一新式架构为我们的模型预测都带来什么呢?简言之就是将语言事实信息从世界知识信息中分离开来。
我们知道,为了保存住训练数据中的信息,各类大型语言模型将它们所知道的一切都部署并编码到模型参数中,但是对于事实信息是无效的。
当使用这种基于检索的框架后,语言模型可以缩小很多,模型的参数量很小就可以包含更多的文本信息,模型运行的速度也有很大的提升,同时模型的可解释性也能有很大的提高。
在文本生成过程中,神经数据库就能帮助模型检索它需要的事实信息,并能根据具体需要进行调整。
关于Chunked cross-attention(CCA)块详细内容见下图5右图,推导过程请见原论文。
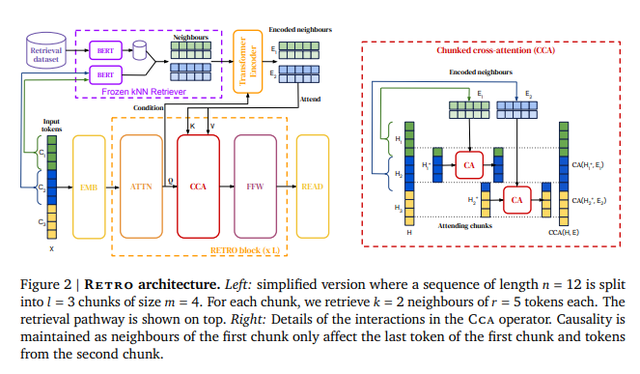
图5. RETRO语言框架
Fig5. RETRO Architecture
03 解决数据泄露问题
在现阶段模型发展中,几乎所有的语言模型都存在数据泄露这个问题,更为关键的是,在检索增强的语言模型中褎然举首,因为检索的过程就能直接访问训练集。
为此论文作者提出了一种衡量测试文档与训练集接近程度的评估方式,解决了测试集数据泄漏的问题[5]。
使用这种方法实验后结果表明,提升RETRO性能来自显式近邻复制(explicit neighbor copying)和通用知识提取(general knowledge extraction),评估测试文档和训练数据集之间重叠函数如下图6,具体推导详情及评估指标请见原论文。

图6. 重叠函数
Fig6. Function of the Overlap
04 模型间对比分析
在RETRO之前就有许多优秀检索方法模型,如REALM、FID和KNN-LM等。
RETRO与KNN-LM和DPR共享组件,因为它使用Frozen检索表示;与FID类似,RETRO在编码器中分别处理检索到的近邻,并将它们组合在分块交叉注意力机制中;使用块可以在生成序列的同时重复检索,而不是根据提示信息只检索一次;
此外,RETRO检索是在整个训练前的过程中完成的,而不是简单地为解决某个下游任务而插入其中,RETRO与现有方法的详细区别如图7所示。

图7. RETRO与其他检索方法对比
Fig7. Comparison of Retro with existing retrieval approaches
05 RETRO模型实验结果
论文作者在C4 (Colossal Clean Crawled Corpus,web爬行语料库,数据经过清理)、Wikitext103 (超过 1 亿个语句的数据)、Curation Corpus (新闻文章摘要数据集)、Lambada (叙述性段落)和Pile (825GB,开源)数据集和一组手动选择的维基百科文章上评估了RETRO模型,并评估了整个文档的语言建模性能,测量了字节位数(bpb)。
如图8所示评估结果,每种数据集评估详情请见原论文。
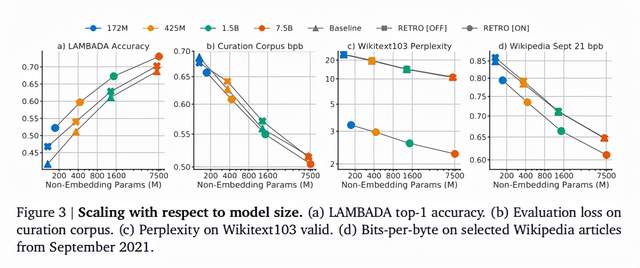
图8. RETRO评估结果
Fig8. Evaluation Results of RETRO
在只使用4%的参数量的基础上,RETRO模型获得了与Gopher和 Jurassic-1 模型相当的性能,在大多数测试集上表现优异。
在Wikitext103上,RETRO的表现优于以前在大规模数据集上训练的模型,并且在检索密集型下游任务(如Q&A任务)上具有竞争力。

