Mycat简介及适用场景
一、Mycat是什么
Mycat是一个开源的分布式数据库系统,是一个实现了 MySQL 协议的的 Server,前端用户可以把它看作是一个数据库代理,用 MySQL 客户端工具和命令行访问,而其后端可以用MySQL 原生(Native)协议与多个 MySQL 服务器通信,也可以用 JDBC 协议与大多数主流数据库服务器通信,其核心功能是分表分库,即将一个大表水平分割为 N 个小表,存储在后端 MySQL 服务器里或者其他数据库里。
Mycat 是一个近似等于 MySQL 的数据库服务器,但它本身并不存储数据,数据是在后端的 MySQL 上存储的,数据可靠性以及事务等都是 MySQL 保证的。你可以用连接 MySQL 的方式去连接 Mycat(除了端口不同,默认的 Mycat 端口是 8066 而非 MySQL 的 3306,因此需要在连接字符串上增加端口信息),大多数情况下,可以用你熟悉的对象映射框架使用 Mycat,但建议对于分片表,尽量使用基础的 SQL 语句,因为这样能达到最佳性能,特别是几千万甚至几百亿条记录的情况下。
二、Mycat的原理
Mycat 的原理并不复杂,复杂的是代码。Mycat 的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的 SQL 语句,首先对 SQL 语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此 SQL 发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
当 Mycat 收到一个 SQL 时,会先解析这个 SQL,查找涉及到的表,然后看此表的定义,如果有分片规则,则获取到 SQL 里分片字段的值,并匹配分片函数,得到该 SQL 对应的分片列表,然后将 SQL 发往这些分片去执行,最后收集和处理所有分片返回的结果数据,并输出到客户端。
三、Mycat应用场景
- 单纯的读写分离,此时配置最为简单,支持读写分离,主从切换;
- 分表分库,对于超过 1000 万的表进行分片,最大支持 1000 亿的单表分片;
- 多租户应用,每个应用一个库,但应用程序只连接 Mycat,从而不改造程序本身,实现多租户化;
- 报表系统,借助于 Mycat 的分表能力,处理大规模报表的统计;
- 替代 Hbase,分析大数据;
- 作为海量数据实时查询的一种简单有效方案,比如 100 亿条频繁查询的记录需要在 3 秒内查询出来结果,除了基于主键的查询,还可能存在范围查询或其他属性查询,此时 Mycat 可能是最简单有效的选择。
四、Mycat不适用场景
1. 非分片字段查询
Mycat中的路由结果是通过分片字段和分片方法来确定的。
如果查询条件中有分片字段,查询会通过计算路由落到某个具体的分片,并将请求路由到指定的数据库上执行。
如果查询条件中没有分片字段条件,此时Mycat无法计算路由,便发送到所有节点上执行。如果DB节点很多,这会极大消耗Mycat和MySQL数据库资源。
2. 分页排序
先看一下Mycat是如何处理分页操作的,假如有如下Mycat分库方案:
一张表有30份数据分布在3个分片DB上,具体数据分布如下:
DB1:[0,1,2,3,4,10,11,12,13,14]
DB2:[5,6,7,8,9,16,17,18,19]
DB3:[20,21,22,23,24,25,26,27,28,29]
这个示例的场景中没有查询条件,所以都是全分片查询,也就没有假定该表的分片字段和分片方法。
当应用执行如下分页查询时:
select * fromtable limit 2;
Mycat将该SQL请求分发到各个DB节点去执行,并接收各个DB节点的返回结果:
DB1: [0,1]
DB2: [5,6]
DB3: [20,21]
但Mycat向应用返回的结果集取决于哪个DB节点最先返回结果给Mycat。如果Mycat最先收到DB1节点的结果集,那么Mycat返回给应用端的结果集为 [0,1],如果Mycat最先收到DB2节点的结果集,那么返回给应用端的结果集为 [5,6]。也就是说,相同情况下,同一个SQL,在Mycat上执行时会有不同的返回结果。
在Mycat中执行分页操作时必须显示加上排序条件才能保证结果的正确性,下面看一下Mycat对排序分页的处理逻辑。
假如在前面的分页查询中加上了排序条件(假如表数据的列名为id):
select * fromtable orderby id limit 2;
在有排序呢条件的情况下,Mycat接收到各个DB节点的返回结果后,对其进行最小堆运算,计算出所有结果集中最小的两条记录 [0,1] 返回给应用。
