mysql系列--sql实现原理
count(*)
MyISAM 引擎把⼀个表的总⾏数存在了磁盘上,因此执⾏ count(*) 的时候会直接返回这个数,效率很⾼;但是加了条件则不能快速返回
⽽ InnoDB 引擎就麻烦了,它执⾏ count(*) 的时候,需要把数据⼀⾏⼀⾏地从引擎⾥⾯读出来,然后累积计数。
InnoDB选择一行行计算是因为不同事物中读物到的数量不同,单行读取能保证事物数据的正确性。
针对count(*)mysql做了优化,普通索引比主键索引数据少,count(*)对于每个索引计算出的值都是相同的,mysql优化器会选择最小的索引树遍历
MyISAM 表虽然 count(*) 很快,但是不⽀持事务;
show table status 命令虽然返回很快,但是不准确;
InnoDB 表直接 count(*) 会遍历全表,虽然结果准确,但会导致性能问题。
对于频繁查询总数的场景,可自己记录表总数
缓存计数:启动redis查询总数后续自己维护数量增减,但是增减redis数量和数据库插入数据之间不是原子操作会导致实际数量和数据有出入,同时不支持分布式事物。
数据库计数:数据库中保存每个表的总数,利用事物达到数量和实际数据的一致性
⾸先要弄清楚 count() 的语义。count() 是⼀个聚合函数,对于返回的结果集,⼀⾏⾏地判断,如果 count 函数的参数不是 NULL,累计值就加 1,否则不加。最后返回累计值。
所以,count(*)、count(主键 id) 和 count(1) 都表示返回满⾜条件的结果集的总⾏数;⽽count(字段),则表示返回满⾜条件的数据⾏⾥⾯,参数“字段”不为 NULL 的总个数。
⾄于分析性能差别的时候,你可以记住这么⼏个原则:
1. server 层要什么就给什么;
2. InnoDB 只给必要的值;
3. 现在的优化器只优化了 count(*) 的语义为“取⾏数”,其他“显⽽易⻅”的优化并没有做。
count(主键 id) ,InnoDB 引擎会遍历整张表,把每⼀⾏的 id 值都取出来,返回给server 层。server 层拿到 id 后,判断是不可能为空的,就按⾏累加。
count(1) ,InnoDB 引擎遍历整张表,但不取值。server 层对于返回的每⼀⾏,放⼀个数字“1”进去,判断是不可能为空的,按⾏累加。
单看这两个⽤法的差别的话,你能对⽐出来,count(1) 执⾏得要⽐ count(主键 id) 快。因为从引擎返回 id 会涉及到解析数据⾏,以及拷⻉字段值的操作。
count(字段) :
1. 如果这个“字段”是定义为 not null 的话,⼀⾏⾏地从记录⾥⾯读出这个字段,判断不能为null,按⾏累加;
2. 如果这个“字段”定义允许为 null,那么执⾏的时候,判断到有可能是 null,还要把值取出来再判断⼀下,不是 null 才累加。
也就是前⾯的第⼀条原则,server 层要什么字段,InnoDB 就返回什么字段。
但是 count(*) 是例外,并不会把全部字段取出来,⽽是专⻔做了优化,不取值。count(*) 肯定不是 null,按⾏累加。
主键 id 肯定⾮空啊,为什么不能按照count(*) 来处理优化下,因为类似优化过多,count(*)已优化,其他暂不优化
结论是:按照效率排序的话,count(字段)<count(主键 id)<count(1)≈count(*),所以我建议你,尽量使⽤ count(*)。
自测结论:selct(1)>select(*)>select(自增主键)>select(业务数字主键)>select(业务字符型主键)>select(普通唯一索引)
order by
全字段排序
MySQL 会给每个线程分配⼀块内存⽤于排序,称为 sort_buffer。
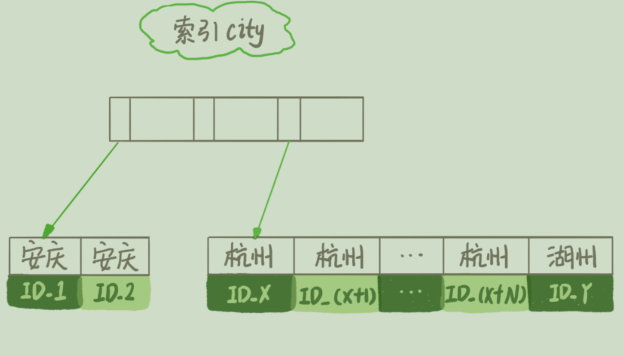
select city,name,age from t where city='杭州' order by name limit 1000;
1. 初始化 sort_buffer,确定放⼊ name、city、age 这三个字段;
2. 从索引 city 找到第⼀个满⾜ city='杭州’条件的主键 id,也就是图中的 ID_X;
3. 到主键 id 索引取出整⾏,取 name、city、age 三个字段的值,存⼊ sort_buffer 中;
4. 从索引 city 取下⼀个记录的主键 id;
