散列表和JAVA中的hash
引文
hello,今天写的数据结构是散列表(hash表),也算是一种基础数据结构了吧。学过计算机的人大概都能说出来这是个以空间换时间的东西,那么具体怎么实现的是今天要讨论的问题。
为什么需要它?主要还是人们希望能完成O(1)时间复杂度的查询,之前我们学习的最优秀的数据结构AVL树也是O(lg n)量级的。很多人想到了数组这种数据结构,数组可以随机访问,在知道索引的情况下,可以O(1)时间访问之。最初的思想是将关键字的值作为索引,在对应的位置上存储数字,以1、3、5、8为例,建立一个8个长度的数组,索引为1、3、5、8的位置存储true,其他为false,算是初步达到了目的。当然,后续的改进都是在此基础上进行的,基本思想没有变化。
如果只存两个数,1和10000,那岂不是要创建个10000长度的数组,但是只存两个有效数据吗?
那如果关键字是string呢?
这时候就需要一个函数,完成对关键字的转换工作,也即将原先的关键字转化为索引,根据索引存储数据。
定义
|
散列与散列函数 散列表是存储数组。散列是通过推演出对象的数值散列码,并把这个散列码映射到散列表中的位置来在散列表中存储对象的过程。将对象映射到散列表中位置的函数就叫散列函数。 |
散列冲突
有个问题必须要考虑,通过散列函数转化关键字,两个不同的关键字会不会转换结果相同?
当然会!存储数组位置是有限的,而输入变量在输入空间中是个无限可能的量,必然存在转换结果相同的情况,这种情况我们叫做散列冲突。有问题就要解决,如何解决冲突,可以先思考一下。哈哈,鄙人第一次考虑的时候猜对过其中一类办法,当然,不难。
说散列冲突之前,先说散列函数。有哪些散列函数?散列之前先将输入变量转换成整数,举个例子,先将字符串各个位置的字母编号加一起得到结果:
|
cat = 3+1+20 = 24 dog = 4+15+7 = 26 ear = 5+1+18 = 24 |
以上计算结果叫做散列码,知道散列码还不够,要将其映射到数组对应的位置上。比方说,数组大小为10。使用散列函数 h(k) = k mod 10,则以上三个单词有两个存储在4位置,发生了冲突。当然,你可以设计其他映射函数,但是肯定会有冲突的情况发生,如何解决散列冲突是最关键的。
开放寻址法
开放寻址法,在散列表内寻找另一个位置存储数据。常用的有线性探查法和二次探查法。
线性探查法设映射函数为h,表的规模为N,被映射的关键字是k。如果在表中散列位置h(k)上发生冲突,那么线性探查法依次检查位置(h(k) + i)mod N, i=1,2,...,直到某个(h(k) + i)是空位置,或者(h(k) + i)mod N = h(k)结束。 |
线性探查法有个问题,考虑最坏情况,所有存储值都在同一个位置冲突。每次寻找一个新的位置存储数据,第一次冲突寻找1次,第二次冲突2次,直到第N-1次冲突,需要寻找N-1次。
假设你的散列函数可以使得在表的各位置均匀地分布关键字。如上例中,10长度的数组中已经插入cat于第四个索引处。之后再插入一个数,各个位置的概率?发现除了4,和5之外位置为1/10,而5位置的概率为2/10。随着冲突项继续插入,这个概率会越来越大。
这种堆积效应使得插入和查找的复杂度都变为O(N)。
|
二次探查法 设散列函数为h,表的规模为N,要散列的关键字为k。那么,如果在散列位置h(k)发生冲突,二次探查法依次检查位置(h(k) +i2),直到某个位置是个空位置,或者已经检查过的位置。 |
相对线性探查法,二次探查确实可以一定程度避免堆积。但二次探查法最坏情况下,即所有关键字在同一个位置冲突下,数组的利用率为1/2。可以证明,对于任意素数N,一旦一个位置被检查两次,那么之后的所有位置都是被已检查过的位置。
//设在i和j结束于相同位置
(h+i2) mod N = (h+j2) mod N
→ (i+j)(i-j) mod N = 0
//因为N是素数,它必须整除因子(i+j)或(i-j),只有做了N次探查,N才能整除(i-j);同时,使得N整除(i+j)的最小(i+j)为N。
→ i+j = N → j = N - i
//故而不同的探查位置数只能是N/2。
最坏情况的搜索和插入运行时间依旧是O(N)。
封闭寻址法
封闭寻址法不把关键字存储在表中,而是把散列在相同位置的所有关键字都存储在一个“吊挂”在那个位置上的数据结构中。最常见的就是链表,在java中java.util.HashMap就采用这样的设计。盗图盗图:
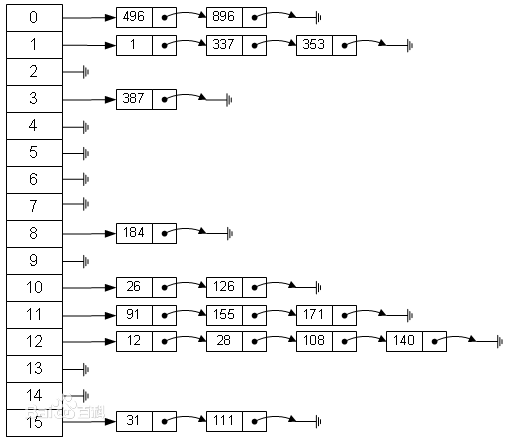
先介绍一个量,负载因子 a = n/N,n为散列表中的实际项数,N为散列表的容量。一般来说,负载因子越大,搜索的时间就越长。
同开放寻址法,最坏的插入和搜索的时间复杂度都是O(n),当然如果是对关键字完美散列的散列函数,时间复杂度都是O(1)。
java中HashMap是一种字典结构,实现了散列表的功能,存储(key,value)键值对,至少支持get(key)、put(key,value)、delete(key)方法。广义上来说,列表和二叉查找树都是字典。
HashMap的创建
// 创建默认容量为16,默认负载因子上限为0.75的hashmap
HashMap<String,String> phoneBook = new HashMap<String,String>(); // 创建默认容量大于101的hashmap,但hashmap容量为2的幂,故实际容量为128
HashMap<String,String> phoneBook = new HashMap<String,String>(101); // 创建初始容量为128,负载因子上限为2.5的散列表