但是,当排序分页中有 偏移量 (offset)时,处理逻辑又有不同。假如应用的查询SQL如下:
select * fromtable order by id limit 5,2;
如果按照上述排序分页逻辑来处理,那么处理结果如下图:
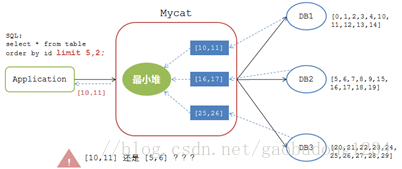
Mycat将各个DB节点返回的数据 [10,11],[16,17], [20,21] 经过最小堆计算后返回给应用的结果集是 [10,11]。可是,对于应用而言,该表的所有数据明明是 0-29 这30个数据的集合,limit 5,2 操作返回的结果集应该是 [5,6],如果返回 [10,11] 则是错误的处理逻辑。
所以Mycat在处理 有偏移量的排序分页 时是另外一套逻辑——改写SQL 。
Mycat在下发有 limit m,n 的SQL语句时会对其进行改写,改写成 limit 0, m+n 来保证查询结果的逻辑正确性。所以,Mycat发送到后端DB上的SQL语句是:
select * fromtable order by id limit 0,7;
各个DB返回给Mycat的结果集是:
DB1: [0,1,2,3,4,10,11]
DB2: [5,6,7,8,9,16,17]
DB3: [20,21,22,23,24,25,26]
经过最小堆计算后得到最小序列 [0,1,2,3,4,5,6] ,然后返回偏移量为5的两个结果为 [5,6] 。
虽然Mycat返回了正确的结果,但是仔细推敲发现这类操作的处理逻辑是及其消耗(浪费)资源的。应用需要的结果集为2条,Mycat中需要处理的结果数为21条。也就是说,对于有 t 个DB节点的全分片 limit m, n 操作,Mycat需要处理的数据量为 (m+n)*t 个。比如实际应用中有50个DB节点,要执行limit 1000,10操作,则Mycat处理的数据量为 50500 条,返回结果集为10,当偏移量更大时,内存和CPU资源的消耗则是数十倍增加。
3. 任意表的join
先看一下在单库中JOIN中的场景。假设在某单库中有 player 和 team 两张表,player 表中的 team_id 字段与 team 表中的id 字段相关联。

JOIN操作的SQL如下:
selectp_name,t_name from player p, team t where p.no = 3 and p.team_id = t.id;
此时能查询出结果。
如果将这两个表的数据分库后,相关联的数据可能分布在不同的DB节点上:
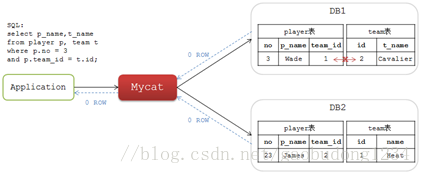
这个SQL在各个单独的分片DB中都查不出结果,也就是说Mycat不能查询出正确的结果集。
4. 分布式事务
Mycat并没有根据二阶段提交协议实现 XA事务,而是只保证 prepare 阶段数据一致性的 弱XA事务 ,实现过程如下:
应用开启事务后Mycat标识该连接为非自动提交,比如前端执行:
mysql>begin;
Mycat不会立即把命令发送到DB节点上,等后续下发SQL时,Mycat从连接池获取非自动提交的连接去执行。

Mycat会等待各个节点的返回结果,如果都执行成功,Mycat给该连接标识为 Prepare Ready 状态,如果有一个节点执行失败,则标识为 Rollback 状态。
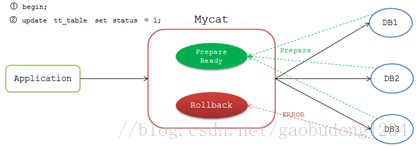
执行完成后Mycat等待前端发送 commit 或 rollback 命令。发送 commit 命令时,Mycat检测当前连接是否为 Prepare Ready 状态,若是,则将 commit 命令发送到各个DB节点。
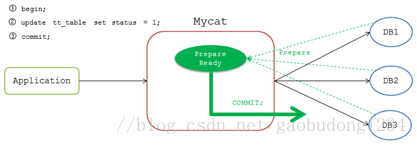
但是,这一阶段是无法保证一致性的,如果一个DB节点在 commit 时故障,而其他DB节点 commit 成功,Mycat会一直等待故障DB节点返回结果。Mycat只有收到所有DB节点的成功执行结果才会向前端返回 执行成功 的包,此时Mycat只能一直 waiting 直至TIMEOUT,导致事务一致性被破坏。
本系列是基于1.6-RELEASE (2.0尚在开发)
参考:https://blog.csdn.net/gaobudong1234/article/details/79581846
Mycat简介及适用场景的更多相关文章
- mycat简介
开源数据库中间件-MyCat简介 如今随着互联网的发展,数据的量级也是撑指数的增长,从GB到TB到PB.对数据的各种操作也是愈加的困难,传统的关系性数据库已经无法满足快速查询与插入数据的需求.这个时候 ...
