spark实验(一)--spark安装(1)
一、实验目的
(1)掌握 Linux 虚拟机的安装方法。Spark 和 Hadoop 等大数据软件在 Linux 操作系统 上运行可以发挥最佳性能,因此,本教程中,Spark 都是在 Linux 系统中进行相关操作,同 时,下一章的 Scala 语言也会在 Linux 系统中安装和操作。鉴于目前很多读者正在使用 Windows 操作系统,因此,为了顺利完成本教程的后续实验,这里有必要通过本实验,让读 者掌握在 Windows 操作系统上搭建 Linux 虚拟机的方法。当然,安装 Linux 虚拟机只是安 装 Linux 系统的其中一种方式,实际上,读者也可以不用虚拟机,而是采用双系统的方式安 装 Linux 系统。本教程推荐使用虚拟机方式。 (2)熟悉 Linux 系统的基本使用方法。本教程全部在 Linux 环境下进行实验,因此, 需要读者提前熟悉 Linux 系统的基本用法,尤其是一些常用命令的使用方法。
二、实验过程
环境:centos6.4,jdk1.7.0,spark1.5.2
根据这篇博文https://www.cnblogs.com/Genesis2018/p/9079787.html安装spark1.5.2
首先输入
wget http://archive.apache.org/dist/spark/spark-1.5.2/spark-1.5.2-bin-hadoop2.6.tgz下载spark1.5.2

等待下载完成后,将下载完的文件进行解压
输入
tar -zxvf spark-1.5.2-bin-hadoop2.6.tgz将下载完的文件进行解压,之后输入以下命令移动到对应的/usr/local/目录中
mv spark-1.5.2-bin-hadoop2.6 /usr/local/
接着输入
gedit /etc/profile.d/spark.sh在打开的文件中添加以下的信息
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR==$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/usr/local/spark-1.5.2-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin保存退出后
输入
source /etc/profile.d/spark.sh使文件生效
接着输入
cp /usr/local/spark-1.5.2-bin-hadoop2.6/conf/spark-env.sh.template /usr/local/spark-1.5.2-bin-hadoop2.6/conf/spark-env.shgedit /usr/local/spark-1.5.2-bin-hadoop2.6/conf/spark-env.sh在打开的文件中输入(IP和jdk需要根据自己本身的版本进行设置)
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.221.x86_64/jre
export SCALA_HOME=/usr/local/scala-2.10.6
export HADOOP_HOME=/usr/local/hadoop-2.7.2
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_MASTER_HOST=192.168.57.128
export SPARK_LOCAL_IP=192.168.57.128
接着输入
cp /usr/local/spark-1.5.2-bin-hadoop2.6/conf/slaves.template /usr/local/spark-1.5.2-bin-hadoop2.6/conf/slavesgedit /usr/local/spark-1.5.2-bin-hadoop2.6/conf/slaves将localhost中的内容改为对应虚拟机ip的地址
192.168.57.128
保存退出
验证spark安装:
sbin/start-master.sh在服务器外边输入对应
http://192.168.57.128:8080/
发现正常启动
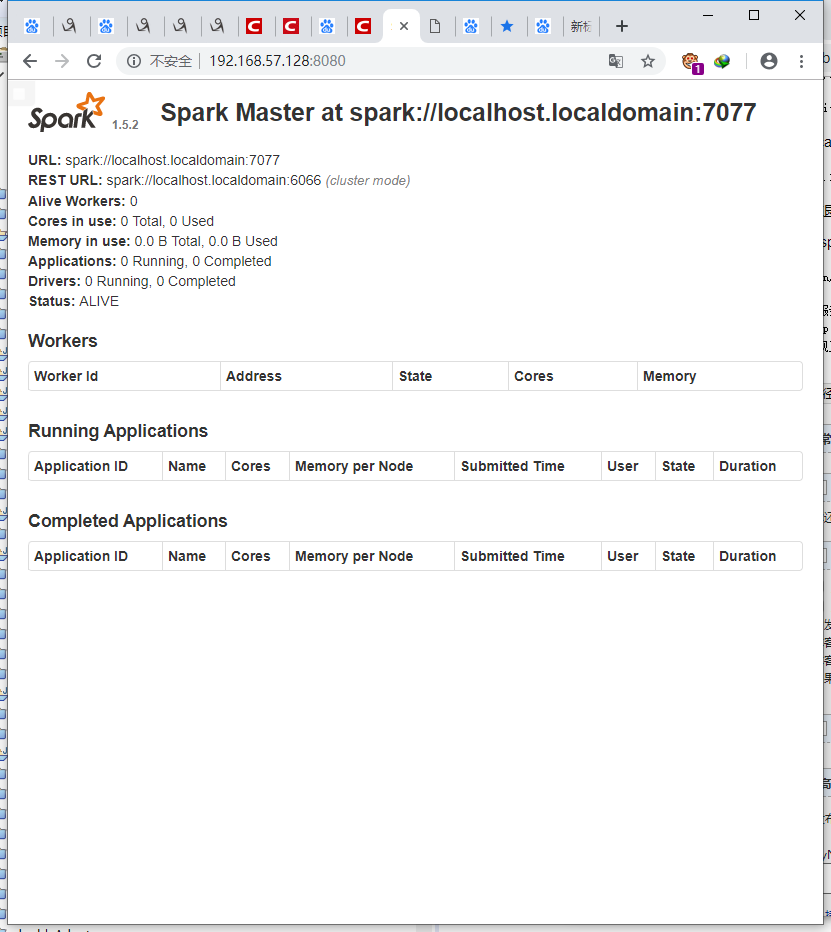
spark安装完毕
spark实验(一)--spark安装(1)的更多相关文章
- spark实验(五)--Spark SQL 编程初级实践(1)
一.实验目的 (1)通过实验掌握 Spark SQL 的基本编程方法: (2)熟悉 RDD 到 DataFrame 的转化方法: (3)熟悉利用 Spark SQL 管理来自不同数据源的数据. 二.实 ...