HashMap<String,String> phoneBook = new HashMap<String,String>(128, 2.5);
实际负载因为 a = n/N , 此处设置的上限,超过负载因子上限的时候,就会进行散列表扩展,每次扩展都为之前的2倍。
HashMap项的存储
以鄙人的1.8版本jdk为例,其成员变量:
/* ---------------- Fields -------------- */
transient Node<K,V>[] table;
transient Set<Map.Entry<K,V>> entrySet;
transient int size;
int threshold;
final float loadFactor;
transient关键字声明的成员不能被序列化和反序列化,与本文关系不大,不用在意。
size是散列表的实际存储项数
threshold是散列表项数上限,等于容量和负载因子上限的乘积:N*t,因此size最大值为threshold。
loadFactor是初始化时设定的负载因子上限值。
Node<K,V>[] table 构建一个链表数组,每一个Node<K,v>都是一个节点,Node对用户不可见,其数据结构为:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
...
}
HashMap操作
源码写到东西太多了,代码就用简化版本吧,声明一下,这个不是jdk1.8源码啊,可能是老版本的。
添加项
public V put(K key, V value) {
K k = mashNull(key);
int hash = hash(k);
int i = indexFor(hash, table.length);
for(Node<K,V> e = table[i]; e!=null; e=e.next){
if ((e.hash == hash)&&(eq(k, key)){ // eq判断是否相等
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
++modCount;
addNode(hash, k, value, i);
return null;
}
Node的数据结构如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
...
}
2行mashNull()处理为空的情况,indexFor将散列码映射到表位置上:
static int indexFor(int h, int length){
return h & (length-1);
}
其作了一个位操作,按位并,length是2的幂,(length-1)与h并,就是取模,这个思考一下,很简单的。
addNode()为插入操作。
void addNode(int hash, K key, V value, int bucketIndex){
Node<K,V> e = table[bucketIndex];
table[bucketIndex] = new Node<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2*table.length);
}
在表中插入的位置称为桶,resize()是再散列方法,新表容量是原表的2倍。代码如下:
void resize(int newCapacity){
Node[] oldtable = table;
int oldCapacity = oldtable.length;
if(oldCapacity == MAXIMUM_CAPACITY){
threshould = Integer.MAX_VALUE;
return;
}
Node[] newTable = new Node[newCapacity];
transfer(newTable);
table = newTable;
threshould = (int)(newCapacity*loadFactor);
}
如果旧容量已经达到最大可能值而没有满足需要,那就将最大容量上限设为最大可能整数值,然后返回。如果不是的话,就创建2倍容量的新表,并对原表中的项重新散列。考虑下散列码1和9在容量8下索引都为1,但在16容量下索引分别为1和9,故需要重新散列。这个功能在方法transfer()中实现。
void transfer(Node[] newtable){
Node[] src = table;
int newCapacity = newtable.length;
for(int j=0; j<src.length; j++){
Node<K,V> e = src[j];
if(e!=null){
src[j] = null;
do{
Node<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newtable[i];
newtable[i] = e;
e = next;
}while (e!=null);
}
}
}
以上。
散列表和JAVA中的hash的更多相关文章
- 散列表Java实现
package 散列表; import java.util.Scanner; public class HashSearch { public static int data[] = {69,65,9 ...
- 读APUE分析散列表的使用
最近学习APUE读到避免线程死锁的部分,看到部分源码涉及到避免死锁部分,源码使用了散列表来实现对结构(struct)的存储与查找. 本文不讨论代码中的互斥量部分. #include <stdli ...
