【C#IO 操作】字符流(StreamWriter、StreamReader)
StreamWaiter类和StreamReader类的用法
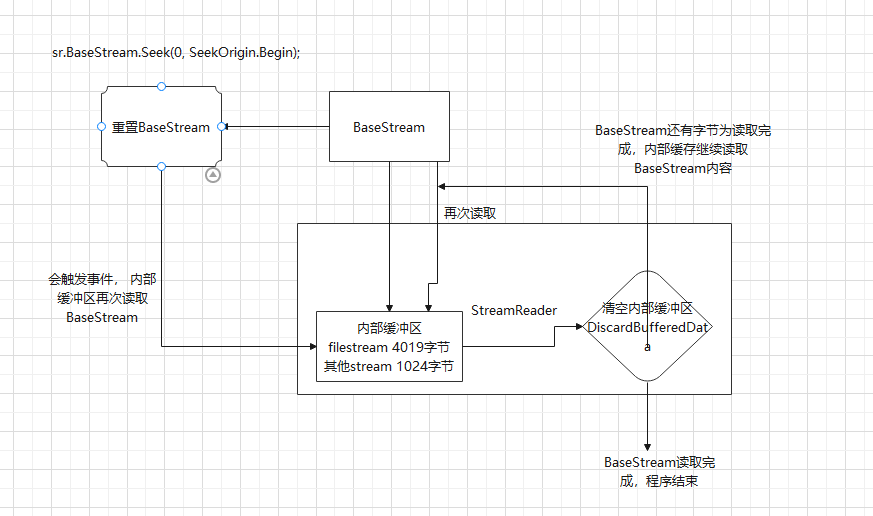
事实上, StreamReader为了性能的考虑, 在自己的内部内置并维护了一个byte buffer。 如果在声明StreamReader对象的时候没有指定这个buffer的尺寸, 那么它的默认大小是1k。 如果是文件流, 那么这个buffer的默认大小是4K。 所有Read操作,都直接或间接转换为了对这个buffer的操作。StreamReader不能seek,只能通过baseStream.seek和StreamReader.DiscardBufferData()一起来实现StreamReader的定向输出的功能。内部的basestream=外部传入的filestream等
默认情况下,StreamWriter 不是线程安全的。有关线程安全包装的信息,请参见 TextWriter.Synchronized。
StreamReader类的用法
StreamReader 工作原理
构造函数
- StreamReader(Stream)
- StreamReader(String)
- StreamReader(Stream, Boolean)
- StreamReader(Stream, Encoding)
- StreamReader(String, Boolean)
- StreamReader(String, Encoding)
- StreamReader(Stream, Encoding, Boolean)
- StreamReader(String, Encoding, Boolean)
- StreamReader(Stream, Encoding, Boolean, Int32)
- StreamReader(String, Encoding, Boolean, Int32)
- StreamReader(Stream, Encoding, Boolean, Int32, Boolean)
- Boolean :是否又字节顺序标记 即 BOM全称是Byte Order Mark 可以通过Encoding的方法GetPreamble()来判断这编码有没有BOM,目前CLR中只有下面5个Encoding有BOM。
可以通过Encoding的方法GetPreamble()来判断这编码有没有BOM,目前CLR中只有下面5个Encoding有BOM。
UTF-8: EF BB BF
UTF-16 big endian: FE FF
UTF-16 little endian: FF FE
UTF-32 big endian: 00 00 FE FF
UTF-32 little endian: FF FE 00 00
用Encoding的静态属性Unicode,UTF8,UTF32构造的Encoding都是默认带有BOM的,如果你想在写一个文本时(比如XML文件,如果有BOM,会有乱码的),不想带BOM,那么就必须用它们的实例,
Encoding encodingUTF16=new UnicodeEncoding(false, false);//第二个参数必须要为false Encoding encodingUTF8=new UTF8Encoding(false); Encoding encodingUTF32=new UTF32Encoding(false,false);//第二个参数必须要为false
读写文本和BOM的关系可以参考园子里这篇博客,讲的很详细我就不重复了,.NET(C#):字符编码(Encoding)和字节顺序标记(BOM)
具体的功能
//构造函数
//using (StreamReader sr = new StreamReader(pat,Encoding.Unicode))//更具文件内容选择合适的编码格式读取文件。不指定就采用UTF8编码
using (StreamReader sr = new StreamReader(pat))
{ //属性
Stream stream = sr.BaseStream; //返回基流,stream 是字节码。
Console.WriteLine(stream.GetType()); //输出 System.IO.FileStream
Console.WriteLine(sr.CurrentEncoding); //当前流读取器使用的编码,默认是本机编码(当构造器不指定时),如果构造方法指定了,输出的就是构造方法指定的编码 //方法
//Read()应用
char[] burffer1 = new char[9];// {'a', 's', 'd', 'f', 'g', 'h', 'j', 'k' };
char[] burffer2 = new char[9];
var s = sr.Read();//读取当前指针的所指向的字符 ,读取完成后指针向前移一个字符。
Console.WriteLine(Convert.ToChar(s)); //A //Read(Span<Char>)
Span<char> span = new Span<char>(burffer1);//将数组转成指针数组
sr.Read(span);//将流中存入 span,存满后就停止。charPos又向前移动了9个位置