5. 重复步骤 3、4 直到 city 的值不满⾜查询条件为⽌,对应的主键 id 也就是图中的 ID_Y;
6. 对 sort_buffer 中的数据按照字段 name 做快速排序;
7. 按照排序结果取前 1000 ⾏返回给客户端。
“按 name 排序”这个动作,可能在内存中完成,也可能需要使⽤外部排序,这取决于排序所需的内存和参数 sort_buffer_size。
sort_buffer_size,就是 MySQL 为排序开辟的内存(sort_buffer)的⼤⼩。如果要排序的数据量⼩于 sort_buffer_size,排序就在内存中完成。但如果排序数据量太⼤,内存放不下,则不得不利⽤磁盘临时⽂件辅助排序。
rowid 排序
在上⾯这个算法过程⾥⾯,只对原表的数据读了⼀遍,剩下的操作都是在 sort_buffer 和临时⽂件中执⾏的,问题在于字段多时内存只能存放少量数据,需要分成许多临时文件,效率低
SET max_length_for_sort_data = 16;
max_length_for_sort_data,是 MySQL 中专⻔控制⽤于排序的⾏数据的⻓度的⼀个参数。意思是,如果单⾏的⻓度超过这个值,MySQL 就认为单⾏太⼤,要换⼀个算法
city、name、age 这三个字段的定义总⻓度是 36,我把 max_length_for_sort_data 设置为16,换新算法:
新的算法放⼊ sort_buffer 的字段,只有要排序的列(即 name 字段)和主键 id。
但这时,排序的结果就因为少了 city 和 age 字段的值,不能直接返回了,整个执⾏流程就变成如下所示的样⼦:
1. 初始化 sort_buffer,确定放⼊两个字段,即 name 和 id;
2. 从索引 city 找到第⼀个满⾜ city='杭州’条件的主键 id,也就是图中的 ID_X;
3. 到主键 id 索引取出整⾏,取 name、id 这两个字段,存⼊ sort_buffer 中;
4. 从索引 city 取下⼀个记录的主键 id;
5. 重复步骤 3、4 直到不满⾜ city='杭州’条件为⽌,也就是图中的 ID_Y;
6. 对 sort_buffer 中的数据按照字段 name 进⾏排序;
7. 遍历排序结果,取前 1000 ⾏,并按照 id 的值回到原表中取出 city、name 和 age 三个字段返回给客户端。
即:通过where条件找到排序字段和id放到sort_buffer中,排序后通过id到原表中取出结果返回。
排序是个耗性能的操作,可通过将排序字段和筛选字段做成联合索引,天然有序,或者使用覆盖索引
小惊喜
1、积少成多,下载高佣联盟,领取各大平台隐藏优惠券,每次购物省个十块八块不香吗,通过下方二维码注册的用户可添加微信liershuang123(微信号)领取价值千元海量学习视频。
为表诚意奉献部分资料:
软件电子书:链接:https://pan.baidu.com/s/1_cUtPtZZbtYTF7C_jwtxwQ 提取码:8ayn
架构师二期:链接:https://pan.baidu.com/s/1yMhDFVeGpTO8KTuRRL4ZsA 提取码:ui5v
架构师阶段课程:链接:https://pan.baidu.com/s/16xf1qVhoxQJVT_jL73gc3A 提取码:2k6j

2、本人重金购买付费前后端分离脚手架源码一套,现10元出售,加微信liershuang123获取源码
mysql系列--sql实现原理的更多相关文章
- MySQL系列(九)--InnoDB索引原理
InnoDB在MySQL5.6版本后作为默认存储引擎,也是我们大部分场景要使用的,而InnoDB索引通过B+树实现,叫做B-tree索引.我们默认创建的 索引就是B-tree索引,所以理解B-tree ...
- MySQL系列(七)--SQL优化的步骤
前面讲了如何设计数据库表结构.存储引擎.索引优化等内存,这篇文章会讲述如何进行SQL优化,也是面试中关于数据库肯定会被问到的, 这些内容不仅仅是为了面试,更重要的是付诸实践,最终用到工作当中 之前的M ...
- 无法复现的“慢”SQL《死磕MySQL系列 八》
系列文章 四.S 锁与 X 锁的爱恨情仇<死磕MySQL系列 四> 五.如何选择普通索引和唯一索引<死磕MySQL系列 五> 六.五分钟,让你明白MySQL是怎么选择索引< ...
