《Redis开发与运维》
第1章 初识Redis
1. Redis介绍:
Redis是一种基于键值对(key-value)的NoSQL数据库。
与很多键值对数据库不同的是,Redis中的值可以是由string(字符串)、hash(哈希)、list(列表)、set(集合)、zset(有序集合)等多种数据结构和算法组成,因此Redis可以满足很多的应用场景。
而且因为Redis会将所有数据都存放在内存中,所以它的读写性能非常惊人。
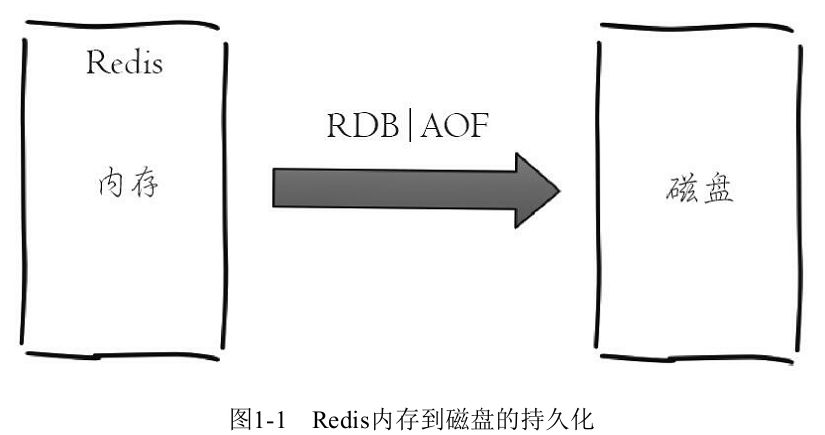
不仅如此,Redis还可以将内存的数据利用快照(RDB)和日志(AOF)的形式保存到硬盘上,这样在发生类似断电或者机器故障的时候,内存中的数据不会“丢失”。
2. Redis特性:
(1)速度快。速度快的原因:
- Redis的所有数据都是存放在内存中的,这是Redis速度快的最主要原因。
- Redis是用C语言实现的,一般来说C语言实现的程序“距离”操作系统更近,执行速度相对会更快。
- Redis使用了单线程架构,预防了多线程可能产生的竞争问题。
(2)基于键值对的数据结构服务器。
与很多键值对数据库不同的是,Redis中的值不仅可以是字符串,而且还可以是具体的数据结构,它主要提供了5种数据结构:字符串、哈希、列表、集合、有序集合。这样不仅能便于在许多应用场景的开发,同时也能够提高开发效率。
(3)简单稳定
- 首先,Redis的源码很少。
- 其次,Redis使用单线程模型,这样不仅使得Redis服务端处理模型变得简单,而且也使得客户端开发变得简单。
- 最后,Redis不需要依赖于操作系统中的类库(例如Memcache需要依赖libevent这样的系统类库),Redis自己实现了事件处理的相关功能。
(4)持久化
通常看,将数据放在内存中是不安全的,一旦发生断电或者机器故障,重要的数据可能就会丢失,因此Redis提供了两种持久化方式:RDB和AOF,即可以用两种策略将内存的数据保存到硬盘中(如图1-1所示),这样就保证了数据的可持久性。
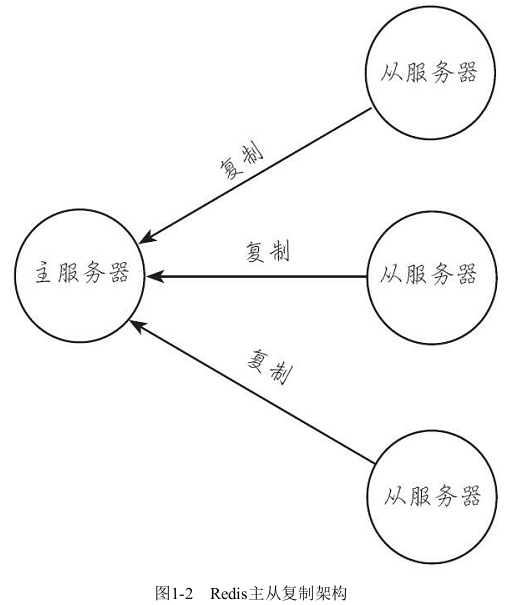
(5)主从复制
Redis提供了复制功能,实现了多个相同数据的Redis副本。
(6)高可用和分布式
Redis从2.8版本正式提供了高可用实现Redis Sentinel(哨兵模式),它能够保证Redis节点的故障发现和故障自动转移。
Redis从3.0版本正式提供了分布式实现Redis Cluster(集群模式),它是Redis真正的分布式实现,提供了高可用、读写和容量的扩展性。
3. Redis使用场景:
(1)缓存。合理地使用缓存不仅可以加快数据的访问速度,而且能够有效地降低后端数据源的压力。
(2)排行榜系统。Redis提供了列表和有序集合数据结构,合理地使用这些数据结构可以很方便地构建各种排行榜系统。
(3)计数器应用。Redis天然支持计数功能而且计数的性能也非常好。
(4)社交网络。赞/踩、粉丝、共同好友/喜好、推送、下拉刷新等是社交网站的必备功能,由于社交网站访问量通常比较大,而且传统的关系型数据不太适合保存这种类型的数据,Redis提供的数据结构可以相对比较容易地实现这些功能。
(5)消息队列系统。消息队列系统可以说是一个大型网站的必备基础组件,因为其具有业务解耦、非实时业务削峰等特性。Redis提供了发布订阅功能和阻塞队列的功能,虽然和专业的消息队列比还不够足够强大,但是对于一般的消息队列功能基本可以满足。
4. 在Linux系统上安装Redis
第1步:将redis的源码包上传到linux系统。
Alt+p打开sftp窗口:输入put "F:/java/ziyuan/redis-3.0.0.tar.gz"
第2步:解压:tar -zxvf redis-3.0.0.tar.gz
第3步:进行编译。 cd到解压后的目录 输入命令:make
第4步:进行安装。 输入命令:make install PREFIX=/usr/local/redis
启动:redis-server (加上配置文件) [root@localhost bin]# ./redis-server redis.conf
连接Redis服务:redis-cli [root@localhost bin]# ./redis-cli
停止Redes服务:redis-cli shutdown [root@localhost bin]# ./redis-cli shutdown
第2章 API的理解和使用
2.1 预备
2.1.1 全局命令:
keys * :将所有的键都输出
dbsize :输出键总数
exits key :检查某个键是否存在,如果存在返回1,不存在返回0
del key :删除某个键
expire key 时间 :为某个键设置过期时间
ttl key :观察某键的剩余过期时间
type key :返回某键的数据结构类型,如果键不存在返回none
2.1.2 数据结构与内部编码:
type命令实际返回的就是当前键的数据结构类型,它们分别是:string(字符串)、hash(哈希)、list(列表)、set(集合)、zset(有序集合),但这些只是Redis对外的数据结构。
实际上每种数据结构都有自己底层的内部编码实现,而且是多种实现,这样Redis会在合适的场景选择合适的内部编码。