- spark实验(三)--Spark和Hadoop的安装(1)
一.实验目的 (1)掌握在 Linux 虚拟机中安装 Hadoop 和 Spark 的方法: (2)熟悉 HDFS 的基本使用方法: (3)掌握使用 Spark 访问本地文件和 HDFS 文件的方法. ...
- spark实验(二)--scala安装(1)
一.实验目的 (1)掌握在 Linux 虚拟机中安装 Hadoop 和 Spark 的方法: (2)熟悉 HDFS 的基本使用方法: (3)掌握使用 Spark 访问本地文件和 HDFS 文件的方法. ...
- spark实验(二)--eclipse安装scala环境(2)
此次在eclipse中的安装参考这篇博客https://blog.csdn.net/lzxlfly/article/details/80728772 Help->Eclipse Marketpl ...
- 在阿里云上搭建 Spark 实验平台
在阿里云上搭建 Spark 实验平台 Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程 [传统文化热爱者] 阿里云服务器搭建spark特别坑的地方 阿里云实现Hadoop+Sp ...
- Apache Spark简单介绍、安装及使用
Apache Spark简介 Apache Spark是一个高速的通用型计算引擎,用来实现分布式的大规模数据的处理任务. 分布式的处理方式可以使以前单台计算机面对大规模数据时处理不了的情况成为可能. ...
- spark的standlone模式安装和application 提交
spark的standlone模式安装 安装一个standlone模式的spark集群,这里是最基本的安装,并测试一下如何进行任务提交. require:提前安装好jdk 1.7.0_80 :scal ...
- Spark运行环境的安装
scala-2.9.3:一种编程语言,下载地址:http://www.scala-lang.org/download/ spark-1.4.0:必须是编译好的Spark,如果下载的是Source ...
- 实验5 Spark SQL编程初级实践
今天做实验[Spark SQL 编程初级实践],虽然网上有答案,但都是用scala语言写的,于是我用java语言重写实现一下. 1 .Spark SQL 基本操作将下列 JSON 格式数据复制到 Li ...
随机推荐
- 无法创建“System.Object”类型的常量值。此上下文仅支持基元类型或枚举类型
Entity FreamWork 无法创建“System.Object”类型的常量值.此上下文仅支持基元类型或枚举类型错误解决: 最近在开发中把我原来抄的架构里面的主键由固定的Guid改成了可以泛型指 ...
- ViewModel、LiveData、DataBinding
ViewModel ViewModel的引入 如果系统销毁或重新创建界面控制器,则存储在其中的任何临时性界面相关数据都会丢失.例如,应用的某个 Activity 中可能包含用户列表.因配置更改而重新创 ...
- 专题一 Java基础语法
小辨析: println 输出字符后,下一个输出的字符会换行展示 print 输出字符后,下一个输出字符不会会换展示 system.out.println() 空格 分支结构:if-else使用说明 ...
- JS中for循环“全局”变量的传递
在项目中,遇到了一个问题,描述如下:我们在联动下拉框中,选中值后,会在隐藏的控件中记录一下选中值的主键(展示的是名称).但是,在取消选中的时候,没有把隐藏控件中的value值清空,导致在提交的时候,有 ...
- Django - 生成models的UML图
参考 https://simpleit.rocks/python/django/generate-uml-class-diagrams-from-django-models/ 运用django-ext ...
- 放眼全球,关注游戏质量变化:腾讯WeTest发布《2019中国移动游戏质量白皮书》
2019是中国游戏市场,尤其是手游市场称得上是跌宕起伏的一年,同时也是各大厂商推陈出新突破过去的一年.面对竞争激烈的市场,手游厂商们不仅着眼于游戏质量的提升,更是将一众优秀的国产游戏带入到了海外市场, ...
- Qt: 释放窗口资源
1. 对于使用指针,使用new创建的窗口,当然可以使用delete显示的释放其占用的资源: Widget *w = new Widget(); delete w; 2. 对于使用指针,使用new创 ...
- AT24C02芯片学习记录
1.首先看AT24C02芯片的引脚说明 2.芯片的型号与存储容量(bit)的对应关系: 3.总线时序 我对时序的理解: 时钟线分两种:一种是外部时钟源控制时钟线低电平持续多久高电平持续多久,就像串口: ...
- Apache Thrift Learning Notes
简介 Apache Thrift软件框架(用于可扩展的跨语言服务开发)将软件堆栈与代码生成引擎结合在一起,以构建可在C ++,Java,Python,PHP,Ruby,Erlang,Perl,Hask ...
- provide 和 inject高阶使用
provide 在祖先里授权导出 inject在后代负责接收 foo可以是本组件的函数方法 或者 变量foo 也可以是祖先组件自己 祖先组件foo: this 后代组件 foo.$options.da ...