- MySQL 系列(四)主从复制、备份恢复方案生产环境实战
第一篇:MySQL 系列(一) 生产标准线上环境安装配置案例及棘手问题解决 第二篇:MySQL 系列(二) 你不知道的数据库操作 第三篇:MySQL 系列(三)你不知道的 视图.触发器.存储过程.函数 ...
- MySQL系列:高可用架构之MHA
前言 从11年毕业到现在,工作也好些年头,入坑mysql也有近四年的时间,也捣鼓过像mongodb.redis.cassandra.neo4j等Nosql数据库.其实一直想写博客分享下工作上的零零碎碎 ...
- Mysql系列八:Mycat和Sharding-jdbc的区别、Mycat分片join、Mycat分页中的坑、Mycat注解、Catlet使用
一.Mycat和Sharding-jdbc的区别 1)mycat是一个中间件的第三方应用,sharding-jdbc是一个jar包 2)使用mycat时不需要改代码,而使用sharding-jdbc时 ...
- MySQL系列(一)--基础知识(转载)
安装就不说了,网上多得是,我的MySQL是8.0版本,可以参考:CentOS7安装MySQL8.0图文教程和MySQL8.0本地访问设置为远程访问权限 我的MySQL安装在阿里云上面,阿里云向外暴露端 ...
- MySQL强人“锁”难《死磕MySQL系列 三》
系列文章 一.原来一条select语句在MySQL是这样执行的<死磕MySQL系列 一> 二.一生挚友redo log.binlog<死磕MySQL系列 二> 前言 最近数据库 ...
- 什么?还在用delete删除数据《死磕MySQL系列 九》
系列文章 五.如何选择普通索引和唯一索引<死磕MySQL系列 五> 六.五分钟,让你明白MySQL是怎么选择索引<死磕MySQL系列 六> 七.字符串可以这样加索引,你知吗?& ...
随机推荐
- oracle监控参数
Sar –u 检查CPU的繁忙程度列说明Usr用户模式下cpu运行所占的百分比Sys系统模式下cpu运行所占的百分比Wio因为有进程等待块I/O而使cpu处于闲置状态所占百分比IdleCpu为闲置状态 ...
- LeetCode--二叉树1--树的遍历
LeetCode--二叉树1--树的遍历 一 深度遍历 深度遍历里面由 三种遍历方式,两种实现方法.都要熟练掌握. 值得注意的是,当你删除树中的节点时,删除过程将按照后序遍历的顺序进行. 也就是说,当 ...
- 7-43 jmu-python-字符串异常处理 (20 分)
输入一行字符串及下标,能取出相应字符.程序能对不合法数据做相应异常处理. 输入格式: 行1:输入一字符串 行2:输入字符下标 输出格式: 下标非数值异常,输出下标要整数 下标越界,输出下标越界 数据正 ...
- 简单说 用CSS做一个魔方旋转的效果
说明 魔方大家应该是不会陌生的,这次我们来一起用CSS实现一个魔方旋转的特效,先来看看效果图! 解释 我们要做这样的效果,重点在于怎么把6张图片,摆放成魔方的样子,而把它们摆放成魔方的样子,重点在于用 ...
- 蚂蚁金服开源 | 可视化图形语法G2 3.3 琢磨
G2 是蚂蚁金服数据可视化解决方案 AntV 的一个子产品,是一套数据驱动的.高交互的可视化图形语法. 经过两个多月密锣紧鼓的开发,400+次提交,G2 3.3版本今天终于和大家见面了.自上次3.2版 ...
- Sketchup二次开发教程
Sketchup提供了两套API: C API,主要用于读写SU文件.我们的SU文件导入功能就是用这套API做的 Ruby API,用于开发SU插件 这次我们主要关注Ruby API,因为它是实现更丰 ...
- I - A计划 HDU - 2102
A计划 Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submiss ...
- 简单服务器端Blazor Cookie身份验证的演示
为了演示身份验证如何在服务器端 Blazor 应用程序中工作,我们将把身份验证简化为最基本的元素. 我们将简单地设置一个 cookie,然后读取应用程序中的 cookie. 应用程序身份验证 大多数商 ...
- iview中遇到table的坑(已经修改了table的数据,但是界面没有更新)
https://blog.csdn.net/bigdargon/article/details/89381466 https://blog.csdn.net/qiuyan_f/article/deta ...
- Node的require和module.exports
node编程中最重要的思想之一就是模块,在 Node.js 模块系统中,每个文件都被视为独立的模块.这是这个思想,让javascript的大规模工程成为可能.模块化编程在前端大肆盛行,在node中导出 ...