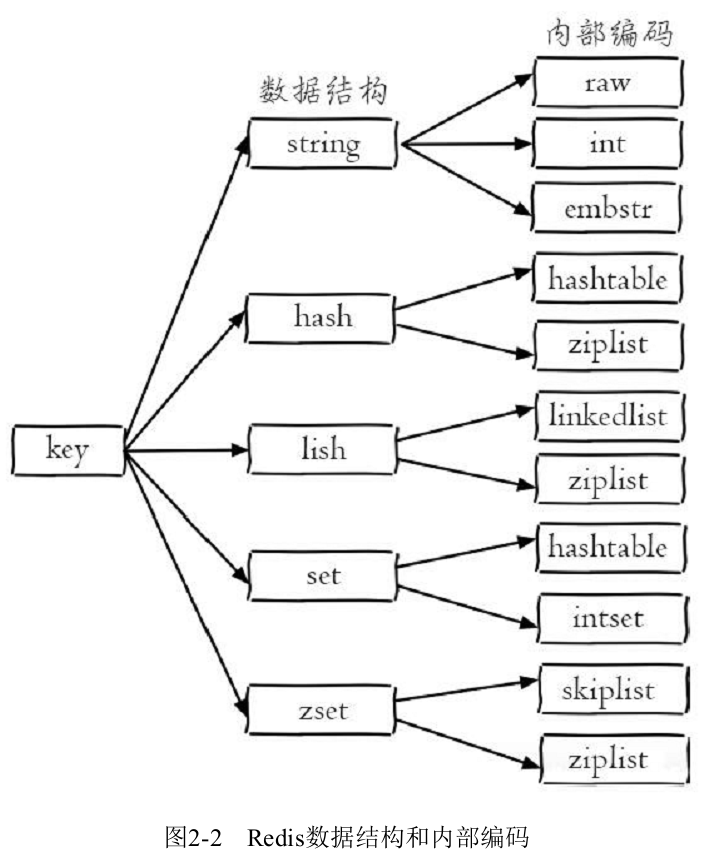
多种内部编码实现可以在不同场景下发挥各自的优势,例如ziplist比较节省内存,但是在列表元素比较多的情况下,性能会有所下降,这时候Redis会根据配置选项将列表类型的内部实现转换为linkedlist。
2.1.3 单线程架构:
(1)单线程模型:
Redis使用了单线程架构和I/O多路复用模型来实现高性能的内存数据库服务。
因为Redis是单线程来处理命令的,所以一条命令从客户端达到服务端不会立刻被执行,所有命令都会进入一个队列中,然后逐个被执行。所以假如有多个客户端命令,则这些命令的执行顺序是不确定的,但是可以确定不会有两条命令被同时执行。
但是像发送命令、返回结果、命令排队肯定不像描述的这么简单,Redis使用了I/O多路复用技术来解决I/O的问题。
(2)为什么单线程号还能这么快?
为什么Redis使用单线程模型会达到每秒万级别的处理能力呢?可以将其归结为三点:
第一,纯内存访问,Redis将所有数据放在内存中,内存的响应时长大约为100纳秒,这是Redis达到每秒万级别访问的重要基础。
第二,非阻塞I/O,Redis使用epoll作为I/O多路复用技术的实现,再加上Redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不在网络I/O上浪费过多的时间。
第三,单线程避免了线程切换和竞态产生的消耗。
2.2. 五种数据类型
2.2.1 字符串String
字符串类型的值实际可以是字符串(简单的字符串、复杂的字符串(例如JSON、XML))、数字(整数、浮点数),甚至是二进制(图片、音频、视频),但是值最大不能超过512MB。
1、命令:
- 设置值:set key value
- 获取值:get key
- 批量设置值:mset key value key value ... 例如:mset a 1 b 2 c 3
- 批量获取值:mset key key ... 例如:mset a b c
- 计数:incr key(自增)、decr key(自减)、incrby key number(自增指定数字)、decrby key number(自减指定数字)
2、字符串类型的内部编码有3种:
- int:8个字节的长整型。
- embstr:小于等于39个字节的字符串。
- raw:大于39个字节的字符串。
Redis会根据当前值的类型和长度决定使用哪种内部编码实现。
3、典型使用场景
(1)缓存功能
下图是比较典型的缓存使用场景,其中Redis作为缓存层,MySQL作为存储层,绝大部分请求的数据都是从Redis中获取。由于Redis具有支撑高并发的特性,所以缓存通常能起到加速读写和降低后端压力的作用。
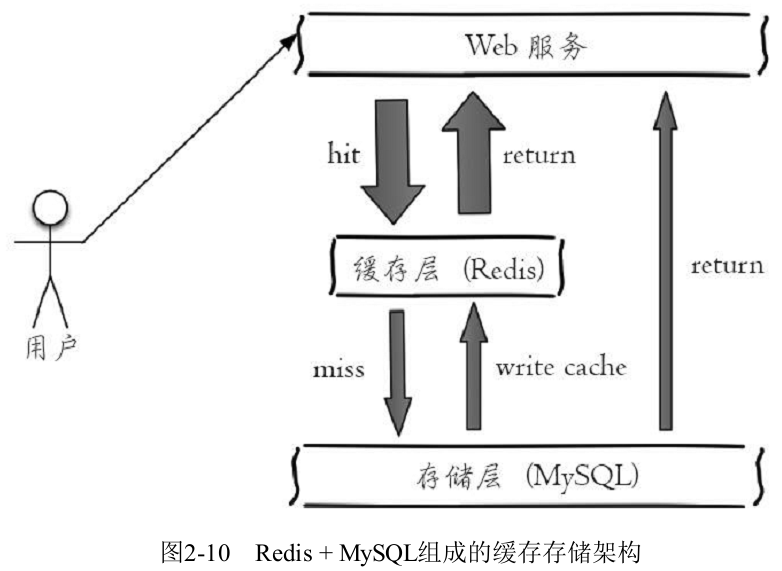
首先从Redis中获取用户信息(伪代码):

如果没有从Redis获取到用户信息,需要从MySQL中进行获取,并将结果回写到Redis,添加1小时(3600秒)过期时间:(伪代码)

(2)计数
例如使用Redis作为视频播放数计数的基础组件,用户每播放一次视频,相应的视频播放数就会自增1:

(3)共享sessio
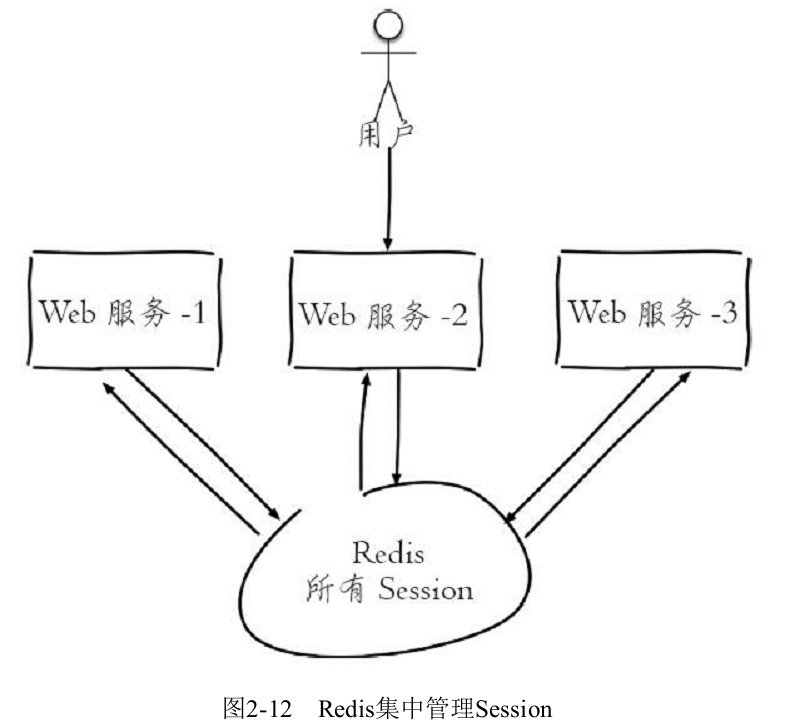
一个分布式Web服务将用户的Session信息(例如用户登录信息)保存在各自服务器中,这样会造成一个问题,出于负载均衡的考虑,分布式服务会将用户的访问均衡到不同服务器上,用户刷新一次访问可能会发现需要重新登录,这个问题是用户无法容忍的。
为了解决这个问题,可以使用Redis将用户的Session进行集中管理,如下图所示,在这种模式下只要保证Redis是高可用和扩展性的,每次用户更新或者查询登录信息都直接从Redis中集中获取。
(4)限速
很多应用出于安全的考虑,会在每次进行登录时,让用户输入手机验证码,从而确定是否是用户本人。但是为了短信接口不被频繁访问,会限制用户每分钟获取验证码的频率,例如一分钟不能超过5次。此功能可以使用Redis来实现,下面的伪代码给出了基本实现思路:

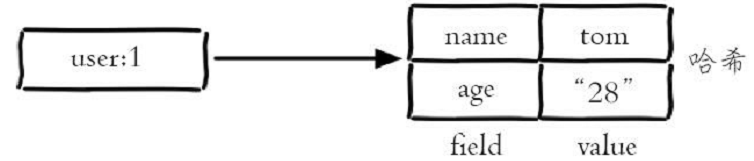
2.2.2 哈希Hash
1、命令:
- 设置值:hset key field value 例:为user:1 添加一对field-value:hset user:1 name tom
- 获取值:hget key field 例hget user:1 name
- 删除field:hdel key field [field ...] (可以同时删除多个)
- 计算field的个数:hlen key
- 批量设置或获取field-value:hmset key field value [field value ...] hmget key field [field ...]
- 判断field是否存在:hexits key field
- 获取所有field:hkeys key
- 获取所有value:hvals key
- 获取所有field-value:hgetall key
- field自增:hincrby
- 计算value的字符串长度:hstrlen key field
2、哈希类型的内部编码:
哈希类型的内部编码有两种:
ziplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个)、同时所有值都小于hash-max-ziplist-value配置(默认64字节)时,Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。
hashtable(哈希表):当哈希类型无法满足ziplist的条件时,Redis会使用hashtable作为哈希的内部实现,因为此时ziplist的读写效率会下降,而hashtable的读写时间复杂度为O(1)。
2.2.3 列表List
列表(list)类型是用来存储多个有序的字符串.
1、命令:
- 从右边插入元素:rpush key value [value ...]
- 从左边插入元素:lpush key value [value ...]
- 向某个元素(pivot)前或者后插入元素:linsert key before | after pivot value
- 查找指定范围内的元素列表:lrange key start end 例lrange listket 0 -1 查找全部元素
- 获取列表指定索引下标的元素:lindex key index
- 获取列表长度:llen key
- 从列表左侧弹出元素:lpop key
- 从列表左侧弹出元素:rpop key删除指定元素:lrem key count value (lrem命令会从列表中找到等于value的元素进行删除,根据count的不同分为三种情况:count>0,从左到右,删除最多count个元素;count<0,从右到左,删除最多count绝对值个元素;count=0,删除所有)
- 修改:lset key index newvalue
- 阻塞弹出:blpop key [key ...] timeout
2、内部编码
列表类型的内部编码有两种:
- ziplist(压缩列表):当列表的元素个数小于list-max-ziplist-entries配置(默认512个),同时列表中每个元素的值都小于list-max-ziplist-value配置时默认64字节),Redis会选用ziplist来作为列表的内部实现来减少内存的使用。
- inkedlist(链表):当列表类型无法满足ziplist的条件时,Redis会使用linkedlist作为列表的内部实现。
3、使用场景
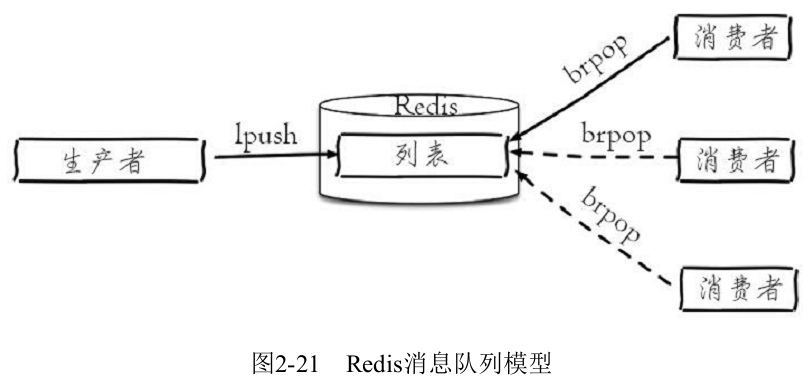
(1)消息队列
Redis的lpush+brpop命令组合即可实现阻塞队列,生产者客户端使用lrpush从列表左侧插入元素,多个消费者客户端使用brpop命令阻塞式的“抢”列表尾部的元素,多个客户端保证了消费的负载均衡和高可用性。
(2)文章列表
每个用户有属于自己的文章列表,现需要分页展示文章列表。此时可以考虑使用列表,因为列表不但是有序的,同时支持按照索引范围获取元素。
实际上列表的使用场景很多,在选择时可以参考以下口诀:
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpsh+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
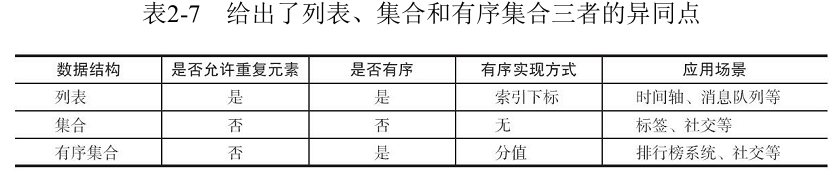
2.2.4 集合Set
集合(set)类型也是用来保存多个的字符串元素,但和列表类型不一样的是,集合中不允许有重复元素,并且集合中的元素是无序的,不能通过索引下标获取元素。
一个集合最多可以存储2^32-1个元素。Redis除了支持集合内的增删改查,同时还支持多个集合取交集、并集、差集,合理地使用好集合类型,能在实际开发中解决很多实际问题。
1、命令:
- 添加元素:sadd key element [element ...] (返回结果为添加成功的元素个数)
- 删除元素:srem key element [element ...] (返回结果为成功删除的元素个数)
- 计算元素个数:scard key
- 判断元素是否在集合中:sismember key element
- 随机从集合返回指定个数元素:srandmember key [count] (count如果不写默认为1)
- 从集合随机弹出元素:spop key
- 获取所有元素:smembers key
2、内部编码:
- intset(整数集合):当集合中的元素都是整数且元素个数小于set-maxintset-entries配置(默认512个)时,Redis会选用intset来作为集合的内部实现,从而减少内存的使用。
- hashtable(哈希表):当集合类型无法满足intset的条件时,Redis会使用hashtable作为集合的内部实现。
3、使用场景:
集合类型比较典型的使用场景是标签(tag)。例如一个用户可能对娱乐、体育比较感兴趣,另一个用户可能对历史、新闻比较感兴趣,这些兴趣点就是标签。
给用户添加标签:

2.2.5 有序集合zset
它保留了集合不能有重复成员的特性,但不同的是,有序集合中的元素可以排序。但是它和列表使用索引下标作为排序依据不同的是,它给每个元素设置一个分数(score)作为排序的依据。
1、命令:
- 添加成员:zadd key score member [score member ...]