图9. RETRO评估结果Ⅱ
Fig9. Evaluation Results of RETRO Ⅱ
06 小结
● 检索记忆机制:RETRO不仅利用当下的知识,还会利用到记忆检索这一机制;
● 半参数化方法:不需要增加模型的大小和训练更多的数据,而让模型在执行预测时能够直接访问大型数据库;
● 应用在块水平上的BERT句子嵌入检索器;
● 应用基于查询条件的可微编码器:可根据实际需要自行调整;
● 与之前的块检索集进行分块交叉注意力机制;
● 无测试集数据泄漏的问题;
● 消融结果显示检索对任务大有帮助。
07 未来展望
Transformer体系结构已经在许多NLP任务上提高了技术水平。然而这些性能改进依赖于大规模的扩展,从而导致了大量的内存和计算负担。
但RETRO模型及OpenAI的WebGPT [6]可以证明,一味增大模型并不是提升性能的唯一路径。
现如今,对信息的获取是无止境的,对于我们人类来说,搜索网络和分析给定的信息比记住所有的东西要直观得多,那么为什么模型不能做同样的事情呢?这项工作为通过前所未有的记忆检索来改进语言模型开辟了一条新的途径。
未来是否为一大趋势呢?Days will tell you. 请期待......
参考文献
[1] Scaling Language Models: Methods, Analysis& Insights from Training Gopher,arXiv:2112. 04426v1,2021
[2] https://developer.nvidia.com/blog/using-deepspeed-and-megatron-to-train-megatron-turing-nlg-530b-the-worlds-largest-and-most-powerful-generative-language-model
[3] http://jalammar.github.io/illustrated-retrieval-transformer
[4] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, 2017.
[5] K. Lee, D. Ippolito, A. Nystrom, C. Zhang, D. Eck, C. Callison-Burch, and N. Carlini. Deduplicating training data makes language models better. arXiv preprint arXiv:2107.06499, 2021.
https://arxiv.org/pdf/2112.09332.pdf
以小25倍参数量媲美GPT-3的检索增强自回归语言模型:RETRO的更多相关文章
- 谷歌出品EfficientNet:比现有卷积网络小84倍,比GPipe快6.1倍
[导读]谷歌AI研究部门华人科学家再发论文<EfficientNet:重新思考CNN模型缩放>,模型缩放的传统做法是任意增加CNN的深度和宽度,或使用更大的输入图像分辨率进行训练,而使用E ...
- SDAccel-FPGA将带来至多25倍单位功耗性能提升
很久没有看FPGA了,本来想继续学习HLS,就上Xilinx的网站看了看.结果发现了SDx 开发环境,很新的一个东西.由于我对这方面了解不多,本篇博文仅仅只是资料的整合和介绍. 1.SDx开发环境 X ...
- 深度学习之(经典)卷积层计算量以及参数量总结 (考虑有无bias,乘加情况)
目录: 1.经典的卷积层是如何计算的 2.分析卷积层的计算量 3.分析卷积层的参数量 4.pytorch实现自动计算卷积层的计算量和参数量 1.卷积操作如下: http://cs231n.github ...
- Kotlin入门(25)共享参数模板
共享参数SharedPreferences是Android最简单的数据存储方式,常用于存取“Key-Value”键值对数据.在使用共享参数之前,要先调用getSharedPreferences方法声明 ...
- 小程序setData数据量过大时候会对渲染有影响吗?
datas:[ { id:1000, name: "帅哥", title: '...', b: '...', d: 0, f:0, .... }, { id:1001, name: ...
- 微信小程序生成带参数的二维码(小程序码)独家asp.net的服务端c#完整代码
一)我先用的小程序端的wx.request去调用API,发现竟然是一个坑! wx.request({ url: 'https://api.weixin.qq.com/wxa/getwxacodeunl ...
- Go Protobuf(比xml小3-10倍, 快20-100倍)
简介 Protocol Buffers是什么? protocol buffers 是一种灵活,高效,自动化机制的结构数据序列化方法-可类比 XML,但是比 XML 更小.更快.更为简单.你可以定义数据 ...
- Java开发中经典的小实例-(while(参数){})
import java.util.Scanner;public class Test_while { public static void main(String[] args) { ...
- Java开发中经典的小实例-(if(参数){}else{})
import java.util.Scanner; public class Calculate { public static void main(String[] args) { ...
随机推荐
- MySQL查询处理——逻辑查询处理和物理查询处理
对于查询处理,可将其分为逻辑查询处理和物理查询处理.逻辑查询处理表示执行查询应该产生什么样的结果,而物理查询代表MySQL数据库是如何得到结果的. 逻辑查询处理 MySQL真正的执行顺序如下: (8) ...
- 513. Find Bottom Left Tree Value
Given a binary tree, find the leftmost value in the last row of the tree. Example 1: Input: 2 / \ 1 ...
- CTF web安全45天入门学习路线
前言 因为最近在准备开发CTF学习平台,先做一个学习路线的整理,顺便也是对想学web的学弟学妹的一些建议. 学习路线 初期 刚刚走进大学,入了web安全的坑,面对诸多漏洞必然是迷茫的,这时的首要任务就 ...
- 不难懂-----Mock基本使用
一.mock解决的问题 开发时,后端还没完成数据输出,前端只好写静态模拟数据.数据太长了,将数据写在js文件里,完成后挨个改url.某些逻辑复杂的代码,加入或去除模拟数据时得小心翼翼.想要尽可能还原真 ...
- Nginx怎么处理请求的?
nginx接收一个请求后,首先由listen和server_name指令匹配server模块,再匹配server模块里的 location,location就是实际地址. server { # 第 ...
- swwager的使用
最近弄swwager文档,被搞得恼火,故记录一下 先展示一下现有的页面,此页面由swwager自动生成 配置步骤: 一:导入swwager的依赖 <!-- =================== ...
- Maven 警告 expected START_TAG or END_TAG not TEXT
原因 在Maven警告提示区域存在空格等不规范字符,在网上复制到项目中时经常出现类似问题. pop.xml文件,setting.xml文件极易出现此类问题. 解决 将空格删除,规范一下格式就好了. 示 ...
- CDN 的缓存与回源机制解析
CDN的缓存与回源机制解析 CDN (Content Delivery Network,即内容分发网络)指的是一组分布在各个地区的服务器.这些服务器存储着数据的副本,因此服务器可以根据哪些服务器与用户 ...
- Spring与Struts2整合时action自动注入的问题
当Struts和Spring框架进行整合时,原本由action实例化对象的过程移交给spring来做(这个过程依赖一个叫struts2-spring-plugin的jar包,这个包主要的功能就是实现刚 ...
- squid 代理服务器应用
squid 代理服务器应用 1.Squid 代理服务器 : Squid 主要提供缓存加速.应用层过滤控制的功能. 代理的工作机制: 代替客户机向网站请求数据,从而可以隐藏用户的真实IP地址. 将获得 ...