- [转帖]kafka入门:简介、使用场景、设计原理、主要配置及集群搭建
kafka入门:简介.使用场景.设计原理.主要配置及集群搭建 http://www.aboutyun.com/thread-9341-1-1.html 还没看完 感觉挺好的. 问题导读: 1.zook ...
- IntelliJ IDEA 2017 Dubbo Elastic-job Redis Zookeeper RabbitMQ FastDFS MyCat 简介以及部分实现(三)
前言 首先需要说明一下,与前两章的安装篇不太一样,这篇主要扫清一下这些插件/框架 等都是干什么用的,大多数都会用于服务端或监测工具或其他,作为新手建立一个大概的思想更好的了解自己的项目.废话不多 ...
- kafka入门:简介、使用场景、设计原理、主要配置及集群搭建(转)
问题导读: 1.zookeeper在kafka的作用是什么? 2.kafka中几乎不允许对消息进行"随机读写"的原因是什么? 3.kafka集群consumer和producer状 ...
- 开放数据接口 API 简介与使用场景、调用方法
此文章对开放数据接口 API 进行了功能介绍.使用场景介绍以及调用方法的说明,供用户在使用数据接口时参考之用. 在给大家分享的一系列软件开发视频课程中,以及在我们的社区微信群聊天中,都积极地鼓励大家开 ...
- Mycat原理、应用场景
Mycat原理 Mycat的原理并不复杂,复杂的是代码,如果代码也不复杂,那么早就成为一个传说了.Mycat的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一 ...
- RabbitMQ 简介以及使用场景
目录 一. RabbitMQ 简介 二. RabbitMQ 使用场景 1. 解耦(为面向服务的架构(SOA)提供基本的最终一致性实现) 2. 异步提升效率 3. 流量削峰 三. 引入消息队列的优缺点 ...
- 浅谈nginx简介和应用场景
简介 nginx是一款轻量级的web服务器,它是由俄罗斯的程序设计师伊戈尔·西索夫所开发. nginx相比于Tomcat性能十分优秀,能够支撑5w的并发连接(而Tomcat只能支撑200-400),并 ...
- 中间件 | kafka简介、使用场景、设计原理、主要配置及集群搭建
开源Java学习 公众号 一.入门 1.简介 Kafka is a distributed,partitioned,replicated commit logservice.它提供了类似于JMS的特性 ...
随机推荐
- 006-PHP检测是否为整数
<?php function checkInteger($Number) { if ($Number > 1) { /* 整数减1仍然是整数 */ return (checkInteger ...
- Java 定时循环运行程序
Timer 和 ScheduledExecutorSeruvce 都能执行定时的循环任务,有函数 scheduleAtFixedRate.但是,如果任务运行时间较长,超过了一个周期时长,下一个任务就会 ...
- android studio 入门坑
安装 android studio,碰到下面这个图片,直接跳过. 安装时候,选择自定义设置,里面可以配置 sdk 的存放位置. 新建工程后,gradle sync 比较慢,可以 修改工程中的 buil ...
- 关于http的两种上传方法
http传输数据GET和POST的两种方法: 1.Post传输数据时,不需要在URL中显示出来,而Get方法要在URL中显示. 2.get方式传递的参数可以在URL上看见,安全性不高,反之post安全 ...
- 使用Vue+JFinal框架搭建前后端分离系统
前后端分离作为Web开发的一种方式,现在应用越来越广泛.前端一般比较流行Vue.js框架,后端框架比较多,网上有很多Vue+SpringMVC前后端分离的demo,但是Vue+JFinal框架貌似没有 ...
- Linux系统sda变sdb的解决
起因 我的电脑有一个128G的固态以及一个500G的机械,我将系统安装在128G固态中,于是将500G的机械(/dev/sdb)挂在在/home目录下,安装完系统后执行lsblk命令 NAME MAJ ...
- asp.net mvc3用file上传文件大小限制问题
在Windows2008下,如果上传比较大的文件,可能会出现404错误,(请求筛选模块被配置为拒绝超过请求内容长度的请求). 可通过如下方法解决: 打开URTracker根目录下的web.config ...
- SpringBoot#JSR303
__震惊了!,一遍一遍在业务逻辑中编写的验证条件被抽离了! 是什么: - Java Specification Requests 303 ,用于对javaBean 属性的验证. - 解决了什么问题: ...
- 自己安装windows版本的Flink
参照 https://blog.csdn.net/clj198606061111/article/details/99694033 我自己做一遍 找到对应的网址 https://flink.apach ...
- gem5-gpu全系统模式
# 注意:安装好gem5-gpu后再配置全系统环境 # 下载全系统模拟需要的工具,详见http://gem5.org/Running_gem5#Full_System_.28FS.29_Mode,将L ...