- 计算成员个数:zcard key
- 计算某个成员的分数:zscore key member
- 计算成员的排名:zrank key member
- 删除成员:zrem key member [member ...]
- 增加成员的分数:zincrby key increment member
- 返回指定排名范围的成员:zrange key start end [withscores] (如果加上withscores选项,同时会返回成员的分数)
2、内部编码:
- ziplist(压缩列表):当有序集合的元素个数小于zset-max-ziplist-entries配置(默认128个),同时每个元素的值都小于zset-max-ziplist-value配置(默认64字节)时,Redis会用ziplist来作为有序集合的内部实现,ziplist可以有效减少内存的使用。
- skiplist(跳跃表):当ziplist条件不满足时,有序集合会使用skiplist作为内部实现,因为此时ziplist的读写效率会下降。
3、使用场景:
有序集合比较典型的使用场景就是排行榜系统。例如视频网站需要对用户上传的视频做排行榜,榜单的维度可能是多个方面的:按照时间、按照播放数量、按照获得的赞数。本节使用赞数这个维度,记录每天用户上传视频的排行榜。主要需要实现以下4个功能:
添加用户赞数:zadd和zincrby
取消用户赞数:zrem
展示获取赞数最多的十个用户:zrevrange
展示用户信息以及用户分数:zscore和zrank
2.3 数据库管理
Redis提供了几个面向Redis数据库的操作,它们分别是dbsize、select、flushdb/flushall命令。
(1) 切换数据库:select dbIndex
许多关系型数据库,例如MySQL支持在一个实例下有多个数据库存在的,但是与关系型数据库用字符来区分不同数据库名不同,Redis只是用数字作为多个数据库的实现。Redis默认配置中是有16个数据库。
例:selet 15 切换到15号数据库
能不能像使用测试数据库和正式数据库一样,把正式的数据放在0号数据库,测试的数据库放在1号数据库,那么两者在数据上就不会彼此受影响了。事实真有那么好吗?
Redis3.0中已经逐渐弱化这个功能,原因:
- Redis是单线程的。如果使用多个数据库,那么这些数据库仍然是使用一个CPU,彼此之间还是会受到影响的。
- 多数据库的使用方式,会让调试和运维不同业务的数据库变的困难,假如有一个慢查询存在,依然会影响其他数据库,这样会使得别的业务方定位问题非常的困难。
- 部分Redis的客户端根本就不支持这种方式。即使支持,在开发的时候来回切换数字形式的数据库,很容易弄乱。
如果要使用多个数据库功能,完全可以在一台机器上部署多个Redis实例,彼此用端口来做区分,因为现代计算机或者服务器通常是有多个CPU的。这样既保证了业务之间不会受到影响,又合理地使用了CPU资源。
(2)flushdb/flushall
flushdb/flushall命令用于清除数据库,两者的区别的是flushdb只清除当前数据库,flushall会清除所有数据库。
注意如果当前数据库键值数量比较多,flushdb/flushall存在阻塞Redis的可能性。
第3章 小功能大用处
3.1 慢查询分析
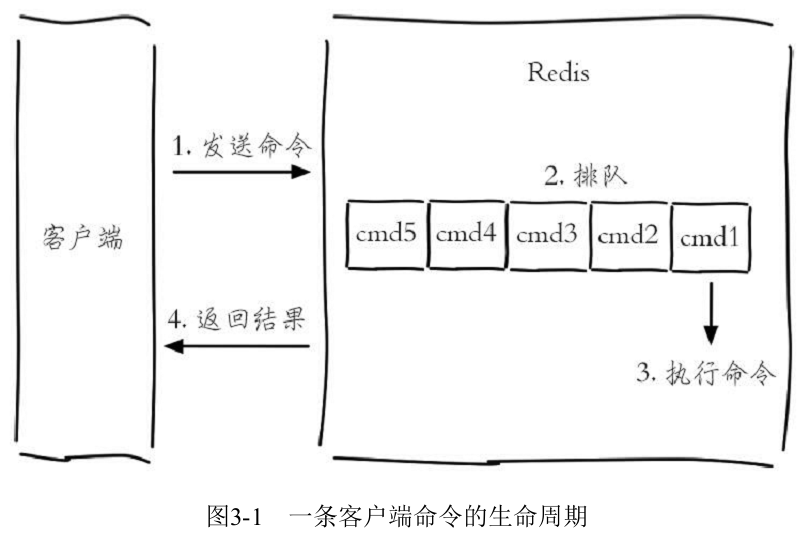
许多存储系统(例如MySQL)提供慢查询日志帮助开发和运维人员定位系统存在的慢操作。所谓慢查询日志就是系统在命令执行前后计算每条命令的执行时间,当超过预设阀值,就将这条命令的相关信息(例如:发生时间,耗时,命令的详细信息)记录下来,Redis也提供了类似的功能。如图3-1所示,Redis客户端执行一条命令分为如下4个部分:
1)发送命令 2)命令排队 3)命令执行 4)返回结果
慢查询的两个配置参数:slowlog-log-slower-than和slowlog-max-len
- slowlog-log-slower-than是预设阀值,它的单位是微秒,默认值是10000,假如执行了一条“很慢”的命令(例如keys*),如果它的执行时间超过了10000微秒,那么它将被记录在慢查询日志中。
- Redis使用了一个列表来存储慢查询日志,slowlog-max-len就是列表的最大长度。一个新的命令满足慢查询条件时被插入到这个列表中,当慢查询日志列表已处于其最大长度时,最早插入的一个命令将从列表中移出。
获取慢查询日志:slow get
获取慢查询日志列表当前的长度:slowlog len
慢查询日志重置:slowlog reset
3.2 Redis Shell
Redis提供了redis-cli、redis-server、redis-benchmark等Shell工具。
启动:redis-server (加上配置文件) [root@localhost bin]# ./redis-server redis.conf
连接Redis服务:redis-cli [root@localhost bin]# ./redis-cli
停止Redes服务:redis-cli shutdown [root@localhost bin]# ./redis-cli shutdown
redis-benchmark可以为Redis做基准性能测试:
-c(clients)选项代表客户端的并发数量(默认是50)
-n(num)选项代表客户端请求总量(默认是100000)
3.3 Pipeline
Redis客户端执行一条命令分为如下四个过程:1)发送命令 2)命令排队 3)命令执行 4)返回结果。 其中1)+4)称为RTT(往返时间)
Redis提供了批量操作命令(例如mget、mset等),有效地节约RTT。但大部分命令是不支持批量操作的,例如要执行n次hgetall命令,并没有mhgetall命令存在,需要消耗n次RTT。
Pipeline(流水线)机制能将一组Redis命令进行组装,通过一次RTT传输给Redis,再将这组Redis命令的执行结果按顺序返回给客户端。
3.4 事务与Lua
3.4.1 事务
为了保证多条命令组合的原子性,Redis提供了简单的事务功能以及集成Lua脚本来解决这个问题。