- linux内核的双链表list_head、散列表hlist_head
一.双链表list_head 1.基本概念 linux内核提供的标准链表可用于将任何类型的数据结构彼此链接起来. 不是数据内嵌到链表中,而是把链表内嵌到数据对象中. 即:加入链表的数据结构必须包含一个 ...
- 为什么我要放弃javaScript数据结构与算法(第七章)—— 字典和散列表
本章学习使用字典和散列表来存储唯一值(不重复的值)的数据结构. 集合.字典和散列表可以存储不重复的值.在集合中,我们感兴趣的是每个值本身,并把它作为主要元素.而字典和散列表中都是用 [键,值]的形式来 ...
- Nginx数据结构之散列表
1. 散列表(即哈希表概念) 散列表是根据元素的关键码值而直接进行访问的数据结构.也就是说,它通过把关键码值映射到表中一个位置来访问记录, 以加快查找速度.这个映射函数 f 叫做散列方法,存放记录的数 ...
- Java中如何判断两个对象是否相等(Java equals and ==)
原文https://www.dutycode.com/post-140.html 如何判断两个对象相等,这个问题实际上可以看做是如何对equals方法和hashcode方法的理解. 从以下几个点来理解 ...
- java-集合排序,队列,散列表map以及如何遍历
1.1集合排序 可以通过集合的工具类java.util.Collections的静态方法sort需要注意的时,只能对List排序,因为它有序. Collections.sort(list); 排序字符 ...
- C++中的重载隐藏覆盖&&JAVA中的重载覆盖&&多态
class 类继承默认是private, struct 默认继承是public C++中的隐藏: 只要派生类中出现和基类一样的函数名,基类中的函数就会被派生类中的函数给隐藏(如果派生类和基类中的函数名 ...
- Java中的HashMap 浅析
在Java的集合框架中,HashSet,HashMap是用的比较多的一种,顺序结构的ArrayList.LinkedList这种也比较多,而像那几个线程同步的容器就用的比较少,像Vector和Hash ...
随机推荐
- Building Applications with Force.com and VisualForce(Dev401)( 九):Designing Applications for Multiple Users: Putting It All Together
Module Objectives1.Apply profiles, organization wide defaults, role hierarchy and sharing to given a ...
- 深度学习、物联网专家Sunil Kumar Vuppala博士独家专访
介绍 有多种方法可以学习数据科学,机器学习和深度学习概念.您可以观看视频,阅读文章,参加课程,参加会议等.但是有一件事是无法替代的----经验. 我个人从与数据科学专家和行业领袖的交流中学到了很多.他 ...
- Python Seaborn综合指南,成为数据可视化专家
概述 Seaborn是Python流行的数据可视化库 Seaborn结合了美学和技术,这是数据科学项目中的两个关键要素 了解其Seaborn作原理以及使用它生成的不同的图表 介绍 一个精心设计的可视化 ...
- 十 | 门控循环神经网络LSTM与GRU(附python演练)
欢迎大家关注我们的网站和系列教程:http://panchuang.net/ ,学习更多的机器学习.深度学习的知识! 目录: 门控循环神经网络简介 长短期记忆网络(LSTM) 门控制循环单元(GRU) ...
- iOS 架构
一.MVC MVC 全名 Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写,一种软件设计典范,用一种业务逻辑.数据.界面显示分离 ...
- MySQL进阶篇(01):基于多个维度,分析服务器性能
本文源码:GitHub·点这里 || GitEE·点这里 一.服务器性能简介 1.性能定义 服务器性能优化是一项非常艰巨的任务,当然也是很难处理的问题,在写这篇文章的时候,特意请教下运维大佬,硬件工程 ...
- ES6 class 类的理解(一)
优点 ES6 的类提供了几点明显的好处: 兼容当前大量的代码. 相对于构造器和构造器继承,类使初学者更容易入门. 子类化在语言层面支持. 可以子类化内置的构造器. 不再需要继承库:框架之间的代码变得更 ...
- 在函数中修改全局变量的值,需要加global关键字
一.引用 使用到的全局变量只是作为引用,不在函数中修改它的值的话,不需要加global关键字.如: #! /usr/bin/python a = 1 b = [2, 3] def func(): if ...
- 操作系统-1-存储管理之LFU页面置换算法(leetcode460)
LFU缓存 题目:请你为 最不经常使用(LFU)缓存算法设计并实现数据结构.它应该支持以下操作:get 和 put. get(key) - 如果键存在于缓存中,则获取键的值(总是正数),否则返回 -1 ...
- mpvue小程序开发
查阅资料,看官方文档,知道mpvue是一个使用 Vue.js 开发小程序的前端框架(美团的开源项目).框架基于 Vue.js 核心,mpvue 修改了 Vue.js 的 runtime 和 compi ...