Console.WriteLine(string.Join("",span.ToArray()));//SCII hell //Read(Char[], Int32, Int32)
sr.Read(burffer2, 2, 4);//从sr 重charPos 指针当前所指向的位子开始读取 4个字符,存入burffer数组的3-7位置。charPos++向前移动了4个位置
Console.WriteLine(String.Join("", burffer2));//链接字符数组并且打印 o I Console.WriteLine(sr.BaseStream.Position);//读取BaseStream指针的绝对位置 //这两种方式都是判断BaseStream 中数据是否都读取完毕
Console.WriteLine(sr.BaseStream.Position==sr.BaseStream.Length); //true 判断基础流的内存是否都读取完成了,BaseStream指针的绝对位置和长度相同时候,就说明读取完成了。
调用 DiscardBufferedData 方法 重置内部缓冲区 会降低性能,只应在绝对必要的情况下调用。
Console.WriteLine(sr.EndOfStream);// true 判断基础流的内存是否都读取完成了。 sr.BaseStream.Seek(0, SeekOrigin.Begin); //0表示相对于SeekOrigin.Begin的位置。SeekOrigin.Begin表示在哪里读取流 sr.DiscardBufferedData(); // 清空sr内部缓冲区,因为BaseStream内容都已经读取完成。所以清空内部缓冲区后,sr不会再次从BaseStream读取数据到内部缓冲区中。
if (sr.Peek() == -1)
{
Console.WriteLine("内部缓冲区内容已经读取完成。");
}
sr.BaseStream.Seek(0, SeekOrigin.Begin);//重置BaseStream 指针,触发sr内部缓冲区又会开始读取 BaseStream的内容。
if (sr.Peek() > -1)
{
Console.WriteLine("又可以读取了");
} //判断是否读取完成。读取完成返回值是-1,Peek()也read()也都是返回accii的编码
while (sr.Peek() > -1)
{ //ReadLine() 的应用
var ren = sr.ReadLine();//ASCII hello I am programmer hello 因为缓存和指针都重置过了。从头开始读取
Console.WriteLine(sr.Peek());
Console.WriteLine(ren); }
//第二次重置,一次性读取本文内容。
sr.DiscardBufferedData();
sr.BaseStream.Seek(0, SeekOrigin.Begin); //0表示相对于SeekOrigin.Begin的位置。SeekOrigin.Begin表示在哪里读取流
Console.WriteLine(sr.ReadToEnd());//从 charPos++ 所指向的字符开始读取 一直读取到内容结束。因为指针已经知道末尾,所以返回为空 }
SeekOrigin枚举
| Begin | 0 |
指定流的开始位置。 |
| Current | 1 |
指定流中的当前位置。 |
| End | 2 |
指定流的结束位置。 |
StreamWriter类的用法
在讲这个用法之前,必须了解一个概念:
Stream类型不支持终结,所有必须显示调用Dispose()方法将缓存中的数据flush到FileStream。不显示调用就会造成数据丢失。
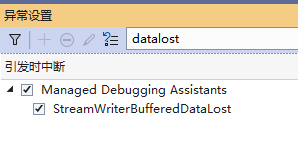
VS支持托管调试助手MDA来找出特点种类的常见编程错误。激活一个MDA就像抛出一个异常.使用方法如下:
调试>窗口>异常设置>搜索datalost 并且勾选,streamWriter 会在对象的数据丢失时候停止。
.NET中的Encoding类和BOM
在.NET的世界里,我们经常用Encoding的静态属性来得到一个Encoding类,从这里得到的编码默认都是提供BOM的(如果支持BOM的话)。
如果你想让指定编码不提供BOM,那么需要手动构造这个编码类。
//不提供BOM的Encoding编码
Encoding utf8NoBom = new UTF8Encoding(false);
Encoding utf16NoBom = new UnicodeEncoding(false, false);
Encoding utf32NoBom = new UTF32Encoding(false, false);
另外这里都是构造Little-endian的,Big-endian构造函数里也有参数。
其次UnicodeEncoding类代表UTF16编码。
文本写入时,StreamWriter类和File.WriteAllText类方法的默认编码都是不带BOM的UTF8。
和StreamReader一样 , StreamWriter也有内部缓冲区,在Write(Char)先将内如写入内部缓冲区,如果设置了sw.AutoFlush = true;属性那么每执行一次Write(Char),就会刷新一次内部缓冲区,将