事务表示一组动作,要么全部执行,要么全部不执行。例如在社交网站上用户A关注了用户B,那么需要在用户A的关注表中加入用户B,并且在用户B的粉丝表中添加用户A,这两个行为要么全部执行,要么全部不执行,否则会出现数据不一致的情况。
Redis提供了简单的事务功能,将一组需要一起执行的命令放到multi和exec两个命令之间。multi命令代表事务开始,exec命令代表事务结束,它们之间的命令是原子顺序执行的。
Redis提供了简单的事务,之所以说它简单,主要是因为它不支持事务中的回滚特性,同时无法实现命令之间的逻辑关系计算。Lua脚本同样可以实现事务的相关功能,但是功能要强大很多。
3.4.2 Lua脚本
Redis将Lua作为脚本语言可帮助开发者定制自己的Redis命令。Lua语言提供了如下几种数据类型:booleans(布尔)、numbers(数值)、strings(字符串)、tables(表格)。
在Redis中执行Lua脚本有两种方法:eval和evalsha。
- eval 脚本内容 key个数 key列表 参数列表
例:eval 'return "hello" .. KEYS[1] .. ARGV[1]' 1 redis word (此时KEYS[1]="redis",ARGV[1]="world",所以最终的返回结果是"hello redisworld"。)
如果Lua脚本较长,还可以使用redis-cli--eval直接执行文件。
eval命令和--eval参数本质是一样的,客户端如果想执行Lua脚本,首先在客户端编写好Lua脚本代码,然后把脚本作为字符串发送给服务端,服务端会将执行结果返回给客户端。
- 除了使用eval,Redis还提供了evalsha命令来执行Lua脚本。如下图所示,首先要将Lua脚本加载到Redis服务端,得到该脚本的SHA1校验和,evalsha命令使用SHA1作为参数可以直接执行对应Lua脚本,避免每次发送Lua脚本的开销。这样客户端就不需要每次执行脚本内容,而脚本也会常驻在服务端,脚本功能得到了复用。

Lua可以使用redis.call函数实现对Redis的访问,例如下面代码是Lua使用redis.call调用了Redis的get操作:

除此之外Lua还可以使用redis.pcall函数实现对Redis的调用,redis.call和redis.pcall的不同在于,如果redis.call执行失败,那么脚本执行结束会直接返回错误,而redis.pcall会忽略错误继续执行脚本,所以在实际开发中要根据具体的应用场景进行函数的选择。
Lua脚本功能为Redis开发和运维人员带来如下三个好处:
- Lua脚本在Redis中是原子执行的,执行过程中间不会插入其他命令。
- Lua脚本可以帮助开发和运维人员创造出自己定制的命令,并可以将这些命令常驻在Redis内存中,实现复用的效果。
- Lua脚本可以将多条命令一次性打包,有效地减少网络开销。
Redis提供了4个命令实现对Lua脚本的管理:
- script load sript:此命令用于将Lua脚本加载到Redis内存中。
- script exists sha1 [sha1 ...]:此命令用于判断sha1是否已经加载到Redis内存中.
- script flush:此命令用于清除Redis内存已经加载的所有Lua脚本。
- script kill:此命令用于杀掉正在执行的Lua脚本。
3.5 Bitmaps
Redis提供了Bitmaps这个“数据结构”可以实现对位的操作。把数据结构加上引号主要因为:
- Bitmaps本身不是一种数据结构,实际上它就是字符串,但是它可以对字符串的位进行操作。
- Bitmaps单独提供了一套命令,所以在Redis中使用Bitmaps和使用字符串的方法不太相同。可以把Bitmaps想象成一个以位为单位的数组,数组的每个单元只能存储0和1,数组的下标在Bitmaps中叫做偏移量。
下面说下Bitmaps的命令。假设将每个独立用户是否访问过网站存放在Bitmaps中,将访问的用户记做1,没有访问的用户记做0,用偏移量作为用户的id:
(1)设置值:setbit key offset value (设置键的第offset个位的值(从0算起))
假设现在有20个用户,userid=0,5,11,15,19的用户对网站进行了访问,那么当前Bitmaps初始化结果如下图所示:

(2)获取值:getbit key offset (获取键的第offset位的值(从0开始算))
(3)获取Bitmaps指定范围值为1的个数:bitcount [start] [end]
(4)Bitmaps间的运算:bitop and | or | not | xor destkey key [key ...] (做多个Bitmaps的and(交集)、or(并集)、not(非)、xor(异或)操作并将结果保存在destkey中)
假设网站有1亿用户,每天独立访问的用户有5千万,如果每天用集合类型和Bitmaps分别存储活跃用户,这种情况下使用Bitmaps能节省很多的内存空间,尤其是随着时间推移节省的内存还是非常可观的。

但假如该网站每天的独立访问用户很少,例如只有10万(大量的僵尸用户),那么两者的对比如下表所示,很显然,这时候使用Bitmaps就不太合适了,因为基本上大部分位都是0。

3.6 发布订阅
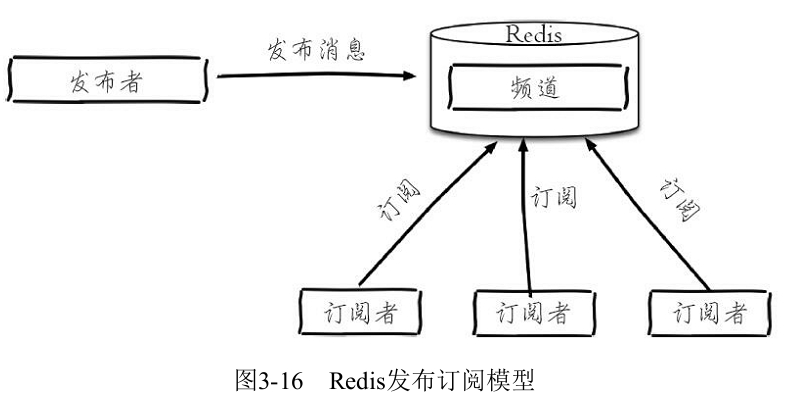
Redis提供了基于“发布/订阅”模式的消息机制,此种模式下,消息发布者和订阅者不进行直接通信,发布者客户端向指定的频道(channel)发布消息,订阅该频道的每个客户端都可以收到该消息。
命令:
- 发布消息:publish channel message ,返回结果为订阅者个数。
- 订阅消息:subscribe channel [channel ...] ,订阅者可以订阅一个或多个频道。
- 注意:1)客户端在执行订阅命令之后进入了订阅状态,只能接收subscribe、psubscribe、unsubscribe、punsubscribe的四个命令。2)·新开启的订阅客户端,无法收到该频道之前的消息,因为Redis不会对发布的消息进行持久化。
- 取消订阅:unsubscribe channel [channel ...]
- 查询订阅: 查看活跃的频道:pubsub channels [pattern] 、 查看频道订阅数:pubsub numsub [channel ...] 、查看模式订阅数:pubsub numpat
使用场景:
聊天室、公告牌、服务之间利用消息解耦都可以使用发布订阅模式,下面以简单的服务解耦进行说明。如下图示,图中有两套业务,上面为视频管理系统,负责管理视频信息;下面为视频服务面向客户,用户可以通过各种客户端(手机、浏览器、接口)获取到视频信息。

第4章 客户端
Redis是用单线程来处理多个客户端的访问,因此作为Redis的开发和运维人员需要了解Redis服务端和客户端的通信协议,以及主流编程语言的Redis客户端使用方法,同时还需要了解客户端管理的相应API以及开发运维中可能遇到的问题。本章将对这些内容进行详细分析,本章内容如下:
- 客户端通信协议
- Java客户端Jedis
- 客户端管理
- 客户端常见异常
- 客户端案例分析
4.1 客户端通信协议
- 客户端与服务端之间的通信协议是在TCP协议之上构建的。
- Redis制定了RESP(REdis Serialization Protocol,Redis序列化协议)实现客户端与服务端的正常交互,这种协议简单高效,既能够被机器解析,又容易被人类识别。
例如客户端发送一条set hello world命令给服务端,按照RESP的标准,客户端需要将其封装为如下格式(每行用\r\n分隔):

这样Redis服务端能够按照RESP将其解析为set hello world命令,执行后回复的格式如下:+OK
Redis的返回结果类型分为以下五种:
- 状态回复:在RESP中第一个字节为"+"。
- 错误回复:在RESP中第一个字节为"-"。
- 整数回复:在RESP中第一个字节为":"。
- 字符串回复:在RESP中第一个字节为"$"。
- 多条字符串回复:在RESP中第一个字节为"*"。
4.2 Java客户端Jedis
Jedis属于Java的第三方开发包,在Java中获取第三方开发包通常有两种方式:
- 直接下载目标版本的Jedis-${version}.jar包加入到项目中。
- 使用集成构建工具,例如maven、gradle等将Jedis目标版本的配置加入到项目中。
通常在实际项目中使用第二种方式,但如果只是想测试一下Jedis,第一种方法也是可以的。以Maven为例子,在项目中加入下面的依赖即可:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.8.2</version>
</dependency>
4.2.1 Jedis使用方法
//1. 生成一个Jedis对象,这个对象负责和指定Redis实例进行通信。 初始化Jedis需要两个参数:Redis实例的IP和端口
Jedis jedis = new Jedis("127.0.0.1", 6379);
//2. jedis执行set操作
jedis.set("hello", "world");
//3. jedis执行get操作, value="world"
String value = jedis.get("hello");
Jedis对于Redis五种数据结构的操作:
//-----------1.string------------
// 输出结果:OK
jedis.set("hello", "world");
// 输出结果:world
jedis.get("hello");
// 输出结果:1
jedis.incr("counter");
//-----------2.hash---------------
jedis.hset("myhash", "f1", "v1");
jedis.hset("myhash", "f2", "v2");
// 输出结果:{f1=v1, f2=v2}
jedis.hgetAll("myhash");
//-----------3.list---------------
jedis.rpush("mylist", "1");
jedis.rpush("mylist", "2");
jedis.rpush("mylist", "3");
// 输出结果:[1, 2, 3]
jedis.lrange("mylist", 0, -1);
//-----------4.set----------------
jedis.sadd("myset", "a");
jedis.sadd("myset", "b");
jedis.sadd("myset", "a");
// 输出结果:[b, a]
jedis.smembers("myset");
//------------5.zset----------------
jedis.zadd("myzset", 99, "tom");
jedis.zadd("myzset", 66, "peter");
jedis.zadd("myzset", 33, "james");
// 输出结果:[[["james"],33.0], [["peter"],66.0], [["tom"],99.0]]
jedis.zrangeWithScores("myzset", 0, -1);
4.2.2 Jedis连接池的使用方法
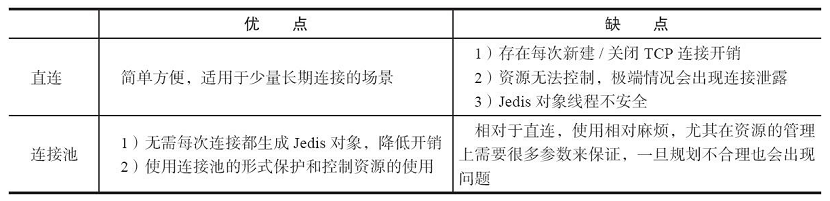
- 前面介绍的是Jedis的直连方式,所谓直连是指Jedis每次都会新建TCP连接,使用后再断开连接,对于频繁访问Redis的场景显然不是高效的使用方式。
- 因此生产环境中一般使用连接池的方式对Jedis连接进行管理。所有Jedis对象预先放在池子中(JedisPool),每次要连接Redis,只需要在池子中借,用完了在归还给池子。
客户端连接Redis使用的是TCP协议,直连的方式每次需要建立TCP连接,而连接池的方式是可以预先初始化好Jedis连接,所以每次只需要从Jedis连接池借用即可,而借用和归还操作是在本地进行的,只有少量的并发同步开销,远远小于新建TCP连接的开销。另外直连的方式无法限制Jedis对象的个数,在极端情况下可能会造成连接泄露,而连接池的形式可以有效的保护和控制资源的使用。下表给出两种方式各自的优劣势。
Jedis提供了JedisPool这个类作为对Jedis的连接池。使用JedisPool操作Redis的代码示例:
(1)Jedis连接池(通常JedisPool是单例的):
// common-pool连接池配置,这里使用默认配置
GenericObjectPoolConfig poolConfig = new GenericObjectPoolConfig();
// 初始化Jedis连接池
JedisPool jedisPool = new JedisPool(poolConfig, "127.0.0.1", 6379);
(2)获取Jedis对象不再是直接生成一个Jedis对象进行直连,而是从连接池直接获取,代码如下:
Jedis jedis = null;
try {
// 1. 从连接池获取jedis对象
jedis = jedisPool.getResource();
// 2. 执行操作
jedis.get("hello");
} catch (Exception e) {
logger.error(e.getMessage(),e);
} finally {
if (jedis != null) {
// 如果使用JedisPool,close操作不是关闭连接,代表归还连接池
jedis.close();
}
}
4.2.3 Redis中Pipeline的使用方法