缓冲区的内容写入BaseStream,然后更新更新到相应的文件。或者执行sw.Close()、swDispose()关闭内部缓冲区和baseStream也会刷新缓冲区。或者在 using(StreamWriter sw = new StreamWriter(fs)){。。。}结束后刷新缓冲区。
StreamWriter会关闭内部流的对象fs,因此不用关闭stream/filestream。
构造函数
StreamWriter(Stream) 使用 UTF-8 编码及默认的缓冲区大小,为指定的流初始化 StreamWriter 类的新实例。
StreamWriter(String) 用默认编码和缓冲区大小,为指定的文件初始化 StreamWriter 类的一个新实例。
StreamWriter(Stream, Encoding) 使用指定的编码及默认的缓冲区大小,为指定的流初始化 StreamWriter 类的新实例。
StreamWriter(String, Boolean) 用默认编码和缓冲区大小,为指定的文件初始化 StreamWriter 类的一个新实例。 string path,Boolean append 如果该文件存在,则可以将其覆盖或向其追加。 如果该文件不存在,此构造函数将创建一个新文件。
StreamWriter(Stream, Encoding, Int32) 使用指定的编码及缓冲区大小,为指定的流初始化 StreamWriter 类的新实例。int32 缓冲区大小
StreamWriter(String, Boolean, Encoding) 使用指定的编码和默认的缓冲区大小,为指定的文件初始化 StreamWriter 类的新实例。 如果该文件存在,则可以将其覆盖或向其追加。 如果该文件不存在,此构造函数将创建一个新文件。
StreamWriter(Stream, Encoding, Int32, Boolean) 使用指定的编码和缓冲区大小,为指定的流初始化 StreamWriter 类的新实例,并可以选择保持流处于打开状态。
StreamWriter(String, Boolean, Encoding, Int32) 使用指定编码和缓冲区大小,为指定路径上的指定文件初始化 StreamWriter 类的新实例。 如果该文件存在,则可以将其覆盖或向其追加。 如果该文件不存在,此构造函数将创建一个新文件。
具体功能
class StreamWaiterTest
{
static void Main()
{
//设置桌面为当前目录
Directory.SetCurrentDirectory(Environment.GetFolderPath(Environment.SpecialFolder.Desktop));
DirectoryInfo directory = Directory.CreateDirectory("StreamWaiter");
directory.Create();
if (directory.Exists)
{
DirectoryInfo subDir = directory.CreateSubdirectory("sub");
subDir.Create();
FileInfo fileinfo = new FileInfo(Path.Combine(subDir.FullName, "text.txt"));
FileStream fs = fileinfo.Create();
if (fileinfo.Exists)
{
using(StreamWriter sw = new StreamWriter(fs))
{
char[] cha = { '1', '2', '3', '4', '6' };
//属性
Console.WriteLine(sw.Encoding.GetPreamble());
sw.AutoFlush = true;//该值指示 StreamWriter 在每次调用 Write(Char) 之后是否都将其缓冲区刷新到基础流。 只有刷新到BaseStream 才能写到"text.txt"中 // 方法
sw.WriteLine("first line");
sw.WriteLine("second line ");
sw.WriteLine("third line ");
sw.Write(cha);//将字符数组写入BaseStream
sw.BaseStream.Seek(0, SeekOrigin.Begin);//重置BaseStream.的指针,将指针指向最开始位置。
sw.WriteLine("four line ");
sw.Flush();//清理当前写入器的所有缓冲区,并使所有缓冲数据写入基础流。 } } using (StreamWriter sws = new StreamWriter(Path.Combine(subDir.FullName, "text.txt"), true))//以追加方式新建流
{
sws.Write("fsfsdfsfsdfsdf"); }
} } }
【C#IO 操作】字符流(StreamWriter、StreamReader)的更多相关文章
- 文本数据IO操作--字符流
一.Reader和Writer 1. 字符流原理 Reader是所有字符输入流的父类而Writer是所有字符输出流的父类.字符流是以字符(char)为单位读写数据的.一次处理一个unicode.字符流 ...