回顾:Pipeline(流水线)机制能将一组Redis命令进行组装,通过一次RTT传输给Redis,再将这组Redis命令的执行结果按顺序返回给客户端。
Jedis支持Pipeline特性,我们知道Redis提供了mget、mset方法,但是并没有提供mdel方法,如果想实现这个功能,可以借助Pipeline来模拟批量删除:
public void mdel(List<String> keys) {
Jedis jedis = new Jedis("127.0.0.1");
// 1)生成pipeline对象
Pipeline pipeline = jedis.pipelined();
// 2)pipeline执行命令,注意此时命令并未真正执行
for (String key : keys) {
pipeline.del(key);
}
// 3)执行命令
pipeline.sync();
}
4.2.4 Jedis的Lua脚本
Jedis中执行Lua脚本和redis-cli十分类似,Jedis提供了三个重要的函数实现Lua脚本的执行:
Object eval(String script, int keyCount, String... params)
Object evalsha(String sha1, int keyCount, String... params)
String scriptLoad(String script)
以一个最简单的Lua脚本为例子进行说明: return redis.call('get',KEYS[1])
在redis-cli中执行上面的Lua脚本,方法如下:
eval "return redis.call('get',KEYS[1])" 1 hello
在Jedis中执行,方法如下:
String key = "hello";
String script = "return redis.call('get',KEYS[1])";
Object result = jedis.eval(script, 1, key);
System.out.println(result);
scriptLoad和evalsha函数要一起使用,首先使用scriptLoad将脚本加载到Redis中,代码如下:
String scriptSha = jedis.scriptLoad(script);
然后执行结果如下:
Stirng key = "hello";
Object result = jedis.evalsha(scriptSha, 1, key);
System.out.println(result);
4.3 客户端管理
client list命令能列出与Redis服务端相连的所有客户端连接信息。
Redis为每个客户端分配了输入缓冲区,它的作用是将客户端发送的命令临时保存,同时Redis从会输入缓冲区拉取命令并执行,输入缓冲区为客户端发送命令到Redis执行命令提供了缓冲功能,如下图所示。
输入缓冲使用不当会产生两个问题:
- 一旦某个客户端的输入缓冲区超过1G,客户端将会被关闭。
- 输入缓冲区不受maxmemory控制,假设一个Redis实例设置了maxmemory为4G,已经存储了2G数据,但是如果此时输入缓冲区使用了3G,已经超过maxmemory限制,可能会产生数据丢失、键值淘汰、OOM等情况。
Redis为每个客户端分配了输出缓冲区,它的作用是保存命令执行的结果返回给客户端,为Redis和客户端交互返回结果提供缓冲。与输入缓冲区不同的是,输出缓冲区的容量可以通过参数client-output-buffer-limit来进行设置,并且输出缓冲区做得更加细致,按照客户端的不同分为三种:普通客户端、发布订阅客户端、slave客户端,如下图所示。
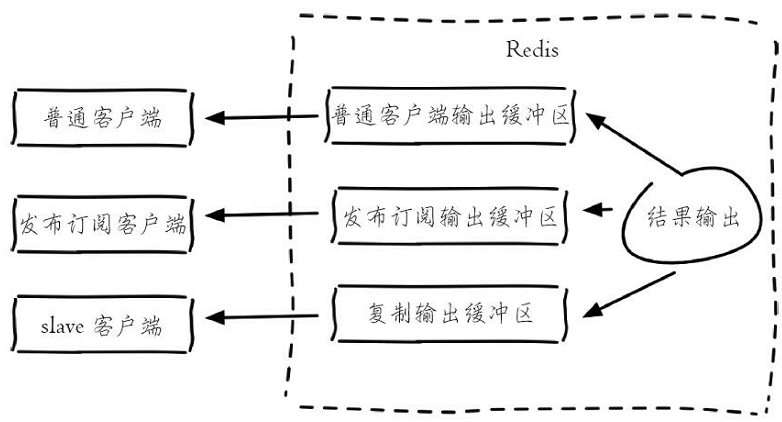
和输入缓冲区相同的是,输出缓冲区也不会受到maxmemory的限制,如果使用不当同样会造成maxmemory用满产生的数据丢失、键值淘汰、OOM等情况。
第5章 持久化
Redis支持RDB和AOF两种持久化机制,持久化功能有效地避免因进程退出造成的数据丢失问题,当下次重启时利用之前持久化的文件即可实现数据恢复。
5.1 RDB(快照方式)
RDB持久化是把当前进程数据生成快照保存到硬盘的过程。触发RDB持久化过程分为手动触发和自动触发:
(1)手动触发分别对应save和bgsave命令:
- save命令:阻塞当前Redis服务器,直到RDB过程完成为止,对于内存比较大的实例会造成长时间阻塞,线上环境不建议使用。
- bgsave命令:Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。
显然bgsave命令是针对save阻塞问题做的优化。因此Redis内部所有的涉及RDB的操作都采用bgsave的方式,而save命令已经废弃。
bgsave命令的运作过程:
- 执行bgsave命令,Redis父进程判断当前是否存在正在执行的子进程,如果存在bgsave命令直接返回。
- 父进程fork完成后,bgsave命令返回“Background saving started”信息并不再阻塞父进程,可以继续响应其他命令。
- 子进程创建RDB文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换。
- 进程发送信号给父进程表示完成,父进程更新统计信息。
(2)自动触发:
- 使用save相关配置,如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。
- 如果从节点执行全量复制操作,主节点自动执行bgsave生成RDB文件并发送给从节点。
- 执行debug reload命令重新加载Redis时,也会自动触发save操作。
- 默认情况下执行shutdown命令时,如果没有开启AOF持久化功能则自动执行bgsave。
RDB的优点:
- RDB是一个紧凑压缩的二进制文件,代表Redis在某个时间点上的数据快照。非常适用于备份,全量复制等场景。比如每6小时执行bgsave备份,并把RDB文件拷贝到远程机器或者文件系统中(如hdfs),用于灾难恢复。
- Redis加载RDB恢复数据远远快于AOF的方式。
RDB的缺点:
- RDB方式数据没办法做到实时持久化/秒级持久化。因为bgsave每次运行都要执行fork操作创建子进程,属于重量级操作,频繁执行成本过高。
- RDB文件使用特定二进制格式保存,Redis版本演进过程中有多个格式的RDB版本,存在老版本Redis服务无法兼容新版RDB格式的问题。
5.2 AOF(日志方式)
AOF(append only file)持久化:以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中的命令达到恢复数据的目的。AOF的主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式。
AOF默认是默认不开启的,开启AOF功能需要设置配置:appendonly yes。
AOF工作流程:
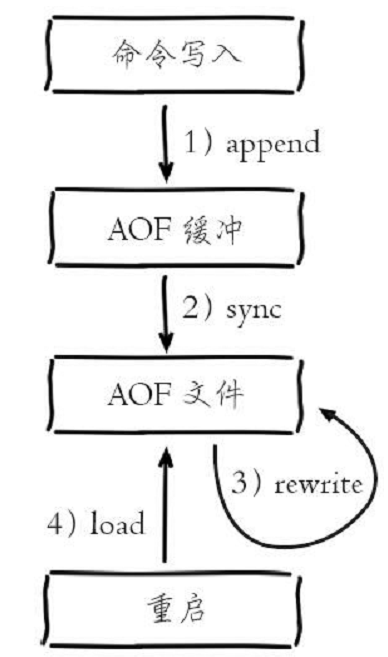
- 所有的写入命令会追加到aof_buf(缓冲区)中。
- AOF缓冲区根据对应的策略向硬盘做同步操作。
- 随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的。
- 当Redis服务器重启时,可以加载AOF文件进行数据恢复。
注:
1. AOF为什么把命令追加到aof_buf中?
Redis使用单线程响应命令,如果每次写AOF文件命令都直接追加到硬盘,那么性能完全取决于当前硬盘负载。先写入缓冲区aof_buf中,还有另一个好处,Redis可以提供多种缓冲区同步硬盘的策略,在性能和安全性方面做出平衡。
2. AOF缓冲区同步文件策略,由参数appendfsync控制:
appendfsync always #每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度
appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘
appendfsync no #让操作系统决定何时进行同步
3. AOF文件重写是把Redis进程内的数据转化为写命令同步到新AOF文件的过程。重写后的AOF文件为什么可以变小?
1)进程内已经超时的数据不再写入文件。
2)旧的AOF文件含有无效命令,重写使用进程内数据直接生成,这样新的AOF文件只保留最终数据的写入命令。
3)多条写命令可以合并为一个,如:lpush list a、lpush list b、lpush list c可以转化为:lpush list a b c。为了防止单条命令过大造成客户端缓冲区溢出,对于list、set、hash、zset等类型操作,以64个元素为界拆分为多条。
AOF重写降低了文件占用空间,除此之外,另一个目的是:更小的AOF文件可以更快地被Redis加载。
【注】如果同时配了RDB和AOF,优先加载AOF。
第6章 复制
《Redis开发与运维》的更多相关文章
- 简单物联网:外网访问内网路由器下树莓派Flask服务器
最近做一个小东西,大概过程就是想在教室,宿舍控制实验室的一些设备. 已经在树莓上搭了一个轻量的flask服务器,在实验室的路由器下,任何设备都是可以访问的:但是有一些限制条件,比如我想在宿舍控制我种花 ...
- 利用ssh反向代理以及autossh实现从外网连接内网服务器
前言 最近遇到这样一个问题,我在实验室架设了一台服务器,给师弟或者小伙伴练习Linux用,然后平时在实验室这边直接连接是没有问题的,都是内网嘛.但是回到宿舍问题出来了,使用校园网的童鞋还是能连接上,使 ...
- 外网访问内网Docker容器
外网访问内网Docker容器 本地安装了Docker容器,只能在局域网内访问,怎样从外网也能访问本地Docker容器? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Docker容器 ...
- 外网访问内网SpringBoot
外网访问内网SpringBoot 本地安装了SpringBoot,只能在局域网内访问,怎样从外网也能访问本地SpringBoot? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装Java 1 ...
- 外网访问内网Elasticsearch WEB
外网访问内网Elasticsearch WEB 本地安装了Elasticsearch,只能在局域网内访问其WEB,怎样从外网也能访问本地Elasticsearch? 本文将介绍具体的实现步骤. 1. ...
- 怎样从外网访问内网Rails
外网访问内网Rails 本地安装了Rails,只能在局域网内访问,怎样从外网也能访问本地Rails? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Rails 默认安装的Rails端口 ...
- 怎样从外网访问内网Memcached数据库
外网访问内网Memcached数据库 本地安装了Memcached数据库,只能在局域网内访问,怎样从外网也能访问本地Memcached数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装 ...
- 怎样从外网访问内网CouchDB数据库
外网访问内网CouchDB数据库 本地安装了CouchDB数据库,只能在局域网内访问,怎样从外网也能访问本地CouchDB数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Cou ...
- 怎样从外网访问内网DB2数据库
外网访问内网DB2数据库 本地安装了DB2数据库,只能在局域网内访问,怎样从外网也能访问本地DB2数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动DB2数据库 默认安装的DB2 ...
- 怎样从外网访问内网OpenLDAP数据库
外网访问内网OpenLDAP数据库 本地安装了OpenLDAP数据库,只能在局域网内访问,怎样从外网也能访问本地OpenLDAP数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动 ...
随机推荐
- Maven系列(二) -- 将开源库上传到maven仓库私服
前言 之前简单说了下Maven的搭建,现在跟大家说一下如何将自己的aar传到我们新搭建的maven仓库里面,接下来我们就从最基本的新建一个library开始讲述整个流程,话不多说,让我们把愉快的开始吧 ...
- pyinstaller打包pyqt5,从入坑到填坑,详解
以上省略pyinstaller安装步骤,直入主题.先分享我的心路历程. 1.pyinstaller -F -i 1.ico UI_Main.py (先在CMD中 cd到 py文件对应的路径) 第一步打 ...
- Android_存储访问框架SAF
概念 存储访问框架---Storage Access Framework (SAF),这是在Android4.4(API level 19)之后引入的. 借助 SAF,用户可轻松在其所有首选文档存储提 ...
- 题解 P4071 【[SDOI2016]排列计数】 (费马小定理求组合数 + 错排问题)
luogu题目传送门! luogu博客通道! 这题要用到错排,先理解一下什么是错排: 问题:有一个数集A,里面有n个元素 a[i].求,如果将其打乱,有多少种方法使得所有第原来的i个数a[i]不在原来 ...
- 关于服务器运维人员,该如何管理很多VPS呢?
众所周知,服务器运营人员的工作内容,主要围绕着公司上下所有服务器.网络等硬件平台的运维工作,对每台服务器的状况,如磁盘.内存.网络.CPU等资源情况都要有明确的了解,还要定期对服务器进行巡检和修复,避 ...
- Java实现 蓝桥杯 算法提高 上帝造题五分钟
算法提高 上帝造题五分钟 时间限制:1.0s 内存限制:256.0MB 问题描述 第一分钟,上帝说:要有题.于是就有了L,Y,M,C 第二分钟,LYC说:要有向量.于是就有了长度为n写满随机整数的向量 ...
- Java中StringBuffer和StringBuilder的区别
区别1线程安全: StringBuffer是线程安全的,StringBuilder是线程是不安全的.因为StringBuffer的所有公开方法都用synchronized 来修饰,StringBuil ...
- JavaWeb+SVN+Maven+Tomcat +jenkins搭建持续集成环境和自动部署
https://blog.csdn.net/wh52788/article/details/80900477 https://blog.csdn.net/liyong1028826685/articl ...
- python—迭代器,生成器与for循环机制
一:什么是迭代器协议 1.迭代器协议是指:对象必须提供一个next方法,执行该方法要么返回迭代器中的下一项,要么就引起一个stoplteration异常,以终止协议(只能往后走不能往前) 2.可迭代对 ...
- 制作sentinel docker镜像
在sentinel官方下载jar包即可运行,但是在部署的时候一个一个的启动jar包很不方便,制作成镜像方便部署和管理. 1)直接运行 # 修改端口号,默认是8080 java -jar sentine ...