- [Java IO]03_字符流
Java程序中,一个字符等于两个字节. Reader 和 Writer 两个就是专门用于操作字符流的类. Writer Writer是一个字符流的抽象类. 它的定义如下: public abstra ...
- Java IO: 其他字符流(下)
作者: Jakob Jenkov 译者: 李璟(jlee381344197@gmail.com) 本小节会简要概括Java IO中的PushbackReader,LineNumberReader,St ...
- Java IO之字符流和文件
前面的博文介绍了字节流,那字符流又是什么流?从字面意思上看,字节流是面向字节的流,字符流是针对unicode编码的字符流,字符的单位一般比字节大,字节可以处理任何数据类型,通常在处理文本文件内容时,字 ...
- Java——文件操作字符流和字节流的区别
转:http://blog.csdn.net/joephoenix/articles/2283165.aspx java的IO流分两种流 字节流 InputStream OutputStream 字符 ...
- Java IO编程——字符流与字节流
在java.io包里面File类是唯一 一个与文件本身有关的程序处理类,但是File只能够操作文件本身而不能够操作文件的内容,或者说在实际的开发之中IO操作的核心意义在于:输入与输出操作.而对于程序而 ...
- IO之字符流
什么是字符流 对于文本文件(.txt .java .c .cpp) 使用字符流处理 注意点 读入的文件一定要存在 否则就会报FileNotFoundException 异常的处理 为了保证流资源 一定 ...
- java IO之 字符流 (字符流 = 字节流 + 编码表) 装饰器模式
字符流 计算机并不区分二进制文件与文本文件.所有的文件都是以二进制形式来存储的,因此, 从本质上说,所有的文件都是二进制文件.所以字符流是建立在字节流之上的,它能够提供字符 层次的编码和解码.列如,在 ...
- Java——IO类 字符流概述
body, table{font-family: 微软雅黑} table{border-collapse: collapse; border: solid gray; border-width: 2p ...
- Java IO(四--字符流基本使用
在上一节,介绍了字节流的基本使用,本节介绍一下字符流的使用 Reader: public abstract class Reader implements Readable, Closeable { ...
随机推荐
- 针对vue中请求数据对象新添加的属性不能响应式的解决方法
1.需要给对象添加属性时,不能采用传统的obj.属性=值,obj[属性]=值 来添加属性,在vue页面时需要这样使用 this.$set(obj,"propertyName",&q ...
- gin中在中间件或handler中使用goroutine
package main import ( "fmt" "github.com/gin-gonic/gin" "log" "tim ...
- 用 CSS 让你的文字更有文艺范
透明文字,模糊文字,镂空文字,渐变文字,图片背景文字,用 CSS 让你的文字也有 freestyle- 前言 我们做页面涉及字体的时候,最多就是换个 color 换个 font-family,总是觉得 ...
- Typora基础快捷键使用流程
Typora简介 Typora是一个所见即所得的Markdown格式文本编辑器,支持windows.macOS和GNU\Linux操作系统,包括对GitHub Flavored Markdown扩展格 ...
- RMAN-20201: datafile not found in the recovery catalog
oracle恢复报错如下: Recovery Manager: Release 10.2.0.4.0 - Production on Fri Aug 28 14:31:31 2015 Copyrigh ...
- 洛谷P1060 java题解
题目描述: 解题思路: 重要度相当于价值的倍率 (物品价格*重要度=价值) 经典的背包问题 直接DP把各种情况下的最优解打表出来取最后一个就行了 代码: import java.util.Scanne ...
- dubbo框架的使用方法。。。
图解. 一.dubbo使用须知. 1.所有的service层必须要使用service注解(之前用的spring框架的,现在用dubbo框架所提供的@Service注解) // @Service(tim ...
- Transformer可解释性:注意力机制注意到了什么?
原创作者 | FLPPED 论文: Self-Attention Attribution: Interpreting Information Interactions Inside Transform ...
- Java-方法的递归调用
方法的递归是指在一个方法的内部调用自身的过程.递归必须要有结束条件,否则将陷入无限递归的状态,永远无法结束调用. 代码 public class Example24{ public static vo ...
- CAAnimation——简介